







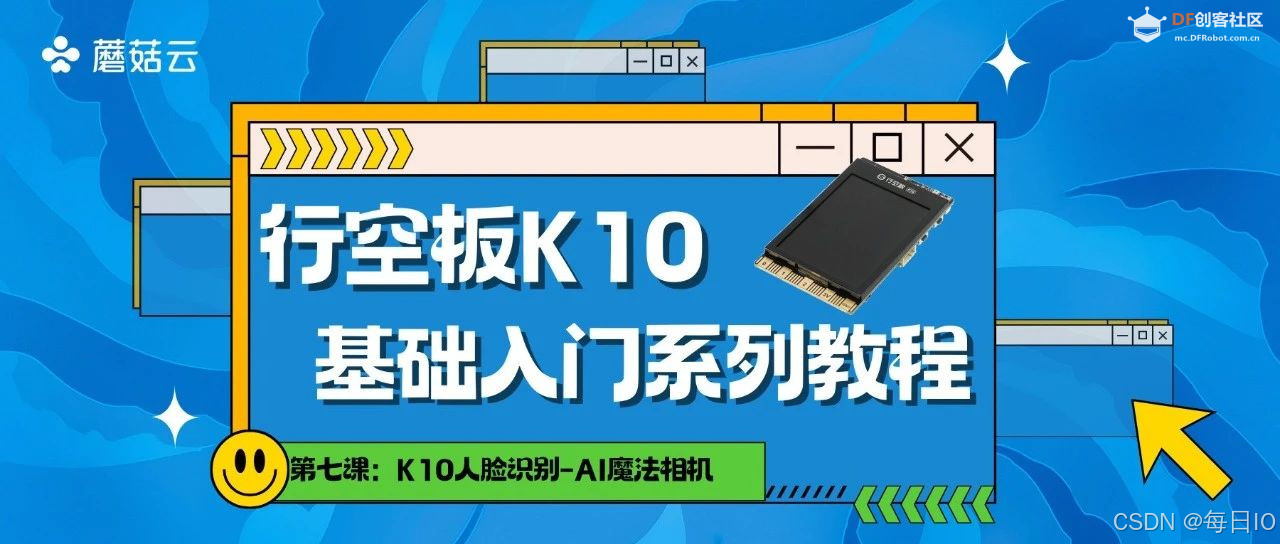
Hi,欢迎各位来到行空板 K10的第七课!刚刚过去的圣诞节,你是怎么度过的呢?今天我们就来探索如何利用行空板自制一款 AI 魔法相机,我们能用它来拍下照片,还可以一键添加各种精美的圣诞节装饰效果,制作我们的圣诞照片。

任务目标
能用行空板 K10 拍摄人脸照片,记录五官坐标和人脸大小,同时,按下 B 键,能据此添加合适的圣诞贴纸进行装饰。
知识目标
1、 掌握行空板 K10 的拍照存储
2、 掌握行空板 K10 的人脸关键点检测
3、 根据人脸实际大小以及坐标调整贴纸的大小与坐标
材料清单
硬件清单

软件使用
Mind+编程软件
1.软件压缩包下载:
* 网页下载:https://download3.dfrobot.com.cn/K10/Mind%2B1.8.0_RC1.0_20241127.zip * 百度网盘下载:https://pan.baidu.com 提取码: 17d6
* 夸克网盘 下载
2.将压缩包解压,注意解压过程中关闭杀毒软件,解压后文件夹路径不含中文,解压后文件夹路径不宜过长
3.打开解压后的文件夹,找到 Mind+.exe,双击打开
