









字符串
代码随想录刷题笔记
理论基础
什么是字符串
字符串是若干字符组成的有限序列,也可以理解为是一个字符数组,但是很多语言对字符串做了特殊的规定,接下来我来说一说C/C++中的字符串。
在C语言中,把一个字符串存入一个数组时,也把结束符 '\0’存入数组,并以此作为该字符串是否结束的标志。
例如这段代码:
char a[5] = "asd";
for (int i = 0; a[i] != '\0'; i++) {
}
在C++中,提供一个string类,string类会提供 size接口,可以用来判断string类字符串是否结束,就不用’\0’来判断是否结束。
例如这段代码:
string a = "asd";
for (int i = 0; i < a.size(); i++) {
}
那么vector< char > 和 string 又有什么区别呢?
其实在基本操作上没有区别,但是 string提供更多的字符串处理的相关接口,例如string 重载了+,而vector却没有。
所以想处理字符串,我们还是会定义一个string类型。
要不要使用库函数
344. 反转字符串
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。
不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。
这道题主要是为了解释,什么时候使用库函数。
如果题目关键的部分直接用库函数就可以解决,建议不要使用库函数。
毕竟面试官一定不是考察你对库函数的熟悉程度, 如果使用python和java 的同学更需要注意这一点,因为python、java提供的库函数十分丰富。
如果库函数仅仅是 解题过程中的一小部分,并且你已经很清楚这个库函数的内部实现原理的话,可以考虑使用库函数。
解题思路:
大家应该还记得,我们已经讲过了206.反转链表 (opens new window)。
在反转链表中,使用了双指针的方法。
那么反转字符串依然是使用双指针的方法,只不过对于字符串的反转,其实要比链表简单一些。
因为字符串也是一种数组,所以元素在内存中是连续分布,这就决定了反转链表和反转字符串方式上还是有所差异的。
对于字符串,我们定义两个指针(也可以说是索引下标),一个从字符串前面,一个从字符串后面,两个指针同时向中间移动,并交换元素。
参考代码:
void reverseString(vector<char>& s) {
for (int i = 0, j = s.size() - 1; i < s.size()/2; i++, j--) {
swap(s[i],s[j]);
}
}
也可以这样写:
class Solution {
public:
void reverseString(vector<char>& s) {
int n = s.size();
for(int i = 0; i < n / 2; i++){
swap(s[i], s[n - i - 1]);
}
}
};
循环里只要做交换s[i] 和s[j]操作就可以了,那么直接使用swap 这个库函数。
因为相信大家都知道交换函数如何实现,而且这个库函数仅仅是解题中的一部分, 所以这里使用库函数也是可以的。
swap可以有两种实现。
一种就是常见的交换数值:
int tmp = s[i];
s[i] = s[j];
s[j] = tmp;
一种就是通过位运算:
s[i] ^= s[j];
s[j] ^= s[i];
s[i] ^= s[j];
这道题目还是比较简单的,但是我正好可以通过这道题目说一说在刷题的时候,使用库函数的原则。
如果题目关键的部分直接用库函数就可以解决,建议不要使用库函数。
如果库函数仅仅是 解题过程中的一小部分,并且你已经很清楚这个库函数的内部实现原理的话,可以考虑使用库函数。
本着这样的原则,我没有使用reverse库函数,而使用swap库函数。
在字符串相关的题目中,库函数对大家的诱惑力是非常大的,因为会有各种反转,切割取词之类的操作,这也是为什么字符串的库函数这么丰富的原因。
541. 反转字符串 II
给定一个字符串 s 和一个整数 k,从字符串开头算起,每计数至 2k 个字符,就反转这 2k 字符中的前 k 个字符。
如果剩余字符少于 k 个,则将剩余字符全部反转。
如果剩余字符小于 2k 但大于或等于 k 个,则反转前 k 个字符,其余字符保持原样。
示例 1:
输入:s = "abcdefg", k = 2
输出:"bacdfeg"
示例 2:
输入:s = "abcd", k = 2
输出:"bacd"
解题思路:
简单模拟题,模拟规定的反转规则即可。
在遍历字符串时,i每次移动2*k个,即可找到每次要反转的区间的起点,一段一段的处理字符串,然后在循环中判断是否需要有反转的区间即可,判断区间是一个需要思考的点。
if(i + k <= s.size()) 可表示为一段区间的开头再加上k后没有超出整个数组的范围(注意有等于号),也就是剩余字符大于或等于k时,可进行反转。其余条件也就是剩余字符少于k时,将剩余字符全部反转即可。
注意reverse()用法:
标准C中是没有reverse()函数的,这是C++的一个新增函数
