







高并发-解决方案--目录
总结
提高系统并发能力的方式,方法论上主要有两种:垂直扩展(Scale Up)与水平扩展(Scale Out)。
垂直扩展可以通过提升单机硬件性能,或者提升单机架构性能,来提高并发性,但单机性能总是有极限的,
互联网分布式架构设计高并发终极解决方案还是后者:水平扩展。
互联网分层架构中,各层次水平扩展的实践又有所不同:
(1)反向代理层可以通过“DNS轮询”的方式来进行水平扩展;
(2)站点层可以通过nginx来进行水平扩展;
(3)服务层可以通过服务连接池来进行水平扩展;
(4)数据库可以按照数据范围,或者数据哈希的方式来进行水平扩展;
1,什么是高并发
高并发(High Concurrency): 通过设计保证系统能够同时并行处理很多请求
1,响应时间:系统对请求做出响应的时间。例如系统处理一个HTTP请求需要200ms,这个200ms就是系统的响应时间。
2,吞吐量(Throughput):单位时间内处理的请求数量。
3,每秒查询率QPS(Query Per Second):每秒响应请求数。和吞吐量差不多。
4,并发用户数:同时承载正常使用系统功能的用户数量。例如一个即时通讯系统,同时在线量一定程度上代表了系统的并发用户数。
2,常见的互联网分层架构

(1)客户端层:典型调用方是浏览器browser或者手机应用APP
(2)反向代理层:系统入口,反向代理
(3)站点应用层:实现核心应用逻辑,返回html或者json
(4)服务层:如果实现了服务化,就有这一层
(5)数据-缓存层:缓存加速访问存储
(6)数据-数据库层:数据库固化数据存储
先看数据传输的格式,即协议很重要:
service与db/cache之间,二进制协议/文本协议是数据传输的载体
web-server与service之间,RPC的二进制协议是数据传输的载体
client和web-server之间,http协议是数据传输的载体
再看数据在各层次的形态,以用户数据为例:
db层,数据是以“行”为单位存在的row(uid, name, age)
cache层,数据是以kv的形式存在的kv(uid -> User)
service层,会把row或者kv转化为对程序友好的User对象
web-server层,会把对程序友好的User对象转化为对http友好的json对象
client层:最终端上拿到的是json对象
3,分层水平扩展架构实践
3-1,反向代理层的水平扩展
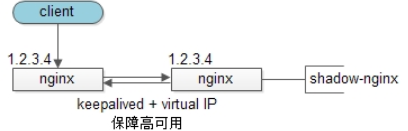
反向代理层的水平扩展,是通过“DNS轮询”实现的:dns-server对于一个域名配置了多个解析ip,每次DNS解析请求来访问dns-server,会轮询返回这些ip。
当nginx成为瓶颈的时候,只要增加服务器数量,新增nginx服务的部署,增加一个外网ip,就能扩展反向代理层的性能,做到理论上的无限高并发。
nginx负载均衡:内置策略:IP Hash,加权轮询;扩展策略:fair策略,通用hash,一致性hash
-
加权轮询:
首先将请求都分给高权重的机器,直到该机器的权值降到了比其他机器低,才开始将请求分给下一个高权重的机器,当所有后端机器都down掉时,nginx会立即将所有机器的标志位清成初始状态,以避免造成所有的机器都处在timeout的状态; -
IP Hash:
流程和轮询很类似,只是其中的算法和具体的策略有些变化,算法是一种变相的轮询算法; -
fair:
根据后端服务器的响应时间判断负载情况,从中选出负载最轻的机器进行分流; -
通用hash,一致性hash:
通用hash比较简单,可以以nginx内置的变量为key进行hash,一致性hash采用了nginx内置的一致性hash环,支持memcache
3-2, 站点层的水平扩展
