






目录
初级
一.初识ElasticSearch
略
二.安装ElasticSearch
1.本机安装
ElasticSearch下载解压即用,如果是卸载,那就先停掉ElasticSearch的服务,然后删除ElasticSearch安装目录下的所有文件及文件夹即可。
Kinaba也是下载解压即用。
ik分词器需要放在ElasticSearch的Pluging目录下。
2.Linux操作系统安装
略。
三.ElasticSearch核心概念
1.索引(index)
ES中的索引相当于关系型数据库MySQL中数据库的概念,索引就是ES存储数据的地方。
2.映射(mapping)
mapping定义了每个字段的类型、字段所使用的分词器。相当于关系型数据库MySQL的表结构的概念。
3.类型(type)----逐渐被弱化的概念
type就像关系型数据库MySQL中的表,如用户表、商品表等。在ElasticSearch7.x中默认的type为_doc。
在ElasticSearch5.x中,一个索引下可以有多张表,建表时必须给表取表名且每张表的表名唯一;
在ElasticSearch6.x中,一个索引下只有一张表,建表时必须给表取表名;
在ElasticSearch7.x中,一个索引下只有一张表,建表时不能给表取表名,默认表名为_doc。
4.文档(document)
ES中最小的数据单元,常以Json格式显示,一个document相当于关系型数据库MySQL中的一行数据。
5.倒排索引
一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,对应一个包含这个词的文档id列表。
问:ElasticSearch为什么查询快?
答:ElasticSearch的数据依旧是存储在磁盘中的,快是因为建立B+树形势的倒排索引快速筛出无用数据,不同于Redis的快,Redis是将数据缓存到内存中才快的。
四.操作ElasticSearch
1.索引操作
Restful风格定义:

1.1.关闭索引(在PostMan上操作的)
语法及例子:
语法:
网络协议://IP地址:端口号/索引名称/_close
例子:
http://localhost:9200/users/_close
关闭某个索引后,这个索引就不能再被访问到了,也不能对这个索引里的内容进行操作,除非将该索引再打开
解释:
_close这种下划线开头的命令是ElasticSearch封装后提供的高效命令1.2.打开索引(在PostMan上操作的)
例子:
http://localhost:9200/users/_open1.3.查询全部索引(在PostMan上操作的)
例子:
http://localhost:9200/_all1.4.补充

2.映射操作
2.1.数据类型介绍

2.2.操作(在Kibana上操作)
2.2.1.创建索引
#创建索引
PUT person2.2.2.为索引添加映射关系(方式一)
#添加映射关系的方式一
PUT person/person/_mapping
{
"properties":{
"name":{
"type": "keyword"
},
"age":{
"type": "integer"
}
}
}2.2.3.为索引追加映射关系
#给已知的映射追加字段
PUT person/person/_mapping
{
"properties": {
"id":{
"type": "long"
}
}
}2.2.4.查询索引
#查询索引(查询出来的是该索引下的所有关系)
GET person2.2.5.查询索引下的映射
#查询索引下的映射
GET person/_mapping2.2.6.删除索引
#删除索引
DELETE person2.2.7.添加映射关系的第二种方式
ElasticSearch6.X时,POST people后面必须有“/xxx”,否则出错
#添加映射关系的方式二
#创建索引并添加映射
POST people/man
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"ages":{
"type": "integer"
},
"id":{
"type": "long"
}
}
}
}
#查询索引(查询出来的是该索引下的所有关系)
GET people
#查询索引下的映射
GET people/_mapping
#删除索引
DELETE people
3.文档操作
3.1.添加文档(2种方式)
#添加文档时指定id,可以用post请求或put请求
PUT person/_doc/1
{
"name":"张三",
"age":22,
"id":1
}
#添加文档时不指定id则必须用post请求,用内置id创建索引文档
POST person/_doc
{
"name":"李四",
"age":33,
"id":3
}3.2.查询文档
根据id查询
全部查询
#根据ID去查询文档
GET person/_doc/1
#查询文档(表)全部信息
GET person/_search3.3.修改文档
全局修改
局部修改
#全局修改文档,会将之前的字段信息全部覆盖
#由于修改文档的语法和添加文档的语法一致,所以如果该ID对应的文档对象是存在的就修改,不存在就添加
PUT person/_doc/1
{
"name":"张三777",
"age":22,
"id":1
}
#局部修改文档,不会将之前的字段信息全部覆盖
#如果本次修改包含文档在本次修改之前不存在的字段,那么自动将字段添加到映射下,字段对应的值添加到文档中
POST /person/person/1/_update
{
"doc":{
"id" : 99,
"username": "xx"
}
}3.4.删除文档
#根据id删除文档
DELETE person/_doc/14.分词器
定义
4.1.标准分词器(对中文不友好)

4.2.IK分词器(对中文友好)
4.2.1.定义
4.2.2.安装:略
4.2.3.使用:
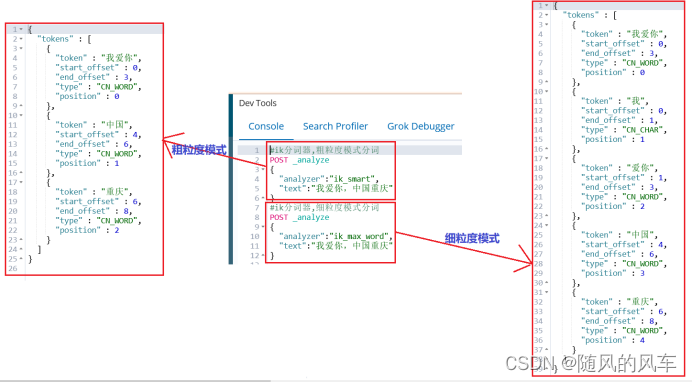
两种模式
粗粒度模式和细粒度模式
#ik分词器,粗粒度模式分词
POST _analyze
{
"analyzer":"ik_smart",
"text":"我爱你,中国重庆"
}
#ik分词器,细粒度模式分词
POST _analyze
{
"analyzer":"ik_max_word",
"text":"我爱你,中国重庆"
}
如图
4.2.4.利用IK分词器进行文档查询
4.2.4.1.term查询----词条查询:不会分析查询条件,只有当词条和查询字符串完全匹配时才匹配搜索
问题一:为什么回出现以下情况?