reverse函数用于反转在[first,last)范围内的顺序(包括first指向的元素,不包括last指向的元素)
1.翻转字符串
reverse(s.begin(),s.end()); //翻转整个字符串
reverse(s.begin()+i,s.begin()+k); //翻转下标i到k(不包含k)
2.翻转数组
reverse(a,a+n);//n为数组长度 翻转整个数组
reverse(a+i,a+k);//翻转指定范围 下标为i到k(不包括k)
3.翻转vector
reverse(vect.begin(),vect.end());//写法和数组一样
最后给出函数原型,该函数等价于通过调用iter_swap来交换元素位置
template <class BidirectionalIterator>
void reverse (BidirectionalIterator first, BidirectionalIterator last)
{
while ((first!=last)&&(first!=--last))
{
std::iter_swap (first,last);
++first;
}
}
参考代码:
class Solution {
public:
string reverseStr(string s, int k) {
for(int i = 0; i < s.size(); i+= (2 * k)){
//每隔2k个字符的前k个字符进行反转
//如果剩余字符小于2k但大于或等于k个,则反转前k个字符
if(i + k <= s.size()){
//注意此处reverse函数用法
reverse(s.begin() + i, s.begin() + i + k);
} else {
//剩余字符小于k个,则将剩余字符全部反转
reverse(s.begin() + i, s.end());
}
}
return s;
}
};
剑指 Offer 05. 替换空格
请实现一个函数,把字符串 s 中的每个空格替换成"%20"。
示例 1:
输入:s = "We are happy."
输出:"We%20are%20happy."
解题思路:
首先分析题目知道要想把里面的空格替换不能直接替换因为字符串数组移动很麻烦,所以先统计整个字符串数组中的空格数目然后把字符串大小扩大为替换后的大小,然后用双指针(i指向新长度的末尾,j指向旧长度的末尾)方法从后向前替换空格移元素。
注意:其实很多数组填充类的问题,都可以先预先给数组扩容带填充后的大小,然后在从后向前进行操作。 这么做有两个好处:
1.不用申请新数组。
2.从后向前填充元素,避免了从前先后填充元素要来的 每次添加元素都要将添加元素之后的所有元素向后移动O(n^2)。
参考代码:
class Solution {
public:
string replaceSpace(string s) {
int count = 0; //统计空格个数
int sOldsize = s.size(); //存放旧字符串个数,用于后续j的指向
for(int i = 0; i < s.size(); i++){
if(s[i] == ' '){
count++;
}
}
// 扩充字符串s的大小,也就是每个空格替换成"%20"之后的大小
s.resize(s.size() + 2 * count);
int sNewsize = s.size(); //存放新字符串个数,用于后续i的指向
// 从后先前将空格替换为"%20"
for(int j = sOldsize - 1, i = sNewsize - 1; j < i; j--, i--){ //注意此处,终止条件为j < i,此时,i追上j,说明前面没有空格了,就可以结束
if(s[j] == ' '){
s[i] = '0';
s[i - 1] = '2';
s[i - 2] = '%';
i -= 2;
} else {
s[i] = s[j];
}
}
return s;
}
};
resize()介绍:
resize函数是C++中序列式容器的一个共性函数,vv.resize(int n,element)表示调整容器vv的大小为n,扩容后的每个元素的值为element,默认为0.
- 时间复杂度:O(n)
- 空间复杂度:O(1)
拓展
字符串和数组有什么差别?
字符串是若干字符组成的有限序列,也可以理解为是一个字符数组,但是很多语言对字符串做了特殊的规定,接下来我来说一说C/C++中的字符串。
在C语言中,把一个字符串存入一个数组时,也把结束符 '\0’存入数组,并以此作为该字符串是否结束的标志。
例如这段代码:
char a[5] = "asd";
for (int i = 0; a[i] != '\0'; i++) {
}
在C++中,提供一个string类,string类会提供 size接口,可以用来判断string类字符串是否结束,就不用’\0’来判断是否结束。
例如这段代码:
string a = "asd";
for (int i = 0; i < a.size(); i++) {
}
那么vector< char > 和 string 又有什么区别呢?