4.若编译任何代码都报错,建议在解压时将所有后台的杀毒软件退出,将解压出的文件夹放到 C 盘根目录,文件夹的名字改为"win-ia32-unpacked20241012"。文件夹中的 exe 文件,不可直接拖到桌面,要右键-发送到桌面快捷方式。
注:不同行空板 K10 的设备名称可能不同,但都是以 K10 结尾。
软件基础使用
1、 打开 Mind+,切换到上传模式
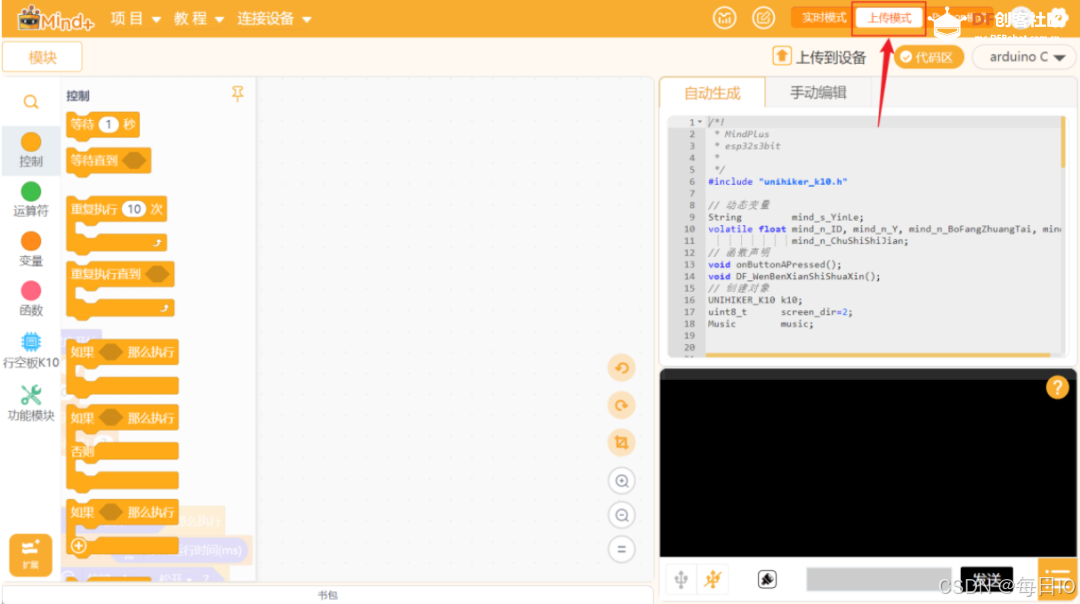
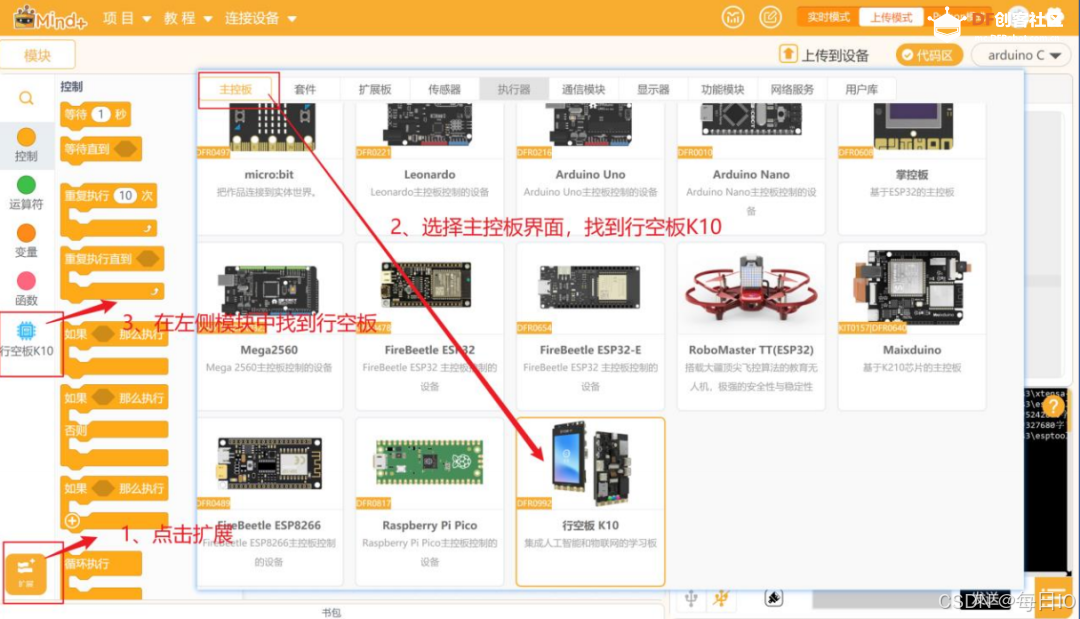
2、 加载行空板 K10
基于前面的操作,只需要点击“扩展库”,找到“官方库”下的“行空板”模块点击完成添加,点击返回后,就可以在“指令区”找到行空板 K10,完成行空板 K10 加载。
3、连接行空板K10
首先,你需要通过 USB 连接线将行空板 K10连接到计算机。
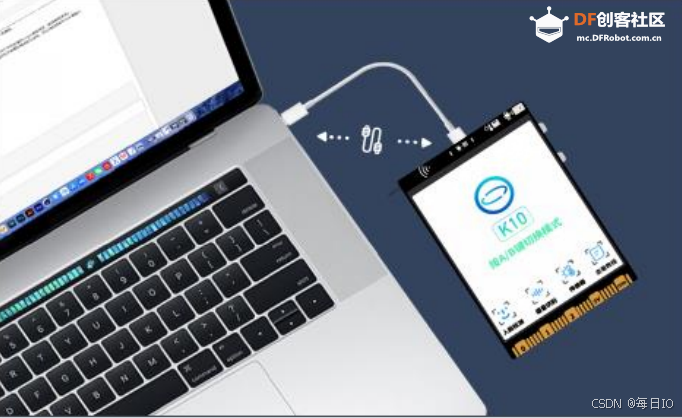
然后,点击连接设备后,点击 COM7-UNIHIKER K10 进行连接。
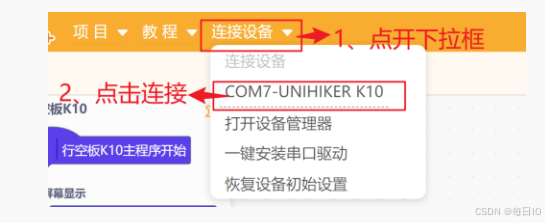
注:不同行空板 K10 的设备名称可能不同,但都是以 K10 结尾。
动手实践
接下来一起动手完成今天的课程任务吧。我们将从学会拍照存储开始,逐步学习如何在行空板K10上检测人脸关键点数据,并添加圣诞装饰贴纸。