分词器问题,当前索引用的是默认starand分词器,这个分词器会把中文词条分词成一个字一个字的样子,这样会把"华为手机"分词成"华"、"为"、"手"、"机",而不是分词成"华为"、"手机",所以查"华为"这个词时,查不到,查"华"一个字时,却能查到。
错误查询(用的starand分词器)
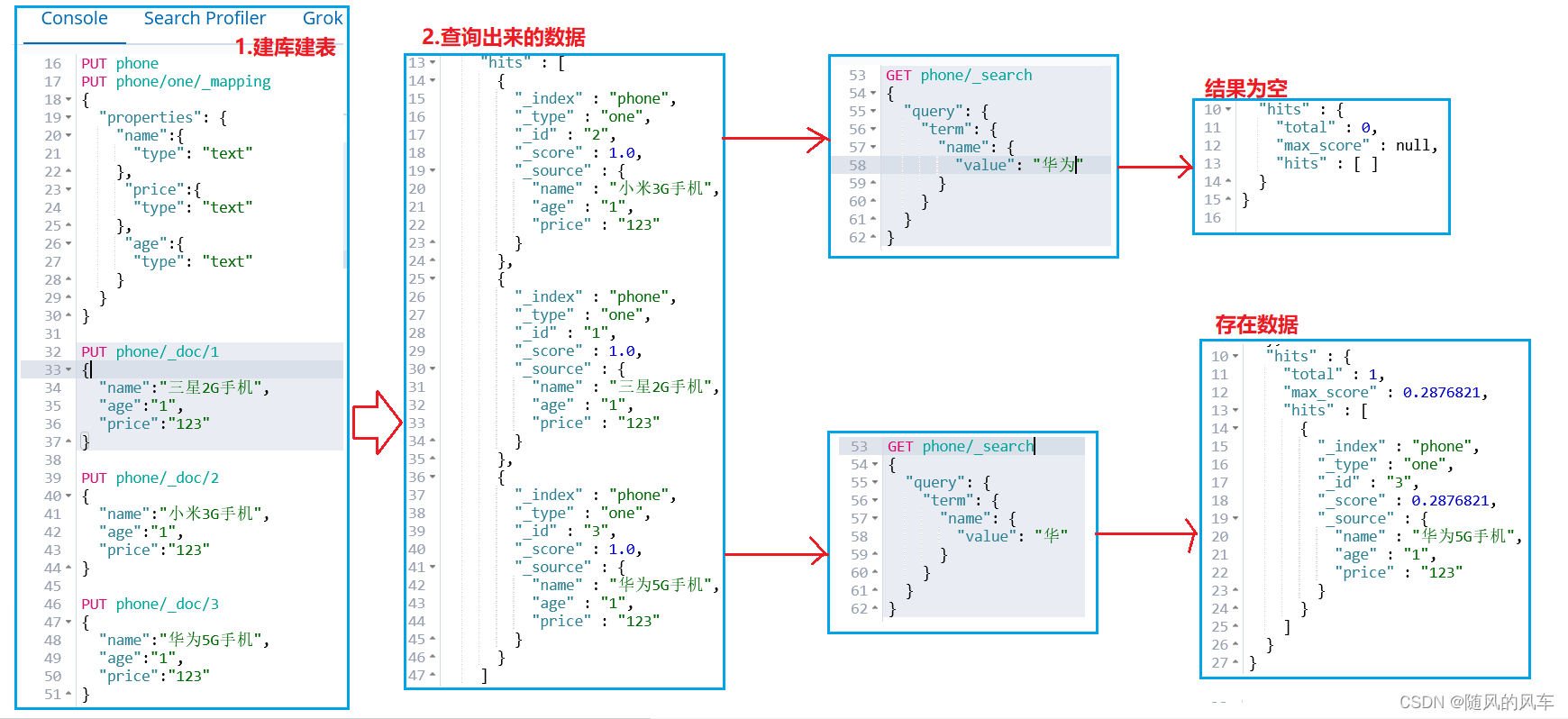
如果在创建索引时只创建了name和age映射,但是添加数据时出现了第三个映射关系detail,那么ES会动态地在这张表里去创建detail映射。
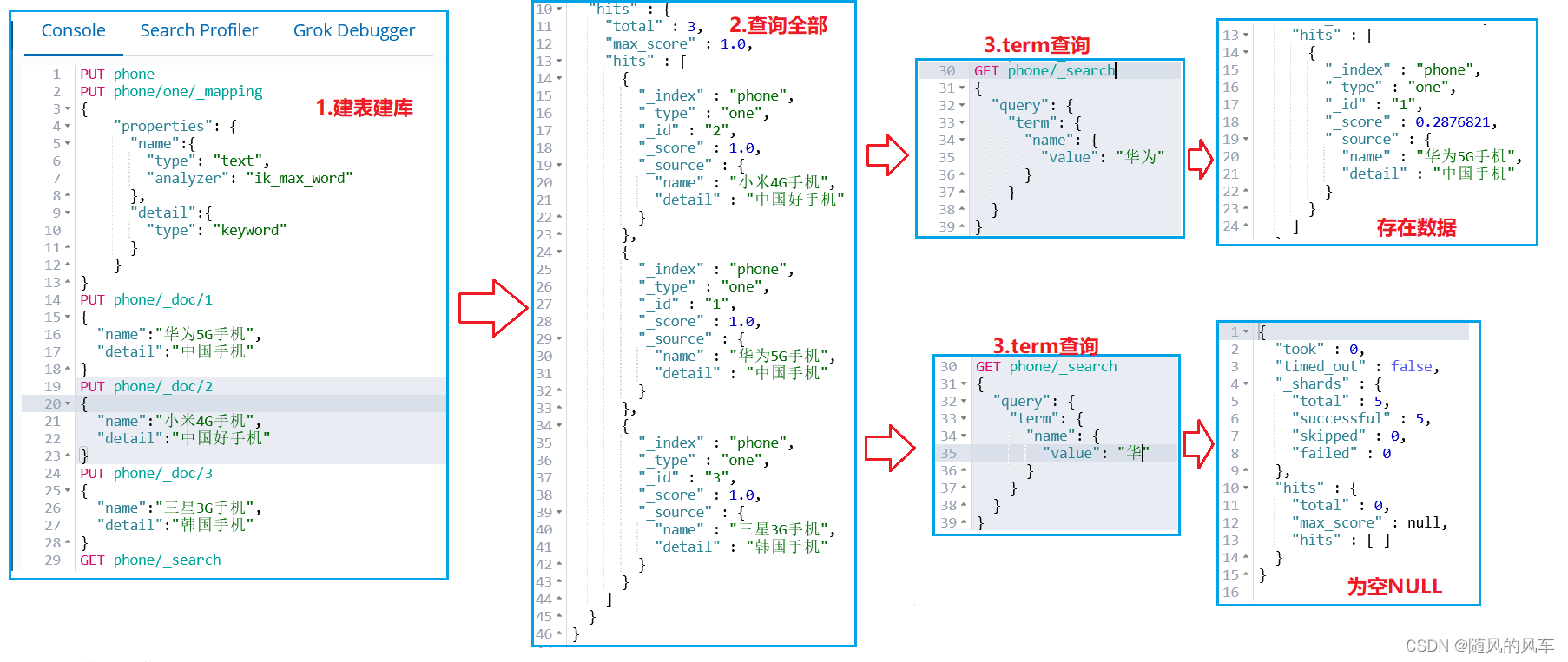
正确查询(用的iK分词器)
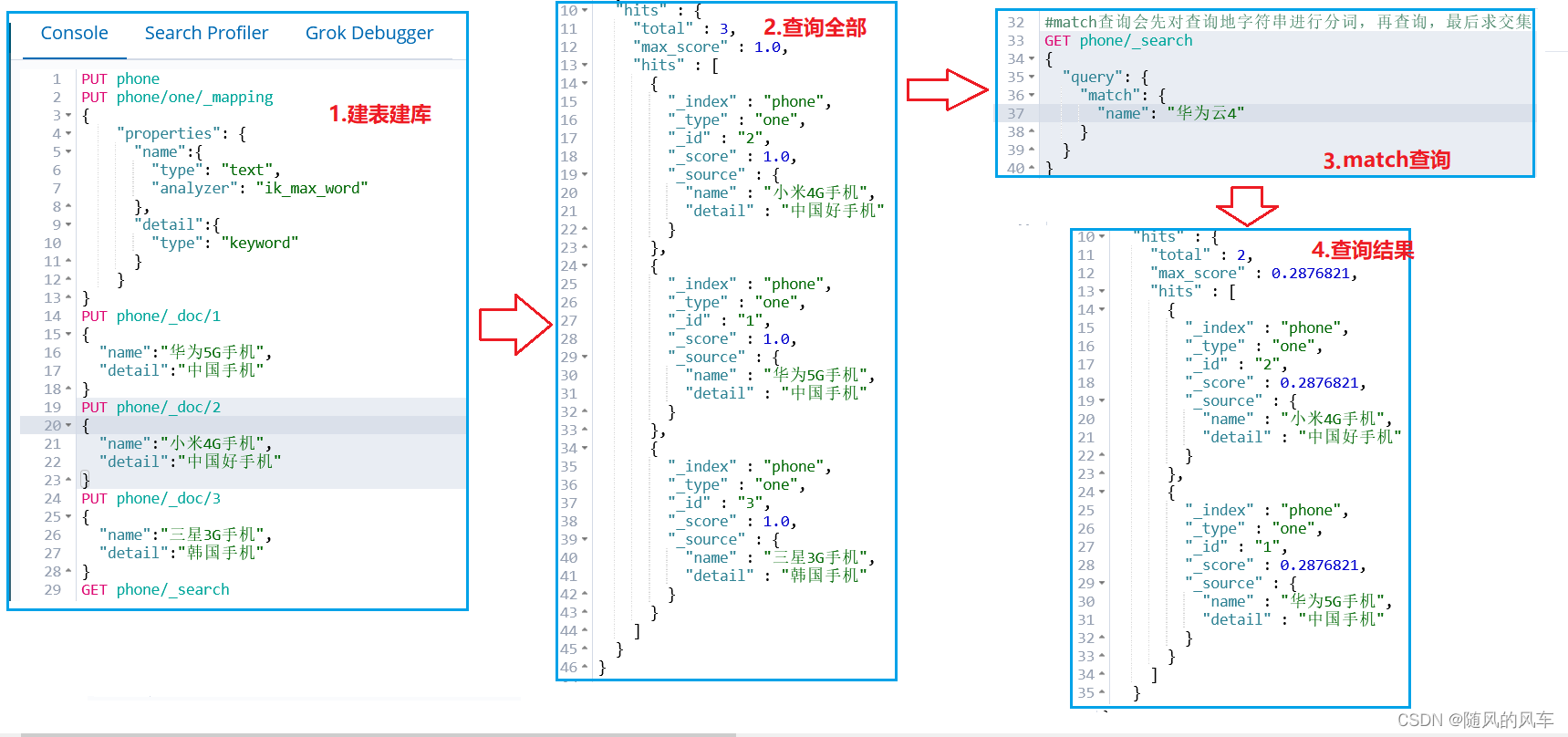
4.2.4.2.match查询----全文查询:先分析查询条件,先将查询条件进行分词,再查询,最后求并集
五.ElasticSearch JavaApi
1.SpringBoot整合ElasticSearch
第一步:创建一个maven项目
第二步:导入相关依赖
一定要引入ElasticSearch的相关依赖(3个)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.zcj</groupId>
<artifactId>TestElasticSearch</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<!--将org.springframework.boot项目作为当前项目的父项目-->
<parent>
<artifactId>spring-boot-parent</artifactId>
<groupId>org.springframework.boot</groupId>
<version>2.0.5.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--3个elasticsearch依赖-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.4.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.4.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.4.0</version>
</dependency>
<!--必须要@SpringBootTest-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-test</artifactId>
</dependency>
<!--@SpringBootApplication-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-autoconfigure</artifactId>
</dependency>
<!--@RunWith和@Test-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
</dependency>
<!--@RunWith(SpringRunner.class)中SpringRunner需要这个依赖-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
</dependency>
<!--2个日志依赖-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.10.0</version>
</dependency>
<!--对象转JSON用的依赖-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.4</version>
</dependency>
</dependencies>
</project>第三步:准备一个application.yml配置文件,文件里面的内容如下:

参数解释:为了能够访问到安装了ElasticSearch的服务器,必须知道服务器的IP地址和端口号,127.0.0.1是当前计算机的IP地址,等价于localhost;9200是端口号。
第四步:准备SpringBoot项目的启动类
package cn.zcj;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class ESApp {
public static void main(String[] args) {
SpringApplication.run(ESApp.class);
}
}
第五步:准备一个配置类,这个配置类的作用是将前文提到的application.yml配置文件中的配置信息读取出来,并利用配置信息构建ElasticSearch客户端对象,将构建出来的对象通过@Bean这个注解让该对象可以被Spring容器管理。
RestHighLevelClient对象解释:
RestHighLevelClient从字面意思理解就是restful风格的高级别的客户端,RestHighLevelClient 底层封装的是一个http连接池,当需要执行 update、index、delete操作时,直接从连接池中取出一个连接,然后发送http请求到ElasticSearch服务端,服务端基于Netty接收请求。新版本的elasticsearch java client 都会推荐用RestHighLevelClient去连接ES集群,放弃掉之前的transport client的方式。
package cn.zcj.esConfig;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticSearchConfig {
@Value("${elasticsearch.host}")
private String host;
@Value("${elasticsearch.port}")
private int port;
public String getHost() {
return host;
}
public void setHost(String host) {
this.host = host;
}
public int getPort() {
return port;
}
public void setPort(int port) {
this.port = port;
}
@Bean
public RestHighLevelClient clientSingle(){
return new RestHighLevelClient(RestClient.builder(
new HttpHost(host,port,"http")
));
}
}
第六步
2.索引操作
2.1.添加索引(创建索引)
2.1.1.仅添加索引
2.1.2.添加索引并添加指定映射关系
2.2.查询索引
2.3.删除索引
2.4.判断索引是否存在
package cn.zcj.esDemo;
import cn.zcj.ESApp;
import cn.zcj.esConfig.ElasticSearchConfig;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.client.*;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.client.indices.GetIndexResponse;
import org.elasticsearch.cluster.metadata.MappingMetaData;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.io.IOException;
import java.util.Map;
@RunWith(SpringRunner.class)
//用了这个注解后,就不用专门去启动启动类,该测试启动时会带着启动类一起启动
@SpringBootTest(classes = ESApp.class)
public class EStest {
@Autowired
private ElasticSearchConfig myclient;
private RestHighLevelClient client;
@Test
public void contextLoads(){
/*//创建ES客户对象
RestHighLevelClient client=new RestHighLevelClient(RestClient.builder(
new HttpHost("127.0.0.1",9200,"http")
));*/
System.out.println(myclient.clientSingle());
}
//添加索引
@Test
public void addIndex() throws IOException {
//1.通过配置类获取RestHighLevelClient对象
client = myclient.clientSingle();
//2.使用client获取操作索引对象
IndicesClient indicesClient = client.indices();
//3.具体操作,获取返回值,这里建库取名字不可以有大写字母
CreateIndexRequest createRequest = new CreateIndexRequest("zcj");
CreateIndexResponse response = indicesClient.create(createRequest, RequestOptions.DEFAULT);
//4.根据返回值判断结果
System.out.println(response.isAcknowledged());
}
//添加索引并添加指定映射关系
@Test
public void addIndexAndMapping() throws IOException {
//1.通过配置类获取RestHighLevelClient对象
client = myclient.clientSingle();
//2.使用client获取操作索引对象
