







上一篇文章中我们介绍了spark-submit脚本如何提交参数给spark服务器,以及spark如何发起一个spark application,最后spark application启动后又会调用我们自己编辑的WordCount主类。这里我们接着追踪源码介绍。
追踪源码之前先简单介绍下driver概念,这样我们查看源码的过程中不至于太迷糊。
driver:用户提交的应用程序代码在spark中运行起来就是一个driver,可以简单理解driver是一段特殊的excutor进程,这个进程里面运行着DAGscheduler Tasksheduler Schedulerbackedn等组件,他们协调分工将我们代码的功能转换成task并下发给executor执行。
所以,本文要介绍的driver如何启动,其实就是我们自己的代码被如何被调用执行的过程。因为我们是client模式提交的任务,实际走的SparkApplication逻辑是JavaMainApplication(不理解的可以参考该系列的上一篇文章),这个类内部就是反射调用我们自己代码的主类(相当于启动了driver),所以client模式的driver启动很简单,根本不涉及master的调度和资源分配。但是因为client不需要spark master进行调度和资源分配,所以其也不会向master进行注册,我们再master页面也看不到driver的信息,只能看到Application的信息。所以在追踪源码的时候,看到这些现象不要太惊讶。
至于为什么我们选用client模式进行讲解,第一cluster集群部署模式是随便找一台节点启动driver,在debug的时候还要修改host名称。第二cluster集群部署模式断点查看的内容量太少,只能看到我们自己代码的执行过程,sparkSubmit提交的过程看不到,所以这里我们选用的client模式讲解,这个模式虽然和cluster模式相比少了一个driver调度的过程,但是不影响我们整体流程的追踪。
下面我们进入正文,看下WordCount中的代码:
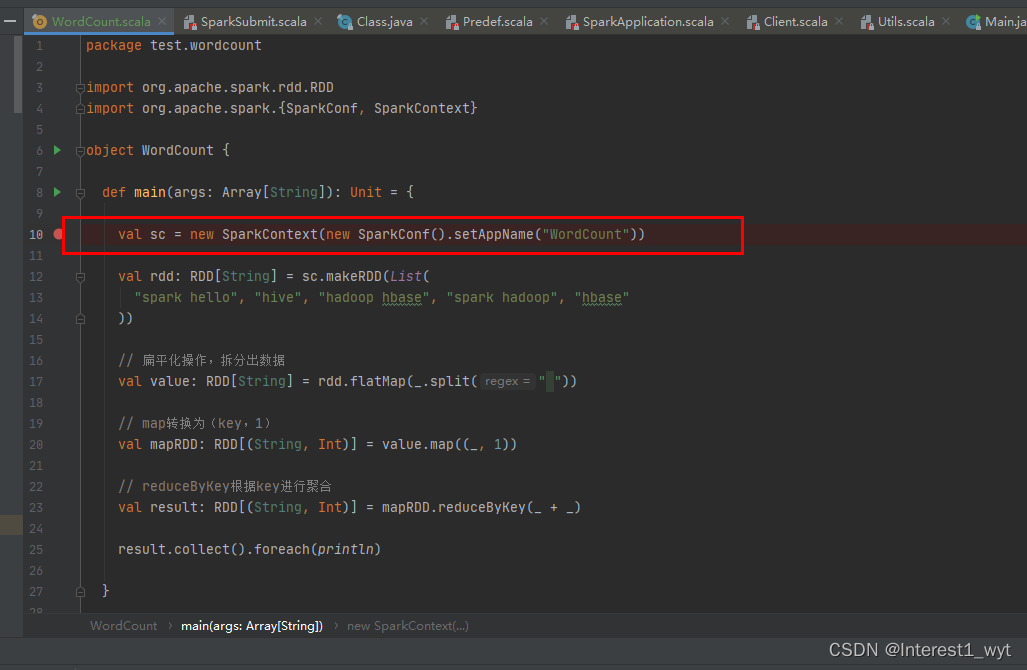
可以知道我们首先是创建一个SparkContext,接下来我们看下SparkContext的代码执行流程。通过断点可以看到再创建SparkContext时,会先执行其静态代码块:
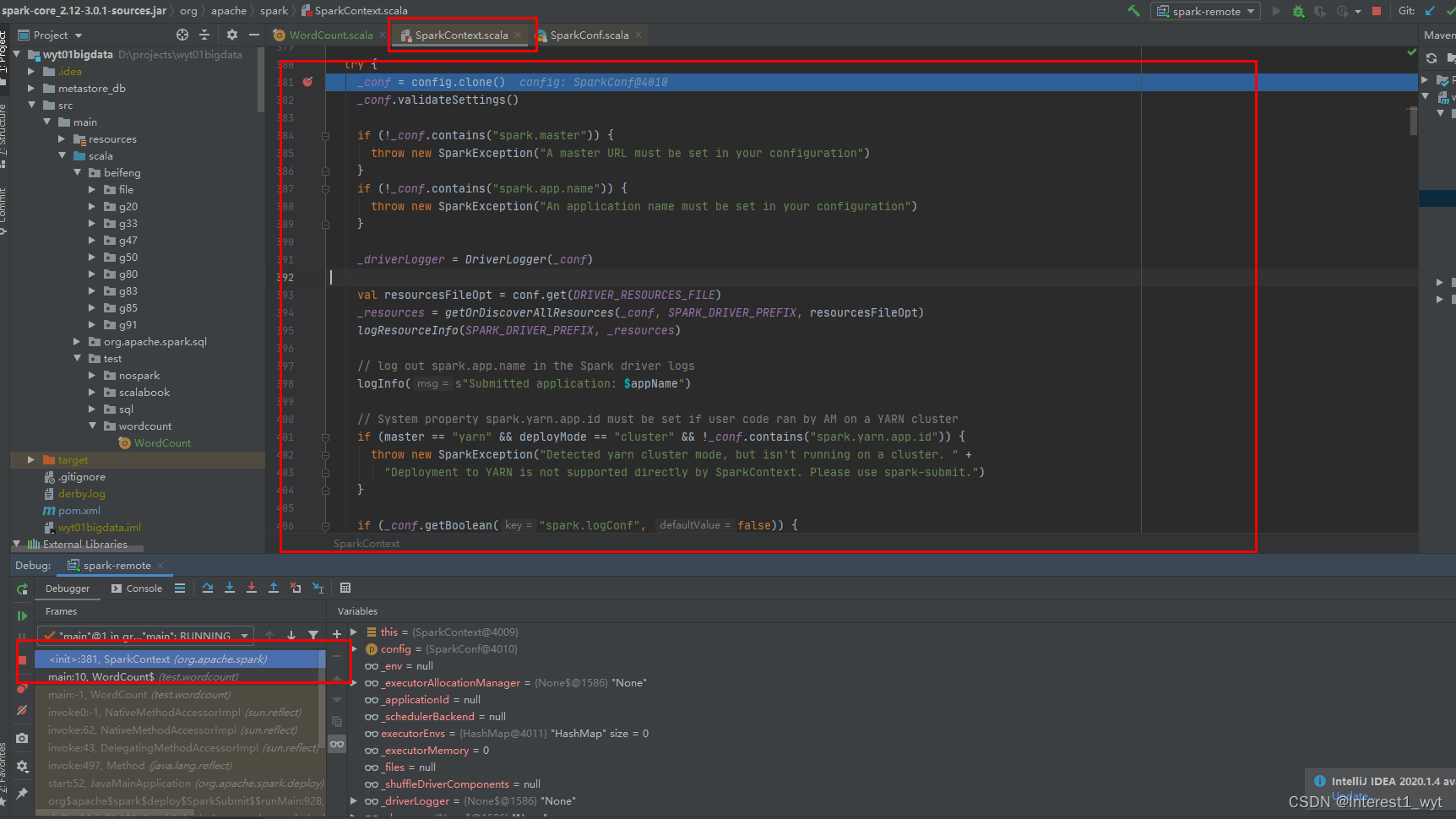
这块的代码量比较多,我们直接在原始代码上加注释:
try {
//配置的克隆和有效性验证
_conf = config.clone()
_conf.validateSettings()
if (!_conf.contains("spark.master")) {
throw new SparkException("A master URL must be set in your configuration")
}
if (!_conf.contains("spark.app.name")) {
throw new SparkException("An application name must be set in your configuration")
}
_driverLogger = DriverLogger(_conf)
//源文件信息的查找
val resourcesFileOpt = conf.get(DRIVER_RESOURCES_FILE)
_resources = getOrDiscoverAllResources(_conf, SPARK_DRIVER_PREFIX, resourcesFileOpt)
logResourceInfo(SPARK_DRIVER_PREFIX, _resources)
logInfo(s"Submitted application: $appName")
if (master == "yarn" && deployMode == "cluster" && !_conf.contains("spark.yarn.app.id")) {
throw new SparkException("Detected yarn cluster mode, but isn't running on a cluster. " +
"Deployment to YARN is not supported directly by SparkContext. Please use spark-submit.")
}
if (_conf.getBoolean("spark.logConf", false)) {
logInfo("Spark configuration:\n" + _conf.toDebugString)
}
//driver所在主机和对应端口号设置
_conf.set(DRIVER_HOST_ADDRESS, _conf.get(DRIVER_HOST_ADDRESS))
