







文章目录
分区表
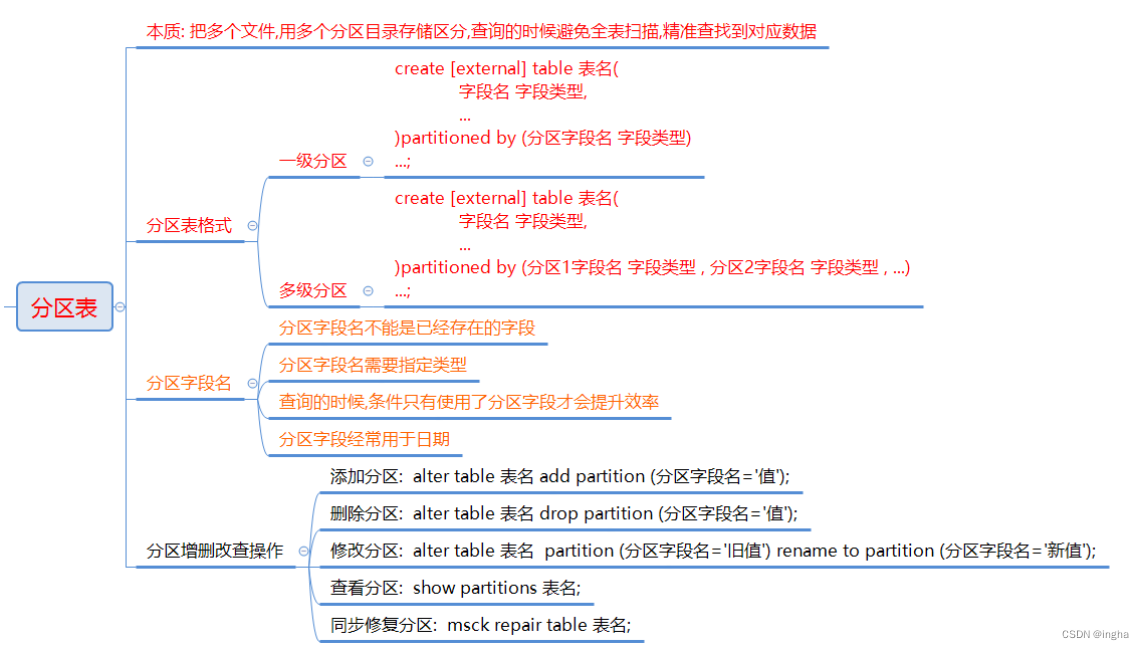
当Hive表对应HDFS中数据量大、文件多时,为了避免查询时全表扫描数据,Hive支持根据用户指定的字段进行分区,分区的字段可以是日期、地域、种类等具有标识意义的字段。比如把一整年的数据根据月份划分12个月(12个分区),后续就可以查询指定月份分区的数据,尽可能避免了全表扫描查询。
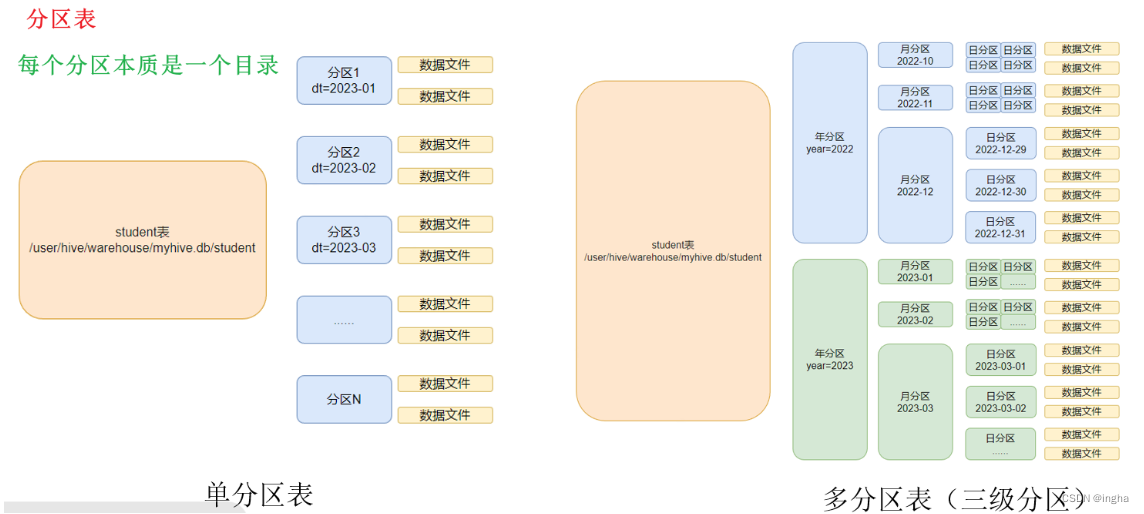
分区表特点/优点:
分区的概念提供了一种将Hive表数据分离为多个目录的方法。 不同分区对应着不同的文件夹,同一分区的数据存储在同一个文件夹下。 只需要根据分区值找到对应的文件夹,扫描本分区下的文件即可,避免全表扫描。
使用重点:
分区表的使用重点在于:
一、建表时根据业务场景设置合适的分区字段。比如日期、地域、类别等;
二、查询的时候尽量先使用where进行分区过滤,查询指定分区的数据,避免全表扫描。( 在查询数据的时不使用分区字段去筛选数据,效率不变)
-- 避免全表扫描,提升查询效率
select * from one_part_order where year='2023'; -- 提升效率
-- 注意: 如果查询的时候条件不是分区字段,效率不会改变
select * from one_part_order where price=20; -- 不会
分区表的注意事项:
- 分区表不是建表的必要语法规则,是一种优化手段表;
- 分区字段不能是表中已有的字段,不能重复(因为分区字段会作为一个字段拼接到表最后 );
- 分区字段是虚拟字段,其数据并不存储在底层的文件中;
- 分区字段值的确定来自于手动指定(静态分区)或者根据查询结果位置自动推断(动态分区)
- Hive支持多重分区,也就是说在分区的基础上继续分区,划分更加细粒度。
建表
一级分区
创建分区表: create [external] table [if not exists] 表名(字段名 字段类型 , 字段名 字段类型 , ... )partitioned by (分区字段名 分区字段类型)... ;
自动生成分区目录并插入数据: load data [local] inpath '文件路径' into table 分区表名 partition (分区字段名='值');
注意: 如果加local后面文件路径应该是linux本地路径,如果没有加那么就是hdfs文件路径
多级分区
多重分区下,分区之间是一种递进关系,可以理解为在前一个分区的基础上继续分区。从HDFS的角度来看就是文件夹下继续划分子文件夹。
创建分区表: create [external] table 表名(
字段名 字段类型 ,
字段名 字段类型 , ...
)partitioned by (一级分区字段名 分区字段类型, 二级分区字段名 分区字段类型 , ...) ;
自动生成分区目录并插入数据: load data [local] inpath '文件路径' into table 分区表名 partition (一级分区字段名='值',二级分区字段名='值' , ...);
注意: 如果加local后面文件路径应该是linux本地路径,如果没有加那么就是hdfs文件路径
示例:
-- 创建表
create table multi_part_order(
oid string,
name string,
price float,
num int
)partitioned by (year string,month string,day string)
row format delimited
fields terminated by ' ';