IndicesClient indicesClient = client.indices();
//3.具体操作,获取返回值,这里建库取名字不可以有大写字母
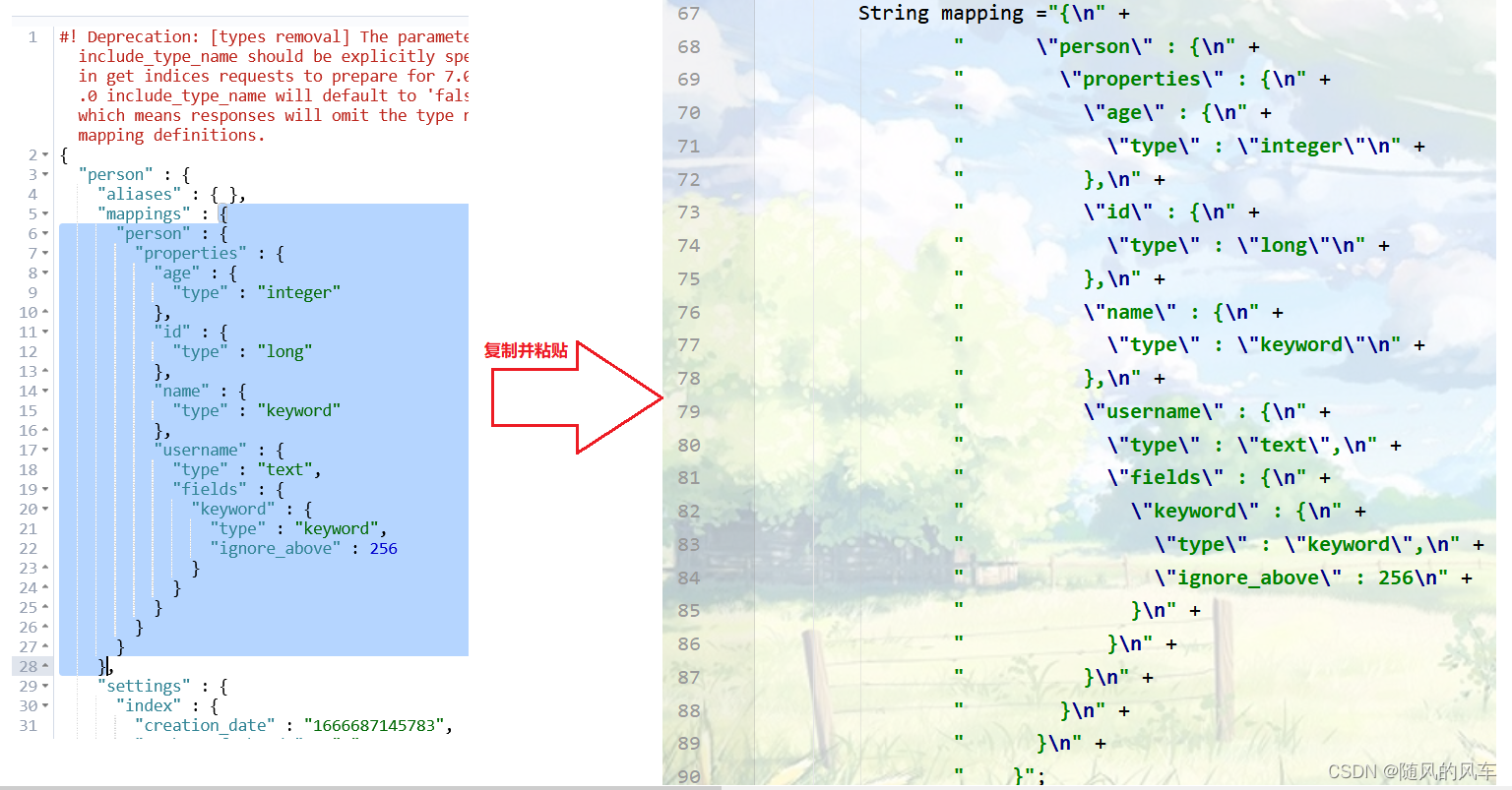
CreateIndexRequest createRequest = new CreateIndexRequest("zr");
//3.1.设置mappings
String mapping ="{\n" +
" \"person\" : {\n" +
" \"properties\" : {\n" +
" \"age\" : {\n" +
" \"type\" : \"integer\"\n" +
" },\n" +
" \"id\" : {\n" +
" \"type\" : \"long\"\n" +
" },\n" +
" \"name\" : {\n" +
" \"type\" : \"keyword\"\n" +
" },\n" +
" \"username\" : {\n" +
" \"type\" : \"text\",\n" +
" \"fields\" : {\n" +
" \"keyword\" : {\n" +
" \"type\" : \"keyword\",\n" +
" \"ignore_above\" : 256\n" +
" }\n" +
" }\n" +
" }\n" +
" }\n" +
" }\n" +
" }";
createRequest.mapping(mapping, XContentType.JSON);
CreateIndexResponse response = indicesClient.create(createRequest, RequestOptions.DEFAULT);
//4.根据返回值判断结果
System.out.println(response.isAcknowledged());
}
//查询索引
@Test
public void queryIndex() throws IOException {
//1.通过配置类获取RestHighLevelClient对象
client = myclient.clientSingle();
//2.使用client获取操作索引对象
IndicesClient indicesClient = client.indices();
GetIndexRequest getRequest = new GetIndexRequest("zr");
GetIndexResponse response = indicesClient.get(getRequest,RequestOptions.DEFAULT);
//获取结果
Map<String, MappingMetaData> mappings = response.getMappings();
for (String key:mappings.keySet()) {
System.out.println(key+":"+mappings.get(key).getSourceAsMap());
}
}
//删除索引
@Test
public void deleteIndex() throws IOException {
//1.通过配置类获取RestHighLevelClient对象
client = myclient.clientSingle();
//2.使用client获取操作索引对象
IndicesClient indicesClient = client.indices();
DeleteIndexRequest deleteRequest = new DeleteIndexRequest("zcj");
AcknowledgedResponse response = indicesClient.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println(response.isAcknowledged());
}
//判断索引是否存在
@Test
public void exitsIndex() throws IOException {
//1.通过配置类获取RestHighLevelClient对象
client = myclient.clientSingle();
//2.使用client获取操作索引对象
IndicesClient indicesClient = client.indices();
GetIndexRequest getRequest = new GetIndexRequest("zcj");
boolean exists = indicesClient.exists(getRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}
}
3.文档操作
3.1.添加文档
如果id存在,本次操作为修改;不存在,本次操作为添加
map集合(写死)
对象(从数据库来)
3.2.修改文档
3.3.根据id查询文档
3.4.删除文档
package cn.zcj.esDemo;
import cn.zcj.ESApp;
import cn.zcj.domain.people;
import cn.zcj.esConfig.ElasticSearchConfig;
import com.alibaba.fastjson.JSON;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
@RunWith(SpringRunner.class)
//用了这个注解后,就不用专门去启动启动类,该测试启动时会带着启动类一起启动
@SpringBootTest(classes = ESApp.class)
public class EsDocTest {
@Autowired
private ElasticSearchConfig myclient;
private RestHighLevelClient client;
//添加文档,将写死的集合数据添加到ES中
@Test
public void addDoc() throws IOException {
//数据对象
Map data = new HashMap();
data.put("id",9L);
data.put("name","奥特曼");
data.put("age",10);
client = myclient.clientSingle();
//1.获取操作文档的对象
IndexRequest request = new IndexRequest("zr").id("1").source(data);
//添加数据,获取结果
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
//打印响应结果
System.out.println(response.getId());
}
//添加文档,将写死的集合数据添加到ES中
@Test
public void addDocWithObject() throws IOException {
//数据对象
people p = new people();
p.setId("2");
p.setName("杰克奥特曼");
p.setPrice(55);
//将对象转换为JSON,需要导入依赖
String data = JSON.toJSONString(p);
client = myclient.clientSingle();
//1.获取操作文档的对象
IndexRequest request = new IndexRequest("zr").id(p.getId()).source(data, XContentType.JSON);
//添加数据,获取结果
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
//打印响应结果
System.out.println(response.getId());
}
//修改文档
@Test
public void updateDoc() throws IOException{
//略
}
//根据id查询
@Test
public void findDocById() throws IOException{
GetRequest getrequest = new GetRequest("zr", "1");
/* 另一种写法:
GetRequest getrequest = new GetRequest("zr");
getrequest.id("1");
*/
//
client = myclient.clientSingle();
GetResponse response = client.get(getrequest, RequestOptions.DEFAULT);
//获取数据对应的JSON
System.out.println(response.getSourceAsString());
}
//根据id删除
@Test
public void deleteDocById() throws IOException{
client = myclient.clientSingle();
DeleteRequest deleteRequest = new DeleteRequest("zr", "1");
DeleteResponse response = client.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println(response.getId());
}
}
高级
一.ElasticSearch高级操作
1.批量操作
定义:Bulk批量操作是将文档的增删改查一系列操作,通过一次请求全部做完,减少网络传输次数。
1.脚本操作
语法:
POST /_bulk
{"action":{"metadata"}}
{"data"}示例:
【注意】这里的批量执行里面有3条语句,分别是一条删除语句、一条添加语句、一条修改语句,这3条语句同时执行且互不干扰,也就是说其中任何一条语句执行失败了并不会影响另外两条语句的执行。
思考:这里的批量操作是同步执行还是异步执行?是先进后出的栈结构,还是先进先出的队列结构?

2.JavaApi操作
JavaApi批量操作

代码如下:
package cn.zcj.esDemo;