任务一:拍摄、存储并显示照片
这一部分我们要调用人脸检测指令,将人像拍照存储到 TF 卡中,并在屏幕上进行显示。
任务二:人脸关键点检测
这一部分我们要检测人脸关键点数据,包括五官坐标和人脸大小。
任务三:圣诞贴纸装饰
这一部分我们要实现能够根据五官坐标和人脸大小调整贴纸坐标,使得圣诞装饰效果贴合人脸。
任务一:拍摄、存储并显示照片
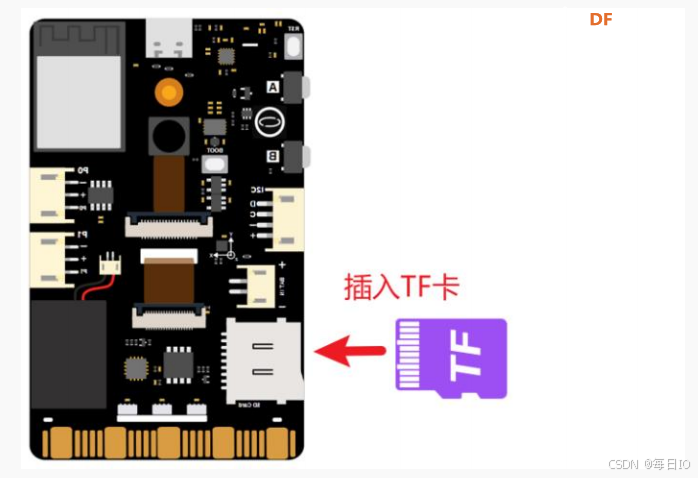
1、 硬件搭建
将 TF 卡插入到行空板 K10 卡槽当中,确认使用 USB 连接线将行空板 K10 连接到计算机,
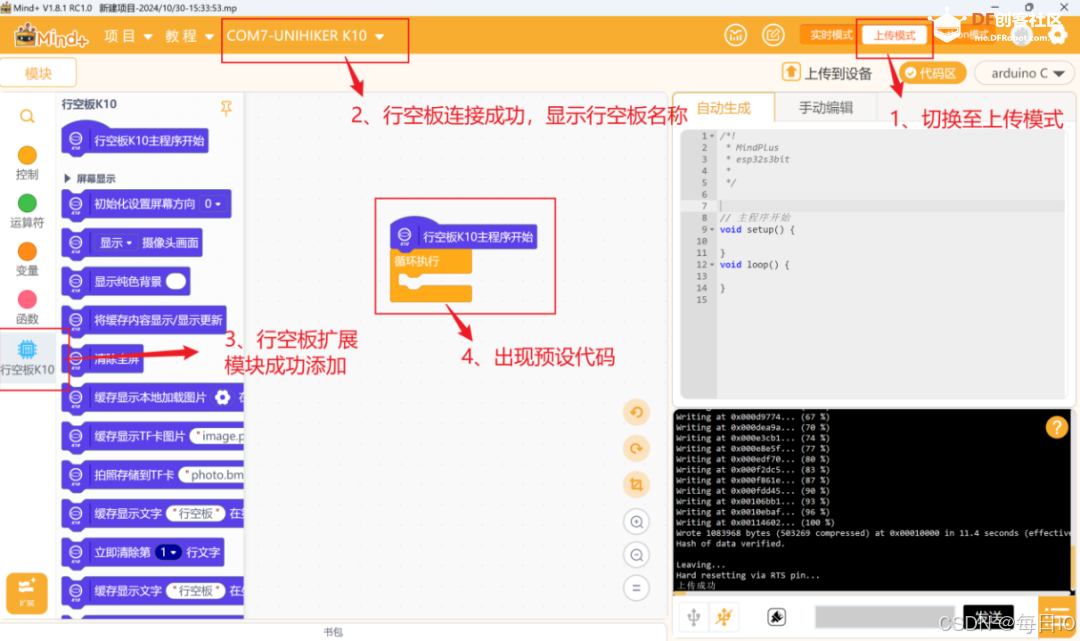
2、 软件准备
确认已打开 Mind+,在 Python 图形化模式下出现预设代码,成功加载行空板。接下来就可以编写项目程序了。
3、 编写程序
STEP1:调用人脸检测指令
我们需要先使用指令 显示摄像头画面 指令,在行空板 K10 屏幕上显示摄像头画面。
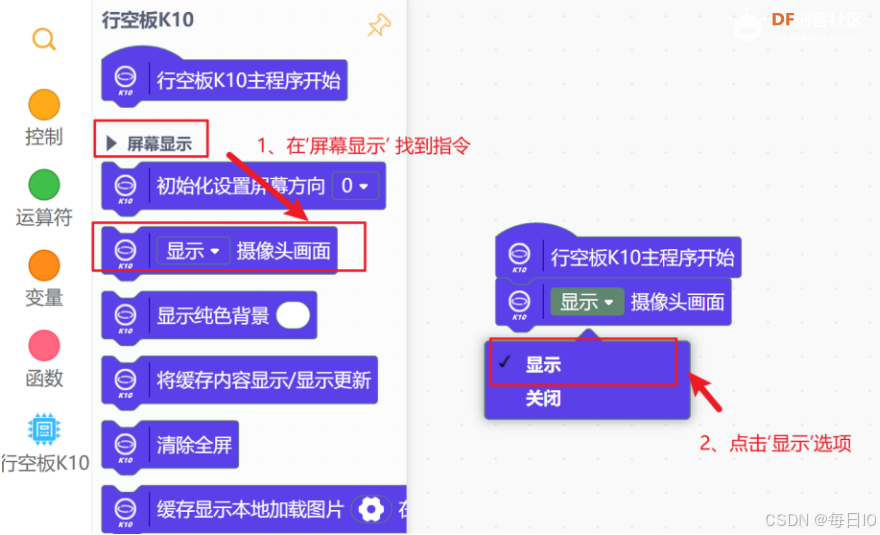
注:关于摄像头指令,详见知识园地。
开启摄像头之后,我们找到 切换为人脸检测模式 指令,将摄像头切换为人脸检测的模式。
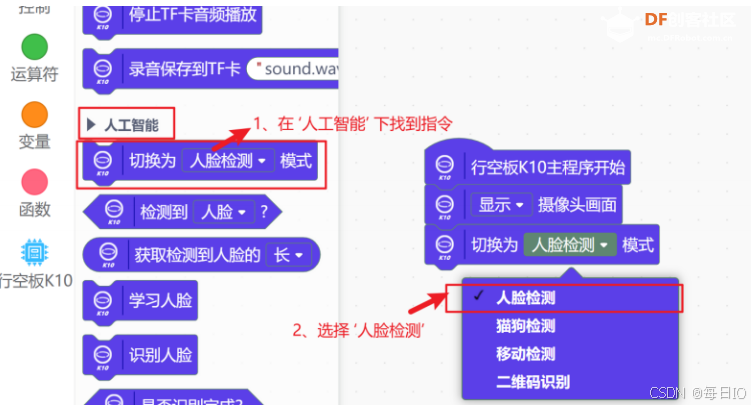