其实在基本操作上没有区别,但是 string提供更多的字符串处理的相关接口,例如string 重载了+,而vector却没有。
所以想处理字符串,我们还是会定义一个string类型。
双指针题目汇总
- 27.移除元素(opens new window)
- 15.三数之和(opens new window)
- 18.四数之和(opens new window)
- 206.翻转链表(opens new window)
- 142.环形链表II(opens new window)
- 344.反转字符串(opens new window)
反转字符
*151. 颠倒字符串中的单词
给你一个字符串 s ,颠倒字符串中 单词 的顺序。
单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。
返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。
注意:输入字符串 s中可能会存在前导空格、尾随空格或者单词间的多个空格。返回的结果字符串中,单词间应当仅用单个空格分隔,且不包含任何额外的空格。
示例 1:
输入:s = "the sky is blue"
输出:"blue is sky the"
示例 2:
输入:s = " hello world "
输出:"world hello"
解释:颠倒后的字符串中不能存在前导空格和尾随空格。
示例 3:
输入:s = "a good example"
输出:"example good a"
解释:如果两个单词间有多余的空格,颠倒后的字符串需要将单词间的空格减少到仅有一个。
解题思路
在344.反转字符串中,我们是将一串字符串进行反转,而本题,是将一个一个单词进行反转,收到344题启发。可以将原字符串首先进行一个整体的反转,反转之后,再对每一个单词(使用空格隔出的子字符串)里再进行反转(直接使用reverse函数即可)。
所以解题思路如下:
" the sky is blue "
- 移除多余空格 “the sky is blue”
- 将整个字符串反转 “eulb si yks eht”
- 将每个单词反转 “blue is sky the”
上述答题思路,一个难点就是如何删除多余的空格?如果要求不要使用辅助空间,空间复杂度要求为O(1)。
有一种思路:遍历整个数组,如果发现有多个空格,则使用erase函数,删除空格,但是erase函数时间复杂度为O(n),所以整个移除操作时间复杂度为O(n^2),效率不高。
那么可以想到,在数组章节,双指针解法中,有一道题目27.移除元素,使用快慢指针移除元素,那么使用**双指针法(快慢指针)**来去移除空格,最后resize(重新设置)一下字符串的大小,就可以做到O(n)的时间复杂度。
具体可以定义快指针:获取符合题目要求的字母,慢指针:指向(快指针遍历时)符合条件的字母更新在哪个地方。与27.移除元素思路相同。
代码细节:
(1)移除多余空格(双指针解法)—removeExtraSpaces函数实现
定义快慢指针,初始化指向字符串的开始位置。
for循环中fast遍历整个字符串,如果字符不为空(if(s[fast] != ’ ')),将该字符赋值给慢指针指向的位置。
但是需要注意!本题要求,每个单词之间要有一个空格,但是首个单词之前不需要空格,所以只要不是第一个单词(slow != ’ '),就需要在每个单词的前面留一个空格,并且slow向后移动一位(slow++),即(if(slow != 0) s[slow++] = ’ '),
留了空格后,就需要做该单词(遇到空格就说明一个单词结束)中各个字母的赋值了即,(while(fast < s.size() && s[fast] != ’ ') s[slow++] = s[fast++])
最终,将修改字符串大小,slow最终指向新字符串末尾,所以(s.resize(slow))即可。
(2) 整个字符串反转和每个单词(字符串子区间)反转—主函数实现
思路与344.反转字符串思路相同(使用reverse函数实现即可)
代码实现:
class Solution {
public:
void removeExtraSpaces(string& s){//使用快慢指针,去除所有空格并在除第一个单词之外的其他单词前添加一个空格
int slow = 0;//慢指针用于指向需要更新的位置
for(int fast = 0; fast < s.size(); ++fast){//快指针遍历整个数组,寻找符合条件的字符
if(s[fast] !=' '){//fast指向的不是空格(也就是一个单词的开始位置),那么就进行快慢指针赋值操作,也就一位置删除所有空格
if(slow != 0) //当slow不为0也就是不是第一个单词时,需要手动在单词前添加一个空格
s[slow++] = ' ';
//单词赋值操作
while(fast < s.size() && s[fast] != ' '){//在对应位置补上单词,遇到空格则说明这一个单词结束,进行下一次循环
s[slow++] = s[fast++];
}
