





InnoDB存储模型
本文翻译自 Mysql官方文档的InnoDB部分,部分内容参考网络博文予以补充,参考文章如下:
mysql的内存模型(一)
linux信号量对mysql_MySQL 信号量semaphore 和 innodb_adaptive_hash_index

从图中可以看出InnoDB的存储架构分为了内存结构和磁盘结构,下面试就各个区域分别讲解
mysql> show engine innodb status \G;
*************************** 1. row ***************************
Type: InnoDB
Name:
Status:
=====================================
2022-03-02 13:14:01 0x2914 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 42 seconds
-----------------
BACKGROUND THREAD
-----------------
srv_master_thread loops: 1 srv_active, 0 srv_shutdown, 324158 srv_idle
srv_master_thread log flush and writes: 0
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 6
OS WAIT ARRAY INFO: signal count 6
RW-shared spins 0, rounds 0, OS waits 0
RW-excl spins 0, rounds 0, OS waits 0
RW-sx spins 0, rounds 0, OS waits 0
Spin rounds per wait: 0.00 RW-shared, 0.00 RW-excl, 0.00 RW-sx
------------
TRANSACTIONS
------------
Trx id counter 27401
Purge done for trx's n:o < 27398 undo n:o < 0 state: running but idle
History list length 0
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 284211251813696, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 284211251812872, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 284211251812048, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
--------
FILE I/O
--------
I/O thread 0 state: wait Windows aio (insert buffer thread)
I/O thread 1 state: wait Windows aio (log thread)
I/O thread 2 state: wait Windows aio (read thread)
I/O thread 3 state: wait Windows aio (read thread)
I/O thread 4 state: wait Windows aio (read thread)
I/O thread 5 state: wait Windows aio (read thread)
I/O thread 6 state: wait Windows aio (write thread)
I/O thread 7 state: wait Windows aio (write thread)
I/O thread 8 state: wait Windows aio (write thread)
I/O thread 9 state: wait Windows aio (write thread)
Pending normal aio reads: [0, 0, 0, 0] , aio writes: [0, 0, 0, 0] ,
ibuf aio reads:, log i/o's:, sync i/o's:
Pending flushes (fsync) log: 0; buffer pool: 0
1042 OS file reads, 217 OS file writes, 39 OS fsyncs
0.00 reads/s, 0 avg bytes/read, 0.00 writes/s, 0.00 fsyncs/s
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 0 buffer(s)
Hash table size 34679, node heap has 1 buffer(s)
Hash table size 34679, node heap has 3 buffer(s)
0.00 hash searches/s, 0.00 non-hash searches/s
---
LOG
---
Log sequence number 112978973
Log buffer assigned up to 112978973
Log buffer completed up to 112978973
Log written up to 112978973
Log flushed up to 112978973
Added dirty pages up to 112978973
Pages flushed up to 112978973
Last checkpoint at 112978973
18 log i/o's done, 0.00 log i/o's/second
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 136970240