注:关于人脸检测指令,详见知识园地。
STEP2:拍摄、存储并显示照片
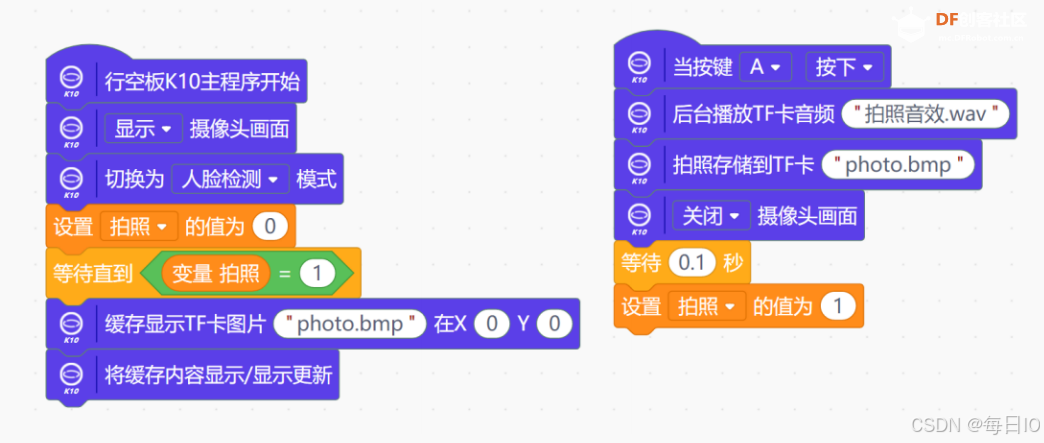
我们需要使用事件回调函数,使用 当按键 A 按下 指令,然后使用 后台播放 TF 卡音频() 指令,模拟相机拍照的音效,接着使用 拍照存储到 TF 卡() 指令,将照片拍摄存储到 TF 卡当中。
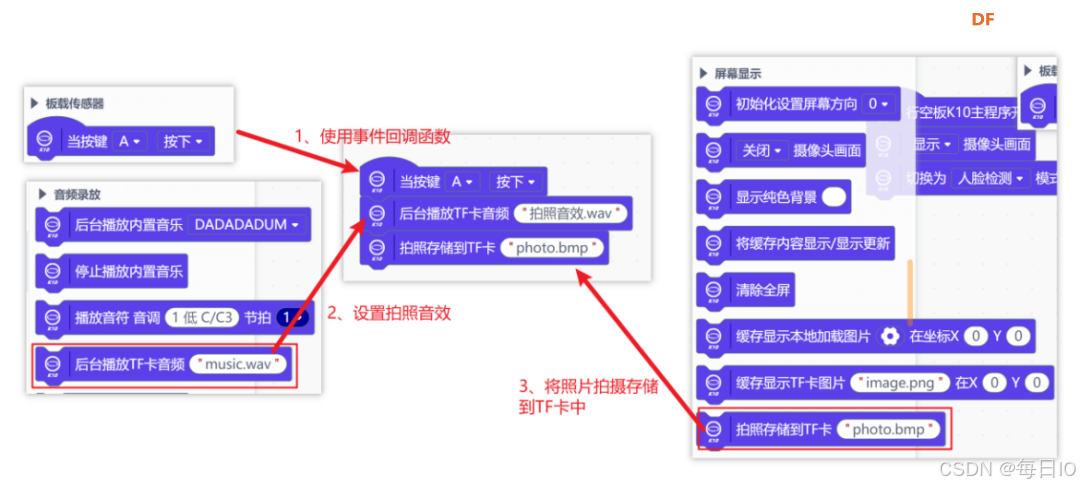
我们需要在拍摄照片之后,再将内存卡中的照片进行展示,因此,我们需要用一个变量 “拍照” 来判断是否完成了拍照,当拍照完成之后,我们关闭摄像头画面,并用 缓存显示 TF 卡图片()在 X0Y0 指令在屏幕上显示刚拍下的照片。
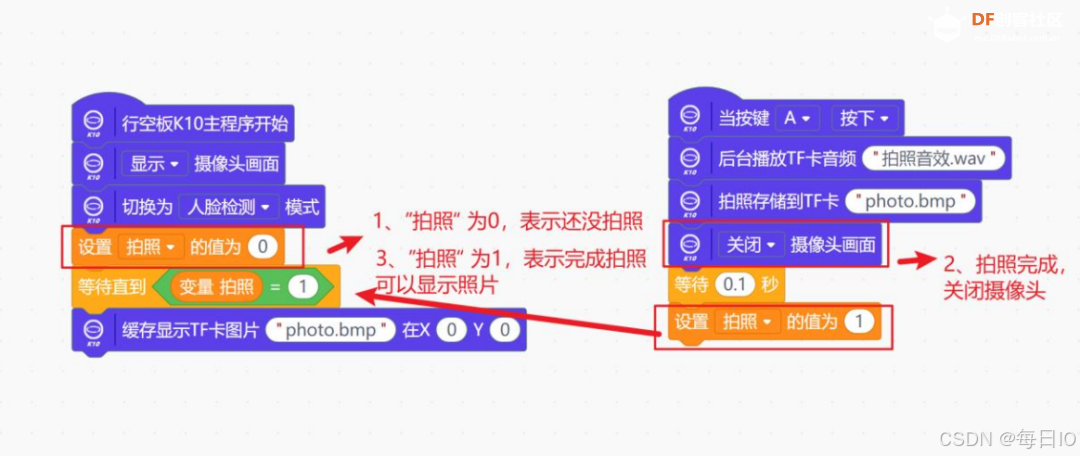
这样,我们就实现了拍摄、存储照片,并将其显示在屏幕上,完整代码如下图:
4、 程序执行
STEP1:检查并保证行空板 K10 已连接 Mind+,即在“菜单栏”部分显示 IP;

STEP2:点击界面右上方的上传到设备按钮;

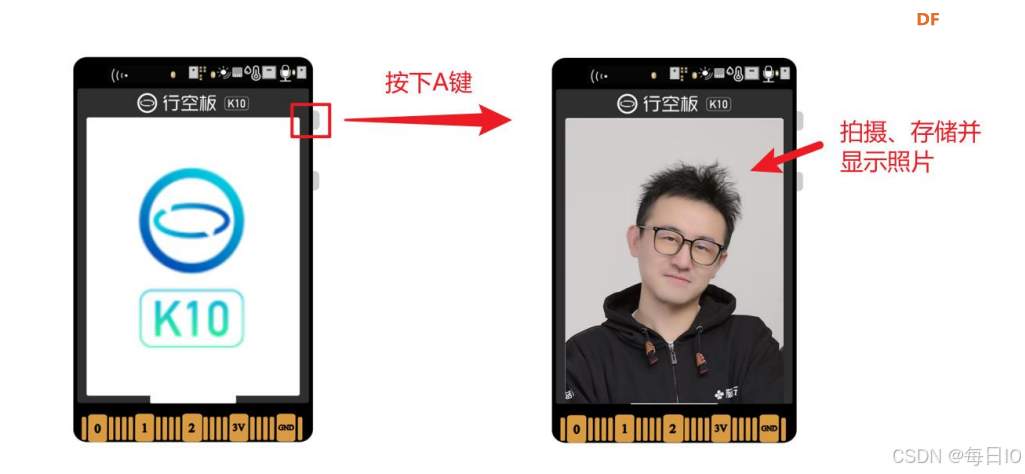
STEP3:运行程序,出现摄像头画面,当按下 A 键的时候,拍下照片,并将照片显示在屏幕上,如下图所示:
任务二:人脸关键点检测
1、 编写程序
STEP1:获取人脸关键点数据
在行空板 K10 中,提供了检测人脸关键点数据的指令,我们可以使用 获取检测到人脸的() 指令,来获取五官坐标以及人脸的大小,同时,我们创建相应的变量来存储人脸的关键点数据。我们将指令封装到函数“人脸关键点检测“中。
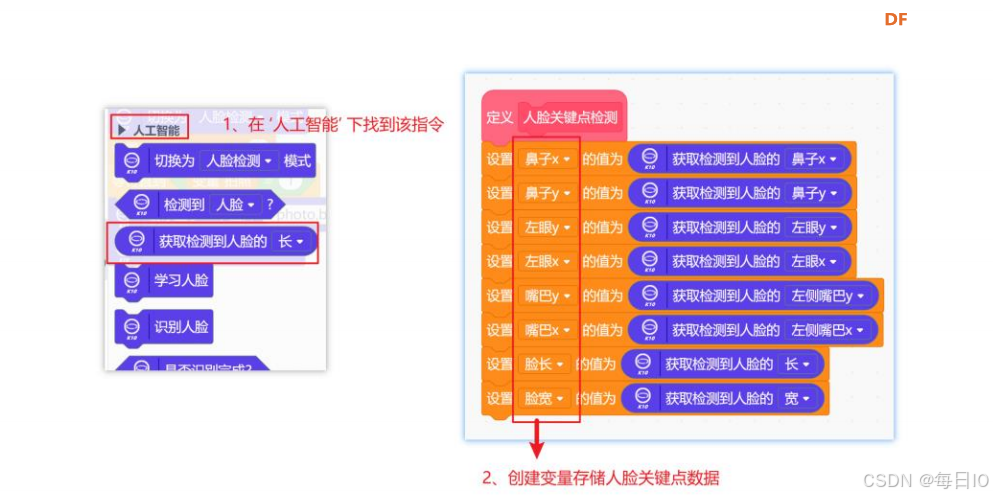
注:关于人脸关键点数据检测指令,详见知识园地。
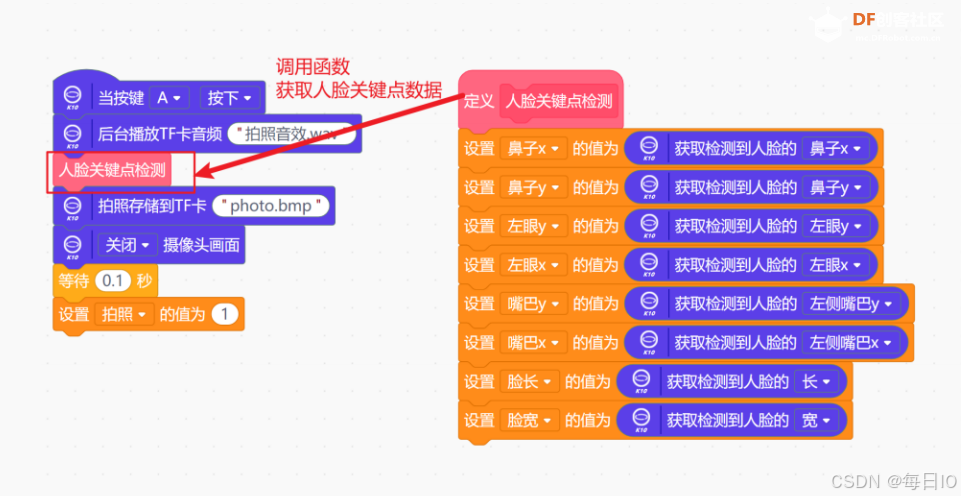
我们要获取到所拍下照片的人脸关键点数据,因此,在事件回调函数“当按下 A 键“ 中,我们需要调用 ”人脸关键点检测“ 函数,获得拍摄照片的人脸关键点数据。
STEP2:显示人脸关键点数据
为了确定圣诞贴纸的位置,我们需要知道前面所获得的人脸关键点数据,因此,我们需要让人脸关键点数据跟随照片一起显示,在上一步,我们已经将人脸关键点的数据存储在相对应的变量之中,因此,我们使用 缓存显示文字()在坐标 X0Y0 字号()颜色() 指令,将数据进行显示,指令如下。
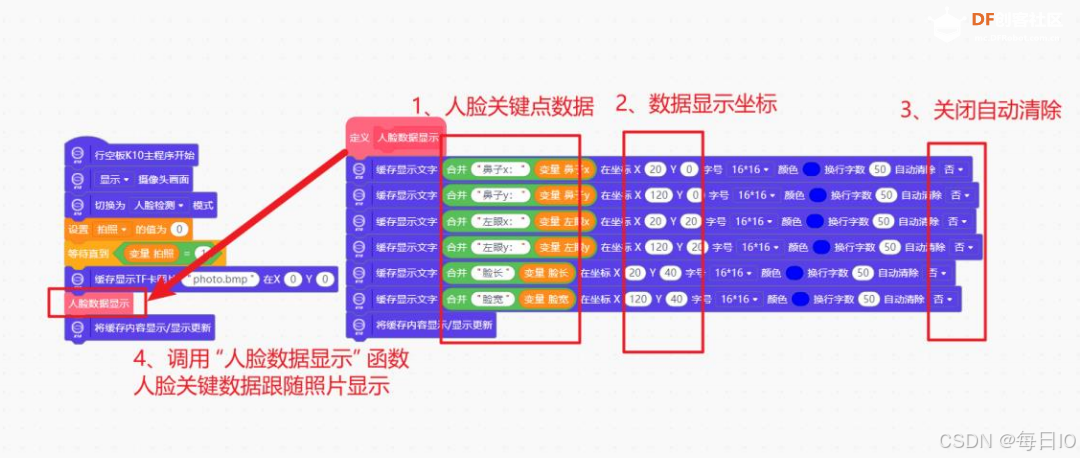
人脸关键点检测模块完整程序代码如下:
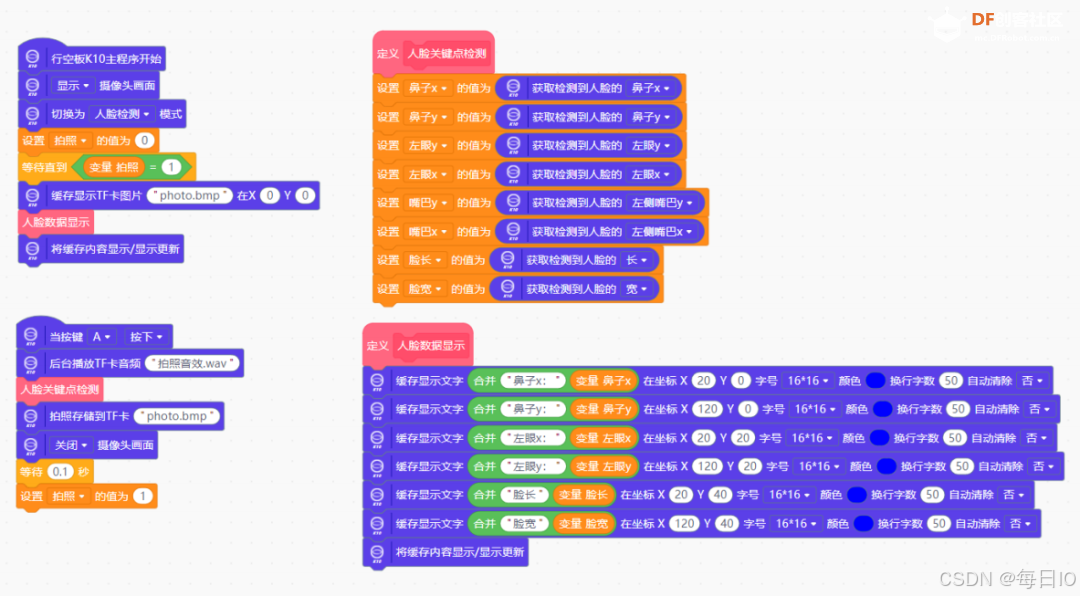
