






目录
1、项目业务场景示例
例如下图是京东上某个商品的连接,我用红色框框起来的其实是这个商品的唯一编号SKU
那这个页面,我们后台应该是如何把数据展示出来的呢? 我们可以根据下图所示的流程进行访问:
1.应用程序先从Redis中获取,如果能获取到就直接返回。 2.如果在Redis中获取不到,就从数据库中根据编号进行查询,查询出来之后放入到Redis缓存,然后返回

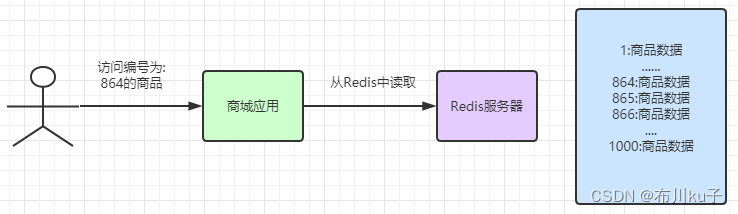
经过长时间积累,我们的Redis服务中存储的数据可能是这样子的
假设我们商城中只有1000个商品,所以最终在Redis中会存储0~1000个商品数据
2 、业务场景存在的问题
目前的架构存在一些问题,比如一些同行、一些恶意的对手、或者第三方公司的爬虫机器人对我们的系统短时间内进行批量的查询,而这些编号是数据库中不存在的,如下图所示:

短时间发起的大量请求查询数据库中不存在的商品,由于商城应用先会访问Redis服务器,Redis服务器中并没有这个商品数据,从而到数据空进行查询。由于大量的请求在Redis中都无法获取到数据,所以这些请求都落到了数据库中(数据库对于这种瞬时超高访问承载能力是不强的,这样就会导致数据库宕机。
恶意用户在短时间内大量查询不存在的数据,导致大量请求被送达数据库进行查询,当请求数量超过数据库负载上限时,使系统响应出现高延迟甚至瘫痪的攻击行为称为 (缓存穿透攻击)
3 、什么是布隆过滤器?
布隆过滤器是巴顿.布隆于一九七零年提出的,其主旨是采用一个很长的二进制数组,通过一系列的Hash函数来确定该数据是否存在.
接下来我们看看布隆过滤器是如何工作的.
-
初始化布隆过滤器的数组(只存放0和1的数据)
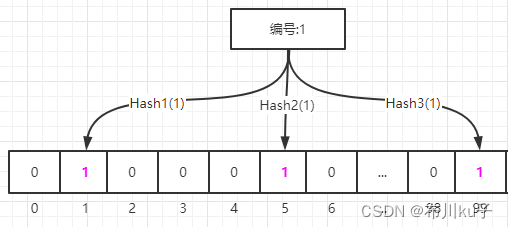
-
添加1号商品数据
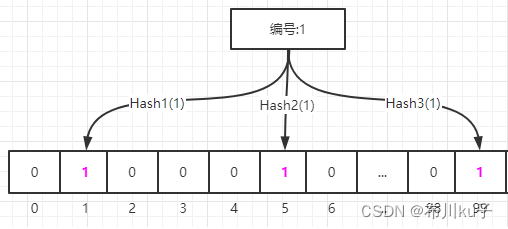
编号为1的数据需要进行三个Hash函数的计算 通过Hash1函数计算出索引位置为1,就把索引位置1的元素从0变成1. 通过Hash2函数计算出索引位置为5,就把索引位置5的元素从0变成1. 通过Hash3函数计算出索引位置为99,就把索引位置99的元素从0变成1.
-
添加2号商品数据
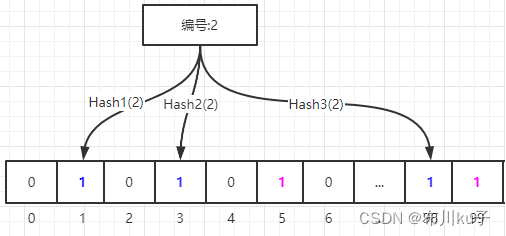
编号为2的数据需要进行三个Hash函数的计算 通过Hash1函数计算出索引位置为1,因为这个位置已经为1了,所以就不变了. 通过Hash2函数计算出索引位置为3,就把索引位置3的元素从0变成1. 通过Hash3函数计算出索引位置为98,就把索引位置98的元素从0变成1. 一般来说,不同的key计算出的hash值是不一样的,但是计算出来的位置可能是一样的,如果不同的key通过hash函数计算出来的索引位置是一样的,我们称为Hash冲突. 一般是通过这样方式计算索引位置的: hash(key) % 数组长度 = [0,数组长度-1]范围的值 比如现在数组长度是100,目前有两个key分别是key1和key2 Hash(key1)=1 Hash(key2)=101 通过hash函数计算出来的这两个key的hash值确实不一样,但是他们算出的索引位置确实一样的. 1 % 100 = 1 101 % 100 = 1
-
布隆过滤器初始化完1000个商品后
布隆过滤器的判断过程:
我们在前面的步骤中完成了布隆过滤器的数据初始化,接下来看看布隆过滤器是如何判断数据是否存在呢?
-
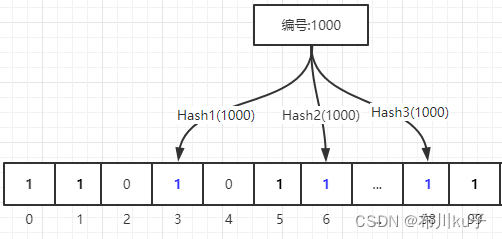
判断编号为1000的商品是否存在?