Dictionary memory allocated 373269
Buffer pool size 8192
Free buffers 7027
Database pages 1161
Old database pages 448
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 1019, created 142, written 160
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
No buffer pool page gets since the last printout
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 1161, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
--------------
ROW OPERATIONS
--------------
0 queries inside InnoDB, 0 queries in queue
0 read views open inside InnoDB
Process ID=6224, Main thread ID=8640 , state=sleeping
Number of rows inserted 0, updated 0, deleted 0, read 0
0.00 inserts/s, 0.00 updates/s, 0.00 deletes/s, 0.00 reads/s
Number of system rows inserted 0, updated 315, deleted 0, read 4683
0.00 inserts/s, 0.00 updates/s, 0.00 deletes/s, 0.00 reads/s
----------------------------
END OF INNODB MONITOR OUTPUT
============================
一、MySQL Glossary
截取自官方词汇表,解释本文中出现的部分概念,该部分可先跳过
data dictionary 数据字典
跟踪数据库对象(例如表、索引和表列)的元数据。对于MySQL 8.0 中引入的 MySQL 数据字典,元数据存储在数据库目录中的InnoDB file-per-table (独立表空间)文件中。对于 InnoDB的数据字典,元数据存储在系统表空间中。
因为MySQL Enterprise Backup产品总是备份 InnoDB系统表空间,所以所有备份都包含InnoDB数据字典的内容
dirty page 脏页
已经在缓冲池中更新,但尚未刷新(flush)到磁盘上的数据文件的页面,与clean pages相对
extent 扩展区
表空间中的一组页。对于16KB的默认页面大小,一个区包含 64 个页面。在 MySQL 5.6 中,实例的页面大小可以是 4KB、8KB 或 16KB,由配置选项控制。对于4KB、8KB 和 16KB 页面大小,扩展区大小始终为 1MB(或 1048576 字节)。 InnoDBMySQL 5.7.6 中添加了 对 32KB 和 64KB 页面大小的支持。对于 32KB 的页面大小,extent 大小为 2MB。对于 64KB 的页面大小,extent 大小为 4MB。
InnoDB的段、预读请求和双写缓冲区等功能 使用 I/O 操作,一次读取、写入、分配或释放一个区段的数据。
file-per-table 独立表空间
由 innodb_file_per_table选项控制的系统设置,它是影响InnoDB文件存储、功能可用性和 I/O 特性等方面的重要配置选项。从 MySQL 5.6.7 开始, innodb_file_per_table默认启用。
启用该innodb_file_per_table 选项后,您可以在自己的 .ibd 文件中创建表,而不是在系统表空间的共享ibdata 文件中 创建表。当表数据存储在单独的.ibd 文件中时,您可以更灵活地选择行格式以满足数据压缩等特性。TRUNCATE TABLE操作也更快,并且回收的空间可以由操作系统使用,而不是保留给InnoDB
MySQL Enterprise Backup产品对于处于独立文件中的表更加灵活。例如,可以从备份中排除表,但前提是它们位于单独的文件中。因此,此设置适用于备份频率较低或按不同计划备份的表。
flushing 刷新
把已缓冲在内存区域或临时磁盘存储区域中的数据更改写入数据库文件。定期刷新的 InnoDB存储结构包括重做日志redo log、撤消日志undo log和缓冲池buffer pool。
刷新可能发生在如下情况中:
- 内存区域变满并且系统需要释放一些空间
- 事务提交操作,产生数据更改
- 缓慢的关闭操作意味着应该完成所有未完成的工作。
当我们不急于一次刷新所有缓冲数据时, InnoDB可以使用一种称为模糊检查点(fuzzy checkpointing)的技术来小批量地刷新页面以分散 I/O 开销。
general tablespace 通用表空间
使用
CREATE TABLESPACE语法创建的共享InnoDB 表空间。通用表空间可以在 MySQL 数据目录之外创建,能够容纳多个表,并且支持所有行格式。MySQL 5.7.6 中引入了通用表空间。
使用CREATE TABLE tbl_name ... TABLESPACE [=] tablespace_name or ALTER TABLE tbl_name TABLESPACE [=] tablespace_name语法将表添加到通用表空间
与系统表空间和独立表空间相对。
read-ahead 预读
一种 I/O 请求,它将一组预期要被使用到的页面(一个extent的所有页面)异步预取到缓冲池中。线性预读技术根据前一盘区中页面的访问模式预取一个盘区的所有页面。一旦缓冲池中有来自同一extent的一定数量的页面,随机预读技术就会预取一个extent的所有页面。随机预读不是 MySQL 5.5 的一部分,但在 innodb_random_read_ahead 配置选项的控制下在 MySQL 5.6 中重新引入。