2、程序运行
STEP1:连接行空板 K10
STEP2:点击界面右上方的“上传到设备”按钮
STEP3:按下 A 键,观察屏幕,可以看到人脸关键点数据跟随照片一起显示。

任务三:圣诞贴纸装饰
在这个任务中,我们需要根据五官坐标和人脸大小调整贴纸坐标和大小,使得圣诞装饰效果贴合人像。
1、 编写程序
STEP1:调整贴纸位置
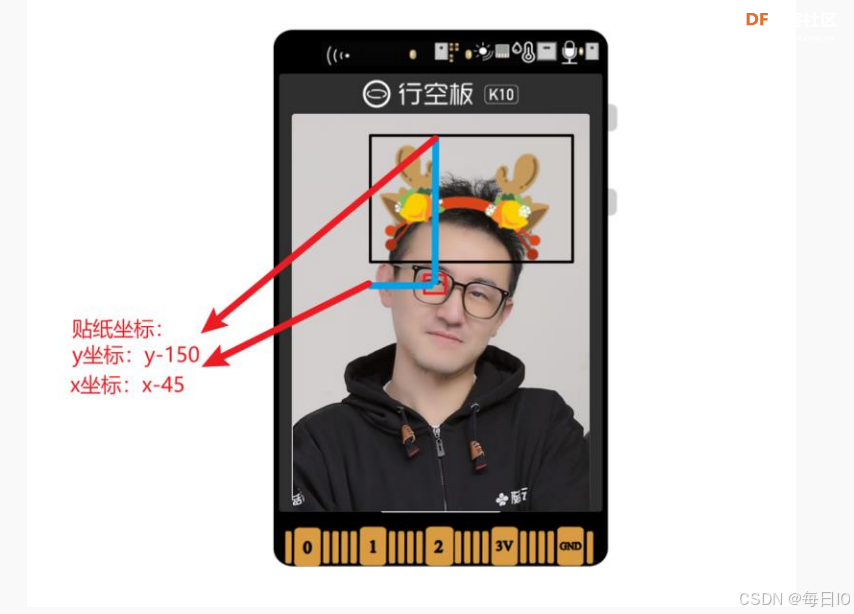
我们以“鹿角贴纸”为例子,我们要根据人脸的不同位置,调整贴纸的坐标。为了确定人脸的位置,我们需要选取前面的一个人脸关键点数据作为参考点。这里,我们选取“左眼”的 X、Y 坐标,来确定 “鹿角贴纸“的所在位置。

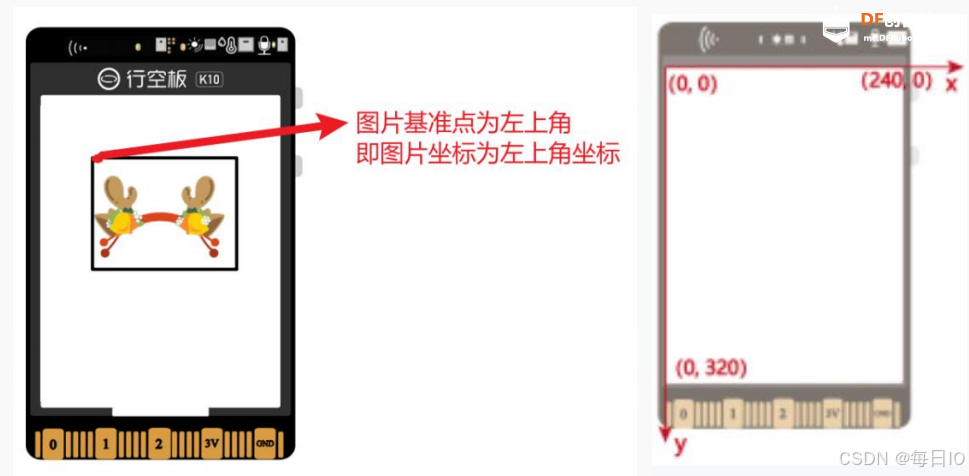
要注意,在行空板 K10 中,图片的基准点是位于左上角,即图片的 X、Y 坐标实际上是图片左上角所在位置,这能帮助我们更好地调整贴纸坐标。另外,当行空板方向为竖直正向时,屏幕坐标的对应图如下所示。
经过调整之后,我们确定了“鹿角贴纸“的 X、Y 坐标以左眼作为参考系的相对坐标位置。X 坐标为(左眼 X-45),y 坐标为(左眼 y-150),程序指令如下所示。
STEP2:根据脸的尺寸调整贴纸大小