}
}
s.resize(slow); //slow大小就是删除空格后新字符串的大小
}
string reverseWords(string s) {
//第一步:去除多余空格,保证单词之间只有一个空格
removeExtraSpaces(s);
//第二步:反转整个字符串
reverse(s.begin(), s.end());
//第三步:反转每个单词(子字符串)
int start = 0;//记录一个单词的开始位置
for(int i = 0; i <= s.size(); i++){
if(i == s.size() || s[i] == ' '){//到达尾部或者遇到空格,则说明一个单词结束了,需要进行反转
reverse(s.begin() + start, s.begin() + i);
start = i + 1; //更新下一个单词的开始下标
}
}
return s;
}
};
剑指 Offer 58 - II. 左旋转字符串
字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。比如,输入字符串"abcdefg"和数字2,该函数将返回左旋转两位得到的结果"cdefgab"。
示例 1:
输入: s = "abcdefg", k = 2
输出: "cdefgab"
示例 2:
输入: s = "lrloseumgh", k = 6
输出: "umghlrlose"
解题思路:
本题如果可以申请额外空间,就比较简单,现将需要的字符串放入新字符串,然后进行对应的移动,最后将新字符串放到最后即可。
但如果不能申请额外空间,也就是只能在本串上操作,则需要思考。
上一道题,使用了整体反转+局部反转可以实现反转字符串中单次顺序的目的。
本题也可以使用类似思路,可以通过局部反转+整体反转,达到左旋目的。
具体步骤为:(以示例1为例: s = “abcdefg”, k = 2)
- 反转区间为前n的子串(bacdefg)
- 反转区间为n到末尾的子串(bagfedc)
- 反转整个字符串(cdefgab)
这样就达到了在本串中操作的目的
参考代码:
class Solution {
public:
string reverseLeftWords(string s, int n) {
//局部反转
reverse(s.begin(), s.begin() + n);
reverse(s.begin() + n, s.end());
//整体反转
reverse(s.begin(), s.end());
return s;
}
};
KMP系列
28. 实现 strStr()
实现 strStr() 函数。
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串出现的第一个位置(下标从 0 开始)。如果不存在,则返回 -1 。
说明:
当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。
对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与 C 语言的 strstr() 以及 Java 的 indexOf() 定义相符。
示例 1:
输入:haystack = "hello", needle = "ll"
输出:2
示例 2:
输入:haystack = "aaaaa", needle = "bba"
输出:-1
解题思路:
这道题是KMP经典题目
KMP讲解
KMP主要应用:解决字符串匹配问题。
KMP**主要思想:**当出现字符串不匹配时,可以记录一部分之前已经匹配的文本内容,利用这些信息避免从头再去做匹配。
所以,如何记录已经匹配的文本内容,是KMP的重点。也是前缀表(也叫作next数组)肩负的重任。
前缀表作用:
前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始与文本串不匹配的地方重新匹配。
例如:要在文本串:aabaabaafa 中查找是否出现过一个模式串:aabaaf。
文本串中第六个字符b 和 模式串的第六个字符f,不匹配了。
如果暴力匹配,会发现不匹配,此时就要从头匹配了。
但如果使用前缀表,就不会从头匹配,而是从上次已经匹配的内容开始匹配(也就是因为f前字符串是aabaa,最长相等前后缀为2:aa == aa,所以也就是aa不需要匹配了,模式串直接从下标为2的字符与文本串中不匹配的位置也就是b(aabaa后的b)继续匹配),找到了模式串中第三个字符b继续开始匹配。
什么是前缀表:
记录下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。
在某个字符失配时,前缀表会告诉你下一步匹配中,模式串应该跳到哪个位置继续匹配。
next数组就是一个前缀表(prefix table)。
什么是最长相等前后缀:
- 什么是前缀后缀?
前缀:包含首字母,不包含尾字母的所有子串
后缀:包含尾字母,不包含首字母的所有子串
所以可以求出各子字符串的对应最长相等前后缀。
如何计算前缀表?
eg.