-- 加载数据
-- 思考数据文件在哪里?如果想从hdfs加载,怎么操作?上传到hdfs指定位置
load data inpath '/source/order202251.txt' into table multi_part_order partition (year=2022,month=05,day=01);
load data inpath '/source/order202351.txt' into table multi_part_order partition (year=2023,month=05,day=01);
load data inpath '/source/order202352.txt' into table multi_part_order partition (year=2023,month=05,day=02);
load data inpath '/source/order2023415.txt' into table multi_part_order partition (year=2023,month=04,day=15);
-- 验证数据
select * from multi_part_order;
-- 分区表的好处:避免全表扫描,提升查询效率
-- 需求: 统计2023年商品总销售额
select sum(price*num) from multi_part_order where year='2023'; -- 提升效率
-- 需求: 统计2023年5月份商品总销售额
select sum(price*num) from multi_part_order where year='2023'and month='5'; -- 进一步提升效率
-- 需求: 统计2023年5月1日的商品总销售额
select sum(price*num) from multi_part_order where year='2023'and month='5' and day='1';
分区增删改查操作
添加分区(add): alter table 分区表名 add partition (分区字段名='值' , ...);
删除分区(drop): alter table 分区表名 drop partition (分区字段名='值' , ...);
修改分区名(rename): alter table 分区表名 partition (分区字段名='旧值' , ...) rename to partition (分区字段名='新值' , ...);
查看所有分区: show partitons 分区表名;
-- 如果在hdfs上创建符合分区目录格式的文件夹,可以使用msck repair修复
同步/修复分区: msck repair table 分区表名;
-- 分区操作
-- 注意: 先确定有一级分区和多级分区表,如果没有先创建再做分区操作
select * from one_part_order limit 20;
select * from multi_part_order limit 20;
-- 添加分区(本质在hdfs上创建分区目录)
alter table one_part_order add partition (year=2024);
alter table multi_part_order add partition (year=2024,month=5,day=1);
-- 修改分区(本质在hdfs上修改分区目录名)
alter table one_part_order partition (year=2024) rename to partition (year=2030);
