









基于HBase的存储方案并没解决数据的高效检索问题。在实际应用中,经常有根据特定的几个字段进行组合后检索的应用场景,而HBase采用row key作为索引,不支持多条件查询。
由于在HBase中,表的每行都是按照RowKey的字典序排序存储,表的数据是按照RowKey区间进行分割存储成多个region,所以HBase主要适用下面这两种常见场景:适用于基于rowkey的单行数据快速随机读写、适合基于rowkey前缀的范围扫描。
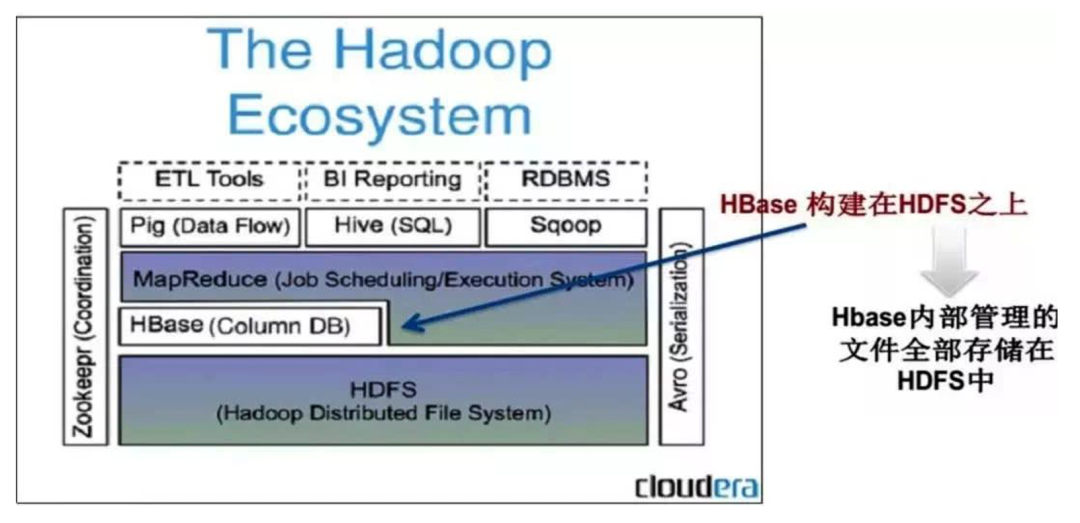
HBase里面只有rowkey作为一级索引, 如果要对库里的非rowkey字段进行数据检索和查询, 往往要通过MapReduce/Spark等分布式计算框架进行,硬件资源消耗和时间延迟都会比较高。为了HBase的数据查询更高效、适应更多的场景, 诸如使用非rowkey字段检索也能做到秒级响应,或者支持各个字段进行模糊查询和多字段组合查询等, 因此需要在HBase上面构建二级索引, 以满足现实中更复杂多样的业务需求。
这里,我们可以采用Elasticsearch存储HBase的索引信息,以支持复杂高效的查询功能。主要查询过程:
-
在Elasticsearch中存放用于检索条件的数据,并将row key也存储进去;
-
使用Elasticsearch的API根据组合标签的条件查询出row key的集合;
-
使用上一步得到的row key去HBase数据库查询对应的结果。
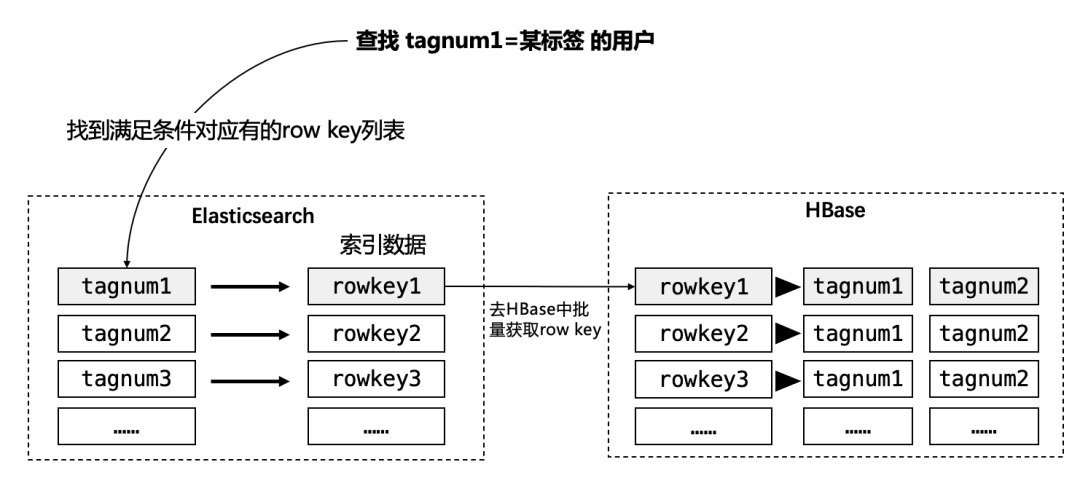
将HBase的rowkey设定为ES的文档ID,搜索时根据业务条件先从ES里面全文检索出相对应的文档,从而获取出文档ID,即拿到了rowkey,再从HBase里面抽取数据。
优点
-
发挥了Elasticsearch的全文检索的优势,能够快速根据关键字检索出相关度最高的结果;
-
同时减少了Elasticsearch的存储压力,这种场景下不需要存储检索无关的内容,甚至可以禁用_source,节约一半的存储空间,同时提升最少30%的写入速度;
-
避免了Elasticsearch大数据量下查询返回慢的问题,大数据量下Hbase的抽取速度明显优于Elasticsearch;
-
各取所长,发挥两个组件各自的优势。














 2319
2319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