import cn.zcj.ESApp;
import cn.zcj.esConfig.ElasticSearchConfig;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.rest.RestStatus;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
@RunWith(SpringRunner.class)
//用了这个注解后,就不用专门去启动启动类,该测试启动时会带着启动类一起启动
@SpringBootTest(classes = ESApp.class)
public class ESBulkTest {
@Autowired
private ElasticSearchConfig myclient;
private RestHighLevelClient client;
@Test
public void testBulk() throws IOException {
//创建BulkRequest对象,整合所有操作
BulkRequest bulkRequest = new BulkRequest();
//业务一:删除zr库中detail表里面id为1的那条数据
DeleteRequest deleteRequest= new DeleteRequest("zr","detail","1");
bulkRequest.add(deleteRequest);
//业务二:向zr库中detail表里面添加一条id为10的数据,添加内容为map01里的数据
Map map01 = new HashMap();
map01.put("name","雷欧奥特曼");
map01.put("price",100);
IndexRequest indexRequest= new IndexRequest("zr","detail").id("10").source(map01);
bulkRequest.add(indexRequest);
//业务三:修改zr库中detail表里面id为10的那条数据
Map map02 = new HashMap();
map02.put("name","迪迦奥特曼");
map02.put("price",999);
UpdateRequest updateRequest = new UpdateRequest("zr","detail","10").doc(map02);
bulkRequest.add(updateRequest);
//获取RestHighLevelClient
client = myclient.clientSingle();
//申请一次http请求来进行ElasticSearch批量操作
BulkResponse responses = client.bulk(bulkRequest, RequestOptions.DEFAULT);
//获取请求执行状态
RestStatus status = responses.status();
System.out.println(status);
}
}
代码解释:
2.导入数据
第一步:在kibana上创建对应数据库字段的索引
POST /users/a
{
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "ik_smart"
},
"id":{
"type": "double"
},
"createtime":{
"type": "double"
},
"updatetime":{
"type": "double"
},
"uid":{
"type": "keyword"
},
"phone":{
"type": "keyword"
},
"email":{
"type": "keyword"
},
"state":{
"type": "double"
},
"level":{
"type": "integer"
},
"loginid":{
"type": "double"
}
}
}
}第二步:查询数据库中user表的数据
1.加入3个依赖
<!--Mybatis和数据库连接依赖-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!--@Data注解需要-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
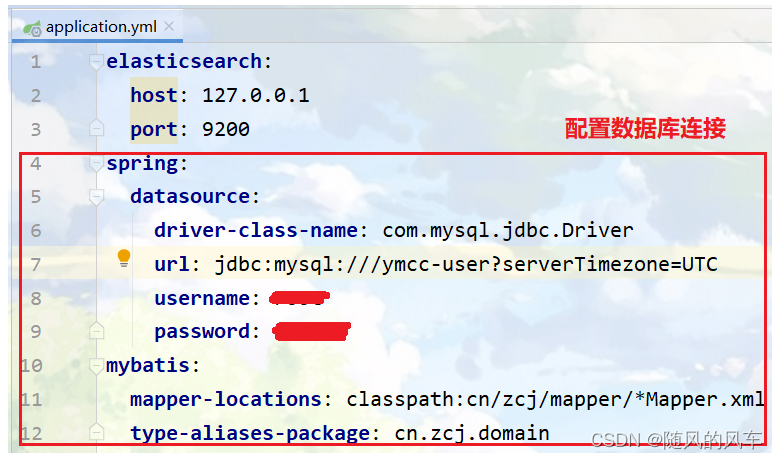
</dependencies>2.在application.yml文件里面配置数据库连接
3.准备一个domain
package cn.zcj.domain;
import lombok.Data;
import lombok.ToString;
@Data
@ToString
public class User {
private String nick_name;
private Double id;
private Double create_time;
private Double update_time;
private String third_uid;
private String phone;
private String email;
private Double bit_state;
private Integer sec_level;
private Double login_id;
}
4.准备一个查询user表全部数据的接口和SQL语句
package cn.zcj.mapper;
import cn.zcj.domain.User;
import org.apache.ibatis.annotations.Mapper;
import org.springframework.stereotype.Repository;
import java.util.List;
@Mapper
@Repository
public interface userMapper {
List<User> findAll();
}
SQL语句
<select id="findAll" resultType="cn.zcj.domain.User">
select * from t_user
</select>第三步:将从user表中查询到的数据批量导入到ElasticSearch中,如果某个对象里面的某个字段对应的的值为null,那么在ElasticSearch上就不会展示这个对象里面值为null的那些字段。
package cn.zcj.esDemo;
import cn.zcj.ESApp;
import cn.zcj.domain.User;
import cn.zcj.esConfig.ElasticSearchConfig;
import cn.zcj.mapper.userMapper;
import com.alibaba.fastjson.JSON;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.io.IOException;
import java.util.List;
@RunWith(SpringRunner.class)
//用了这个注解后,就不用专门去启动启动类,该测试启动时会带着启动类一起启动
@SpringBootTest(classes = ESApp.class)
public class ESImportData {
@Autowired
private ElasticSearchConfig myclient;
private RestHighLevelClient client;
@Autowired
private userMapper userMapper;
@Test
public void importData() throws IOException {
//1.mysql查询所有数据
List<User> userList = userMapper.findAll();
//bulk导入数据
BulkRequest bulkRequest = new BulkRequest();
for (User user:userList) {
//2.1.循环userList集合,创建IndexRequest添加数据
IndexRequest indexRequest = new IndexRequest("users","a");
indexRequest.id(user.getId()+"").source(JSON.toJSONString(user), XContentType.JSON);
bulkRequest.add(indexRequest);
}
client = myclient.clientSingle();
client.bulk(bulkRequest, RequestOptions.DEFAULT);
}
}
3.各种查询(重要)
第一种:matchAll查询:查询所有文档
脚本操作:
语法:
GET users/_search
{
"query": {
"match_all": {}
}
}示例:
得分:得分越高,排得就越靠前,假设现在去用户详情里面查询包含“重庆渝北”字段的所有用户,那么用户详情里面既包含"重庆"又包含"渝北"的用户信息的得分就会高于用户详情里面只包含"重庆"或只包含"渝北"的用户信息的得分。

JavaApi操作
package cn.zcj.esDemo;
import cn.zcj.ESApp;
import cn.zcj.domain.User;
import cn.zcj.esConfig.ElasticSearchConfig;
import com.alibaba.fastjson.JSON;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchRequestBuilder;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.MatchAllQueryBuilder;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
@RunWith(SpringRunner.class)
//用了这个注解后,就不用专门去启动启动类,该测试启动时会带着启动类一起启动