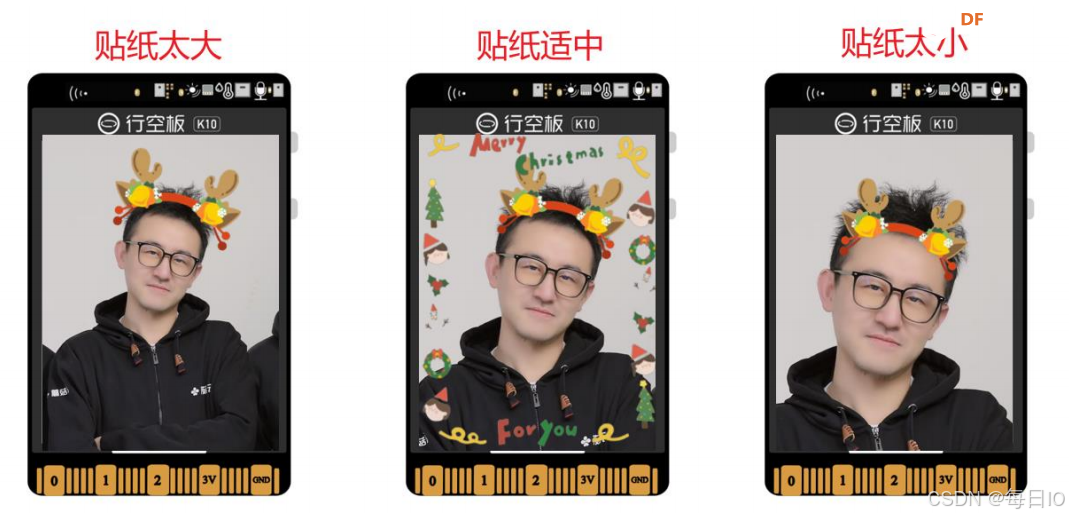
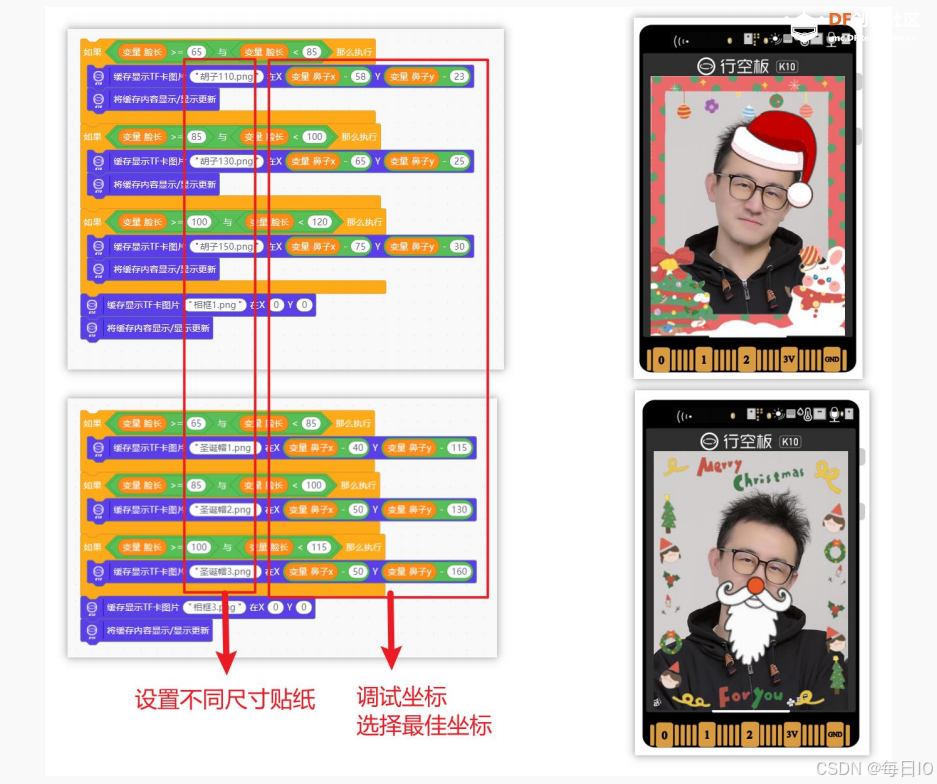
在实际拍摄中,人脸的尺寸大小是不同的,因此,不能简单地将贴纸作为一张固定尺寸的图片,贴在人脸上,如下图,是同一个贴纸在不同尺寸人脸的效果,可以看到,这是很不自然的效果。
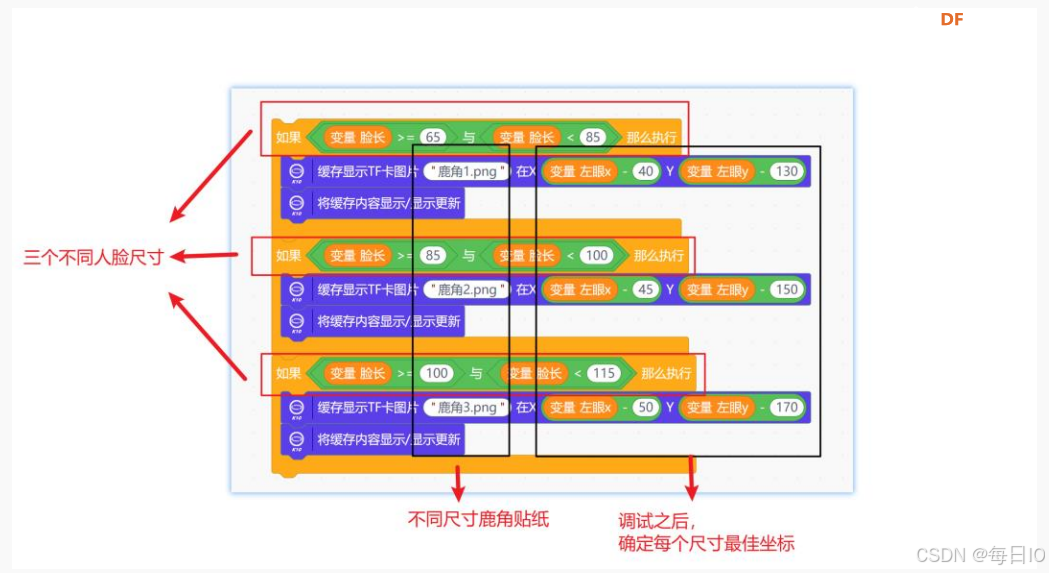
因此,我们需要根据不同人脸的尺寸,调整贴纸的大小。通过 “脸长” 这一参数,对人脸尺寸进行判断,根据不同尺寸的人脸,我们需要有对应不同尺寸的贴纸。在这里,我们依据“脸长”,将脸长分为三个不同的梯度:65-85、85-100、100-115,同时,设置三种不同尺寸的“鹿角贴纸”。

我们使用条件判断语句,对于三个不同尺寸的脸,分别显示不同大小的“鹿角贴纸。需要注意的是,三个不同的尺寸下,贴纸的 x、y 坐标是不同的,需要进行调试,在多次调试之后确定每个尺寸贴纸的最佳 x、y 坐标,相关的程序指令如下。
为了让照片更有氛围,我们需要给图片添加一个圣诞边框,同时,我们设置当按下 B 键时,清除屏幕上人脸关键点数据,并显示圣诞贴纸。为了提高主程序的易读性,我们将上一步切换贴纸的指令集成在“特效”函数中。程序指令如下所示。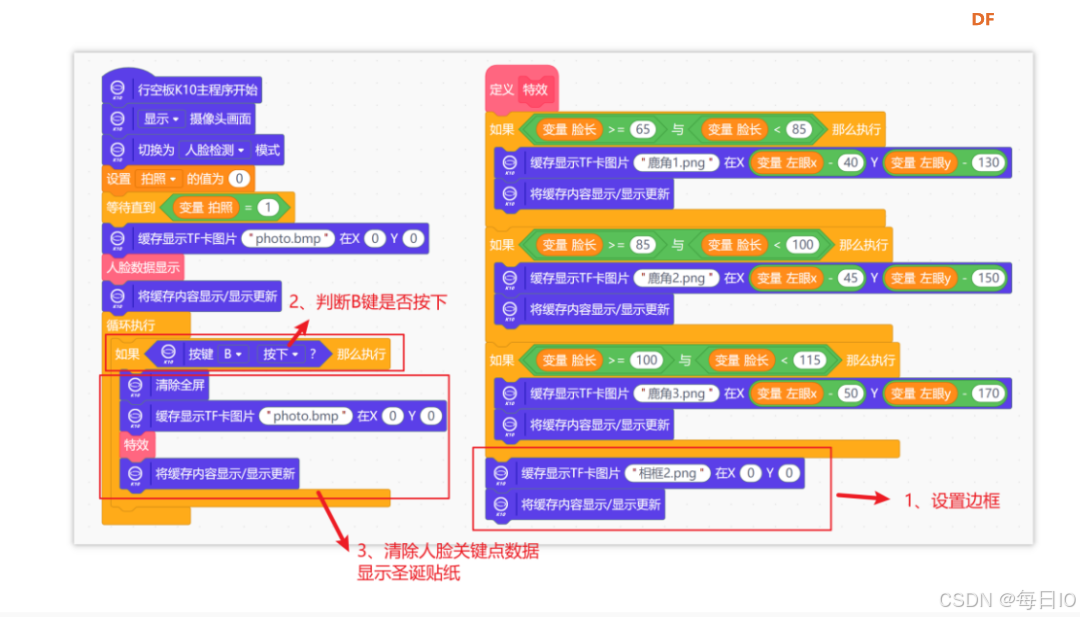