字符串a的最长相等前后缀为0
字符串aa的最长相等前后缀为1
字符串aab的最长相等前后缀为0
字符串aaba的最长相等前后缀为1
字符串aabaa的最长相等前后缀为2
字符串aabaaf的最长相等前后缀为0
这样将子字符串长度从小到大对应最长相等前后缀组合为一个序列**[0,1,0,1,2,0],对应模式串的前缀表**。
可以看出模式串与前缀表对应位置的数字表示的就是:下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。
如何使用前缀表进行匹配?
当找到的不匹配的位置, 那么此时我们要看它的前一个字符的前缀表的数值是多少。
为什么找前一个字符的前缀表的数值呢?
前一个字符的前缀表的数值n就是 后面有一个长度为n的后缀在前面也有一个与其相等的前缀。后缀的后一位不匹配了,那么就找与其(后缀)相等的前缀继续开始匹配。那么模式串就从前缀的后面(下标为前一个字符的前缀表的数值n的位置)开始与文本串不匹配位继续比对。
前缀表与next数组
遇到冲突的地方之后,next数组指出需要回退到哪个位置继续匹配。
具体实现,next数组即可以就是前缀表
时间复杂度
其中n为文本串长度,m为模式串长度,因为在匹配的过程中,根据前缀表不断调整匹配的位置,可以看出匹配的过程是O(n),之前还要单独生成next数组,时间复杂度是O(m)。所以整个KMP算法的时间复杂度是O(n+m)的。
暴力的解法显而易见是O(n × m),所以KMP在字符串匹配中极大的提高的搜索的效率。
为了和力扣题目28.实现strStr保持一致,方便大家理解,以下文章统称haystack为文本串, needle为模式串。
都知道使用KMP算法,一定要构造next数组。
代码细节
(1)构造next数组
定义一个函数getNext来构建next数组,函数参数为指向next数组的指针,和一个字符串(模式串)。 (void getNext(int next, const string& s)*)
构造next数组其实就是计算模式串s,前缀表的过程。 主要有如下三步:
- 初始化
- 处理前后缀不相同的情况
- 处理前后缀相同的情况
- 更新next数组的值
详情步骤:
-
初始化
定义两个指针i和j,j指向前缀末尾位置,i指向后缀末尾位置。其实j不仅指向前缀末尾,它还代表这i(包括i)之前的子串的最长相等前后缀的长度。
由于子字符串长度为1的时候没有前后缀,所以初始化从子字符串长度为2开始,那么初始化如下:
j初始化为0(j = 0),i的初始化(i = 1)在循环遍历中进行
然后还要对next数组进行初始化赋值
next[0] = 0;
因为j初始化为0,所以i就从1开始,进行s[i] 与s[j ]的比较。
所以遍历模式串s的循环下标i要从1开始(for(int i = 1; i < s.size(); i++))
-
处理前后缀不相同的情况(i和j指向的位置的值不相等),执行回退
当遇到s[i] 与 s[j] 不相同,也就是前后缀末尾不匹配的情况,那么j就要向前回退。如何回退呢?
next[j]就是记录着j(包括j)之前的子串的相同前后缀的长度。
那么s[i] 与 s[j] 不相同,就要找j前一个元素在next数组中的值也就是next[j - 1]
为什么这样回退呢?