@SpringBootTest(classes = ESApp.class)
public class matchAllTest {
@Autowired
private ElasticSearchConfig myclient;
private RestHighLevelClient client;
@Test
public void testMatchAll() throws IOException {
client = myclient.clientSingle();
//2.构建查询请求对象,指定查询的索引名称
SearchRequest searchRequest = new SearchRequest("users");
//4.创建查询条件构建器SearchSourceBuilder
SearchSourceBuilder searchBuilder = new SearchSourceBuilder();
//6.查询条件
QueryBuilder query = QueryBuilders.matchAllQuery();
//5.指定查询条件
searchBuilder.query(query);
//3.添加查询条件构建器SearchSourceBuilder
searchRequest.source(searchBuilder);
/*
为什么需要分页?
如果数据有1亿条,一下装进内存,会将内存击穿,分页展示相当于分批处理数据的意思,会减小处理压力
8.添加分页信息
from表示从第几条数据开始展示
size表示每页展示多少条数据
*/
searchBuilder.from(0);
searchBuilder.size(30);
//1.查询,获取查询结果
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
//7.获取命中对象
SearchHits searchHits = searchResponse.getHits();
//7.1.获取命中数据的总条数
long value = searchHits.getTotalHits().value;
System.out.println(value);
//9.将读取到的数据存进集合
List<User> usersList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
//转为java对象
User user = JSON.parseObject(sourceAsString, User.class);
usersList.add(user);
}
//默认只会打印10条数据,需要第8步的数据分页设置后,就可以自定义每页展示多少条数据
for (User u:usersList) {
System.out.println(u);
}
}
}
2
第二种:term查询:不会对查询条件进行分词
脚本操作
语法及例子如下:
#term查keyword类型的数据好一些,因为keyword是不分词的,text是要分词的
#语法
GET 索引名/_search
{
"query": {
"term": {
"字段名称": {
"value": "查询条件"
}
}
}
}
#具体例子
GET users/_search
{
"query": {
"term": {
"nick_name": {
"value": "yhptest"
}
}
}
}JavaApi操作
package cn.zcj.esDemo;
import cn.zcj.ESApp;
import cn.zcj.domain.User;
import cn.zcj.esConfig.ElasticSearchConfig;
import com.alibaba.fastjson.JSON;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
@RunWith(SpringRunner.class)
//用了这个注解后,就不用专门去启动启动类,该测试启动时会带着启动类一起启动
@SpringBootTest(classes = ESApp.class)
public class matchAllTest {
@Autowired
private ElasticSearchConfig myclient;
private RestHighLevelClient client;
@Test
public void testTerm() throws IOException {
SearchRequest searchRequest = new SearchRequest("users");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//term词条查询
QueryBuilder query = QueryBuilders.termQuery("nick_name", "yhptest");
sourceBuilder.query(query);
searchRequest.source(sourceBuilder);
client = myclient.clientSingle();
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("查询到的记录数为:"+value);
ArrayList<User> usersList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit:hits) {
String sourceAsString = hit.getSourceAsString();
//转为Java
User user = JSON.parseObject(sourceAsString, User.class);
usersList.add(user);
}
for (User u:usersList) {
System.out.println(u);
}
}
}第三种:match查询----会对查询条件进行分词,然后将分词后的查询条件和词条进行等值匹配,且默认取并集(or)
脚本操作:
语法及举例
#语法:
GET 索引名称/_search
{
"query": {
"match": {
"字段名称": "查询条件"
}
}
}
#match查询取,默认并集
GET users/_search
{
"query": {
"match": {
"third_uid": "中国华为"
}
}
}
#match查询取交集
GET users/_search
{
"query": {
"match": {
"third_uid": {
"query": "中国华为",
"operator": "and"
}
}
}
}
#match查询取并集
GET users/_search
{
"query": {
"match": {
"third_uid": {
"query": "中国华为",
"operator": "or"
}
}
}
}JavaApi操作
package cn.zcj.esDemo;
import cn.zcj.ESApp;
import cn.zcj.domain.User;
import cn.zcj.esConfig.ElasticSearchConfig;
import com.alibaba.fastjson.JSON;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.Operator;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
@RunWith(SpringRunner.class)
//用了这个注解后,就不用专门去启动启动类,该测试启动时会带着启动类一起启动
@SpringBootTest(classes = ESApp.class)
public class matchAllTest {
@Autowired
private ElasticSearchConfig myclient;
private RestHighLevelClient client;
@Test
public void testMatchQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("users");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//match词条查询
MatchQueryBuilder query = QueryBuilders.matchQuery("third_uid", "中国华为");
//Operator.OR代表取并集
query.operator(Operator.OR);
sourceBuilder.query(query);
searchRequest.source(sourceBuilder);
client = myclient.clientSingle();
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("查询到的记录数为:"+value);
ArrayList<User> usersList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit:hits) {
String sourceAsString = hit.getSourceAsString();
//转为Java
User user = JSON.parseObject(sourceAsString, User.class);
usersList.add(user);
}
for (User u:usersList) {
System.out.println(u);
}
}
}第四种----模糊查询(3种查询方式,使用这3中查询尽量都是对keyword类型进行查询)
wildcard查询:会对查询条件进行分词。还可以使用通配符“?”(任意单个字符)和“*”(0个或多个字符)
regexp查询(正则查询)
prefix查询(前缀查询)
#wildcard查询,前面不要加通配符"*",加了就是全表扫描
GET users/_search
{
"query": {
"wildcard": {
"phone": {
"value": "?800053409?"