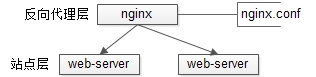
站点层的水平扩展,是通过“nginx”实现的。通过修改nginx.conf,可以设置多个web后端。
当web后端成为瓶颈的时候,只要增加服务器数量,新增web服务的部署,在nginx配置中配置上新的web后端,就能扩展站点层的性能,做到理论上的无限高并发。
3-3, 服务层的水平扩展
负载均衡,也就是接收到一个请求后具体分配到那个服务器去处理的问题
不同的业务请求,发送到对应的业务服务器群中。
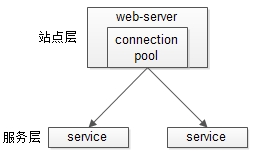
服务层的水平扩展,是通过“服务连接池”实现的。
站点层通过RPC-client调用下游的服务层RPC-server时,RPC-client中的连接池会建立与下游服务多个连接,
当服务成为瓶颈的时候,只要增加服务器数量,新增服务部署,在RPC-client处建立新的下游服务连接,就能扩展服务层性能,做到理论上的无限高并发。
如果需要优雅的进行服务层自动扩容,这里可能需要配置中心里服务自动发现功能的支持。
3-4,应用和静态资源分离
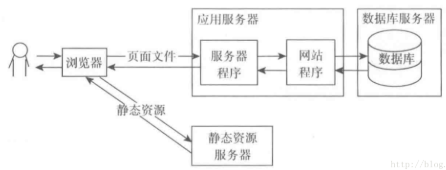
刚开始的时候应用和静态资源是保存在一起的,当并发量达到一定程度的时候就需要将静态资源保存到专门的服务器中,
静态资源主要包括图片、视频、js、css和一些资源文件等,
这些文件因为没有状态所以分离比较简单,直接存放到响应的服务器就可以了,一般会使用专门的域名去访问。
通过不同的域名可以让浏览器直接访问资源服务器而不需要再访问应用服务器了。架构图如下:
3-5, 前端使用CDN引进资源
CDN适用场景:站点或者应用中大量静态资源的加速分发,如css,js,img和html;大文件下载;直播网站等
<script src="http://cdn.bootcss.com/vue/2.1.10/vue.js"></script>
<script src="http://cdn.bootcss.com/vue-router/2.2.0/vue-router.js"></script>
<script src="http://cdn.bootcss.com/vue-resource/1.1.0/vue-resource.js"></script>
cdn其实是一种特殊的集群页面缓存服务器,他和普通集群的多台页面缓存服务器相比,主要是它存放的位置和分配请求的方式有点特殊。
CDN 服务器是分布在全国各地的,当接收到用户请求后会将请求分配到最合适的CDN服务器节点获取数据。
比如联通的用户分配到联通的节点,上海的用户分配到上海的节点。
CDN的每个节点其实就是一个页面缓存服务器,如果没有请求资源的缓存就会从主服务器获取,否则直接返回缓存的页面。

传统访问:
用户在浏览器输入域名发起请求–解析域名获取服务器IP地址–根据IP地址找到对应的服务器–服务器响应并返回数据;
使用CDN访问:
用户发起请求–智能DNS的解析(根据IP判断地理位置,接入网类型,选择路由最短和负载最轻的服务器)–取得缓存服务器IP–把内容返回给用户(如果缓存中有)–向源站发起请求–将结果返回给用户–将结果存入缓存服务器
3-6,
1、降低延迟:如果不采用连接池,每次连接发起Http请求的时候都会重新建立TCP连接(经历3次握手),用完就会关闭连接(4次挥手),如果采用连接池则减少了这部分时间损耗,别小看这几次握手,本人经过测试发现,基本上3倍的时间延迟
2、支持更大的并发:如果不采用连接池,每次连接都会打开一个端口,在大并发的情况下系统的端口资源很快就会被用完,导致无法建立新的连接
3-7, 高并发下数据库
按照范围水平拆分
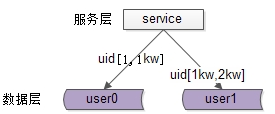