alter table multi_part_order partition (year=2024,month=5,day=1) rename to partition (year=2030,month=6,day=10);
-- 查看所有分区
show partitions one_part_order;
show partitions multi_part_order;
-- 删除分区
alter table multi_part_order drop partition (year=2030,month=6,day=10);
alter table multi_part_order drop partition (year=2023,month=4);
alter table multi_part_order drop partition (year=2022);
-- 如果在hdfs上创建符合分区目录格式的文件夹,可以使用msck repair修复
-- 举例:手动创建一个year=2033目录
msck repair table one_part_order;
msck repair table multi_part_order;
-- 修复后再次查看所有分区
show partitions one_part_order;
show partitions multi_part_order;

分桶表
分桶表也叫做桶表,源自建表语法中bucket单词。是一种用于优化查询而设计的表类型。该功能可以让数据分解为若干个部分易于管理。
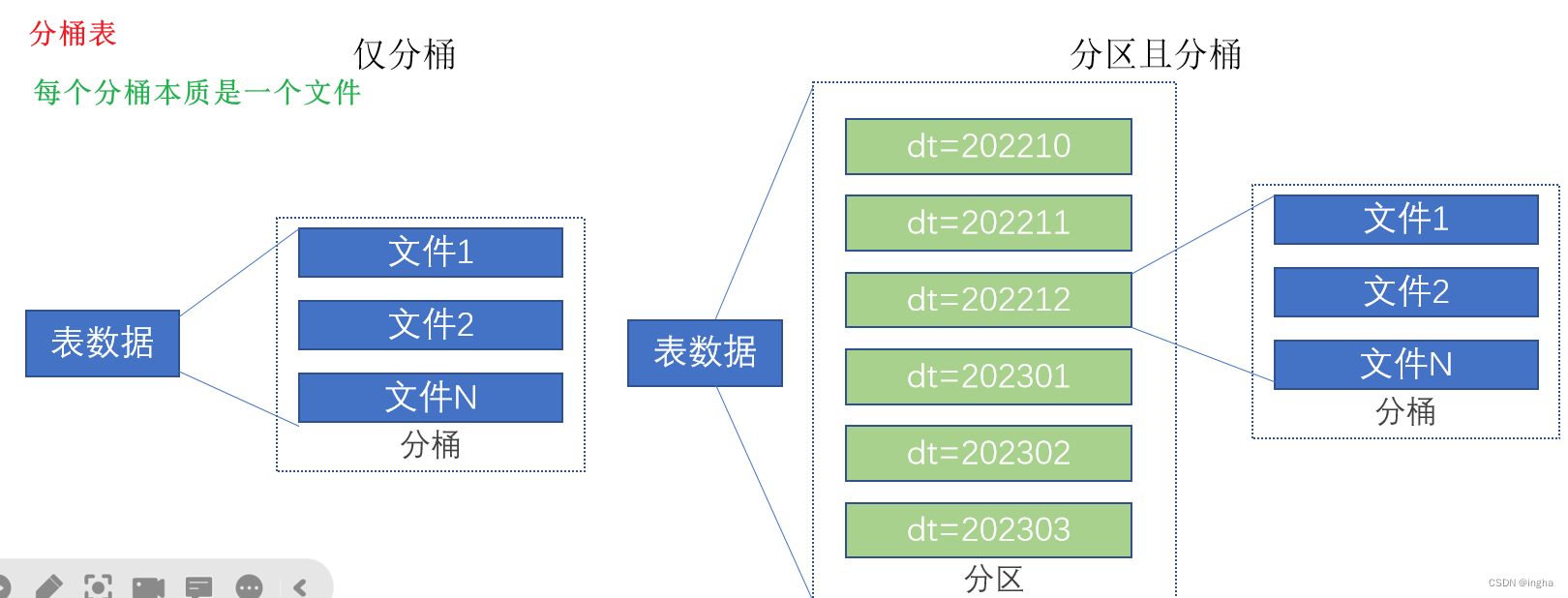
分桶表特点/优点:
需要产生分桶文件, 查询的时候特定操作上提升效率(过滤,join,分组 以及 抽样):
-
基于分桶字段查询不再需要进行全表扫描,提高抽样效率
-
JOIN时可以提高MR程序效率,减少笛卡尔积数量
对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了分桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
-
分桶表便于数据进行抽样
使用重点:
-
分桶字段名必须是原有字段名, 因为分桶需要根据对应字段值取余数把余数相同的数据放到同一个分桶文件中。
-
在查询数据的时使用分桶字段查询。如果没有使用分桶字段去筛选数据,效率不变。
重要参数
-- 默认开启,hive2.x版本已经被移除
set hive.enforce.bucketing; -- 查看未定义因为已经被移除
set hive.enforce.bucketing=true; -- 修改
-- 查看reduce数量
-- 参数优先级: set方式 > hive文档 > hadoop文档
set mapreduce.job.reduces; -- 查看默认-1,代表自动根据桶数量匹配reduce数量
set mapreduce.job.reduces=3; -- 设置参数
基础建表:
创建基础分桶表:
create [external] table 表名(
字段名 字段类型
)
clustered by (分桶字段名)
into 桶数量 buckets ;
分桶表排序:
创建基础分桶表,然后桶内排序:
create [external] table 表名(
字段名 字段类型
)
clustered by (分桶字段名)sorted by(排序字段名 asc|desc) # 注意:asc升序(默认) desc降序
into 桶数量 buckets ;
注意事项:
数据倾斜问题: 分桶字段值如果大量重复,相同的会分到同一个桶内,导致数据倾斜
