







背景
客户需要将 Elasticsearch 集群无缝迁移到移动云,迁移过程要保证业务的最小停机时间。
实现方式
通过采用成熟的 INFINI 网关来进行数据的双写,在集群的切换恢复过程中来记录数据变更,待全量数据恢复之后再追平后面增量数据,追平增量之后,进行校验确保数据一致再进行流量的切换。
总体流程
总体迁移流程如下:
- 客户业务代码,切流量,双写。(新增的变更都会记录在网关本地,但是暂停消费到移动云)
- 暂停网关移动云这边的增量数据消费。
- 迁移 11 月的数据,快照,快照上传到 S3 。
- 下载 S3 的文件到移动云。
- 恢复快照到移动云的 11 月份的索引。
- 开启网关移动云这边的增量消费。
- 等待增量追平(接近追平)。
- 按照时间条件(如:时间 A,当前时间往前 30 分钟),验证文档数据量,Hash 校验等等。
- 停业务的写入,网关,腾讯云的写入(10 分钟)。
- 等待剩余的增量追完。
- 对时间 A 之后的,增量进行校验。
- 切换所有流量到移动云,业务端直接访问移动云 ES。
总体的迁移时间:
- 11 月备份时间(30 分钟)19 号开始
- 备份下载到移动云的时间(2-3 天)
- 备份恢复到移动云集群的时间(30 分钟)
- 11 月份增量备份(20 分钟)(双写开始)(21 号)
- 11 月份增量下载到移动云(6 小时)
- 11 月份增量恢复时间(20 分钟)
- 追增量数据(8 个小时产生的数据,需要 1 个小时)
- 校验比对(存量 1 个小时)
- 流量暂停,增量的校验(10 分钟)
- 切换(1 分钟)
总体流程如下示意图:

ES 集群信息
- ES 版本 7.10.1
- 2 个热节点 3 个温节点 总数 1.9 TB
- 索引 1041,分片 2085
- 无自定义插件
- 有 update_bu_query 使用
- 有 delete_by_query 使用
- 吞吐量没有测试过,当前日增文档数 1 千多万,目标日增加上亿
迁移操作手册(参考)
环境
- 自建 ES 5.4.2
- 自建 ES 5.6.8
- 自建 ES 7.5.0
- 极限网关服务器 1
- 极限网关服务器 2
- 云端负载均衡 1 (监听 9200 端口,指向极限网关服务器 1/2 的 8000 端口)
- 云端负载均衡 2 (监听 9200 端口,指向极限网关服务器 1/2 的 8001 端口)
场景描述
若干个自建 Elasticsearch 集群需要平滑迁移到移动云,业务不停写、不做代码改动。
数据架构
通过将应用端流量走网关的方式,请求同步转发给自建 ES,网关记录所有的写入请求,并确保顺序在云端 ES 上重放请求,两侧集群的各种故障都妥善进行了处理,从而实现透明的集群双写,实现安全无缝的数据迁移。
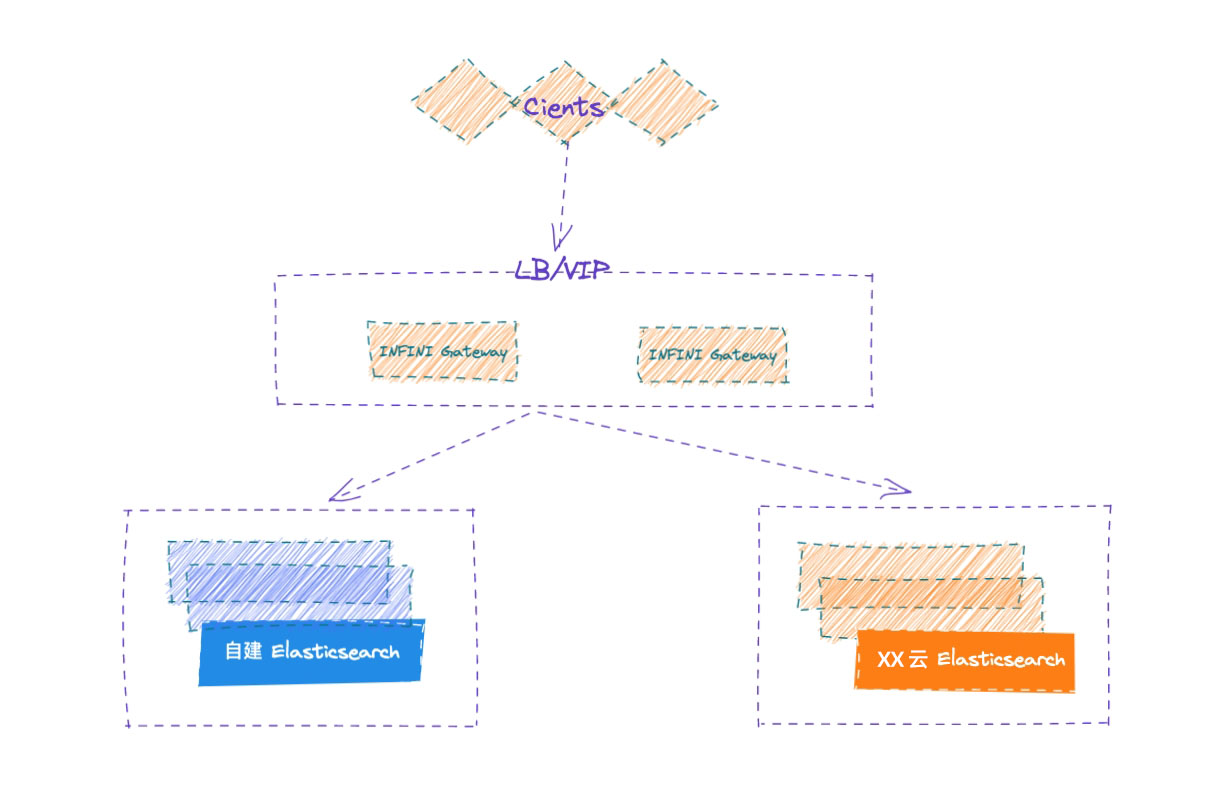
业务端如果已经部署在云上,可以使用云上的 SLB 服务来访问网关,确保后端网关的高可用,如果业务端和极限网关还在企业内网,可以使用极限网关自带的 4 层浮动 IP 来确保网关的高可用。
数据描述
以数据从自建集群 5.4.2 迁移到云上的 5.6.16 为例进行说明,执行步骤依次说明。
执行步骤
部署 INFINI Gateway
为了保证数据的无缝透明迁移,通过 INFINI Gateway 来进行双写。
-
系统调优
参考此文档。
-
下载程序
[root@iZbp1gxkifg8uetb33pvcoZ ~]# mkdir /opt/gateway
[root@iZbp1gxkifg8uetb33pvcoZ ~]# cd /opt/gateway/
[root@iZbp1gxkifg8uetb33pvcoZ gateway]# wget http://release.infinilabs.com/gateway/snapshot/gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz
--2022-05-19 10:16:25-- http://release.infinilabs.com/gateway/snapshot/gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz
正在解析主机 release.infinilabs.com (release.infinilabs.com)... 120.79.205.193
正在连接 release.infinilabs.com (release.infinilabs.com)|120.79.205.193|:80... 已连接。
已发出 HTTP 请求,正在等待回应... 200 OK
长度:7430568 (7.1M) [application/octet-stream]
正在保存至: “gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz”
100%[==============================================================================================================================================>] 7,430,568 22.8MB/s 用时 0.3s
2022-05-19 10:16:25 (22.8 MB/s) - 已保存 “gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz” [7430568/7430568])
[root@iZbp1gxkifg8uetb33pvcoZ gateway]# tar vxzf gateway-1.6.0_SNAPSHOT-649-linux-amd64.tar.gz
gateway-linux-amd64
gateway.yml
sample-configs/
sample-configs/elasticsearch-with-ldap.yml
sample-configs/indices-replace.yml
sample-configs/record_and_play.yml
sample-configs/cross-cluster-search.yml
sample-configs/kibana-proxy.yml
sample-configs/elasticsearch-proxy.yml
sample-configs/v8-bulk-indexing-compatibility.yml
sample-configs/use_old_style_search_response.yml
sample-configs/context-update.yml
sample-configs/elasticsearch-route-by-index.yml
sample-configs/hello_world.yml
sample-configs/entry-with-tls.yml
sample-configs/javascript.yml
sample-configs/log4j-request-filter.yml
sample-configs/request-filter.yml
sample-configs/condition.yml
sample-configs/cross-cluster-replication.yml
sample-configs/secured-elasticsearch-proxy.yml
sample-configs/fast-bulk-indexing.yml
sample-configs/es_migration.yml
sample-configs/index-docs-diff.yml
sample-configs/rate-limiter.yml
sample-configs/async-bulk-indexing.yml
sample-configs/elasticssearch-request-logging.yml
sample-configs/router_rules.yml
sample-configs/auth.yml
sample-configs/index-backup.yml
将网关提供的示例配置拷贝,并根据实际集群的信息进行相应的修改,如下:
[root@iZbp1gxkifg8uetb33pvcoZ gateway]# cp sample-configs/cross-cluster-replication.yml 5.4.2TO5.6.16.yml
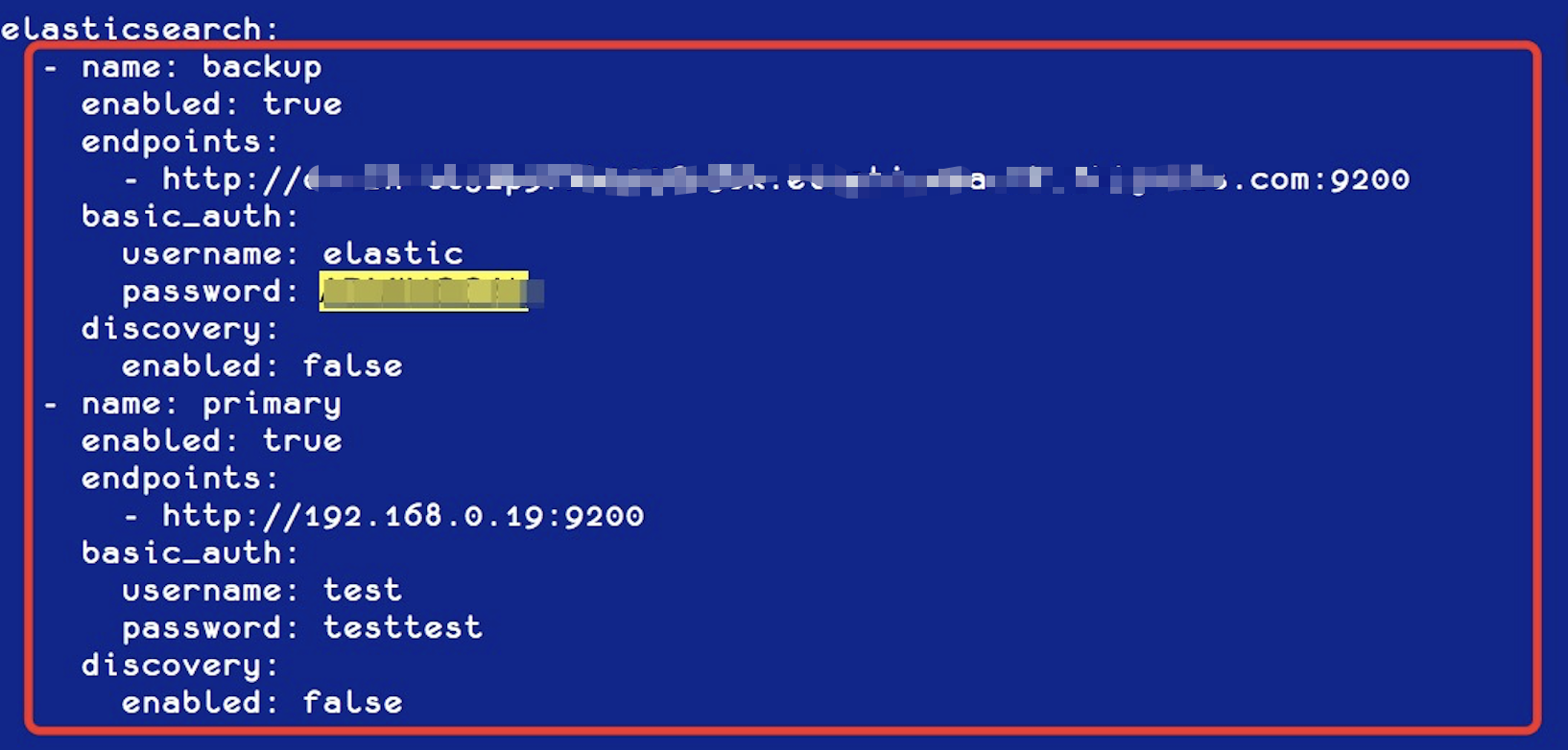
首先修改集群的身份信息,如下:

然后修改集群的注册信息,如下:
根据需要修改网关监听的端口,以及是否开启 TLS (如果应用客户端通过 http 协议访问 ES,请将 entry.tls.enabled 值改为 false),如下:
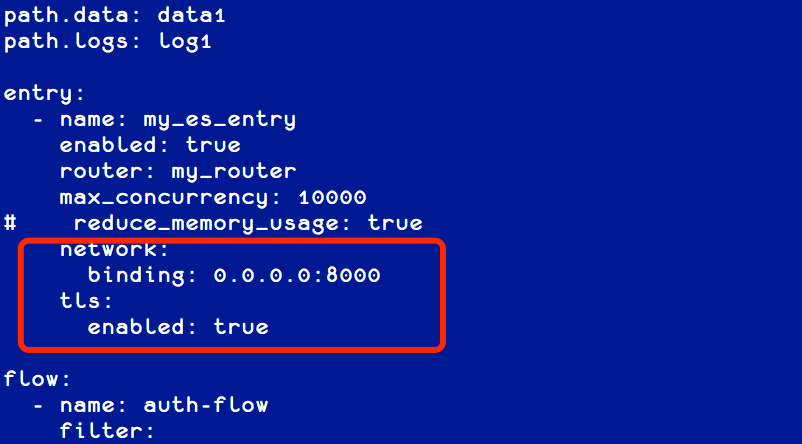
不同的集群可以使用不同的配置,分别监听不同的端口,用于业务的分开访问。
- 启动网关
启动网关并指定刚刚创建的配置,如下:
[root@iZbp1gxkifg8uetb33pvcoZ gateway]# ./gateway-linux-amd64 -config 5.4.2TO5.6.16.yml
___ _ _____ __ __ __ _
/ _ \ /_\ /__ \/__\/ / /\ \ \/_\ /\_/\
/ /_\///_\\ / /\/_\ \ \/ \/ //_\\\_ _/
/ /_\\/ _ \/ / //__ \ /\ / _ \/ \
\____/\_/ \_/\/ \__/ \/ \/\_/ \_/\_/
[GATEWAY] A light-weight, powerful and high-performance elasticsearch gateway.
[GATEWAY] 1.6.0_SNAPSHOT, 2022-05-18 11:09:54, 2023-12-31 10:10:10, 73408e82a0f96352075f4c7d2974fd274eeafe11
[05-19 13:35:43] [INF] [app.go:174] initializing gateway.
[05-19 13:35:43] [INF] [app.go:175] using config: /opt/gateway/5.4.2TO5.6.16.yml.
[05-19 13:35:43] [INF] [instance.go:72] workspace: /opt/gateway/data1/gateway/nodes/ca2tc22j7ad0gneois80
[05-19 13:35:43] [INF] [app.go:283] gateway is up and running now.
[05-19 13:35:50] [INF] [actions.go:358] elasticsearch [primary] is available
[05-19 13:35:50] [INF] [api.go:262] api listen at: http://0.0.0.0:2900
[05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [primary] hosts: [] => [192.168.0.19:9200]
[05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [backup] hosts: [] => [es-cn-tl32p9fkk0006m56k.elasticsearch.aliyuncs.com:9200]
[05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [primary] hosts: [] => [192.168.0.19:9200]
[05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [backup] hosts: [] => [es-cn-tl32p9fkk0006m56k.elasticsearch.aliyuncs.com:9200]
[05-19 13:35:50] [INF] [reverseproxy.go:261] elasticsearch [primary] hosts: [] => [192.168.0.19:9200]
[05-19 13:35:50] [INF] [entry.go:322] entry [my_es_entry/] listen at: https://0.0.0.0:8000
[05-19 13:35:50] [INF] [module.go:116] all modules are started
- 后台运行
[root@iZbp1gxkifg8uetb33pvcoZ gateway]# nohup ./gateway-linux-amd64 -config 5.4.2TO5.6.16.yml &
- 应用授权