page 页
表示磁盘(数据文件)和内存( 缓冲池InnoDB) 之间任何时候传输的数据量的单位。一页可以包含一行或多行,具体取决于每行中的数据量。如果一行不完全适合单个页面,则设置额外的指针样式数据结构,以便可以将有关该行的信息存储在一个页面中。
InnoDB在每页中容纳更多数据的一种方法是使用压缩行格式(compressed row format)。对于使用 BLOB 或大文本字段的表, 压缩行格式允许将这些大列与行的其余部分分开存储,从而减少不引用这些列的查询的 I/O 开销和内存使用。
当InnoDB批量读取或写入页面集以增加 I/O 吞吐量时,它一次读取或写入一个扩展区(extent)。
MySQL 实例中的所有InnoDB磁盘数据结构共享相同的页面大小。
purge 清除
一种由一个或多个单独的后台线程(由 innodb_purge_threads控制)执行的垃圾收集,这些线程定期运行。purge线程从历史列表中解析和处理撤消日志(undo log)页面,以删除标记为deletion(通过先前的DELETE语句)并且不再需要用于MVCC或 回滚的聚集和二级索引记录。清除处理后从历史列表中释放撤消日志页面。
system tablespace
一个或多个数据文件(ibdata 文件),其中包含 InnoDB相关对象的元数据,以及写缓冲区和双写缓冲区的存储区域。如果表是在系统表空间而不是file-per-table或通用表空间中创建的,它还可能包含表本身和其索引数据。系统表空间中的数据和元数据适用于MySQL 实例中的所有数据库。
在 MySQL 5.6.7 之前,默认将所有 InnoDB表和索引保留在系统表空间内,这通常会导致此文件变得非常大。因为系统表空间从不收缩,如果加载大量临时数据然后删除,可能会出现存储问题。在 MySQL 8.0 中,默认为 file-per-table模式,其中每个表及其关联的索引都存储在单独的 .ibd 文件中。这个默认值使得InnoDB基于 DYNAMIC和COMPRESSED行格式的特性变得更容易使用,例如表压缩、页外列的高效存储, 和大索引键前缀。
将所有表数据保存在系统表空间或单独的 .ibd文件中通常会对存储管理产生影响。MySQL Enterprise Backup产品可能会备份一小组大文件或许多较小的文件。在具有数千个表的系统上,处理数千个 .ibd文件的文件系统操作可能会导致瓶颈。
InnoDB在 MySQL 5.7.6 中引入了通用表空间,也由 .ibd文件表示。通用表空间是使用CREATE TABLESPACE语法创建的共享表空间。它们可以在数据目录之外创建,能够保存多个表,并支持所有行格式的表。
二、In-Memory Structures
1. Buffer Pool
缓冲池是主内存中的一个区域,用于在 InnoDB访问表和索引数据时对其进行缓存。缓冲池允许直接从内存中访问经常使用的数据,从而加快处理速度。在专用服务器上,多达 80% 的物理内存通常分配给缓冲池。
为了提高大容量读取操作的效率,缓冲池被划分为可能包含多行的页面。为了缓存管理的效率,缓冲池被实现为页链表,并使用最近最少使用 (LRU) 算法的变体处理缓存中的老化数据
了解如何利用缓冲池将频繁访问的数据保存在内存中是 MySQL 调优的一个重要方面。
1.1 Buffer Pool LRU Algorithm
缓冲池被组织为List结构(一般用链表实现),使用类LRU 算法进行管理。当需要空间来向缓冲池添加新page时,最近最少使用的页面将被逐出,并将新页面添加到列表的中间。此中点插入策略将列表视为两个子列表:
- 头部子列表保存新页面(即最近被使用得更频繁的年轻页面)
- 尾部子列表保存老页面
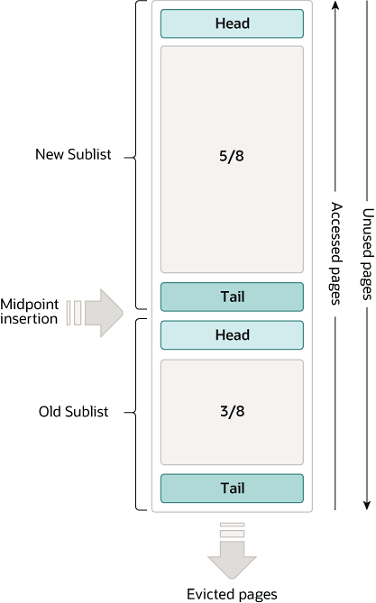
该算法将经常使用的页面保留在新子列表中。旧子列表包含不常用的页面,以待新页面进入但空间不足时被剔除。
默认情况下,算法运行如下:
-
缓冲池的 3/8 专用于旧子列表。
-
列表的中点是新子列表的尾部与旧子列表的头部相交的边界。
-
当InnoDB将页面读入缓冲池时,它最初将其插入到中点(旧子列表的头部)。这种读取会发生在以下两种情况当中:
- 用户主动读取页面,如SQL查询
- InnoDB主动发起预读操作
-
访问旧子列表中的页面将使其变得 “年轻”——将其移动到新子列表的头部。如果页面是因为用户操作的需要而被读取的,则将立刻产生first access,并且页面会变得年轻。反之,如果由于预读操作而读取了页面,则first access不会立即发生,并且可能直到页面被驱逐都还没发送。
-
随着数据库的运行,缓冲池中未被访问的页面通过向列表尾部移动而“老化” 。新旧子列表中的页面都会随着其他页面的更新而老化。旧子列表中的页面也会随着页面插入到中点而老化。最终,未使用的页面到达旧子列表的尾部并被驱逐。
默认情况下,查询读取的页面会立即移动到新的子列表中,这意味着它们在缓冲池中的停留时间更长。例如,mysqldump操作和不带where子句的SELECT语句将对表进行扫描并为Buffer Pool引入大量的新数据(而这些数据可能根本不会被使用),同时淘汰等量的老页面。类似地,由read-ahead后台线程加载并只被读取过一次的页面也将被移动至新子列表的首端。这些情况都会将一些经常被使用的页面推送至旧子列表并最终被淘汰,如何提高缓冲池的稳定性,详见Section 15.8.3.3, “Making the Buffer Pool Scan Resistant”
Section 15.8.3.4, “Configuring InnoDB Buffer Pool Prefetching (Read-Ahead)”
InnoDB标准监视器输出包含有关缓冲池 LRU 算法操作的部分属性。详见Monitoring the Buffer Pool Using the InnoDB Standard Monitor
- Q:缓冲池为什么在LRU列表中引入新子列表和旧子列表机制?
- A:为了防止预取失效现象,即被预取到列表中但最终未被读取的页面。解决方案是加速预取页面老化的速度,在第一次引入缓冲池时插入Midpoint而非列表头部。
- Q:“老生代停留时间窗口”(innodb_old_blocks_time)的设置目的是什么?