_conf.setIfMissing(DRIVER_PORT, 0)
_conf.set(EXECUTOR_ID, SparkContext.DRIVER_IDENTIFIER)
//获取配置中指定的jar和file文件信息
_jars = Utils.getUserJars(_conf)
_files = _conf.getOption(FILES.key).map(_.split(",")).map(_.filter(_.nonEmpty))
.toSeq.flatten
//判断是否开启历史记录模式,获取历史日志存储的路径和编码方式
_eventLogDir =
if (isEventLogEnabled) {
val unresolvedDir = conf.get(EVENT_LOG_DIR).stripSuffix("/")
Some(Utils.resolveURI(unresolvedDir))
} else {
None
}
_eventLogCodec = {
val compress = _conf.get(EVENT_LOG_COMPRESS)
if (compress && isEventLogEnabled) {
Some(_conf.get(EVENT_LOG_COMPRESSION_CODEC)).map(CompressionCodec.getShortName)
} else {
None
}
}
//创建监听总线对象,用于异步提交事件到对应监视器
_listenerBus = new LiveListenerBus(_conf)
//初始化application状态,并增加对应的监听器
val appStatusSource = AppStatusSource.createSource(conf)
_statusStore = AppStatusStore.createLiveStore(conf, appStatusSource)
listenerBus.addToStatusQueue(_statusStore.listener.get)
//重点一:创建SparkEnv,其和节点通信、任务计算、数据存储等功能息息相关。一般在driver和executor对象中创建。
_env = createSparkEnv(_conf, isLocal, listenerBus)
SparkEnv.set(_env)
_conf.getOption("spark.repl.class.outputDir").foreach { path =>
val replUri = _env.rpcEnv.fileServer.addDirectory("/classes", new File(path))
_conf.set("spark.repl.class.uri", replUri)
}
//创建状态追踪器,追踪job和stage的进度信息
_statusTracker = new SparkStatusTracker(this, _statusStore)
_progressBar =
if (_conf.get(UI_SHOW_CONSOLE_PROGRESS)) {
Some(new ConsoleProgressBar(this))
} else {
None
}
//重点二:创建并初始化SparkUI,也就是记录job详细运行信息的页面
_ui =
if (conf.get(UI_ENABLED)) {
Some(SparkUI.create(Some(this), _statusStore, _conf, _env.securityManager, appName, "",
startTime))
} else {
None
}
_ui.foreach(_.bind())
_hadoopConfiguration = SparkHadoopUtil.get.newConfiguration(_conf)
_hadoopConfiguration.size()
// 为要执行的任务添加jar和file依赖
if (jars != null) {
jars.foreach(addJar)
}
if (files != null) {
files.foreach(addFile)
}
//获取executor内存信息
_executorMemory = _conf.getOption(EXECUTOR_MEMORY.key)
.orElse(Option(System.getenv("SPARK_EXECUTOR_MEMORY")))
.orElse(Option(System.getenv("SPARK_MEM"))
.map(warnSparkMem))
.map(Utils.memoryStringToMb)
.getOrElse(1024)
//设置executorEnvs信息