之前我们比较模式串和文本串时遇到冲突是不是回退到next数组前一位代表的下标位置,现在我们也是匹配(求next数组的问题也是一个模式匹配的子问题)只不过匹配的时前缀(相当于模式串)和后缀(相当于文本串)
也就是(注意是while连续回退的过程,不能写成if):
while(j >= 0 && s[i] != s[j]){ //前后缀不相同,且要保证前缀j最终不能越界(不能比0的位置更前了,数组下标不能为-1) j = next[j - 1]; //向前回退 } -
处理前后缀相同的情况,并更新next数组的值
当i和j指向的字符相等(if(s[i] == s[j]))时,那么就同时向后移动i(for循环中自然向后移) 和j(j++)(为什么j要向后移一位?因为j不仅代表前缀的末尾,还代表 i包括i之前的子串的最长相等前后缀的长度,因为此时比较出前后缀相等,所以最长相等前后缀的长度需要加一)说明找到了相同的前后缀,之后还要更新next数组的值,将j(i包括i之前的子串的最长相等前后缀的长度)赋给next[i](next[i] = j), 因为next[i]要记录i包括i之前子串相同前后缀的长度。
if(s[i] == s[j]) { //找到相同的前后缀 j++; } next[i] = j;最后整体构建next数组的函数代码如下:
void getNext(int* next, const string& s) { int j = 0; next[0] = 0; for(int i = 1; i < s.size(); i++) { while (j > 0 && s[i] != s[j]) { // j要保证大于0,因为下面有取j-1作为数组下标的操作 j = next[j - 1]; // 注意这里,是要找前一位的对应的回退位置了 } if (s[i] == s[j]) { j++; } next[i] = j; } }得到next数组之后,就可以用它来做匹配了。
(2)使用next数组做匹配
在文本串s里 找是否出现过模式串t。
定义两个下标:j 指向模式串t起始位置,i指向文本串s起始位置。
j初始值为0,i也从0开始,遍历文本串(for (int i = 0; i < s.size(); i++) ),在遍历中进行 s[i] 与 t[j ]的比较。
如果 s[i] 与 t[j] 不相同,j就要从next数组里寻找下一个匹配的位置。
while(j >= 0 && s[i] != t[j]) {
j = next[j - 1];
}
如果 s[i] 与 t[j] 相同,那么i 和 j 同时向后移动, 代码如下:
if (s[i] == t[j]) {
j++; // i的增加在for循环里
}
如何判断在文本串s里出现了模式串t呢?
如果j指向了模式串t的末尾,那么就说明模式串t完全匹配文本串s里的某个子串了。
本题要在文本串字符串中找出模式串出现的第一个位置 (从0开始),所以返回当前在文本串匹配模式串的位置i 减去 模式串的长度,就是文本串字符串中出现模式串的第一个位置。
if (j == t.size() ) {
return (i - t.size() + 1);
}
那么使用next数组,用模式串匹配文本串的整体代码如下:
int j = 0;
for (int i = 0; i < haystack.size(); i++) {
while(j > 0 && haystack[i] != needle[j]) {
j = next[j - 1];
}
if (haystack[i] == needle[j]) {
j++;
}
if (j == needle.size() ) {
return (i - needle.size() + 1);
}
}
整合创建next数组和使用next数组进行匹配,就解决本题
参考代码:
class Solution {
public:
//构造next数组
void getNext(int* next, const string s){
//j指向前缀的末尾
int j = 0;
//next数组为前缀表
next[0] = 0;
for(int i = 1; i < s.size(); i++){ //j初始化为1,指向后缀末尾
while(j > 0 && s[i] != s[j]){ //前后缀不相同,注意while连续回退
j = next[j - 1]; //向前回退
}
if(s[i] == s[j]){ //找到相同前后缀