- A:为了防止“缓冲池污染”现象。当某些用户操作需要全表扫描时,大量新页面将被引入缓冲池并被读取(继而被放到新子列表头部),但其中的多数数据可能不会再被使用第二次,这将导致新列表中存在大量的无效数据。为此,我们设定“老生代停留时间”,当新数据被引入时将被放在老列表首部,只有在此处停留超过一段时间后,该页面才会由于读取操作被而“年轻化”(即第一次读取操作无法使其变得年轻)
1.2 Buffer Pool Configuration
配置缓冲池的各方面参数以提高性能。
- 理想情况下,将缓冲池的大小设置为尽可能大的值,从而为服务器上的其他进程留出足够的内存来运行而不会出现过多的分页。缓冲池越大,InnoDB的性能表现将越接近内存数据库,即只需从磁盘读取一次数据,在后续读取期间直接从内存中访问数据。详见Section 15.8.3.1, “Configuring InnoDB Buffer Pool Size”
- 在具有足够内存的 64 位系统上,您可以将缓冲池拆分为多个部分,以最大程度地减少并发操作之间的内存结构争用。详见Section 15.8.3.2, “Configuring Multiple Buffer Pool Instances”
- 为增强缓冲池的稳定性,防止短期内激增的操作将大量不常使用的数据引入缓冲池,可以先行设置经常被使用的数据即使在特殊情况下也会被保存在缓冲池中。详见Section 15.8.3.4, “Configuring InnoDB Buffer Pool Prefetching (Read-Ahead)”
- 控制执行预读请求的方式和时间,以异步将页面预取到缓冲池中,以应对即将到来的需求。详见Section 15.8.3.4, “Configuring InnoDB Buffer Pool Prefetching (Read-Ahead)”
- 您可以控制何时发生后台刷新以及是否根据工作负载动态调整刷新速率。详见Section 15.8.3.5, “Configuring Buffer Pool Flushing”
- 配置InnoDB如何保留当前缓冲池状态以避免服务器重新启动后的长时间预热。详见Section 15.8.3.6, “Saving and Restoring the Buffer Pool State”
1.3 Buffer Pool Metrics
Monitoring the Buffer Pool Using the InnoDB Standard Monitor
InnoDB可以使用 SHOW ENGINE INNODB STATUS 命令获取InnoDB标准监视器的输出,它将提供有关缓冲池相关操作的指标。缓冲池指标位于标准监视器输出的BUFFER POOL AND MEMORY部分
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 136970240
Dictionary memory allocated 373269
Buffer pool size 8192
Free buffers 7027
Database pages 1161
Old database pages 448
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 1019, created 142, written 160
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
No buffer pool page gets since the last printout
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 1161, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
下表描述了 InnoDB标准监视器报告的缓冲池指标。
InnoDB标准监视器输出中提供的每秒平均值基于自 InnoDB上次打印标准监视器输出以来经过的时间。
| Name | Description |
|---|---|
| Total memory allocated | The total memory allocated for the buffer pool in bytes. |
| Dictionary memory allocated | The total memory allocated for the InnoDB data dictionary in bytes. |
| Buffer pool size | The total size in pages allocated to the buffer pool. |
| Free buffers | The total size in pages of the buffer pool free list. |
| Database pages | The total size in pages of the buffer pool LRU list. |
| Old database pages | The total size in pages of the buffer pool old LRU sublist. |
| Modified db pages | The current number of pages modified in the buffer pool. |
| Pending reads | The number of buffer pool pages waiting to be read into the buffer pool. |
| Pending writes LRU | The number of old dirty pages within the buffer pool to be written from the bottom of the LRU list. |
| Pending writes flush list | The number of buffer pool pages to be flushed during checkpointing. |
| Pending writes single page | The number of pending independent page writes within the buffer pool. |
| Pages made young | The total number of pages made young in the buffer pool LRU list (moved to the head of sublist of “new” pages). |
| Pages made not young | The total number of pages not made young in the buffer pool LRU list (pages that have remained in the “old” sublist without being made young). |
| youngs/s | The per second average of accesses to old pages in the buffer pool LRU list that have resulted in making pages young. See the notes that follow this table for more information. |