}
}
}
}
GET users/_search
{
"query": {
"wildcard": {
"phone": {
"value": "1*"
}
}
}
}
#regexp查询(正则查询)
GET users/_search
{
"query": {
"regexp": {
"third_uid": "\\中+(.)*"
}
}
}
#prefix查询(前缀查询)
GET users/_search
{
"query": {
"prefix": {
"third_uid": {
"value": "中"
}
}
}
}JavaApi操作
package cn.zcj.esDemo;
import cn.zcj.ESApp;
import cn.zcj.domain.User;
import cn.zcj.esConfig.ElasticSearchConfig;
import com.alibaba.fastjson.JSON;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.*;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
@RunWith(SpringRunner.class)
//用了这个注解后,就不用专门去启动启动类,该测试启动时会带着启动类一起启动
@SpringBootTest(classes = ESApp.class)
public class matchAllTest {
@Autowired
private ElasticSearchConfig myclient;
private RestHighLevelClient client;
/**
* 模糊查询第一种:Wildcard
* @throws IOException
*/
@Test
public void testWildcardQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("users");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//模糊查询:Wildcard
QueryBuilder query = QueryBuilders.wildcardQuery("phone", "?800053409?");
sourceBuilder.query(query);
searchRequest.source(sourceBuilder);
client = myclient.clientSingle();
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("查询到的记录数为:"+value);
ArrayList<User> usersList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit:hits) {
String sourceAsString = hit.getSourceAsString();
//转为Java
User user = JSON.parseObject(sourceAsString, User.class);
usersList.add(user);
}
for (User u:usersList) {
System.out.println(u);
}
}
/**
* 模糊查询第二种:Regexp(正则查询)
* @throws IOException
*/
@Test
public void testRegexpQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("users");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//模糊查询:Regexp
RegexpQueryBuilder query = QueryBuilders.regexpQuery("third_uid", "\\中+(.)*");
sourceBuilder.query(query);
searchRequest.source(sourceBuilder);
client = myclient.clientSingle();
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("查询到的记录数为:"+value);
ArrayList<User> usersList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit:hits) {
String sourceAsString = hit.getSourceAsString();
//转为Java
User user = JSON.parseObject(sourceAsString, User.class);
usersList.add(user);
}
for (User u:usersList) {
System.out.println(u);
}
}
/**
* 模糊查询第三种:Prefix(前缀查询)
* @throws IOException
*/
@Test
public void testPrefixQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("users");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//模糊查询:Prefix
QueryBuilder query = QueryBuilders.prefixQuery("third_uid", "中");
sourceBuilder.query(query);
searchRequest.source(sourceBuilder);
client = myclient.clientSingle();
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("查询到的记录数为:"+value);
ArrayList<User> usersList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit:hits) {
String sourceAsString = hit.getSourceAsString();
//转为Java
User user = JSON.parseObject(sourceAsString, User.class);
usersList.add(user);
}
for (User u:usersList) {
System.out.println(u);
}
}
}第五种:范围查询(用于商品价格)----range范围查询:查找指定字段在指定范围内包含的值
脚本操作
#查询50<=update_time<=105的结果并升序排列
GET users/_search
{
"query": {
"range": {
"update_time": {
"gte": 50,
"lte": 105
}
}
},
"sort": [
{
"update_time": {
"order": "asc"
}
}
]
}
JavaApi操作
@RunWith(SpringRunner.class)
//用了这个注解后,就不用专门去启动启动类,该测试启动时会带着启动类一起启动
@SpringBootTest(classes = ESApp.class)
public class matchAllTest {
@Autowired
private ElasticSearchConfig myclient;
private RestHighLevelClient client;
/**
* 1.范围查询:Range
* 2.排序查询:Sort
* @throws IOException
*/
@Test
public void testRangeQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("users");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//范围查询:Range