在查询1000号数据是否存在的时候 通过Hash1函数计算出索引位置3,判断这个位置上的元素数值是否为1 通过Hash2函数计算出索引位置6,判断这个位置上的元素数值是否为1 通过Hash3函数计算出索引位置98,判断这个位置上的元素数值是否为1 当每个索引位置的数值都为1的情况下,说明这个商品是【可能】存在的.
-
判断编号为8888的商品是否存在?

通过三次的Hash函数,发现并不是所有索引位置上的索引元素都为1,说明编号为8888的元素一定是不存在的.
总结来说: 1.某个商品编号在布隆过滤器中通过hash函数计算出来的索引位置的数值都为1,说明该编号的商品【可能】存在 2.某个商品编号在布隆过滤器中通过hash函数计算出来的索引位置的数值只要出现一个0,说明该编号的商品一定不存在 布隆过滤器在一开始设计之初就不是精确的判断,存在一定的误差值,这个误差值是可以进行控制的.
-
布隆过滤器误判的情况

我们现在查询8889这个不存在的数据,这个数据是不存在的,但是通过三个hash函数计算出来的索引位置都为1. 尽管在数据库中8889这个数据是不存在的,但是在布隆过滤器中会被判断为存在.这个就是在布隆过滤器中存在的小概率误判情况.
-
是如何造成误判的呢?
-
数组长度短容易造成误判的情况
比如现在数组长度为3
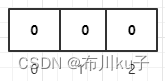
现在添加编号为1的商品,三个hash函数计算出来的值分别为Hash1(1)=9、Hash2(1)=13、Hash3(1)=25
这三个hash值计算出来的索引位置分别为9%3=0、13%3=1、25%3=1
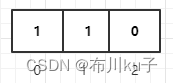
现在添加编号为2的商品,三个hash函数计算出来的值分别为Hash1(2)=52、Hash2(3)=2、Hash3(1)=33
这三个hash值计算出来的索引位置分别为52%3=0、2%3=2、33%3=0
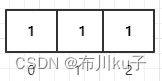
我们添加完两个商品编号之后,发现数组上所有位置的值都为1了。意味后续我们使用不存在的编号判断都存在误判,都将返回商品编号存在的结果.
比如现在判断编号为88的商品是否存在,三个hash函数计算出来的值分别为Hash1(88)=65、Hash2(88)=133、Hash3(88)=204
这三个hash值计算出来的索引位置分别为65%3=2、133%3=1、204%3=0。数组索引位置为1,2的值都为1.
如果我们增大数组长度呢?
比如现在数组长度为6
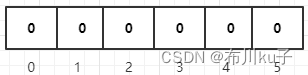
现在添加编号为1的商品,三个hash函数计算出来的值分别为Hash1(1)=9、Hash2(1)=13、Hash3(1)=25
这三个hash值计算出来的索引位置分别为9%6=3、13%6=1、25%3=1