for { (envKey, propKey) <- Seq(("SPARK_TESTING", IS_TESTING.key))
value <- Option(System.getenv(envKey)).orElse(Option(System.getProperty(propKey)))} {
executorEnvs(envKey) = value
}
Option(System.getenv("SPARK_PREPEND_CLASSES")).foreach { v =>
executorEnvs("SPARK_PREPEND_CLASSES") = v
}
executorEnvs("SPARK_EXECUTOR_MEMORY") = executorMemory + "m"
executorEnvs ++= _conf.getExecutorEnv
executorEnvs("SPARK_USER") = sparkUser
_shuffleDriverComponents = ShuffleDataIOUtils.loadShuffleDataIO(config).driver()
_shuffleDriverComponents.initializeApplication().asScala.foreach { case (k, v) =>
_conf.set(ShuffleDataIOUtils.SHUFFLE_SPARK_CONF_PREFIX + k, v)
}
//重点三:创建心跳接收器(其接收executor心跳,executor创建时会检索该接收器,所以该步骤一定要在createTaskScheduler步骤之前执行)
_heartbeatReceiver = env.rpcEnv.setupEndpoint(
HeartbeatReceiver.ENDPOINT_NAME, new HeartbeatReceiver(this))
// 初始化一些插件
_plugins = PluginContainer(this, _resources.asJava)
//重点四:创建TaskScheduler(和我们的问题有关,后面会再深入讲)
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
//重点五:创建DAGScheduler(和我们的问题有关,后面会再深入讲)
_dagScheduler = new DAGScheduler(this)
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
val _executorMetricsSource =
if (_conf.get(METRICS_EXECUTORMETRICS_SOURCE_ENABLED)) {
Some(new ExecutorMetricsSource)
} else {
None
}
// 创建和发起心跳,进而收集内存信息
_heartbeater = new Heartbeater(
() => SparkContext.this.reportHeartBeat(_executorMetricsSource),
"driver-heartbeater",
conf.get(EXECUTOR_HEARTBEAT_INTERVAL))
_heartbeater.start()
// 重点六:启动TaskScheduler(和我们的问题有关,后面会再深入讲)
_taskScheduler.start()
//获取和设置application相关的信息
_applicationId = _taskScheduler.applicationId()
_applicationAttemptId = _taskScheduler.applicationAttemptId()
_conf.set("spark.app.id", _applicationId)
if (_conf.get(UI_REVERSE_PROXY)) {
System.setProperty("spark.ui.proxyBase", "/proxy/" + _applicationId)
}
_ui.foreach(_.setAppId(_applicationId))
_env.blockManager.initialize(_applicationId)
// 启动度量系统
_env.metricsSystem.start(_conf.get(METRICS_STATIC_SOURCES_ENABLED))
// 将driver相关的信息和ui页面关联起来
_env.metricsSystem.getServletHandlers.foreach(handler => ui.foreach(_.attachHandler(handler)))
//启动日志监听事件,存储日志信息,这样后期任务执行结束仍可以查看
_eventLogger =