curl -XPOST http://localhost:2900/_license/apply -d'
{
"license": "XXXXXXXXXXXXXXXXXXXXXXXXX"
}'
部署 INFINI Console
为了方便在多个集群之间快速切换,使用 INFINI Console 来进行管理。
- 下载安装
[root@iZbp1gxkifg8uetb33pvcpZ console]# wget http://release.infinilabs.com/console/snapshot/console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz
--2022-05-19 10:57:24-- http://release.infinilabs.com/console/snapshot/console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz
正在解析主机 release.infinilabs.com (release.infinilabs.com)... 120.79.205.193
正在连接 release.infinilabs.com (release.infinilabs.com)|120.79.205.193|:80... 已连接。
已发出 HTTP 请求,正在等待回应... 200 OK
长度:13576234 (13M) [application/octet-stream]
正在保存至: “console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz”
100%[==============================================================================================================================================>] 13,576,234 33.2MB/s 用时 0.4s
2022-05-19 10:57:25 (33.2 MB/s) - 已保存 “console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz” [13576234/13576234])
[root@iZbp1gxkifg8uetb33pvcpZ console]# tar vxzf console-0.3.0_SNAPSHOT-596-linux-amd64.tar.gz
console-linux-amd64
console.yml
- 修改配置
[root@iZbp1gxkifg8uetb33pvcpZ console]# cat console.yml
# for the system cluster, please use Elasticsearch v7.3+
elasticsearch:
- name: default
enabled: true
monitored: false
endpoint: http://es-cn-xxxxxxxxxxxxxx.com:9200
basic_auth:
username: elastic
password: XXXXXX
discovery:
enabled: false
...
- 启动服务
[root@iZbp1gxkifg8uetb33pvcpZ console]# ./console-linux-amd64 -service install
Success
[root@iZbp1gxkifg8uetb33pvcpZ console]# ./console-linux-amd64 -service start
Success
- 访问后台
访问该主机的 9000 端口,即可打开 Console 后台,http://x.x.x.x:9000/
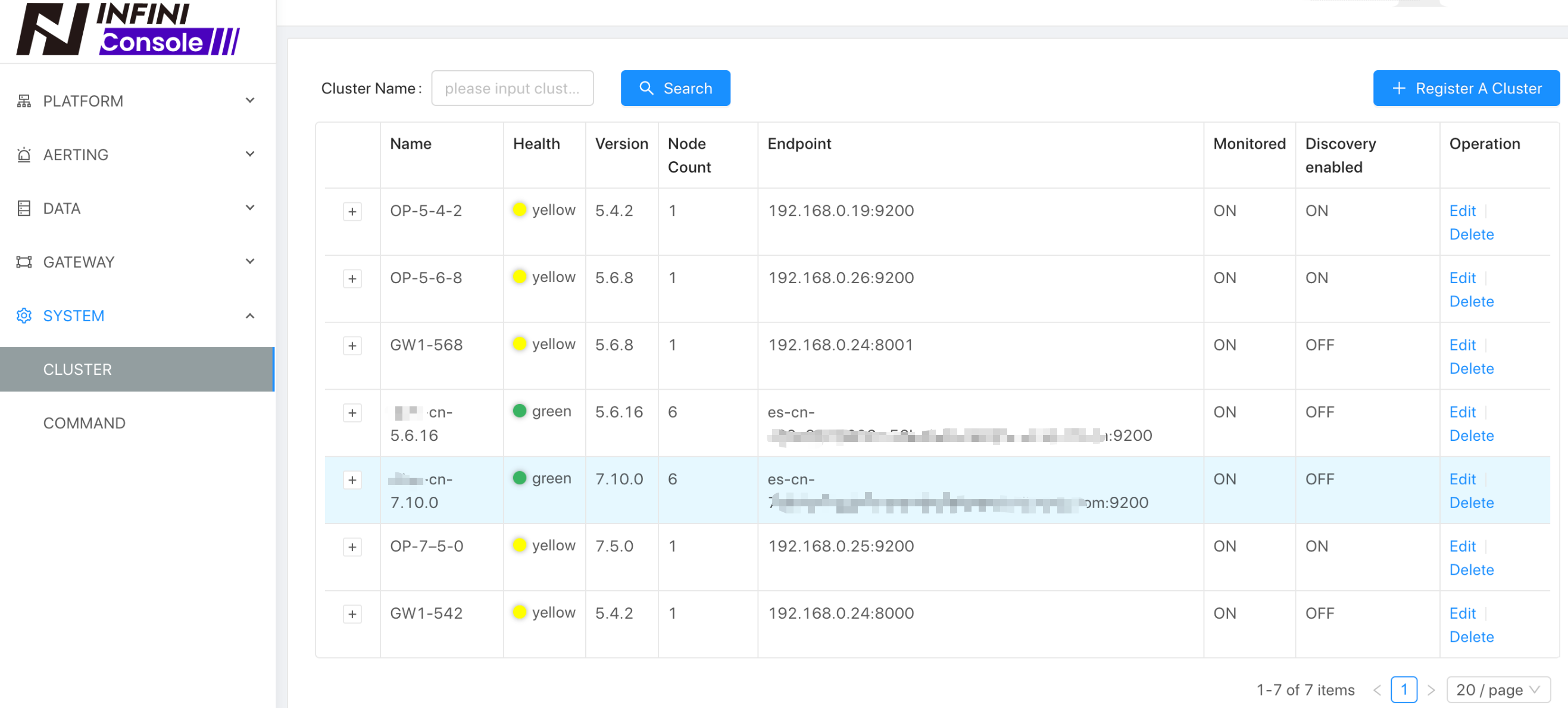
打开菜单 [System][Cluster] ,注册当前需要管理的 Elasticsearch 集群和网关地址,用来快速管理,如下:
测试 INFINI Gateway
为了验证网关是否正常工作,我们通过 INFINI Console 来快速验证一下。
首先通过走网关的接口来创建一个索引,并写入一个文档,如下:
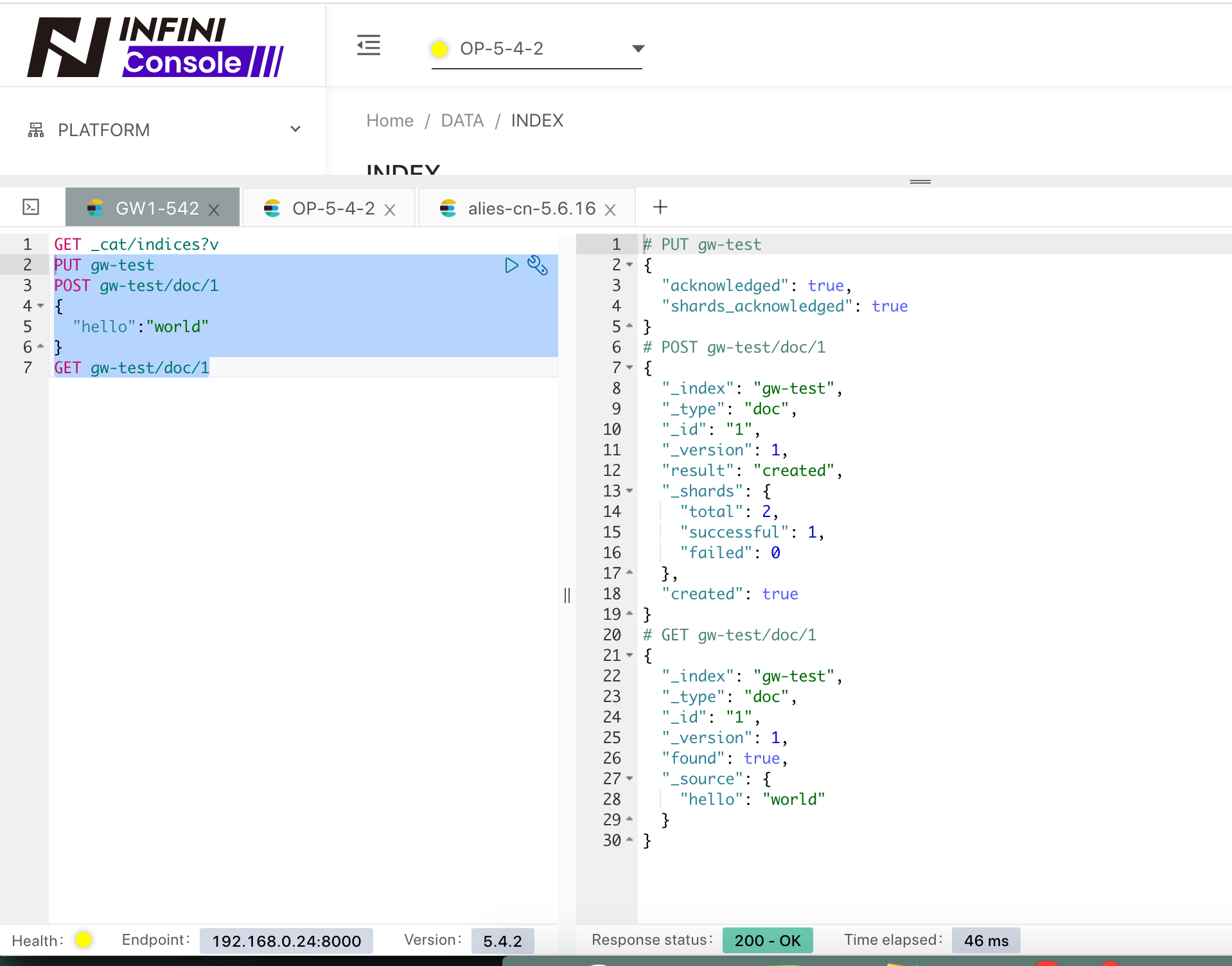
查看 5.4.2 集群的数据情况,如下:

查看集群 5.6.16 的数据情况,如下:

说明网关配置都正常,验证结束。
调整网关的消费策略
因为我们需要在全量数据迁移之后,才能进行增量数据的追加,在全量数据迁移完成之前,我们应该暂停增量数据的消费。修改网关配置里面 Pipeline consume-queue_backup-to-backup和 consume-queue_primary-failure-to-backup的参数 auto_start为 false,表示不自动启动该任务,具体配置方法如下:
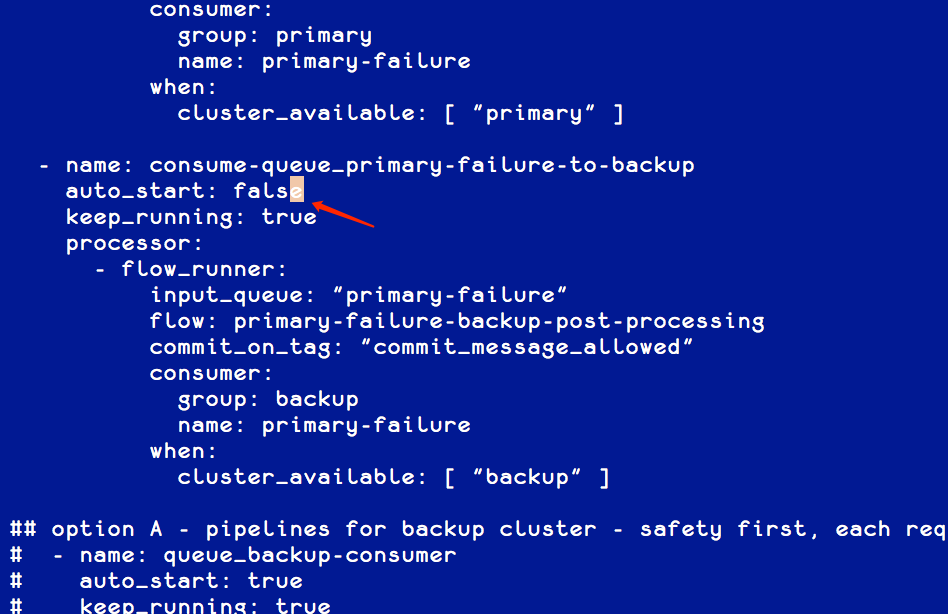

修改完配置之后,需要重新启动网关。
为了方便管理,可以使用 INFINI Console 来注册和管理网关,如下:


待全量迁移完成之后,可以通过后台的 Task 管理来进行后续的任务启动、停止,如下:

切换流量
接下来,将业务正常写的流量切换到网关,也就是需要把之前指向 ES 5.4.2 的地址指向网关的地址,如果 5.4.2 集群开启了身份验证,业务端代码同样需要传递身份信息,和 5.4.2 之前的用法保持不变。