j++; //前缀向后移一位,也就代表i包括i之前的最长相同前后缀加一
}
next[i] = j; // 将j(前缀的长度)赋给next[i]
}
}
int strStr(string haystack, string needle) {
if(needle.size() == 0){
return 0;
}
int next[needle.size()];
getNext(next, needle); //构建next数组
int j = 0; //j指向模式串
for(int i = 0; i < haystack.size(); i++){ //i指向文本串
while(j > 0 && haystack[i] != needle[j]){// 不匹配
j = next[j - 1];// j 寻找之前匹配的位置
}
if(haystack[i] == needle[j]){// 匹配,j和i同时向后移动
j++;// i的增加在for循环里
}
if(j == needle.size()){ // 文本串s里出现了模式串t,也就是j指向了模式串末尾
return(i - needle.size() + 1);//返回模式串首字符在文本串中的位置
}
}
return -1;
}
};
459. 重复的子字符串
给定一个非空的字符串 s ,检查是否可以通过由它的一个子串重复多次构成。
示例 1:
输入: s = "abab"
输出: true
解释: 可由子串 "ab" 重复两次构成。
示例 2:
输入: s = "aba"
输出: false
示例 3:
输入: s = "abcabcabcabc"
输出: true
解释: 可由子串 "abc" 重复四次构成。 (或子串 "abcabc" 重复两次构成。)
解题思路:
题解1:暴力解法
一个for循环获取 子串的终止位置, 然后判断子串是否能重复构成字符串,又嵌套一个for循环,所以是O(n^2)的时间复杂度。
一个for循环就可以获取子串吗? 至少得一个for获取子串起始位置,一个for获取子串结束位置吧。
其实我们只需要判断,以第一个字母为开始的子串就可以,因为本题判断的是重复子串,默认子串一定是从第一个元素开始的,所以一个for循环获取子串的终止位置就行了。 而且遍历的时候 都不用遍历结束,只需要遍历到中间位置,因为子串结束位置大于中间位置的话,一定不能重复组成字符串。
题解2:移动匹配
找出规律:ababab abcabc …
任何一个重复字串,他的前部分和后部分(不一定是半部分,eg.ababab就是abab = abab)一定可以找到相等的子串
那么有一个巧思:原字符串为s(eg.ababab)将两个s拼接在一起:s+s(ababab+ababab),如果s+s中出现了s(原字符串的后面和新字符串的前面又拼接成一个s)那么s就是一个重复子串,(反例:aba—>abaaba中无子串s)在s+s中搜索s时,一定要将首元素和尾元素去掉(因为如果不去掉,那么在s中就能搜索到s没意义)
注意,当在s+s中寻找s时,可以使用ss.find(s)库函数,每种语言对应实现方式不同,时间复杂度也不同,如果底层使用KMP算法实现,那么时间复杂度就是O(m + n)。
参考代码:
class Solution {
public:
bool repeatedSubstringPattern(string s) {
//将s和s拼接在一起组成ss
string ss = s + s;
//去掉ss的头元素和尾元素
ss.erase(ss.begin());
ss.erase(ss.end() - 1);
//在ss中找s
if(ss.find(s) != std::string::npos){ //注意find函数返回的是迭代器
return true;
} else {
return false;
}
}
};
题解3:KMP算法
在KMP算法中,有前缀和后缀,那么最长相等前后缀与求子串有什么联系呢?
如果一个字符串是由重复字串组成的,那么它的最小重复单位就是它的最长相等前后缀不包含的那一部分(子串)
eg. abababab 最长相等前后缀:ababab,所以前缀或后缀不包含的那部分就是ab

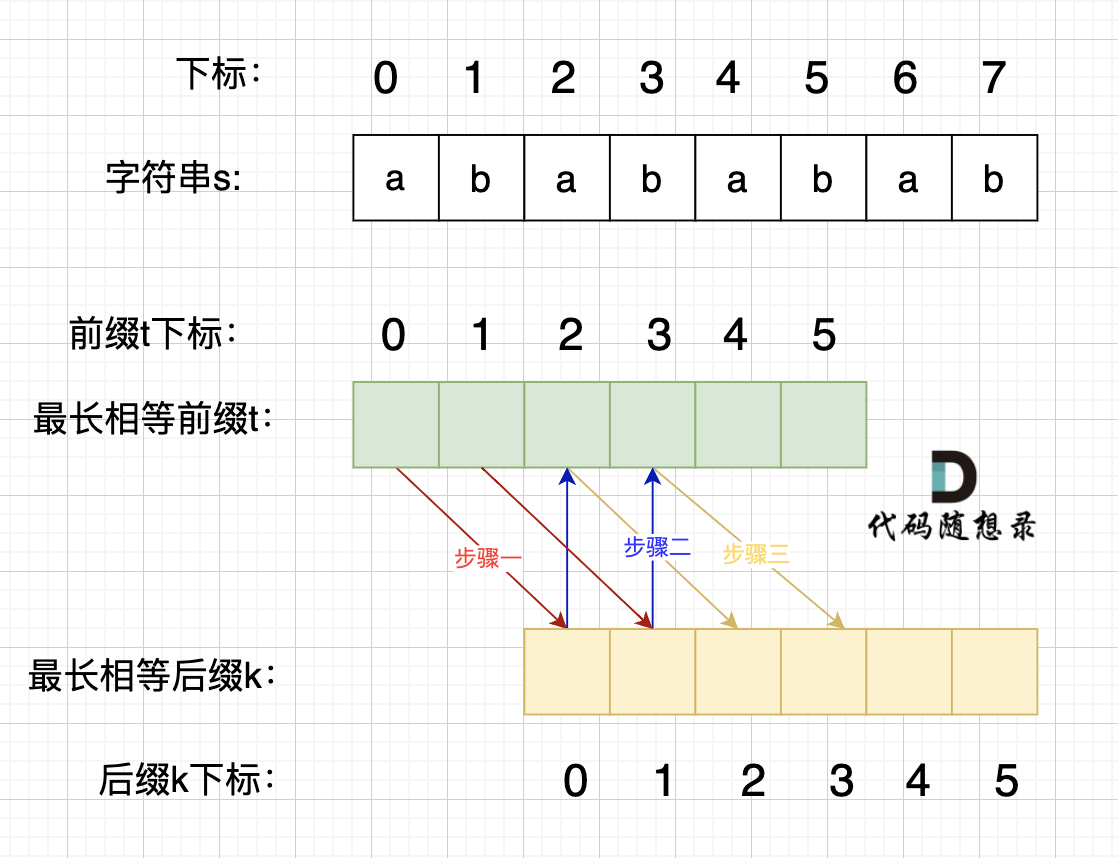
为什么呀?由于最长相等前后缀中前缀不包括尾元素,后缀不包括首元素,所以当找到最长相等前后缀时,也就说明在字符串中有两个不同位置的子串相等。
eg 最长前缀:t子字符串;最长后缀:f子字符串
