







作者:东莞职业技术学院 虞晓琼 博士
前面已介绍使用Optimum Intel工具包,OpenVINO GenAI Python API和OpenVINO GenAI C++API来部署大语言模型,本文将介绍在酷睿™ Ultra处理器上使用OpenVINO™ +vLLM部署大语言模型 (LLMs)。
1. vLLM简介
vLLM是一个由加州大学伯克利分校开发的用于快速实现的大语言模型 (LLMs) 推理和部署的开源框架,其优点有:
-
高性能:实验结果显示,相比于最流行的 LLM 库 HuggingFace Transformers (HF),vLLM 能够提供高达 24 倍的吞吐量提升。
-
易于使用:vLLM 不需要对模型架构进行任何修改就能实现高性能的推理。
-
低成本:vLLM 的出现使得大规模语言模型的部署变得更加经济实惠。
当前,vLLM已支持OpenVINO™ 后端:https://docs.vllm.ai/en/stable/

2. 搭建OpenVINO™ +vLLM开发环境
当前vLLM仅支持Linux操作系统,本文推荐安装Ubuntu22.04 LTS操作系统。若您的AIPC笔记本上已经安装了Windows,可以在Windows上使用WSL2安装Ubuntu22.04 LTS,参见:
https://learn.microsoft.com/zh-cn/windows/wsl/install
安装好Ubuntu22.04 LTS后,请升级apt工具,然后安装Python3,建立并激活虚拟环境vllm_ov,和升级pip工具。
sudo apt-get update -y
sudo apt-get install python3
sudo apt install python3.10-venv
python3 -m venv vllm_ov
source vllm_ov/bin/activate
搭建好虚拟环境后,请将vllm代码仓克隆到本地,然后安装依赖项:
git clone https://github.com/vllm-project/vllm.git
cd vllm
pip install -r requirements-build.txt --extra-index-url https://download.pytorch.org/whl/cpu
最后,安装以OpenVINO™为后端的vLLM:
PIP_EXTRA_INDEX_URL="https://download.pytorch.org/whl/cpu https://storage.openvinotoolkit.org/simple/wheels/pre-release" VLLM_TARGET_DEVICE=openvino python -m pip install -v .
到此,OpenVINO™+vLLM开发环境搭建完毕。
3. 英特尔® 酷睿™ Ultra处理器简介
英特尔® 酷睿™ Ultra处理器内置CPU+GPU+NPU 的三大 AI 引擎,赋能AI大模型在不联网的终端设备上进行推理计算。
4. 用vLLM实现大模型推理计算
带OpenVINO™ 后端的vLLM 使用以下环境变量来控制行为:
-
VLLM_OPENVINO_KVCACHE_SPACE:用于指定键值缓存(KV Cache)的大小。例如,设置 VLLM_OPENVINO_KVCACHE_SPACE=40 表示为 KV 缓存分配 40 GB 的空间。较大的设置可以让 vLLM 支持更多的并发请求。此参数应该根据硬件配置和用户的内存管理方式来设定。
-
VLLM_OPENVINO_CPU_KV_CACHE_PRECISION:用于控制 KV 缓存的精度。默认情况下,根据平台的不同,会使用 FP16 或 BF16 精度。可以通过设置 VLLM_OPENVINO_CPU_KV_CACHE_PRECISION=u8 来使用 u8(无符号 8 位整数)精度。
-
VLLM_OPENVINO_ENABLE_QUANTIZED_WEIGHTS:用于启用模型加载阶段的 U8 权重压缩。默认情况下,权重压缩是关闭的。通过设置 VLLM_OPENVINO_ENABLE_QUANTIZED_WEIGHTS=ON 来开启权重压缩。
为了提高 TPOT(Token Processing Over Time)和 TTFT(Time To First Token)的延迟性能,可以使用 vLLM 的分块预填充功能 (--enable-chunked-prefill)。根据实验结果,推荐的批处理大小是 256 (--max-num-batched-tokens=256)。
默认情况下,vLLM 会从 HuggingFace 下载模型。若您习惯从Hugging Face下载模型,则可以在设置完环境变量后,直接运行vllm自带的范例程序:vllm/examples/offline_inference.py即可。
export VLLM_OPENVINO_KVCACHE_SPACE=40
export VLLM_OPENVINO_CPU_KV_CACHE_PRECISION=u8
export VLLM_OPENVINO_ENABLE_QUANTIZED_WEIGHTS=ON
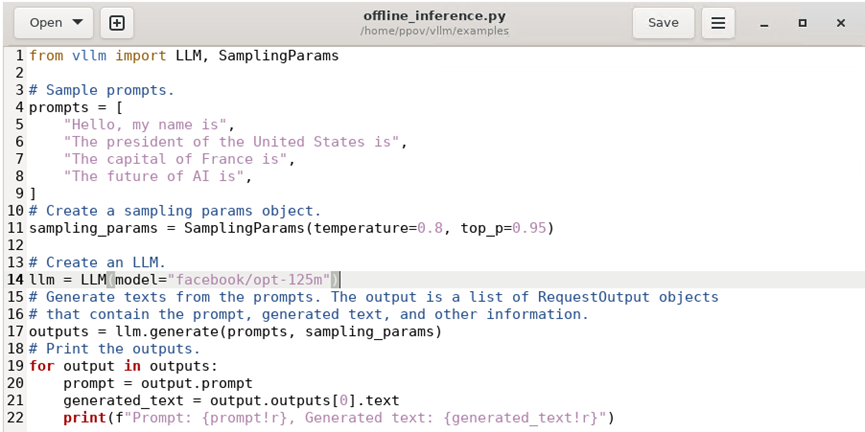
python3 vllm/examples/offline_inference.pyoffline_inference.py完整代码,如下所示:
如果您希望使用 ModelScope中的模型,请先查阅带OpenVINO™ 后端的vLLM 支持的大语言模型列表如下所示:
https://docs.vllm.ai/en/stable/models/supported_models.html
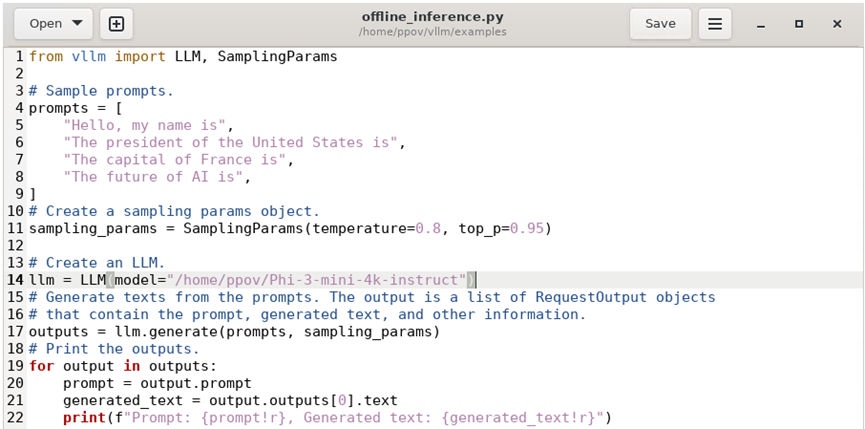
然后从 ModelScope下载,例如:下载Phi-3-mini-4k-instruct模型,请先到ModelScope中找到该模型的页面:https://www.modelscope.cn/models/LLM-Research/Phi-3-mini-4k-instruct,然后使用模型页面给出的命令下载模型。