切换流量到网关之后,用户的请求还是以同步的方式正常访问自建集群,网关记录到的请求会按顺序记录到 MQ 里面,但是消费是暂停状态。
如果业务端代码使用的 ES 的 SDK 支持 Sniff,并且业务代码开启了 Sniff,那么应该关闭 Sniff,避免业务端通过 Sniff 直接链接到后端的 ES 节点,所有的流量现在应该都只通过网关来进行访问。
全量数据迁移
在流量迁移到网关之后,我们开始对自建 Elasticsearch 集群的数据进行全量迁移到云端 Elasticsearch 集群。
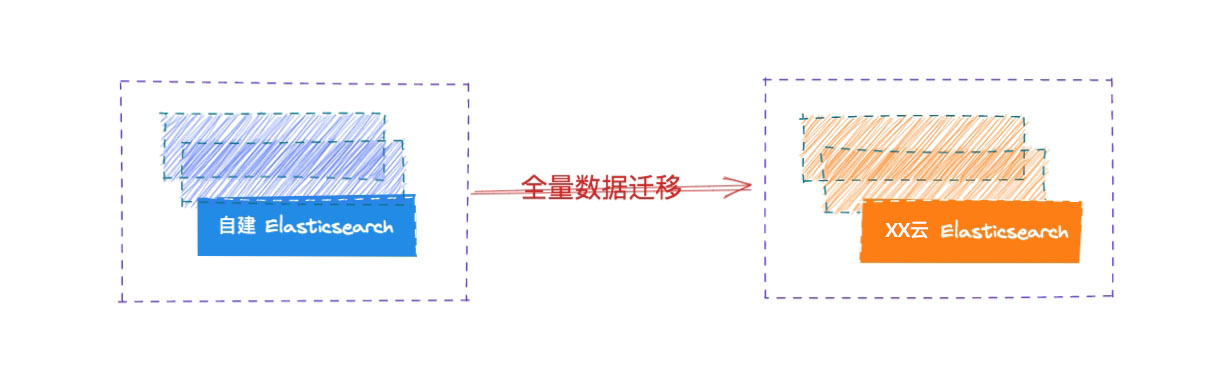
全量迁移已有的数据的方式有很多种:
- 通过快照的方式进行恢复
- 使用工具来导出导入,如: ESM
如果索引数量很多的话,可以按照索引依次进行导入,同时需要注意将 Mapping 和 Setting 提前导入。
以现在 5.4 集群的索引来为例,目前的待迁移索引为 demo_5_4_2,只有4 个文档:

我们使用网关自带的迁移功能来进行数据迁移,拷贝自带的样例文件,如下:
[root@iZbp1gxkifg8uetb33pvcpZ gateway]# cp sample-configs/es_migration.yml 5.4TO5.6.yml
修改其中代表集群和索引的相关配置,可以根据需要配置是否需要重命名索引和统一 Type( 用于跨版本统一 Type),如下图红框位置:

创建好模板和索引,如果目标集群不允许动态创建文档,需要提前创建好索引,如下图:
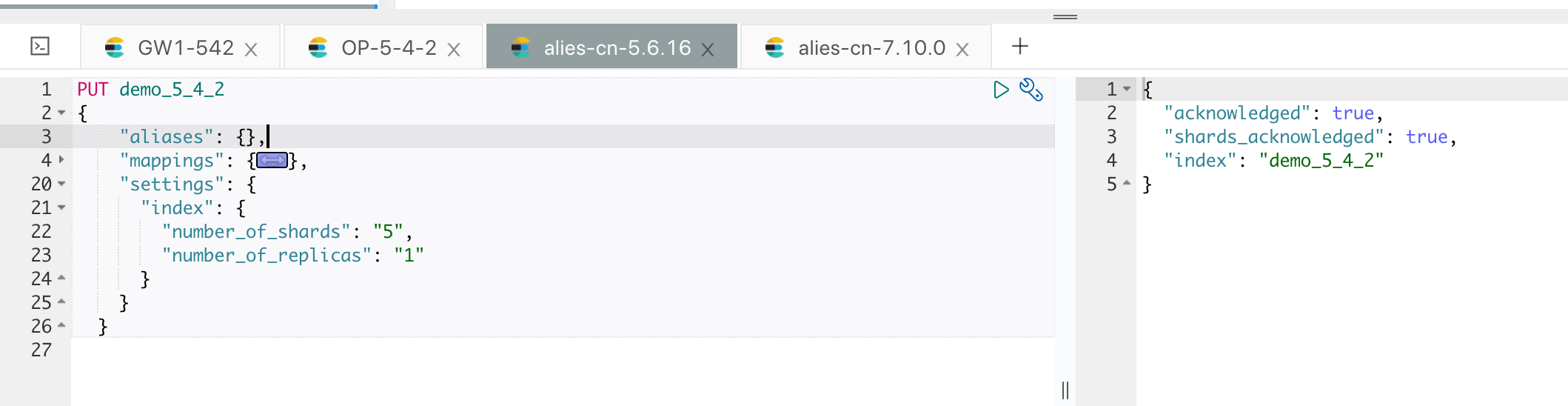
然后就可以开始数据的迁移了,执行网关程序并指定刚刚定义的配置,如下:
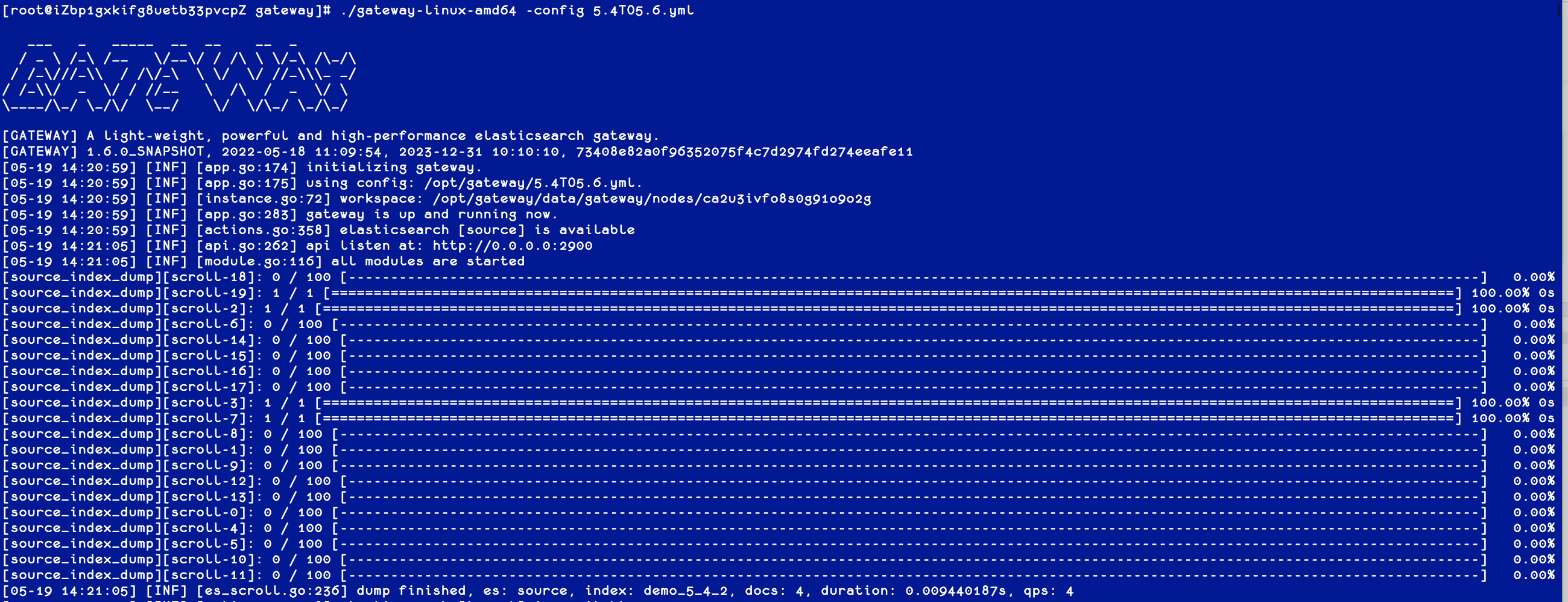
执行完成后,可以确认下数据的情况,如下图:
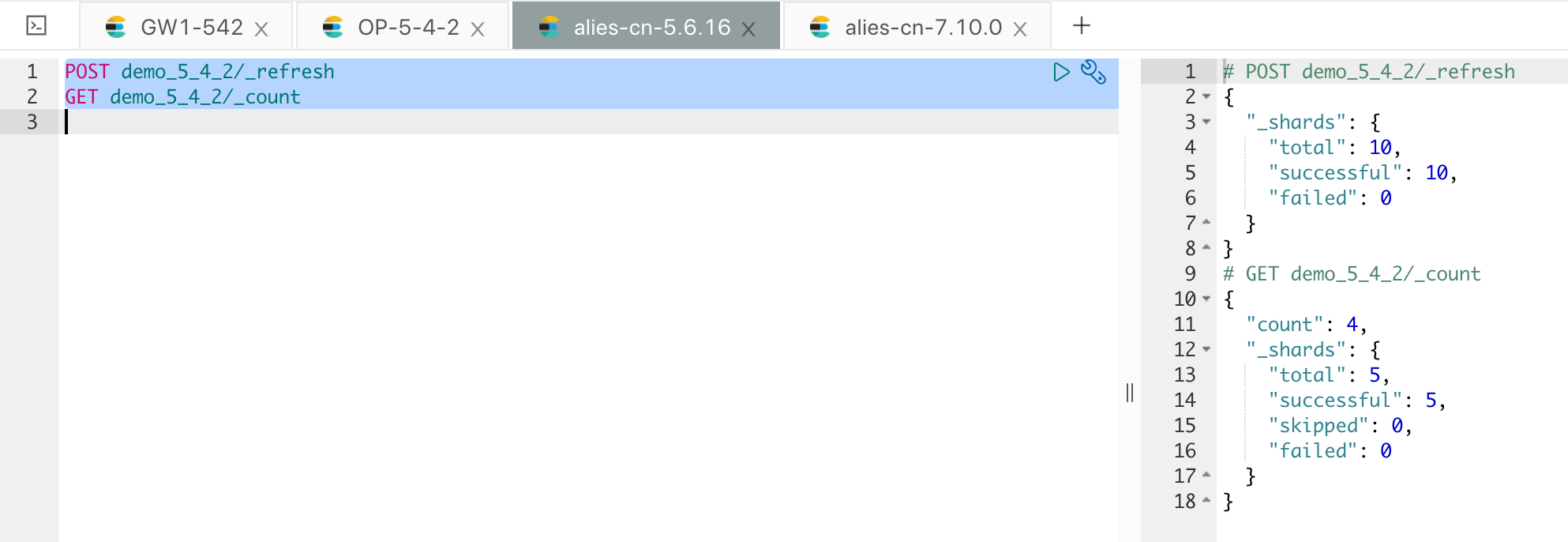
全量数据至此导入完成。
增量数据迁移
在全量导入的过程中,可能存在数据的增量修改,不过这部分请求都已经完整记录下来了,我们只需要开启网关的消费任务即可将挤压的请求应用到云端的 Elasticsearch 集群。