RangeQueryBuilder query = QueryBuilders.rangeQuery("update_time");
//设置下限
query.gte(50);
//设置上限
query.lte(105);
sourceBuilder.query(query);
/*
排序查询:Sort
根据update_time这个字段进行升序排列,也可以根据其他可排序的字段排序,如:id、price、count
*/
sourceBuilder.sort("update_time", SortOrder.ASC);
searchRequest.source(sourceBuilder);
client = myclient.clientSingle();
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("查询到的记录数为:"+value);
ArrayList<User> usersList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit:hits) {
String sourceAsString = hit.getSourceAsString();
//转为Java
User user = JSON.parseObject(sourceAsString, User.class);
usersList.add(user);
}
for (User u:usersList) {
System.out.println(u);
}
}
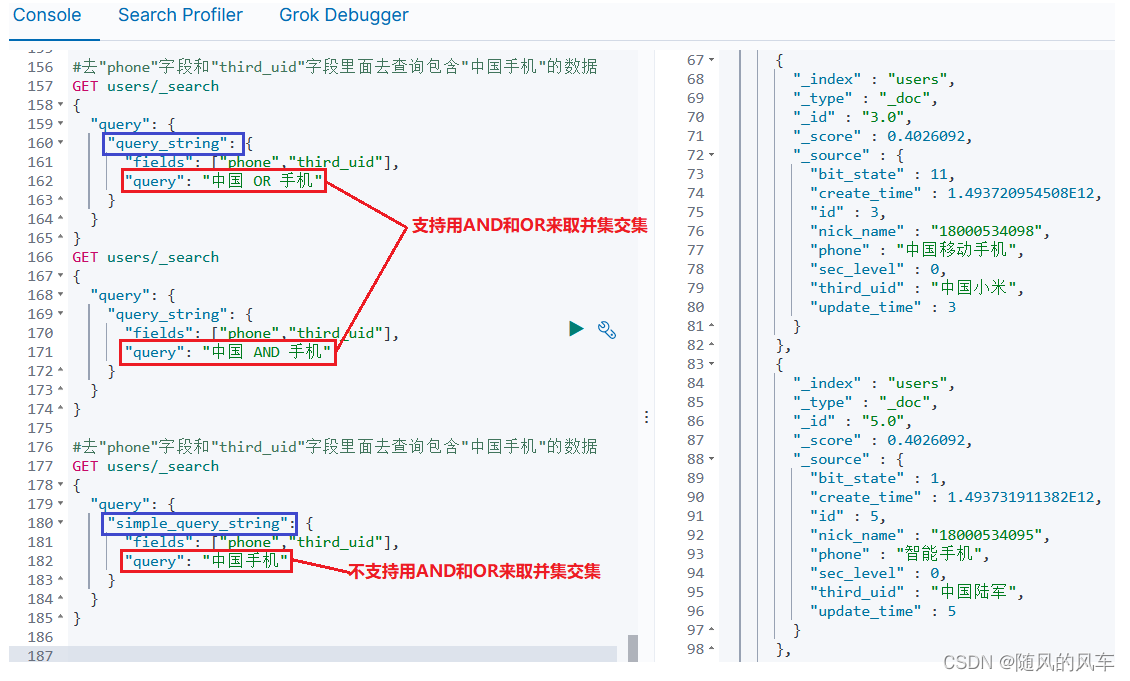
}第六种:query_string多条件查询
queryString:会对查询条件进行分词;然后将分词后的查询条件和词条进行等值匹配;默认取并集(OR);可以指定多个查询字段
语法:
GET 索引名/_search
{
"query": {
"query_string": {
"fields": ["字段1","字段2"...],
"query": "查询条件1 OR 查询条件2"
}
}
}案例:
JavaApi操作
@RunWith(SpringRunner.class)
//用了这个注解后,就不用专门去启动启动类,该测试启动时会带着启动类一起启动
@SpringBootTest(classes = ESApp.class)
public class matchAllTest {
@Autowired
private ElasticSearchConfig myclient;
private RestHighLevelClient client;
/**
* 多字段查询:QueryString
* @throws IOException
*/
@Test
public void testQueryStringQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("users");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//多字段查询:QueryString
QueryStringQueryBuilder query = QueryBuilders.queryStringQuery("中国手机")
.field("phone").field("third_uid").defaultOperator(Operator.AND);
sourceBuilder.query(query);
searchRequest.source(sourceBuilder);
client = myclient.clientSingle();
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("查询到的记录数为:"+value);
ArrayList<User> usersList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit:hits) {
String sourceAsString = hit.getSourceAsString();
//转为Java
User user = JSON.parseObject(sourceAsString, User.class);
usersList.add(user);
}
for (User u:usersList) {
System.out.println(u);
}
}
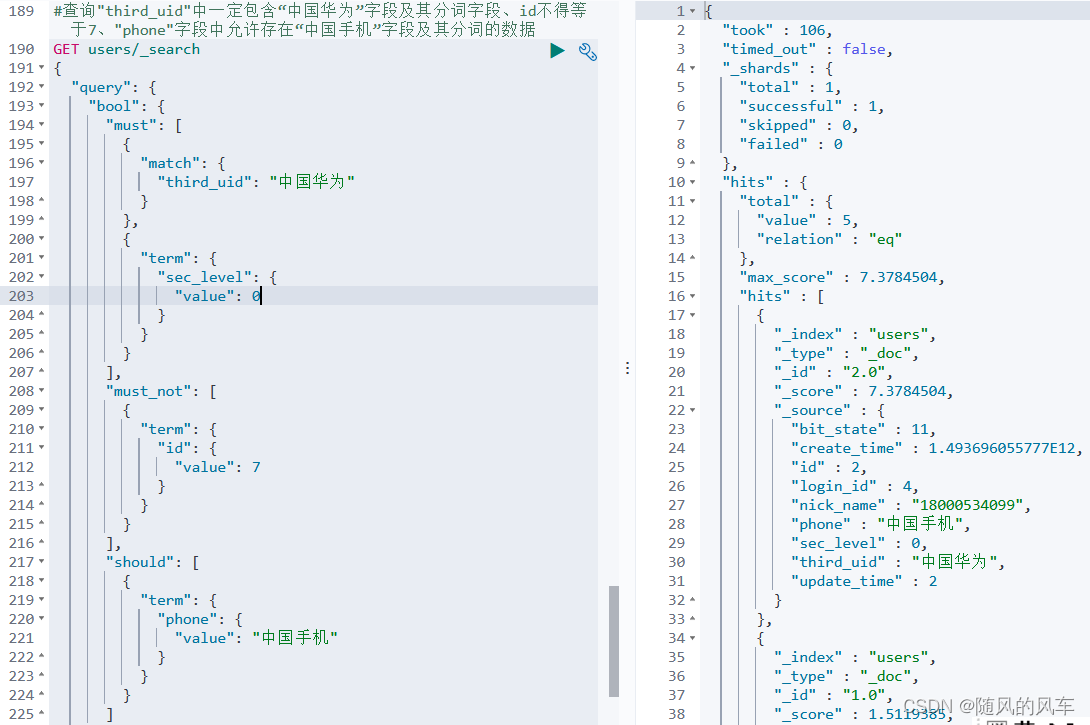
}第七种:布尔查询----多条件拼接查询
定义:

案例
JavaApi操作
@RunWith(SpringRunner.class)
//用了这个注解后,就不用专门去启动启动类,该测试启动时会带着启动类一起启动
@SpringBootTest(classes = ESApp.class)
public class matchAllTest {
@Autowired
private ElasticSearchConfig myclient;
private RestHighLevelClient client;
/**
* 布尔查询:BoolQuery
* @throws IOException
*/
@Test
public void testBoolQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("users");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//1.构建boolQuery
BoolQueryBuilder query = QueryBuilders.boolQuery();
//2.构建各个查询条件
//2.1.1.构建条件1
MatchQueryBuilder matchQuery = QueryBuilders.matchQuery("third_uid", "中国");
//2.1.2.将条件加入must必须满足类型
query.must(matchQuery);
//2.2.
TermQueryBuilder secLevel = QueryBuilders.termQuery("sec_level", 0);
query.must(secLevel);
//2.3.
TermQueryBuilder idQuery = QueryBuilders.termQuery("id", 7);
query.mustNot(idQuery);
//2.4.
TermQueryBuilder phoneQuery = QueryBuilders.termQuery("phone", "中国手机");
query.should(phoneQuery);
//3.使用boolQuery连接
sourceBuilder.query(query);
searchRequest.source(sourceBuilder);
client = myclient.clientSingle();
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("查询到的记录数为:"+value);
ArrayList<User> usersList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit:hits) {
String sourceAsString = hit.getSourceAsString();
//转为Java
User user = JSON.parseObject(sourceAsString, User.class);
usersList.add(user);
}
for (User u:usersList) {
System.out.println(u);
}
}
}第八种:聚合查询(使用场景:手机品牌)
指标聚合:相当于MySQL的聚合函数。max、min、avg、sum等
桶聚合:相当于MYSQL的group by操作。不要对text类型的数据进行分组,会失败。
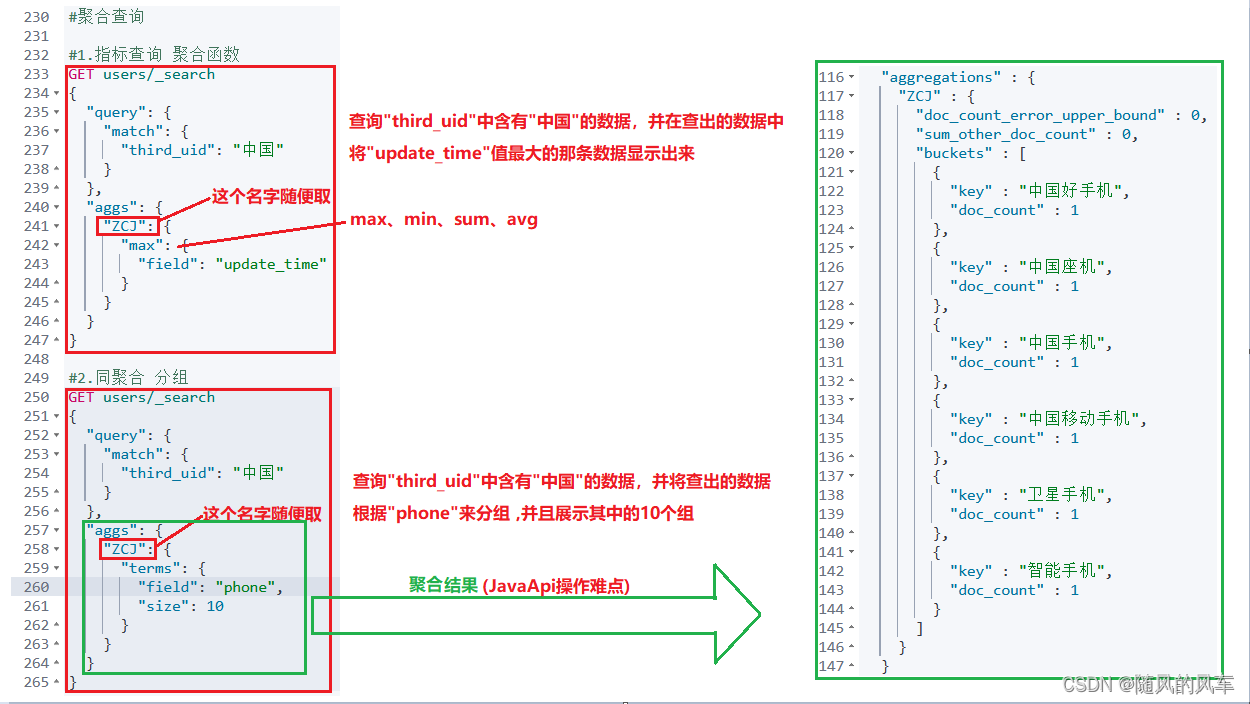
JavaApi操作,用Java代码操作聚合查询的难点在于将最后的聚合结果获取出来
@RunWith(SpringRunner.class)
