










企业日益希望借助人工智能(AI)增加收入,提高效率和推动产品创新。尤其需要指出的是,基于深度学习(DL)的 AI 用例带来了最实用、最深刻的洞察,其中一些用例可
推动多个行业的进步,如:
•图像分类,可用于图像所属类别分类(如面部表情分类)
•对象检测,可被自动驾驶汽车用于对象定位
•图像分割,可以在患者的磁共振成像(MRI)中勾勒出器官轮廓
•自然语言处理,可进行文本分析或翻译
•推荐系统,可被在线商店用于预测客户偏好或推荐向上销售选项
这些用例仅仅是个开始。通过将 AI 融入公司运营中,企业将发现应用 AI 的新方法。然而,所有 AI 用例的商业价值在很大程度上取决于通过深度神经网络训练的模型推理出答案的速度。在 DL 模型上实施推理需要大量资源,通常需要企业更新硬件以获得所需的性能和速度。然而,许多客户希望扩展其现有的基础设施,而不是购买新的单一用途硬件。您的 IT 部门已经非常熟悉英特尔® 硬件架构,其灵活性优势可帮助您保护 IT 投资。基于人工智能推理的英特尔® 精选解决方案是 “交钥匙平台”,经过了预配置、验证和优化,可在 CPU 而非单独的加速卡上执行低延迟、高吞吐量推理。
基于人工智能推理的英特尔® 精选解决方案
基于人工智能推理的英特尔® 精选解决方案可帮助您在基于已验证过的英特尔架构解决方案上,快速部署高效的 AI 推理算法,从而加快创新和进入市场的步伐。为加快 AI 应用的推理和进入市场的速度,基于人工智能推理的英特尔® 精选解决方案将多种英特尔及第三方软件和硬件技术相结合。
软件选择
基于人工智能推理的英特尔® 精选解决方案使用的软件包括开发者工具和管理工具,可帮助您在生产环境中进行 AI 推理。
英特尔® OpenVINO™ 工具套件
英特尔® 开放视觉推理和神经网络优化工具套件(英特尔® OpenVINO™ 工具套件)是开发人员套件,可加速高性能 AI 和DL 推理部署。该工具套件对在不同框架中训练的模型进行优化, 以支持多种英特尔硬件选项,从而实现最佳性能的部署。使用工具套件的深度学习工作台可将模型量化到较低的精度,在此过程中,工具套件可以将模型从使用较大的高精度 32 位浮点数
(通常用于训练且占用较多内存),转变为使用 8 位整数,以优化内存占用和性能。将浮点数转换为整数可以显著提高 AI 推理速度,同时实现几乎相同的精度。1 该工具套件可以转换和执行在多种框架中构建的模型,包括 TensorFlow*、MXNet*、PyTorch*、Kaldi* 以及开放式神经网络交换(ONNX)生态系统支持的任何框架。此外,还提供已预训练过的公共模型,使用户不用自己去搜索和训练模型,从而加快基于英特尔处理器的开发和图像处理相关工作。
深度学习参考栈
基于人工智能推理的英特尔® 精选解决方案配有深度学习参考堆栈
(DLRS),这是一种集成的高性能开源软件堆栈,针对英特尔® 至强® 可扩展处理器进行了优化,封装在一个便捷的 Docker 容器中。DLRS 是一个预先验证和配置完备的堆栈,包括所需的库和软件组件,有助于降低与在 AI 生产环境中集成多个软件组件相关的复杂性。该堆栈还包括针对流行 DL 框架 TensorFlow 和PyTorch 高度调优的容器,及英特尔 OpenVINO 工具套件。此开源社区版本有助于确保 AI 开发人员轻松访问英特尔平台所有特性和功能。
Kubeflow 和 Seldon Core
随着企业积累了在生产环境中部署推理模型的经验,业界在一组统称为 “MLOps” 的最佳实践方面达成了共识,这些实践类似于 “DevOps” 软件开发实践。为帮助团队应用 MLOps,基于人工智能推理的英特尔® 精选解决方案使用了 Kubeflow*。借助 Kubeflow,团队可以在零停机的情况下顺利推出其模型的新版本。Kubeflow 使用受支持的模型服务后端(例如 TensorFlow Serving),将经过训练的模型导出至 Kubernetes。模型部署可使用金丝雀测试或影子部署来实现新版与旧版的并行验证。如果检测到问题,除跟踪外,团队还可使用模型和数据版本控制来简化原因分析。
为确保服务可满足人工智能推理不断增长的需求,基于人工智能推理的英特尔® 精选解决方案还提供了负载均衡功能,可自动将推理分片到节点中可服务对象的可用实例中。多租户支持提供不同的模型,从而提高硬件利用率。