| non-youngs/s | The per second average of accesses to old pages in the buffer pool LRU list that have resulted in not making pages young. See the notes that follow this table for more information. |
| Pages read | The total number of pages read from the buffer pool. |
| Pages created | The total number of pages created within the buffer pool. |
| Pages written | The total number of pages written from the buffer pool. |
| reads/s | The per second average number of buffer pool page reads per second. |
| creates/s | The average number of buffer pool pages created per second. |
| writes/s | The average number of buffer pool page writes per second. |
| Buffer pool hit rate | The buffer pool page hit rate for pages read from the buffer pool vs from disk storage. |
| young-making rate | The average hit rate at which page accesses have resulted in making pages young. See the notes that follow this table for more information. |
| not (young-making rate) | The average hit rate at which page accesses have not resulted in making pages young. See the notes that follow this table for more information. |
| Pages read ahead | The per second average of read ahead operations. |
| Pages evicted without access | The per second average of the pages evicted without being accessed from the buffer pool. |
| Random read ahead | The per second average of random read ahead operations. |
| LRU len | The total size in pages of the buffer pool LRU list. |
| unzip_LRU len | The length (in pages) of the buffer pool unzip_LRU list. |
| I/O sum | The total number of buffer pool LRU list pages accessed. |
| I/O cur | The total number of buffer pool LRU list pages accessed in the current interval. |
| I/O unzip sum | The total number of buffer pool unzip_LRU list pages decompressed. |
| I/O unzip cur | The total number of buffer pool unzip_LRU list pages decompressed in the current interval. |
- Total large memory allocated——为缓冲池分配的总内存(以字节为单位),共136970240字节
- Dictionary memory allocated ——为数据字典分配的总内存(InnoDB以字节为单位),共373269字节
- Buffer pool size ——分配给缓冲池的总页面大小,共8192个页面
我们将136970240/373269/1024,可以得到本地Mysql的页面大小约为16KB - Free buffers——缓冲池空闲列表的总页面大小。
- Database pages ——缓冲池 LRU 列表的总页面大小,即缓冲池中已被使用的部分,包含新列表和旧列表。按理来说,Free buffers(7027)+ Database pages(1161)=8188= Buffer pool size,但实际上相差了4个页面,原因未知
- Old database pages——缓冲池旧 LRU 子列表的总页面大小。
- Modified db pages——当前在缓冲池中修改的页数,即已写入数据,但是没写入硬盘表空间的脏页
- Pending reads——等待读入缓冲池的缓冲池页数
- Pending writes——待写页
LRU 0——缓冲池中等待写入LRU列表底部的旧脏页数量
flush list 0——检查点期间要刷新的缓冲池页数。
single page 0—— 缓冲池中挂起的独立页面写入数。 - Pages made young——LRU列表中变“年轻”(即被移动至新子列表首部)的页面总数
- Pages made not young——未变年轻的页面数(停留在旧子列表)
- youngs/s——每秒访问缓冲池 LRU 列表中旧页面的平均次数,这些访问导致页面变得年轻
- non-youngs/s——每秒访问缓冲池 LRU 列表中的旧页面却未使其变年轻的平均次数
- Pages read——从缓冲池中读取的总页数
- Pages created——在缓冲池中创建的总页数
- Pages written——从缓冲池写入的总页数
- reads/s——每秒平均每秒读取缓冲池页面的次数
- creates/s——平均每秒创建的缓冲池页数
- writes/s——每秒平均写入缓冲池页面的次数
- Buffer pool hit rate——从缓冲池读取的页面与从磁盘存储读取的页面的缓冲池页面命中率
- young-making rate——页面访问导致页面年轻的平均命中率
- not (young-making rate)——页面访问没有导致页面年轻的平均命中率
- Pages read ahead——每秒平均预读操作数
- Pages evicted without access——在没有从缓冲池访问的情况下被逐出的页面的每秒平均数
- Random read ahead ——随机预读操作的每秒平均值
- LRU len—— 缓冲池 LRU 列表的总页面大小
