







这一节是书中的第一个比较综合的实例,包括5个.java文件,把程序实现之后没有什么大问题,只有一个接口类需要注意:LinkFilter,书中后面也说了,这个类需要实现,也给出了实现代码。这里主要说的是要注意一下这个类的引用问题。
因为这个类我是在HtmlParserTool中实现的,但是在MyCrawler中有引用,这里不必重复实现,否则会出错,具体原因我也不知道,可能是变量的作用域引起的。解决的办法就是把HtmlParserTool文件import进来就好,但是一定要具体到类:
import websphinxTest.HtmlParserTool.LinkFilter;
这样程序就能够跑通了,当然还有一点小问题,就是可能会提示编码错误,下面有举例,需要setEncoding("UTF-8"),其他的与书上一直,就是需要自己注意一下import的包和类等。
----------------------------------------------------------------------------------
程序运行结果:
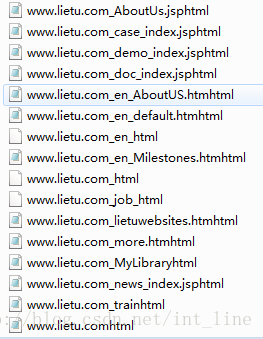
控制台会提示一些异常,当得到的新文件中无法提取出新的url时,所以以猎兔首页为种子页面时能得到上述一些文件。
后来试着改变了一下种子页面为”http://www.baidu.com“,然后出现了如下结果:
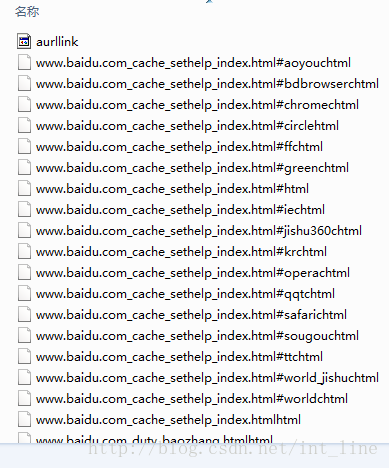
当然以百度为种子页面得到的文件自然比猎兔多,也没有出现不能提取url的情况,但是会出现新的异常:
org.htmlparser.util.EncodingChangeException: character mismatch (new: 锘 [0x9518] != old: [0xfeff?]) for encoding change from UTF-8 to GB2312 at character offset 0
网上查的结果是因为不同的页面用的编码形式不一样,需要对应不同的编码方式,但是这才刚开始做,就不再继续改进了,先记录下这个小缺点!:)
至于最顶上的aurllink文件,加了一个文件写的步骤,把url访问顺序加入进来了,不考虑重复性,利用了fw.write(link.toString()+"\n");这个方法。














 1774
1774











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