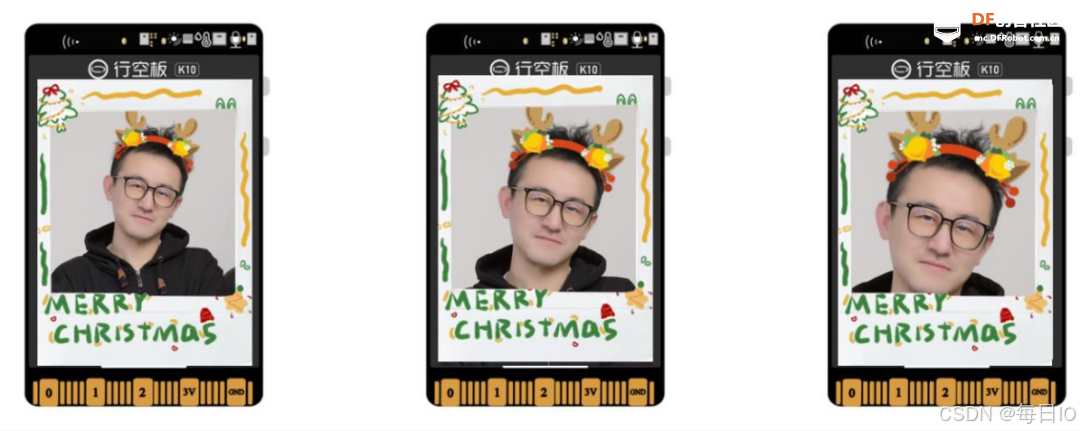
效果图如下所示:
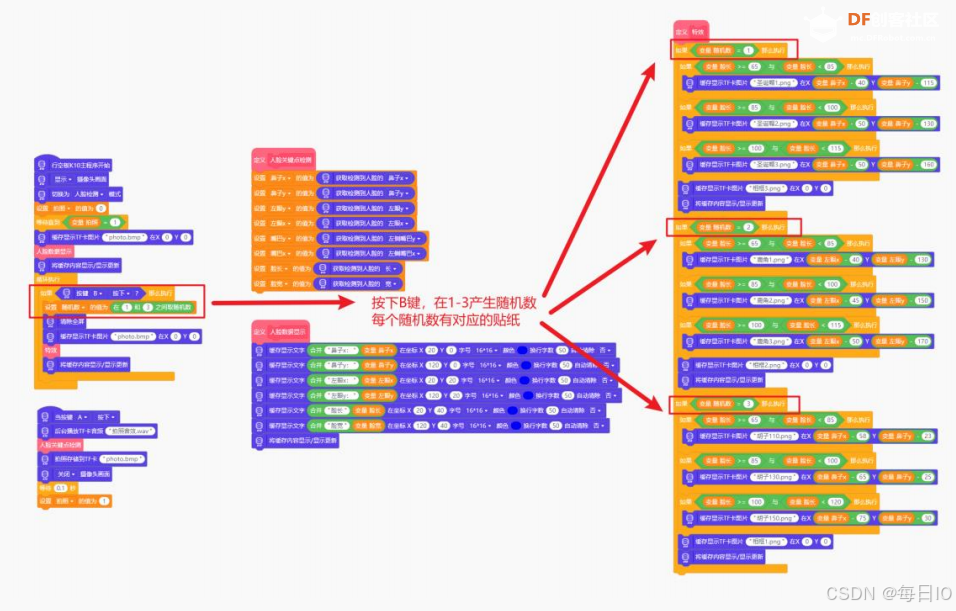
SETP3:随机切换圣诞贴纸
要切换不同的圣诞贴纸,首先我们需要按照上一步的操作,将其他风格的圣诞贴纸也根据不同尺寸的脸调整大小,同时调试坐标以使得贴纸更加自然,相关程序如下。
为了能够随机切换不同风格的圣诞贴纸,我们定义一个变量“随机数”,当按下 B 键的时候,“随机数”会在 1-3 中产生一个数,而 1-3 分别代表三种不同风格的圣诞贴纸,完整的程序指令如下所示。
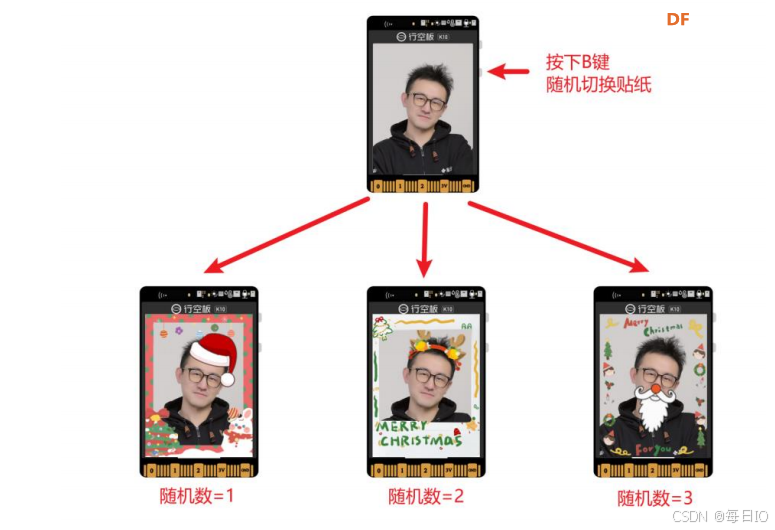
2、 运行程序
点击上传到设备,完成拍照之后,按下 B 键,可以随机切换不同风格的圣诞贴纸,效果如下。
知识园地
1、 摄像头指令

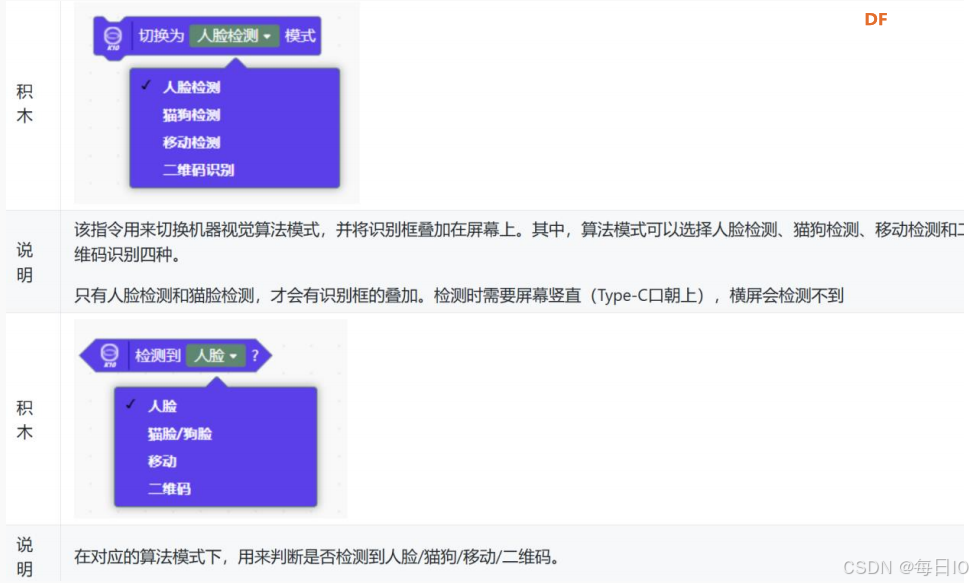
2、人脸检测指令
3、人脸关键点数据检测指令

本转载内容仅供学习,学习素材包,请至原文下载

















 789
789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