- unzip_LRU len——缓冲池 unzip_LRU 列表的长度
- I/O sum——访问的缓冲池 LRU 列表页的总数
- I/O cur ——当前时间间隔内访问的缓冲池 LRU 列表页的总数
- I/O unzip sum——解压缩的缓冲池 unzip_LRU 列表页的总数
- I/O unzip cur——当前时间间隔内解压的缓冲池 unzip_LRU 列表页总数
注:
- youngs/s指标仅适用于旧页面。它基于页面访问次数。给定页面可以被多次访问,所有这些都被计算在内。如果在没有发生大规模扫描时,youngs/s 达到非常低的值,请考虑减少延迟时间或增加缓冲池中旧子列表所占百分比。增加百分比会使旧的子列表变大,从而使该子列表中的页面移动到尾部所需的时间更长,这增加了再次访问这些页面并使其变得年轻的可能性。
- non-youngs/s指标仅适用于旧页面。它基于页面访问次数。如果在执行大型表扫描时没有看到更高的 non-youngs/s值(以及更高的youngs/s值),请增加延迟值。
- young-making速率考虑了所有缓冲池页面访问,而不仅仅是旧子列表中页面的访问。young-making速率和 not速率通常不会增加总缓冲池命中率。旧子列表中的页面命中会导致页面移动到新子列表,但新子列表中的页面命中会导致页面移动到列表的头部,前提是它们与头部有一定距离。
- not (young-making rate)表示未使得页面年轻化的访问比率(导致的原因包括不合理的innodb_old_blocks_time延迟时间(该延迟时间的本意是防止突发的表扫描导致LRU列表大幅移动)和处于新子列表中而未被移动到首部的页面) 。这个比率考虑了所有缓冲池页面访问,而不仅仅是旧子列表中页面的访问。
2. Change Buffer
写缓冲区是一种特殊的数据结构,当二级索引页面不在缓冲池中时 ,它会缓存对这些页面的更改。缓冲区变化可能来源于Insert、Update或是Delete操作(DML),即当这些操作的相关页面不在缓存池中时,我们并不立即将它们从磁盘中取出,而是记录这些操作带来的changes,当页面被其他操作加载进缓冲池时,这些changes也会被合并进缓冲池
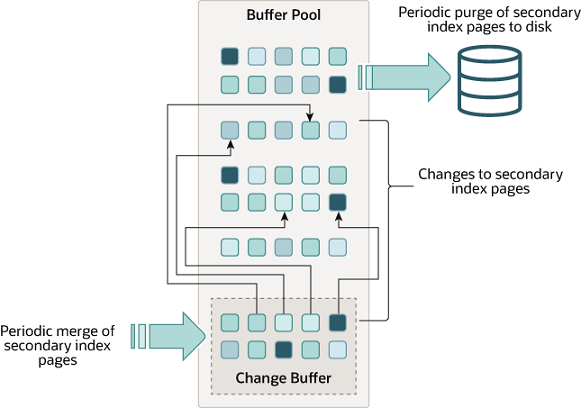
- 与聚集索引不同,二级索引通常是非唯一的,并且二级索引的插入往往以相对随机的顺序发生。类似地,删除和更新可能会影响索引树中不相邻的二级索引页面。当受影响的页面被其他操作读入缓冲池时,我们才将缓存的更改信息合并进缓冲池,避免了将二级索引页面从磁盘读入缓冲池所需的大量随机访问 I/O。
- 在系统大部分空闲或缓慢关闭期间,运行着的清除(purge)操作会定期将更新的索引页写入磁盘。相比起将每个变更值立即写入磁盘,purge操作可以更有效地为一系列索引值写入磁盘块。
- 当有许多受影响的行和许多二级索引要更新时,写缓冲区合并可能需要几个小时。在此期间,磁盘 I/O 会增加,这可能会导致磁盘绑定查询显着变慢。在事务提交后,甚至在服务器关闭和重新启动之后,写缓冲区合并也可能继续发生。
- 在内存中,写缓冲区占据了缓冲池的一部分。在磁盘上,写缓冲区是系统表空间的一部分,其中索引更改在数据库服务器关闭时被缓冲。
- 缓存在写缓冲区中的数据类型由 innodb_change_buffering变量控制。
- 如果索引包含降序索引列或主键包含降序索引列,则二级索引不支持写缓冲。
- Q: 为什么写缓冲区只能存储二级索引的更改数据,而不能用于聚集索引呢?
A: 聚集索引以主键为搜索码,每个索引项都是唯一的,当进行写操作时,如果聚集索引不在缓冲区内,必须先将其从磁盘引入,进行唯一性校验,因此无法使用写缓存 - 写缓存适用于满足以下条件的业务场景:
- 数据库中非唯一索引占多数
- 业务需求大多为写操作(包括插入、更改和删除),且不要求在写入后立刻查询
典型的例子是账单流水记录
Configuring Change Buffering
写缓存相关的参数有innodb_change_buffer_max_size和innodb_change_buffering
innodb_change_buffer_max_size
配置写缓冲的大小,占整个缓冲池的比例,默认值是25%,最大值是50%。
innodb_change_buffering
配置哪些写操作将会启用写缓冲,默认值为all
- all
默认值:缓冲区插入、删除标记操作和清除。 - none
不缓冲任何操作。 - inserts
缓冲插入操作。 - deletes
缓冲删除操作。 - changes
缓冲插入和删除操作。 - purges
缓冲后台发生的物理删除操作。
3. Adaptive Hash Index
自适应散列索引能够InnoDB在系统上执行更像内存数据库,使其具有适当的工作负载和足够的内存用于缓冲池,而不会牺牲事务功能或可靠性。自适应哈希索引由 innodb_adaptive_hash_index 变量启用,或在服务器启动时通过 --skip-innodb-adaptive-hash-index命令关闭。
根据观察到的搜索模式,使用索引键的前缀构建哈希索引。前缀可以是任意长度,也可能只有B树中的一些值出现在哈希索引中。哈希索引是针对经常访问的索引页面的需求而构建的。
如果一个表几乎完全适合主内存,哈希索引通过启用任一元素的直接查找来加速查询,将索引值转换为一种指针。 InnoDB具有监视索引搜索的机制,它会自动构建有益于优化查询的哈希索引
对于某些工作负载,哈希索引查找的加速大大超过了监控索引查找和维护哈希索引结构的额外工作。在繁重的工作负载(例如多个并发连接)下,对自适应哈希索引的访问有时会引发争端。带有 LIKE运算符和% 通配符的查询也往往不会受益。对于不能从自适应哈希索引中受益的工作负载,关闭它可以减少不必要的性能开销。因为很难提前预测自适应哈希索引是否适合特定系统和工作负载,请考虑在启用和禁用它的情况下运行基准测试。
自适应哈希索引特征被分区。每个索引都绑定到一个特定的分区,每个分区都由一个单独的锁存器保护。分区由 innodb_adaptive_hash_index_parts 变量控制。该 innodb_adaptive_hash_index_parts 变量默认设置为 8。最大设置为 512。
我们可以在SHOW ENGINE INNODB STATUS命令输出的SEMAPHORES(信号量)部分获取自适应哈希索引的使用和争用信息
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 68581015, signal count 218437328
--Thread 140653057947392 has waited at btr0pcur.c line 437 for 0.00 seconds the semaphore:
S-lock on RW-latch at 0x7ff536c7d3c0 created in file buf0buf.c line 916
a writer (thread id 140653057947392) has reserved it in mode exclusive
Mutex spin waits 1157217380, rounds 1783981614, OS waits 10610359
RW-shared spins 103830012, rounds 1982690277, OS waits 52051891