//用了这个注解后,就不用专门去启动启动类,该测试启动时会带着启动类一起启动
@SpringBootTest(classes = ESApp.class)
public class matchAllTest {
@Autowired
private ElasticSearchConfig myclient;
private RestHighLevelClient client;
/**
* 聚合查询:桶聚合
* @throws IOException
*/
@Test
public void testAggsQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("users");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//聚合查询:桶聚合
MatchQueryBuilder query = QueryBuilders.matchQuery("third_uid", "中国");
sourceBuilder.query(query);
AggregationBuilder aggs = AggregationBuilders.terms("ZCJ").field("phone").size(10);
sourceBuilder.aggregation(aggs);
searchRequest.source(sourceBuilder);
client = myclient.clientSingle();
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("查询到的记录数为:"+value);
ArrayList<User> usersList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit:hits) {
String sourceAsString = hit.getSourceAsString();
//转为Java
User user = JSON.parseObject(sourceAsString, User.class);
usersList.add(user);
}
for (User u:usersList) {
System.out.println(u);
}
//获取聚合结果
Aggregations aggregations = searchResponse.getAggregations();
Map<String, Aggregation> aggregationMap = aggregations.asMap();
Terms zcj = (Terms)aggregationMap.get("ZCJ");
List<? extends Terms.Bucket> buckets = zcj.getBuckets();
ArrayList zcjs = new ArrayList();
for (Terms.Bucket bucket:buckets) {
Object key = bucket.getKey();
zcjs.add(key);
}
//遍历聚合结果
for (Object z:zcjs) {
System.out.println(z);
}
}
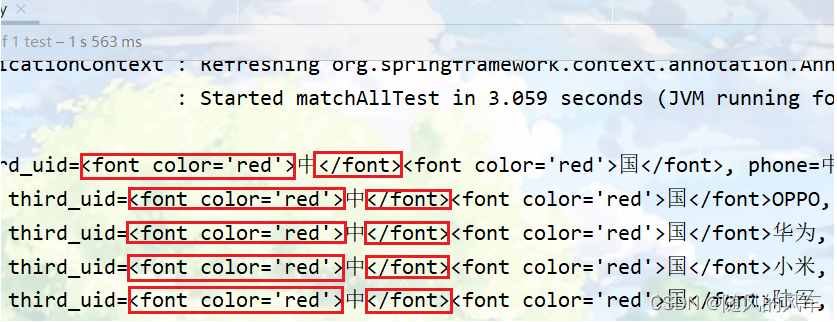
}第九种:高亮查询----三要素:高亮字段、前缀、后缀
脚本操作
1.设置高亮;2.解析高亮结果并将高亮结果设置到原有数据的结果上
【注意】如果不设置前后缀,那么ES会默认加上一个前后缀标签<em></em>

JavaApi操作
@RunWith(SpringRunner.class)
//用了这个注解后,就不用专门去启动启动类,该测试启动时会带着启动类一起启动
@SpringBootTest(classes = ESApp.class)
public class matchAllTest {
@Autowired
private ElasticSearchConfig myclient;
private RestHighLevelClient client;
/**
* 桶聚合查询+高亮查询:
* @throws IOException
*/
@Test
public void testHighLightQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("users");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//聚合查询:桶聚合
MatchQueryBuilder query = QueryBuilders.matchQuery("third_uid", "中国");
sourceBuilder.query(query);
//设置高亮
HighlightBuilder highlighter = new HighlightBuilder();
//设置三要素
highlighter.field("third_uid").preTags("<font color='red'>").postTags("</font>");
sourceBuilder.highlighter(highlighter);
AggregationBuilder aggs = AggregationBuilders.terms("ZCJ").field("phone").size(10);
sourceBuilder.aggregation(aggs);
searchRequest.source(sourceBuilder);
client = myclient.clientSingle();
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("查询到的记录数为:"+value);
ArrayList<User> usersList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit:hits) {
String sourceAsString = hit.getSourceAsString();
//转为Java
User user = JSON.parseObject(sourceAsString, User.class);
//获取高亮结果并用高亮结果替换原始数据
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField highlightField = highlightFields.get("third_uid");
//获取片段
Text[] fragments = highlightField.fragments();
user.setThird_uid(fragments[0].toString());
usersList.add(user);
}
for (User u:usersList) {
System.out.println(u);
}
//获取聚合结果
Aggregations aggregations = searchResponse.getAggregations();
Map<String, Aggregation> aggregationMap = aggregations.asMap();
Terms zcj = (Terms)aggregationMap.get("ZCJ");
List<? extends Terms.Bucket> buckets = zcj.getBuckets();
ArrayList zcjs = new ArrayList();
for (Terms.Bucket bucket:buckets) {
Object key = bucket.getKey();
zcjs.add(key);
}
//遍历聚合结果
for (Object z:zcjs) {
System.out.println(z);
}
}
}代码运行结果(部分):
4.索引别名和索引重建

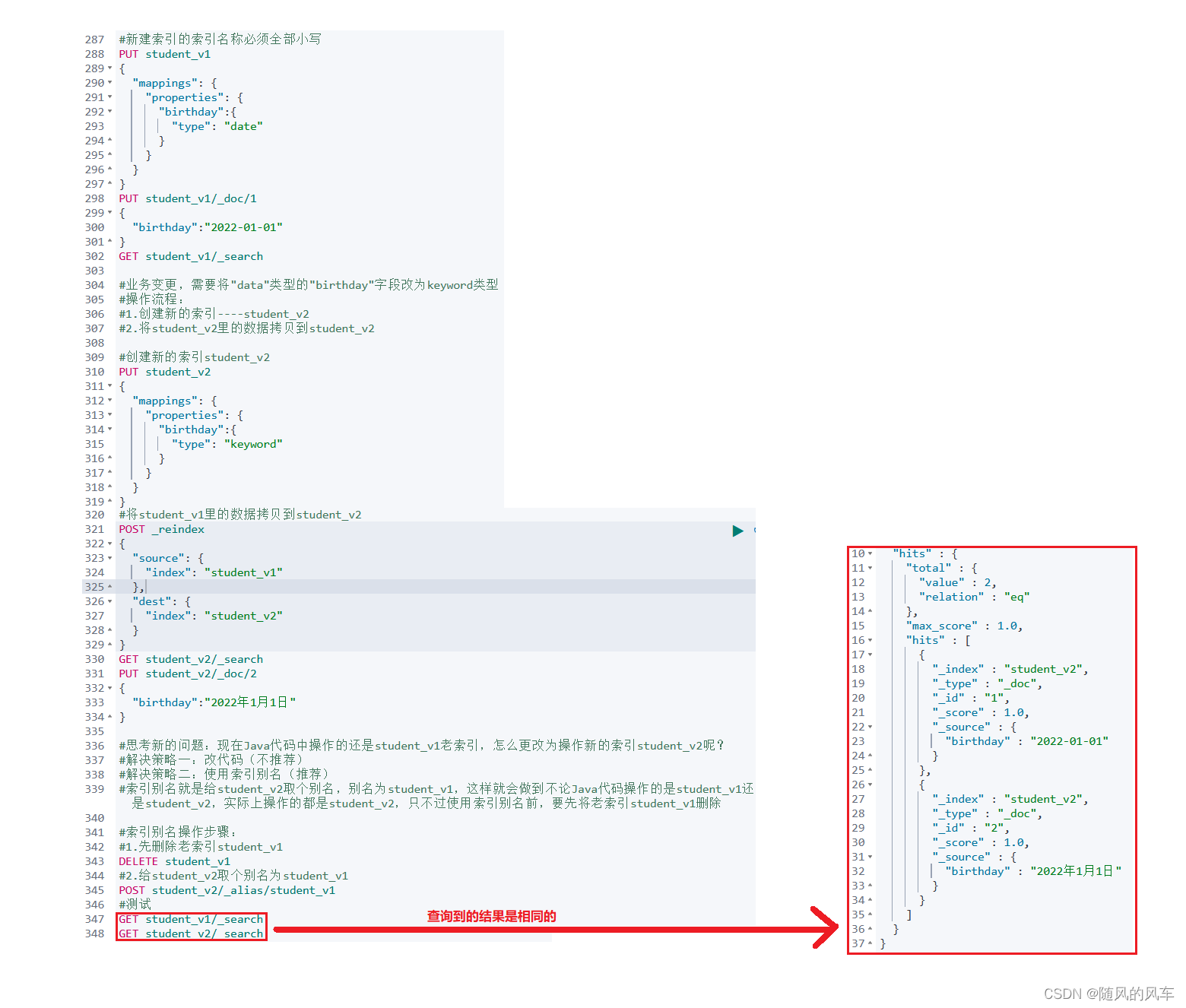
描述:















 1628
1628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