解决方法:随机化处理:可以用rand()对分桶字段进行随机化处理再分桶
还有动态分区,列式存储,调整mapreduce参数以及倾斜算法来解决。
分桶原理
分桶原理:
如果是数值类型分桶字段: 直接使用数值对桶数量取模
如果是字符串类型分桶字段: 使用hash函数计算出哈希值然后再对桶数量取模
ps:Hash函数是一种将输入数据映射为固定长度输出的函数。它具有以下特点:(1)输出长度固定,不受输入长度影响;(2)同一输入必定得到相同输出;(3)不同输入几乎不可能得到相同输出。
问题1:简述下分区表和分桶表的区别?
分区表
创建表的时候使用关键字: partition by (分区字段名 分区字段类型)
分区字段名注意事项: 是一个新的字段,需要指定类型,且不能和其他字段重名
分区表好处: 使用分区字段作为条件的时候,底层直接找到对应的分区目录,能够避免全表扫描,提升查询效率
分区表最直接的效果: 在hfds表目录下,分成多个分区目录(year=xxxx,month=xx,day=xx)
不建议直接上传文件在hdfs表根路径下: 分区表直接不能识别对应文件中数据,因为分区表会找分区目录下的数据文件
使用load方式加载hdfs中文件: 本质是移动文件到对应分区目录下
分桶表
创建表的时候使用关键字: clustered by (分桶字段名) into 桶数量 buckets
分桶字段名注意事项: 是指定一个已存在的字段,不需要指定类型
分桶表好处: 使用分桶字段做抽样等特定操作的时候,也能提升性能效率
分桶表最直接的效果: 在hdfs表目录或者分区目录下,分成多个分桶文件(000000_0,000001_0,000002_0...)
不建议直接上传文件在hdfs表根路径下: 分桶表可以识别对应文件中数据,但是并没有分桶效果,也是不建议的
使用load方式加载hdfs中文件: 本质是复制数据到各个分桶文件中
问题2: 假设Hive中有表A
现在需要将表A的月分区 202309 中user_id为20000的user_dinner字段更新为bonc8920 ,其他用户user_dinner字段数据不变 ,请列出更新的方法步骤。
( Hive实现,提示:Hive中无update语法 ,请通过其他办法进行数据更新)**
insert overwrite table A partition (mon_par = '202309')
select f1, f2, f3, f4, 'bonc8920' as user_dinner
from A
where mon_par = '202309' and user_id = 20000
union all
select f1, f2, f3, f4, user_dinner
from A
where mon_par = '202309' and user_id != 20000;
perties
insert overwrite table A partition (mon_par = '202309')
select f1, f2, f3, f4, 'bonc8920' as user_dinner
from A
where mon_par = '202309' and user_id = 20000
union all
select f1, f2, f3, f4, user_dinner
from A
where mon_par = '202309' and user_id != 20000;















 2783
2783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