现在添加编号为2的商品,三个hash函数计算出来的值分别为Hash1(2)=52、Hash2(3)=2、Hash3(1)=33
这三个hash值计算出来的索引位置分别为52%6=4、2%6=2、33%6=3
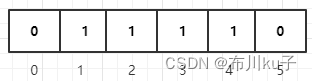
比如现在判断编号为88的商品是否存在,三个hash函数计算出来的值分别为Hash1(88)=65、Hash2(88)=133、Hash3(88)=204
这三个hash值计算出来的索引位置分别为65%6=5、133%6=1、204%6=0。此时索引为1,5的位置的元素为0,判断这个元素并不存在.
通过上面的结果可以看出,数组长度会影响误判率,数组长度越小,误判率越高.
-
hash函数个数太少,也容易造成误判.
我们前面的定义的布隆过滤器的Hash函数个数为3,这个Hash函数个数是可以自定义了.为了方便理解,假设现在布隆过滤器只有一个Hash函数会出现什么情况呢?
比如现在数组长度为100

现在添加编号为1的商品,hash函数计算出来的值为Hash1(1)=3,计算出来的索引位置为3%100=3

现在判断编号为73的商品是否存在,hash函数计算出来的值为Hash1(73)=203,计算出来的索引位置为203%100=3,布隆过滤器判断编号为73这个元素是存在的,出现了误判的情况。原因是只用一个hash函数非常容易出现hash冲突的问题,一旦hash冲突就容易误判.
比如现在我们给布隆过滤器增加到两个hash函数.
现在添加编号为1的商品,2个hash函数计算出来的值分别为Hash1(1)=3,Hash1(1)=305,计算出来的索引位置分别为3%100=3、305%100=5

现在判断编号为73的商品是否存在,2个hash函数计算出来的值分别为Hash1(73)=203,Hash2(73)=98计算出来的索引位置为203%100=3、98%100=98,此时布隆过滤器判断编号为73的元素不存在.
通过上面的结果可以得出,hash函数个数越多,不同元素计算出来的索引位置完全一样的概率也越小.
-
-
减少误判的措施
-
增加二进制数组位数(会增加存储空间)
-
增加Hash次数(CPU需要进行更多运算,会让布隆过滤器的性能降低)
-
4 、如何使用布隆过滤器?
像布隆过滤器这种经典的算法,在Redis中已经做了集成和封装了.我们可以通过提供好的API非常简单的使用布隆过滤器
-
添加依赖
<dependency> <groupId>org.redisson</groupId> <artifactId>redisson-all</artifactId> <version>3.16.0</version> </dependency> -
编写实现逻辑
@Test public void testBloomFilter(){ Config config = new Config(); config.useSingleServer().setAddress("redis://127.0.0.1:6379"); //构造Redisson RedissonClient redisson = Redisson.create(config); RBloomFilter<Object> bloomFilter = redisson.getBloomFilter("bloom"); //初始化布隆过滤器:预计元素为1000000,误判率为1% bloomFilter.tryInit(1000000L,0.01); bloomFilter.add("1");//增加元素 //判断指定编号是否存在布隆过滤器中 System.out.println(bloomFilter.contains("1"));//输出true System.out.println(bloomFilter.contains("8888"));//输出false }
5 、项目中使用流程

















 8473
8473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