最后,为加快运行 AI 推理的服务器与需要 AI 洞察的端点之间的推理请求处理速度,基于人工智能推理的英特尔® 精选解决方案可使用 Seldon Core 帮助管理推理工作流。Kubeflow 还与 Seldon Core 集成,以便在 Kubernetes 上部署 DL 模型,并使用 Kubernetes API 管理在推理工作流中部署的容器。
硬件选择
基于人工智能推理的英特尔® 精选解决方案组合了第二代智能英特尔® 至强® 可扩展处理器、英特尔® 傲腾™ 数据中心级固态盘、英特尔® 3D NAND 固态盘和英特尔® 以太网 700 系列,可帮助您的企业快速部署构建于性能优化平台上的生产级 AI 基础设施,使用大容量内存处理要求最苛刻的应用和工作负载。
第二代智能英特尔® 至强® 可扩展处理器
基于人工智能推理的英特尔® 精选解决方案具有第二代智能英特尔® 至强® 可扩展处理器的性能和功能。对于 “Base” 配置,英特尔® 至强® 金牌 6248 处理器在价格、性能和内置技术之间实现了最佳平衡,可增强在 AI 模型上进行推理的性能和效率。
“Plus” 配置推荐搭载英特尔® 至强® 铂金 8268 处理器,以实现更快的 AI 推理。这两种配置也可以使用更多的处理器数量。第二代智能英特尔® 至强® 可扩展处理器包括英特尔® 深度学习加速, 该系列加速特性可通过使用专门的矢量神经网络指令(VNNI) 集来提高 AI 推理性能,该指令集使用单指令完成以往需要三个单独指令的 DL 计算。
英特尔® 傲腾™ 数据中心级技术
英特尔® 傲腾™ 数据中心级技术填补了存储和内存层级中的关键空白,可帮助数据中心更快速访问数据。这项技术还颠覆了内存和存储层,能够为各种产品和解决方案提供持久内存、大内存池、高速缓存和存储。
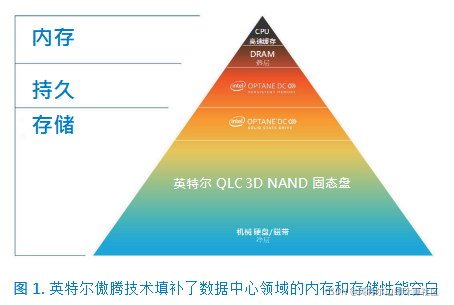
英特尔® 傲腾™ 数据中心级固态盘和英特尔® 3D NAND 固态盘当高速缓存层运行在低延迟和高耐用性的快速固态盘上时,AI 推理性能最佳。如果在高速缓存层采用最高性能的固态盘代替主流串行 ATA(SATA)固态盘,需要高性能的工作负载将受益匪浅。在这些英特尔® 精选解决方案中,英特尔® 傲腾™ 数据中心级固态盘用于驱动高速缓存层。英特尔® 傲腾™ 数据中心级固态盘可提供较高的每秒数据输入输出操作(IOPS)、性价比、低延迟和每天 30 次全盘写入的耐用性,因此它们非常适合承载写入负载较大的高速缓存功能。2 解决方案的容量层由英特尔® 3D NAND 固态盘支持,同时具备出色的数据完整性、性能一致性和磁盘可靠性,可提供优化的读取性能。
25Gb 以太网
25Gb 英特尔® 以太网 700 系列网络适配器可提高基于人工智能推理的英特尔® 精选解决方案的性能。搭配第二代英特尔® 至强® 铂金处理器和英特尔® 固态盘 DC P4600,它们相比 1Gb 以太网
(GbE)适配器和英特尔® 固态盘 DC S4500 可提供高达 2.5 倍的性能。3,4 英特尔® 以太网 700 系列提供了经过验证的性能,可通过广泛的互操作性达到数据弹性和服务可靠性的高质量阈值。5 所有英特尔® 以太网产品均享受全球售前和售后支持,并提供有限的终身保修。
通过基准测试验证性能
所有英特尔® 精选解决方案均经过基准测试的验证,达到工作负载优化性能的预先指定最低性能水平。在该解决方案中,英特尔选择使用标准的 DL 基准测试方法并模拟真实场景进行测量和基准测试。
对于标准基准测试,每秒可处理的图像数量(吞吐量)是在预先 训练的深度残差神经网络(ResNet 50 v1)上进行测量的,该网络与使用合成数据的 TensorFlow、PyTorch 和 OpenVINO 工具套件上广泛使用的 DL 用例(图像分类、定位和检测)紧密关联。
为模拟实际场景,该测试启动了代表多个请求流的多个客户端。这些客户端将图像从外部客户端系统发送到服务器以进行推理。在服务器端,入站请求由 Istio 进行负载平衡。然后,请求被发送到一个可服务对象的多个实例,该对象包含通过 Seldon Core 运行的预处理、预测和后处理步骤工作流。预测是使用 OpenVINO 工具套件模型服务器的优化 DLRS 容器映像完成的。一旦请求通过工作流,推理将被发回请求客户端。测量吞吐量和延迟可以帮助确保测试配置支持生产环境中的推理规模。