RW-excl spins 43730722, rounds 602114981, OS waits 3495769
- OS WAIT ARRAY INFO: reservation count 68581015, signal count 218437328
这行给出了关于操作系统等待数组的信息,它是一个插槽数组,innodb在数组里为信号量保留了一些插槽,操作系统用这些信号量给线程发送信号,使线程可以继续运行,以完成它们等着做的事情,这一行还显示出innodb使用了多少次操作系统的等待:
保留统计(reservation count)显示了innodb分配插槽的频度,
信号计数(signal count)衡量的是线程通过数组得到信号的频度,
操作系统的等待相对于空转等待(spin wait)。
- Thread 140653057947392 has waited at btr0pcur.c line 437 for 0.00 seconds the semaphore:
这部分显示的是当前正在等待互斥量的innodb线程,在这里可以看到有两个线程正在等待,每一个都是以–Thread has waited…开始,这一段内容在正常情况下应该是空的(即查看的时候没有这部分内容),除非服务器运行着高并发的工作负载,促使innodb采取让操作系统等待的措施
- 计数器信息
Mutex spin waits 1157217380, rounds 1783981614, OS waits 10610359 #这行显示的是跟互斥量相关的几个计数器
RW-shared spins 103830012, rounds 1982690277, OS waits 52051891 #这行显示读写的共享锁的计数器
RW-excl spins 43730722, rounds 602114981, OS waits 3495769 #这行显示读写的排他锁的计数器
innodb有着一个多阶段等待的策略,首先,它会试着对锁进行空转等待,如果经历了一个预设的空转等待周期(设置innodb_sync_spin_loops配置变量命令)之后还没有成功,那就会退到更昂贵更复杂的等待数组中。
Comparison of B-Tree and Hash Indexes
B树索引支持=、>、>=、<、<=或是Between等操作符,也支持通过Like “XXX%”语句匹配任意键的前缀,由于顺序存储的缘故,适用于范围查询
SELECT * FROM tbl_name WHERE key_col LIKE 'Patrick%';
SELECT * FROM tbl_name WHERE key_col LIKE 'Pat%_ck%';
相对的,哈希索引只能进行相等性比较,即支持=和<=>操作符(<=>与=的不同之处在于前者支持null,如null<=>null=1,后者涉及null的比较结果全都是null)
此外,mysql不支持前缀索引,仅支持全键索引,也无法通过索引加快Order By语句的速度(因为无法保证相邻值的hashcode值相等,故hash索引不适用于范围查询)
4. Log Buffer
日志缓冲区是保存要写入磁盘上日志文件的数据的内存区域。
日志缓冲区大小由 innodb_log_buffer_size变量定义。默认大小为 16MB。日志缓冲区的内容会定期刷新到磁盘。大型日志缓冲区使大型事务能够运行,而无需在事务提交之前将重做日志数据写入磁盘。因此,如果有更新、插入或删除许多行的事务,则增加日志缓冲区的大小可以节省磁盘 I/O。
innodb_flush_log_at_trx_commit 变量控制日志缓冲区的内容如何写入和刷新到磁盘。innodb_flush_log_at_timeout 变量控制日志刷新频率。
三、On-Disk Structures
1 Tables
1.1 Creating InnoDB Tables
CREATE TABLE t1 (a INT, b CHAR (20), PRIMARY KEY (a)) ENGINE=InnoDB;
当使用默认存储引擎(InnoDB)时,ENGINE=InnoDB子句是不需要的。可以通过发出以下语句来确定 MySQL 服务器实例上的默认存储引擎:
mysql> SELECT @@default_storage_engine;
+--------------------------+
| @@default_storage_engine |
+--------------------------+
| InnoDB |
+--------------------------+
InnoDB默认情况下,表是在 file-per-table 表空间中创建的。要InnoDB 在InnoDB系统表空间中创建表,请在创建表之前禁用该innodb_file_per_table 变量。要在通用表空间中创建 InnoDB表,请使用 CREATE TABLE … TABLESPACE语法。
Row Formats
InnoDB表的行格式决定了其中的行是如何存储在物理磁盘上的,反过来又会影响查询和DML的性能。InnoDB支持四种行格式,包括:REDUNDANT, COMPACT, DYNAMIC(默认), 和COMPRESSED
行格式设置方式:
CREATE TABLE t1 (c1 INT) ROW_FORMAT=DYNAMIC;
---------------------------------------------
mysql> SET GLOBAL innodb_default_row_format=DYNAMIC;
需要注意的是,COMPRESSED格式不支持在系统表空间中使用,不能设置为默认值,只能在CREATE语句中显式指定。
| Row Format | Compact Storage Characteristics | Enhanced Variable-Length Column Storage | Large Index Key Prefix Support | Compression Support | Supported Tablespace Types |
|---|---|---|---|---|---|
REDUNDANT | No | No | No | No | system, file-per-table, general |
COMPACT | Yes | No | No | No | system, file-per-table, general |
DYNAMIC | Yes | Yes | Yes | No | system, file-per-table, general |
COMPRESSED | Yes | Yes | Yes | Yes | file-per-table, general |
各个的行格式的特征尚未翻译,详见:
InnoDB 行格式
Primary Keys
建议为创建的每个表定义一个主键。选择主键列时,选择具有以下特征的列:
- 最重要的查询引用的列。
- 永远不会留空的列。
- 不具有重复值的列。
- 插入后很少更改值的列。
例如,在包含人员信息的表中,您不会在其上创建主键(firstname, lastname),因为可以有多个人具有相同的姓名,姓名列可能留空,有时人们会更改姓名。由于有如此多的约束,通常没有一组明显的列可用作主键,因此您创建一个具有数字 ID 的新列作为主键的全部或部分。您可以声明一个 自动增量列,以便在插入行时自动填充升序值:
# The value of ID can act like a pointer between related items in different tables.
CREATE TABLE t5 (id INT AUTO_INCREMENT, b CHAR (20), PRIMARY KEY (id));
# The primary key can consist of more than one column. Any autoinc column must come first.
CREATE TABLE t6 (id INT AUTO_INCREMENT, a INT, b CHAR (20), PRIMARY KEY (id,a));
Viewing InnoDB Table Properties
mysql> SHOW TABLE STATUS FROM test LIKE 't%' \G;
*************************** 1. row ***************************
Name: t1
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 0
Avg_row_length: 0
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: NULL
Create_time: 2021-02-18 12:18:28
Update_time: NULL
Check_time: NULL
Collation: utf8mb4_0900_ai_ci
Checksum: NULL
Create_options:
Comment:
-
Name
表的名称 -
Engine
表的存储引擎 -
Version
此列未使用。随着 .frmMySQL 8.0 中文件的删除,此列现在报告硬编码值10,这是 MySQL 5.7 中使用的最后一个.frm文件版本 -
Row_format
行存储格式 ( Fixed, Dynamic, Compressed, Redundant, Compact) -
Rows
行数。一些存储引擎,例如 MyISAM,存储确切的计数。对于其他存储引擎,例如InnoDB,这个值是一个近似值,可能与实际值相差 40% 到 50%。在这种情况下,请使用 SELECT COUNT(*)以获得准确的计数。 -
Avg_row_length
平均行长 -
Data_length
对于MyISAM, Data_length是数据文件的长度,以字节为单位。
对于InnoDB, Data_length是为聚集索引分配的近似空间量,以字节为单位。具体来说,它是聚集索引大小(以页面为单位)乘以InnoDB页面大小。 -
Max_data_length
对于MyISAM, Max_data_length是数据文件的最大长度。给定使用的数据指针大小,这是可以存储在表中的数据总字节数。
未用于InnoDB. -
Index_length
对于MyISAM, Index_length是索引文件的长度,以字节为单位。
对于InnoDB, Index_length是为非聚集索引分配的近似空间量,以字节为单位。具体来说,它是非聚集索引大小的总和(以页面为单位)乘以InnoDB页面大小。 -
Data_free
已分配但未使用的字节数。
InnoDBtables 报告该表所属的表空间的可用空间。对于位于共享表空间中的表,这是共享表空间的空闲空间。如果您使用多个表空间并且该表有自己的表空间,则可用空间仅用于该表。空闲空间是指完全空闲范围中的字节数减去安全裕度。即使可用空间显示为 0,只要不需要分配新的扩展区,就可以插入行。
对于 NDB Cluster,Data_free显示磁盘上为磁盘数据表或磁盘上的片段分配但未使用的空间。(按Data_length列报告内存中数据资源的使用情况。) -
Auto_increment
下一个AUTO_INCREMENT值 -
Create_time
创建表的时间 -
Update_time
上次更新数据文件的时间。对于某些存储引擎,此值为NULL. 例如, 在InnoDB系统表空间中存储多个表, 数据文件时间戳不适用。即使使用每个表在单独文件中的file-per-table 模式,写缓冲也会延迟对数据文件的写入,因此文件修改时间与上次插入、更新或删除的时间不同。MyISAM使用数据文件时间戳,但在 Windows 上,时间戳不会被更新更新,因此该值不准确。
Update_time显示未分区表上最后一个UPDATE、 INSERT或 DELETE执行 的时间戳值。对于 MVCC,时间戳值反映了 COMMIT时间,也就是最后一次更新时间。当服务器重新启动或表从InnoDB的数据字典缓存中被逐出时,时间戳不会保留。 -
Check_time
上次检查表的时间。这次并非所有存储引擎都更新,在这种情况下,该值始终为 NULL.
对于分区InnoDB表, Check_time总是 NULL. -
Collation
表默认排序规则。输出没有明确列出表默认字符集,但排序规则名称以字符集名称开头 -
Checksum
实时校验和值(如果有) -
Create_options
与CREATE TABLE一起使用的额外选项,显示分区表的分区 -
Comment
创建表时使用的注释















 2191
2191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