git clone https://www.modelscope.cn/LLM-Research/Phi-3-mini-4k-instruct.git最后,把offline_inference.py程序中第14行的模型路径改为Phi-3-mini-4k-instruct模型的本地路径,如下图所示,然后运行即可。
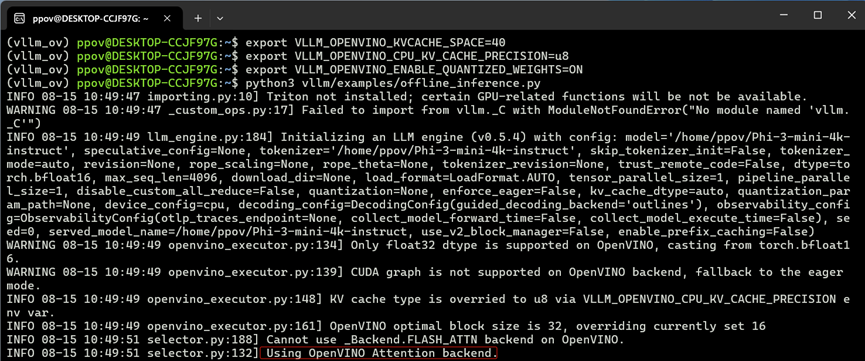
export VLLM_OPENVINO_KVCACHE_SPACE=40export VLLM_OPENVINO_CPU_KV_CACHE_PRECISION=u8export VLLM_OPENVINO_ENABLE_QUANTIZED_WEIGHTS=ONpython3 vllm/examples/offline_inference.py
5. 总结
带OpenVINO™ 后端的vLLM易学易用,很容易把在已支持模型列表中的AI大模型本地化部署在英特尔® 酷睿™ Ultra 处理器上。


















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