Base 和 Plus 配置
如表 1 所示,基于人工智能推理的英特尔® 精选解决方案提供两种配置。Base 配置指定了解决方案的最低要求性能,Plus 配置旨在展示系统构建商、系统集成商以及解决方案和服务提供商可如何进一步优化基于人工智能推理的英特尔® 精选解决方案,进而实现更高的性能。
客户可以升级或扩展其中一项配置,以提高容量或性能。Plus 配置利用性能更高的第二代智能英特尔® 至强® 可扩展处理器和更多内存,与 Base 配置相比可将 AI 推理速度加快高达 39%。6
如需满足基于人工智能推理的英特尔® 精选解决方案的要求,解决方案提供商必须达到或超过定义的最低配置要素,并达到以下所列的最低基准性能阈值。



**推荐但不要求
基于人工智能推理的英特尔® 精选解决方案的技术选择
除了基于人工智能推理的英特尔® 精选解决方案使用的英特尔硬件基础外,英特尔技术进一步提升了性能与可靠性:
•英特尔® 高级矢量扩展指令集 512(英特尔® AVX-512):一个 512 位指令集,可提高要求苛刻的工作负载和用例(如 AI 推理) 的性能。
•英特尔® 深度学习加速:第二代智能英特尔® 至强® 可扩展处理器中引入了一组加速功能,可大幅提高使用领先 DL 框架(例如PyTorch、TensorFlow、MXNet、PaddlePaddle 和 Caffe)构建的推理应用的性能。英特尔深度学习加速技术的基础是 VNNI, 这是一种专用指令集,使用单一指令进行 DL 计算,该任务以前需要三条单独指令。
•英特尔® OpenVINO™ 工具套件分发版:一款免费的软件套件,可帮助开发人员和数据科学家加速 AI 工作负载,并简化从网络边缘到云端的 DL 推理和部署。
•英特尔® 数学核心函数库(英特尔® MLK):该函数库实施了流行的数学运算,这些运算已针对英特尔硬件进行了优化,以帮助应用充分利用英特尔 AVX-512 指令集。它兼容广泛的编译器、语言、操作系统以及链接和线程模型。
•基于深度神经网络的英特尔® 数学核心函数库(英特尔® MKL-DNN):一个开源性能增强库,用于在英特尔硬件上加速 DL 框架。

•英特尔® Python 分发版:借助集成的英特尔® 性能库(例如英特尔® MKL),加速与 AI 有关的 Python 库(例如 NumPy*、SciPy* 和 scikit-learn*),以实现更快的 AI 推理。
•框架优化:英特尔与 Google* 开展 TensorFlow 合作,与Apache* 开展 MXNet 合作,与百度* 开展 PaddlePaddle* 、Caffe* 和 PyTorch 合作,在数据中心内使用基于英特尔® 至强® 可扩展处理器的软件优化来增强 DL 性能,并且继续增加其他行业领导者的框架。
在行业标准硬件上部署优化的快速 AI 推理
借助为英特尔® 至强® 可扩展处理器验证的工作负载优化配置, 英特尔® 精选解决方案可帮助企业快速推进数据中心转型。选择基于人工智能推理的英特尔® 精选解决方案,意味着企业可获得经过优化、测试、可扩展性验证及预先调优的配置,从而帮助IT 部门在生产环境中快速、高效地部署 AI 推理。此外,通过选择基于人工智能推理的英特尔® 精选解决方案,IT 部门可在惯常部署和管理的硬件上实现高速 AI 推理。
访问:https://www.intel.cn/content/www/cn/zh/architecture- and-technology/intel-select-solutions-overview.html, 了 解 更多信息,并向您的基础设施厂商咨询英特尔® 精选解决方案的信息。
关注英特尔边缘计算社区,表示您确认您已年满 18 岁,并同意向英特尔分享个人信息,以便通过电子邮件和电话随时了解最新英特尔技术和行业趋势。您可以随时取消订阅。英特尔网站和通信内容遵守我们的隐私声明和使用条款。


















 499
499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