if (isEventLogEnabled) {
val logger =
new EventLoggingListener(_applicationId, _applicationAttemptId, _eventLogDir.get,
_conf, _hadoopConfiguration)
logger.start()
listenerBus.addToEventLogQueue(logger)
Some(logger)
} else {
None
}
_cleaner =
if (_conf.get(CLEANER_REFERENCE_TRACKING)) {
Some(new ContextCleaner(this, _shuffleDriverComponents))
} else {
None
}
_cleaner.foreach(_.start())
val dynamicAllocationEnabled = Utils.isDynamicAllocationEnabled(_conf)
_executorAllocationManager =
if (dynamicAllocationEnabled) {
schedulerBackend match {
case b: ExecutorAllocationClient =>
Some(new ExecutorAllocationManager(
schedulerBackend.asInstanceOf[ExecutorAllocationClient], listenerBus, _conf,
cleaner = cleaner))
case _ =>
None
}
} else {
None
}
_executorAllocationManager.foreach(_.start())
setupAndStartListenerBus()
postEnvironmentUpdate()
postApplicationStart()
// 一些后置处理
_taskScheduler.postStartHook()
_env.metricsSystem.registerSource(_dagScheduler.metricsSource)
_env.metricsSystem.registerSource(new BlockManagerSource(_env.blockManager))
_env.metricsSystem.registerSource(new JVMCPUSource())
_executorMetricsSource.foreach(_.register(_env.metricsSystem))
_executorAllocationManager.foreach { e =>
_env.metricsSystem.registerSource(e.executorAllocationManagerSource)
}
appStatusSource.foreach(_env.metricsSystem.registerSource(_))
_plugins.foreach(_.registerMetrics(applicationId))
// 任务执行结束的钩子函数
logDebug("Adding shutdown hook") // force eager creation of logger
_shutdownHookRef = ShutdownHookManager.addShutdownHook(
ShutdownHookManager.SPARK_CONTEXT_SHUTDOWN_PRIORITY) { () =>
logInfo("Invoking stop() from shutdown hook")
try {
stop()
} catch {
case e: Throwable =>
logWarning("Ignoring Exception while stopping SparkContext from shutdown hook", e)
}
}
} catch {
case NonFatal(e) =>
logError("Error initializing SparkContext.", e)
try {
stop()
} catch {
case NonFatal(inner) =>
logError("Error stopping SparkContext after init error.", inner)
} finally {
throw e
}
}
通过上面的注解可以知道SparkContext创建过程中的重点有多处(因为没有详细看过,所以我罗列的可能还不全),但是和我们问题相关的只有重点四、五、六三处,下面我们依次看一下。
重点四:创建TaskScheduler
首先来看下createTaskScheduler方法的入参和出参:

可以看到其接收一个SparkContext对象和集群ip以及部署模式,返回的是SchedulerBackend, TaskScheduler对象,这两个都是接口,根据不同场景有不同实现类,其功能如下:
SchedulerBackend:和不同的系统对接,包含executor的信息,即主要负责RPC节点消息的接收与传递。
TaskScheduler:和DAGScheduler对接,接收其传递过来的任务信息,处理后通过SchedulerBackend发送出去。
因此TaskScheduler和SchedulerBackend是一个整体,它们配合才完成了任务从DAGScheduler到executor往返操作流程。下面我们接着debug看源码:

其代码比较简单,主要是根据我们的集群模式创建TaskScheduler和SchedulerBackend的实现类,实现类分别是TaskSchedulerImpl和StandaloneSchedulerBackend,不过schedule初始化要留意下,因为它不仅将SchedulerBackend实现类的引用存到TaskScheduler中(便于TaskScheduler通过SchedulerBackend和其它节点通信),还根据配置创建了任务提交池。

可以看到我们默认创建的任务调度池是先进先出的。
重点五:创建DAGScheduler
DAGScheduler的创建经过多个重载方法,最终构造方法如下:

可以看到 DAGScheduler的创建很简单,就是将TaskScheduler还有事件监听总线等对象传入构造器。这里需要留意只有一点就是虽然DAGScheduler是TaskScheduler流程上的上级工作节点,但是TaskScheduler需要在DAGScheduler之前先创立。只有这样DAGScheduler才能在创建时拿到TaskScheduler的信息,进而将任务下发给TaskScheduler。
重点六:启动TaskScheduler(重中之重)
因为TaskScheduler是一个接口,上面我们获取到的实现类是TaskSchedulerImpl,所以我们直接到TaskSchedulerImpl的启动方法中去看:

可以看到 TaskSchedulerImpl启动主要是调用SchedulerBackend的启动方法,SchedulerBackend也是一个接口,在本地debug案例中其实现类为StandaloneSchedulerBackend,所以我们去StandaloneSchedulerBackend看其启动方法,因为类方法比较多,我们下面还是先直接贴源码。
override def start(): Unit = {
//父类启动方法,主要是组以及token相关的操作
super.start()
// 重点一:LauncherBackend的连接
if (sc.deployMode == "client") {
launcherBackend.connect()
}
// driver RPC节点创建(注意只是创建,还有注册到RPC服务上)
val driverUrl = RpcEndpointAddress(
sc.conf.get(config.DRIVER_HOST_ADDRESS),
sc.conf.get(config.DRIVER_PORT),
CoarseGrainedSchedulerBackend.ENDPOINT_NAME).toString
// 封装参数信息
val args = Seq(
"--driver-url", driverUrl,
"--executor-id", "{{EXECUTOR_ID}}",
"--hostname", "{{HOSTNAME}}",
"--cores", "{{CORES}}",
"--app-id", "{{APP_ID}}",
"--worker-url", "{{WORKER_URL}}")
val extraJavaOpts = sc.conf.get(config.EXECUTOR_JAVA_OPTIONS)
.map(Utils.splitCommandString).getOrElse(Seq.empty)
val classPathEntries = sc.conf.get(config.EXECUTOR_CLASS_PATH)
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
val libraryPathEntries = sc.conf.get(config.EXECUTOR_LIBRARY_PATH)
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
// 测试类路径的获取
val testingClassPath =
if (sys.props.contains(IS_TESTING.key)) {
sys.props("java.class.path").split(java.io.File.pathSeparator).toSeq
} else {
Nil
}
// 重点二:构建executor相关的命令
val sparkJavaOpts = Utils.sparkJavaOpts(conf, SparkConf.isExecutorStartupConf)
val javaOpts = sparkJavaOpts ++ extraJavaOpts
val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend",
args, sc.executorEnvs, classPathEntries ++ testingClassPath, libraryPathEntries, javaOpts)
val webUrl = sc.ui.map(_.webUrl).getOrElse("")
val coresPerExecutor = conf.getOption(config.EXECUTOR_CORES.key).map(_.toInt)
val initialExecutorLimit =
if (Utils.isDynamicAllocationEnabled(conf)) {
Some(0)
} else {
None
}
val executorResourceReqs = ResourceUtils.parseResourceRequirements(conf,
config.SPARK_EXECUTOR_PREFIX)
// 封装Application相关的一些信息
val appDesc = ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
webUrl, sc.eventLogDir, sc.eventLogCodec, coresPerExecutor, initialExecutorLimit,
resourceReqsPerExecutor = executorResourceReqs)
// 重点三:创建StandaloneAppClient对象并启动,用于application和集群间通信
client = new StandaloneAppClient(sc.env.rpcEnv, masters, appDesc, this, conf)
client.start()
//更新spark app状态为提交状态
launcherBackend.setState(SparkAppHandle.State.SUBMITTED)
//等待spark master返回响应信息
waitForRegistration()
//更新spark app为运行状态
launcherBackend.setState(SparkAppHandle.State.RUNNING)
}StandaloneSchedulerBackend的重点有三处,我们依次看下:
重点一:LauncherBackend的连接
LauncherBackend和LauncherServer配合使用,实现用户app和spark app间的信息交流,其中LauncherServer在用户app中构建,LauncherBackend则在spark app中构建。二者的界限也很好区分,就拿我们的WordCount案例来说,在使用SparkSubmit提交到集群运行前都属于用户app,而WordCount运行在spark上则属于spark app阶段。