示例操作如下:

如果从 5.6 的集群来看的话,这部分的修改还没同步过来,如下:
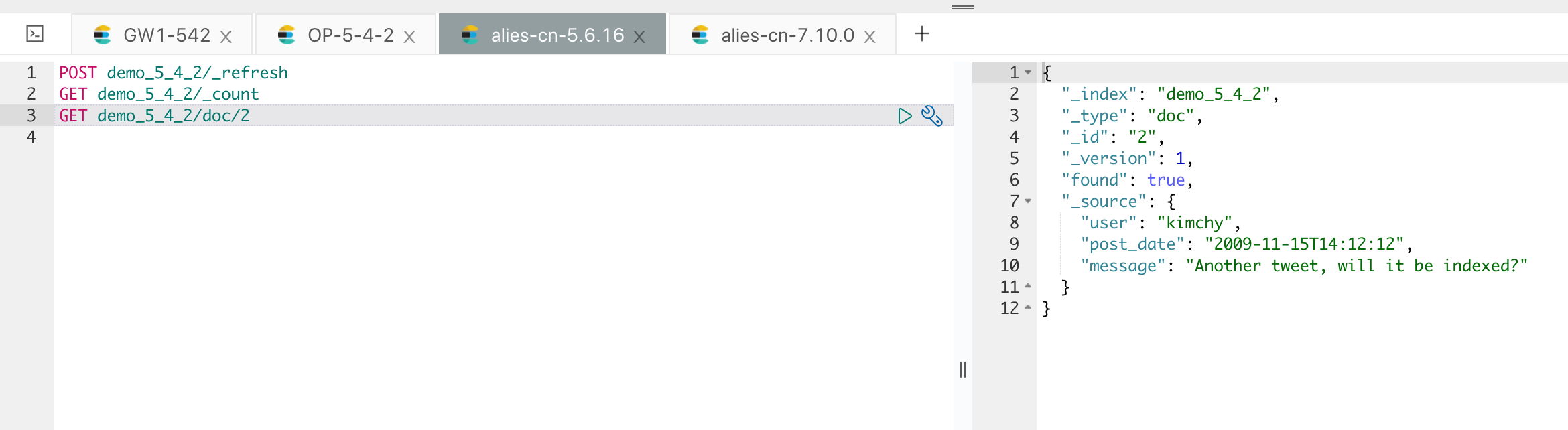
这部分增量的数据变更,在网关层面都进行了完整记录,我们只需要开启网关的增量消费任务,如下:

通过观察队列是否消费完成来判断增量数据是否做完,如下:
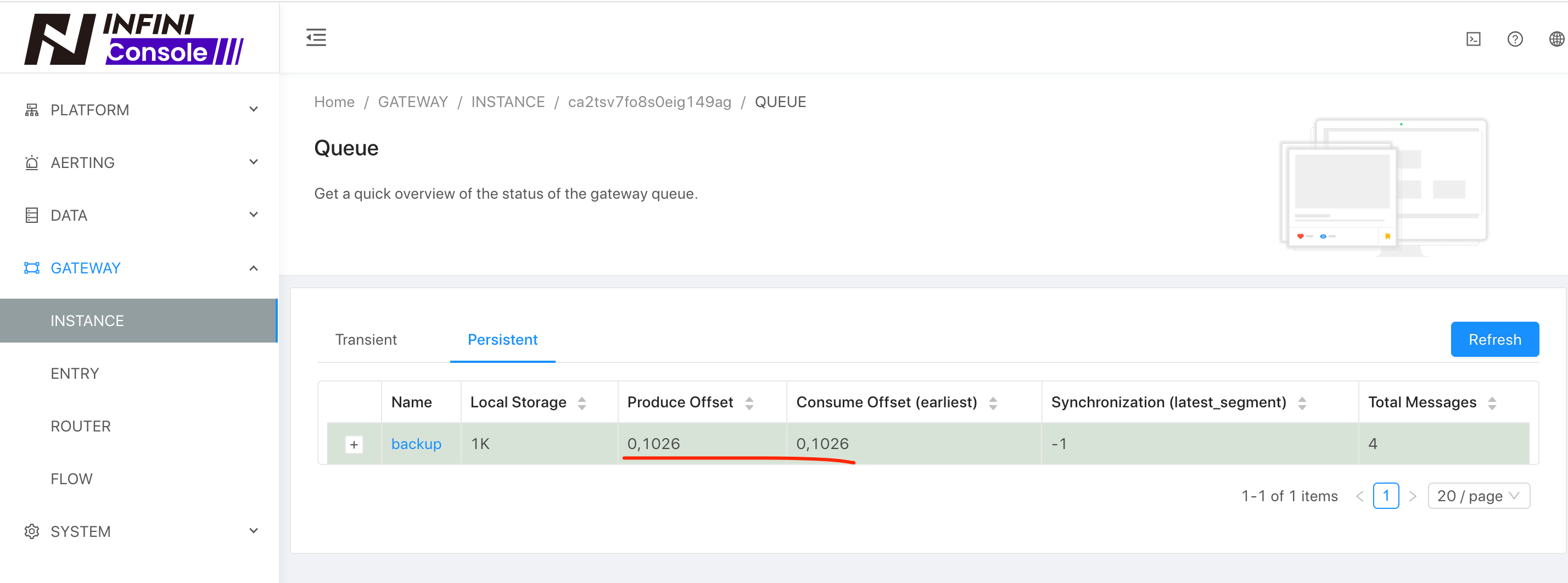
现在我们再看一下 5.6 集群的数据情况,如下:
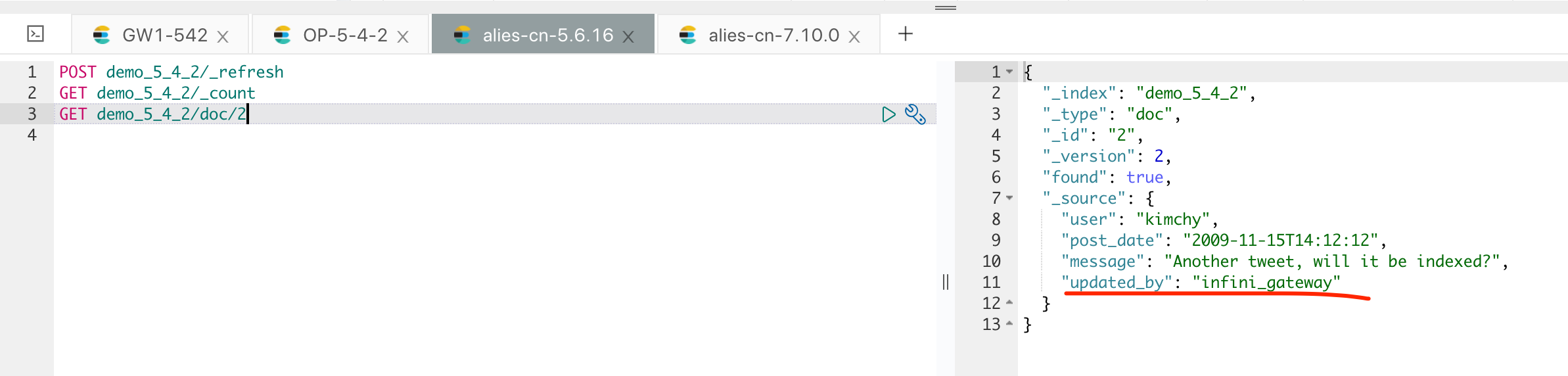
数据的增量更新就过来了。
执行数据比对
由于集群内部的数据可能比较多,我们需要进行一个完整的比对才能确保数据的完整性,可以通过网关自带的数据比对工具来进行,将样例自带的文件拷贝一份,如下:
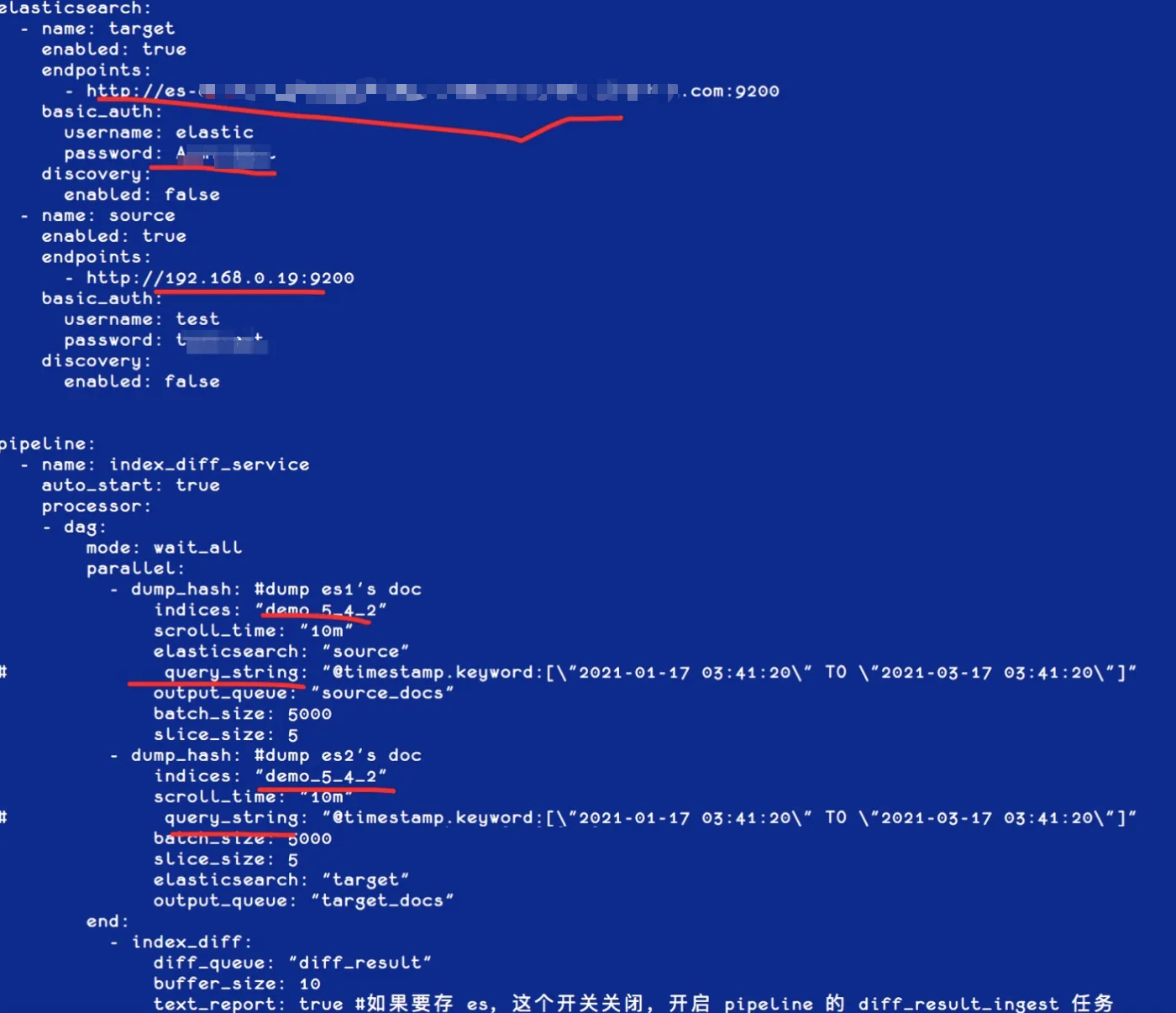
[root@iZbp1gxkifg8uetb33pvcpZ gateway]# cp sample-configs/index-docs-diff.yml 5.4DIFF5.6.yml
修改需要比对的集群和索引信息,可以加上过滤条件,如时间范围窗口来进行增量 Diff,如下图:
执行网关程序,并指定该配置文件,如下图:
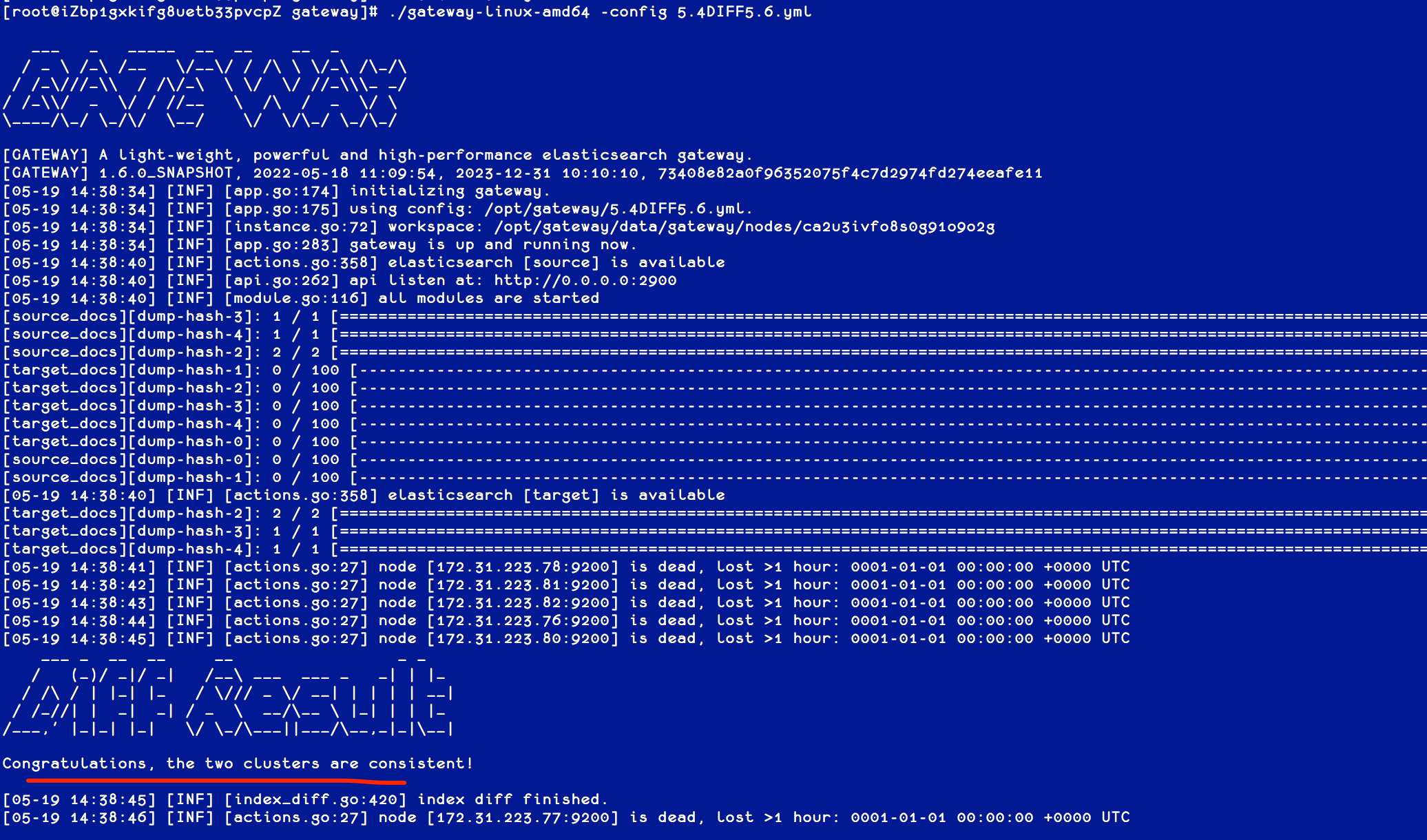
如图,两个集群完全一致。
切换集群
如果验证完之后,两个集群的数据已经完全一致了,可以将程序切换到新集群,或者将网关的配置里面的主备进行互换,同步写 5.6 集群。
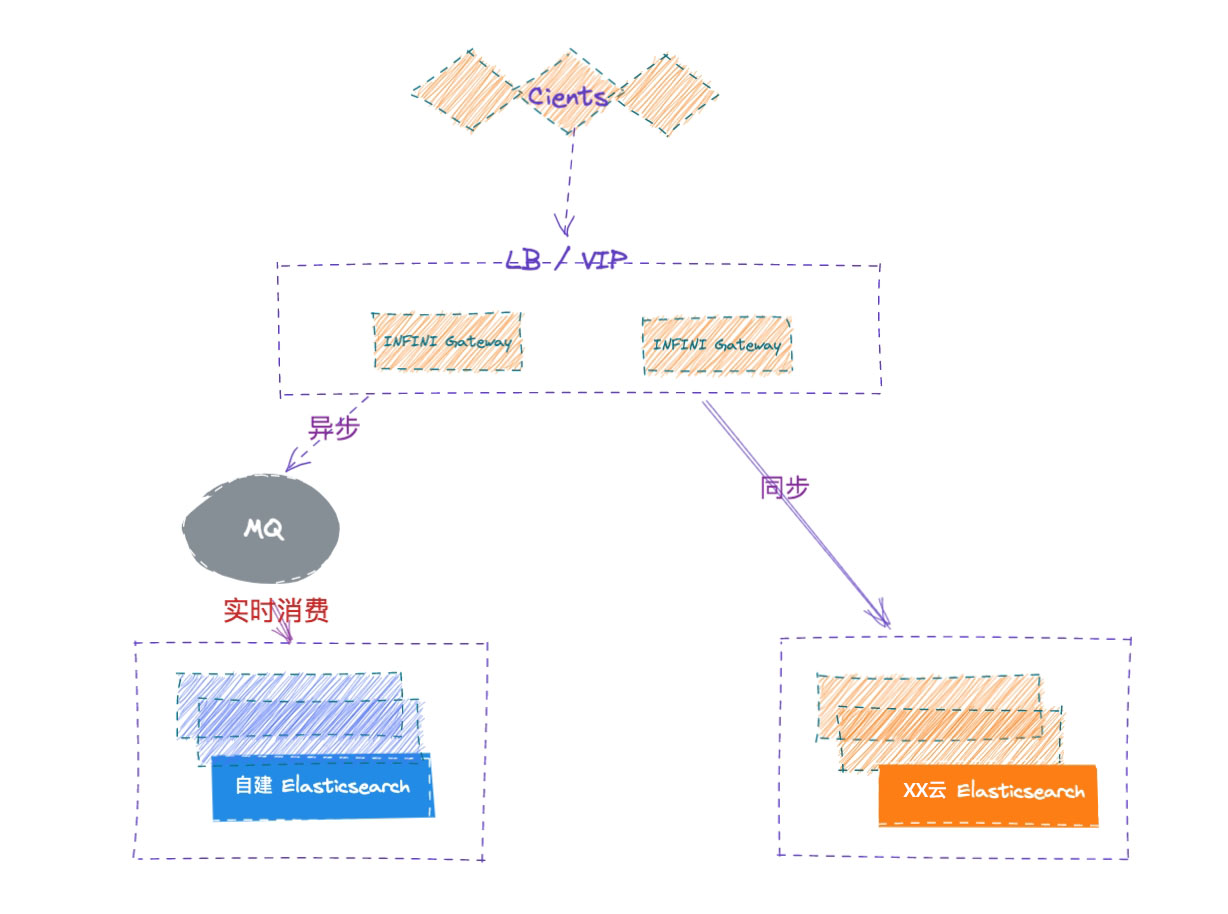
双集群在线运行一段时间,待业务完全验证之后,再安全下线旧集群,如遇到问题,也可以随时回切到老集群。
小结
通过使用极限网关,自建 ES 集群可以安全无缝的迁移到移动云 ES,在迁移的过程中,两套集群通过网关进行了解耦,两套集群的版本也可以不一样,在迁移的过程中还能实现版本的无缝升级。
如有任何问题,请随时联系我,期待与您交流!
关于 Gateway
极限网关 (INFINI Gateway) 是一个面向 Elasticsearch 的高性能应用网关,它包含丰富的特性,使用起来也非常简单。
极限网关工作的方式和普通的反向代理一样,我们一般是将网关部署在 Elasticsearch 集群前面, 将以往直接发送给 Elasticsearch 的请求都发送给网关,再由网关转发给请求到后端的 Elasticsearch 集群。
因为网关位于在用户端和后端 Elasticsearch 之间,所以网关在中间可以做非常多的事情, 比如可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。















 719
719











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