t01 = f01 也就是对应到s字符串中 s01 = s23
而又因为f01和t23又是同一个位置,所以t01 = f01 = t23
而又因为t23 = f23 也就是对应到s字符串中s23 = s45
以此类推:s01 = s23 = s45 = s67
计算的纽带就是前缀和后缀相等这个条件,再加上前后缀在s字符串中是错位的,这样一步一步推导,就可以找到重复子字符串。
所以:
如果一个字符串是由重复字串组成的,那么它的最小重复单位就是它的最长相等前后缀不包含的那一部分(子串)
根据这个思路,如果字符串长度 能够整除 最小重复单位也就是最长相等前后缀不包含的那一部分(子串) (字符串长度 减去 最长相等前后缀的长度),那么它是由重复的子串组成的
例如:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i5QOSeTP-1680311472746)(https://code-thinking.cdn.bcebos.com/pics/459.重复的子字符串_1.png)]
next[len - 1] = 7,next[len - 1] + 1 = 8,8就是此时字符串asdfasdfasdf的最长相同前后缀的长度。
(len - (next[len - 1] + 1)) 也就是: 12(字符串的长度) - 8(最长公共前后缀的长度) = 4, 4正好可以被 12(字符串的长度) 整除,所以说明有重复的子字符串(asdf)。
参考代码:
class Solution {
public:
void getNext(int* next, const string& s){
int j = 0;
next[0] = 0;
for(int i = 1; i < s.size(); i++){
while(j > 0 && s[i] != s[j]){
j = next[j - 1];
}
if(s[i] == s[j]){
j++;
}
next[i] = j;
}
}
bool repeatedSubstringPattern(string s) {
if(s.size() == 0){
return false;
}
int next[s.size()];
getNext(next, s);
int len = s.size();
if(next[len - 1] != 0 && len % (len - next[len - 1]) == 0){
return true;
}
return false;
}
};
相信大家已经对双指针法很熟悉了,但是双指针法并不隶属于某一种数据结构,我们在讲解数组,链表,字符串都用到了双指针法,所有有必要针对双指针法做一个总结。
asdfasdf的最长相同前后缀的长度。
(len - (next[len - 1] + 1)) 也就是: 12(字符串的长度) - 8(最长公共前后缀的长度) = 4, 4正好可以被 12(字符串的长度) 整除,所以说明有重复的子字符串(asdf)。
参考代码:
class Solution {
public:
void getNext(int* next, const string& s){
int j = 0;
next[0] = 0;
for(int i = 1; i < s.size(); i++){
while(j > 0 && s[i] != s[j]){
j = next[j - 1];
}
if(s[i] == s[j]){
j++;
}
next[i] = j;
}
}
bool repeatedSubstringPattern(string s) {
if(s.size() == 0){
return false;
}
int next[s.size()];
getNext(next, s);
int len = s.size();
if(next[len - 1] != 0 && len % (len - next[len - 1]) == 0){
return true;
}
return false;
}
};
相信大家已经对双指针法很熟悉了,但是双指针法并不隶属于某一种数据结构,我们在讲解数组,链表,字符串都用到了双指针法,所有有必要针对双指针法做一个总结。















 1232
1232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