这块代码没什么难度,主要是留意下LauncherBackend和LauncherServer的通信是通过Socket实现。
重点二:构建executor相关的命令(executor创建相关的入口,离真正创建还早)
这块代码也没什么难度,主要是通过Command对象存储executor相关的参数信息,这块之所以标注为重点,是因为从这开始,executor的创建就要开始了,另外要注意下CoarseGrainedExecutorBackend这个类,它是executor创建的主要入口类。


重点三:创建StandaloneAppClient对象并启动,用于application和集群间通信
StandaloneAppClient的创建,主要是存储一些参数信息,这里我们直接进入查看它的启动方法:

可以看到 StandaloneAppClient的启动主要是注册一个RPC服务节点,因为这个是RPC节点,我们没法断点查看它的启动流程,不过通过其receive方法可以大致看出该服务节点的大致功能,这里我们不详细介绍该节点,后面具体哪个事件发送过来,我们再过来看,现在我们先直接看下它启动方法。如下:

可以看到它在启动的时候会去向Master注册,具体注册的是什么呢,让我们接着深入下:

这块代码比较多,但是大多是重试的保证机制,我们抓住主线,直接到tryRegisterAllMasters方法中查看:

可以看到,最终其通过master的RPC客户端节点,向其发送了一个Application的注册事件。
到这有的人可能会有疑惑,executor的创建启动呢,这怎么只注册了application呢,executor的创建请求呢,不要急,还记得前面创建的Command对象吗,它包含了executor创建相关的参数,而它就封装在Application中,所以我们接下来还需要到master节点查看下其接收到RegisterApplication事件后的处理过程。
SparkContext初始化中的关键步骤分析到这基本就结束了,而我们阅读源码的的目的(了解driver的启动和application的注册以及executor命令的拼装)也达到了,下面我们简单总结下
总结:
1、看源码特别是复杂的源码时一定要抓住主线,阅读时掌握好详略的度
2、driver的启动实际上就是WordCount代码的执行
3、application的启动比driver要早一点,实际上在WordCount运行前就已经创建和启动了SparkApplication
4、executor的构建命令是在创建TaskScheduler的时候拼装的,executor创建完成后会将executor信息再注册到TaskScheduler内,这样便于Task任务的下发。(这里的TaskScheduler是一个统称,并非具体的类对象,具体的实现类有多种)
5、注意SchedulerBackend和StandaloneAppClient两个RPC节点的区别,虽然他们都是在TaskScheduler启动的过程中创建,但是前者主要和task任务下发有关,而后者则和application、executor等的注册移除有关。
6、client模式driver不会向master进行注册














 643
643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