每一个数据服务,存储一定范围的数据,上图为例:
user0库,存储uid范围1-1kw;user1库,存储uid范围1kw-2kw
好处是:
(1)规则简单,service只需判断一下uid范围就能路由到对应的存储服务;
(2)数据均衡性较好;
(3)比较容易扩展,可以随时加一个uid[2kw,3kw]的数据服务;
不足是:
(1)请求的负载不一定均衡,一般来说,新注册的用户会比老用户更活跃,大range的服务请求压力会更大;
按照哈希水平拆分
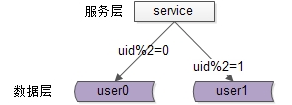
每一个数据库,存储某个key值hash后的部分数据,上图为例:
user0库,存储偶数uid数据;user1库,存储奇数uid数据
好处是:
(1)规则简单,service只需对uid进行hash能路由到对应的存储服务;
(2)数据均衡性较好;
(3)请求均匀性较好;
不足是:
(1)不容易扩展,扩展一个数据服务,hash方法改变时候,可能需要进行数据迁移;
缓存层的水平拆分和数据库层的水平拆分类似,也是以范围拆分和哈希拆分的方式居多,就不再展开。
数据库读取的路径要短
- 在Web层和db层之间加一层cache层,
主要目的:减少数据库读取负担,提高数据读取速度。cache存取的媒介是内存,可以考虑采用分布式的cache层,这样更容易破除内存容量的限制,同时增加了灵活性。
- 使用储存过程
那些处理一次请求需要多次访问数据库的操作,可以把操作整合到储存过程,这样只要一次数据库访问就可以了。
- 批量读取
高并发情况下,可以把多个请求的查询合并到一次进行,以减少数据库的访问次数
分库与分表实现策略
数据库分表可以解决单表海量数据的查询性能问题,分库可以解决单台数据库的并发访问压力问题。
同时考虑这两个问题,既需要对单表进行分表操作,还需要进行分库操作,以便同时扩展系统的并发处理能力和提升单表的查询性能,就是我们使用到的分库分表。
分库分表的常见的路由策略如下:
1、中间变量 = user_id%(库数量*每个库的表数量);
2、库序号 = 取整(中间变量/每个库的表数量);
3、表序号 = 中间变量%每个库的表数量;
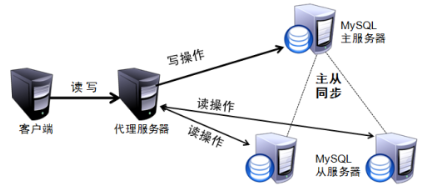
MySQL主从复制,读写分离
当数据库的写压力增加,cache层(如Memcached)只能缓解数据库的读取压力。读写集中在一个数据库上让数据库不堪重负。
使用主从复制技术(master-slave模式)来达到读写分离,以提高读写性能和读库的可扩展性。
读写分离就是只在主服务器上写,只在从服务器上读,基本原理是让主数据库处理事务性查询,而从数据库处理select查询,数据库复制被用于把事务性查询(增删改)导致的改变更新同步到集群中的从数据库。
-
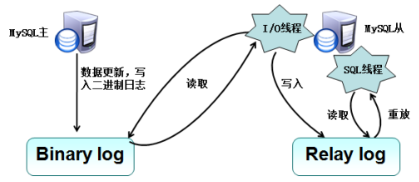
MySQL主从复制的原理:
数据复制的实际就是Slave从Master获取Binary log文件,然后再本地镜像的执行日志中记录的操作。由于主从复制的过程是异步的,因此Slave和Master之间的数据有可能存在延迟的现象,此时只能保证数据最终的一致性。 -
MySQL读写分离提升系统性能:
1、主从只负责各自的读和写,极大程度缓解X锁和S锁争用。
2、slave可以配置MyISAM引擎,提升查询性能以及节约系统开销。
3、master直接写是并发的,slave通过主库发送来的binlog恢复数据是异步的。
4、slave可以单独设置一些参数来提升其读的性能。
5、增加冗余,提高可用性。
实现主从分离可以使用MySQL中间件如:Atlas















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









