







正则表达式就是一个字符串。所以也可以叫模式字符串,或者直接叫模式。
一些程序(如grep)能够根据正则表达式查找相匹配的字符串。这就是正则表达式的作用。
正则表达式中某些字符具有特殊意义,这些字符称为元字符。
一、发展历史
20 世纪 40 年代,两位神经生理学家 Warren McCulloch 和 Walter Pitts,研究出了一种用数学方式来描述神经网络的方法,可以将神经系统中的神经元描述成小而简单的自动控制元。
50 年代,一位叫 Stephen Kleene 的数学家在 McCulloch 和 Pitts 早期工作的基础上,发表了《神经网络事件表示法和有穷自动机》论文。这篇论文描述了一种叫做 "正则集合(Regular Sets)" 的数学符号,引入了正则表达式的概念。
60 年代,Unix 之父 Ken Thompson 发表了 《正则表达式搜索算法》论文。并且根据这篇论文的算法,将正则引入到编辑器 qed ,以及之后的编辑器 ed 中,然后又移植到了我们熟悉的文本搜索工具 grep 中。
70 年代,由于 grep 支持的功能不多,因此 Alfred Aho 编写了 egrep 程序(其中 e 表示加强版的意思)。在 grep 、 egrep 发展的同时, awk 、 lex 、 sed 等异军也开始凸起,每个程序所支持的正则表达式都有差别。
80 年代,POSIX (Portable Operating System Interface) 标准公诸于世,它制定了不同的操作系统都需要遵守的一套规则,其中就包括正则表达式的规则。遵循 POSIX 规则的正则表达式,称为 POSIX 派系的正则表达式。Unix 系统或类 Unix 系统上的大部分工具,如 grep 、sed 、awk 等都属于 POSIX 派系。同样在 80 年代,Larry Wall 发布了 Perl 编程语言,其中引入的正则表达式功能是颗耀眼明珠。
90 年代,随着 Perl 语言的发展,它的正则表达式功能越来越强悍。为了把 Perl 语言中正则的功能移植到其他语言中, PCRE (Perl Compatible Regular Expressions)派系的正则表达式也诞生了。现代编程语言如 Python , Ruby , PHP , C / C++ , Java 等正则表达式,大部分都属于 PCRE 派系。
总的来说,经历 20 世纪 80 至 90 年代洗礼,正则表达式形成了两大派系:POSIX 与 PCRE
二、两种正则表达式:
(一)perl正则表达式
也叫PCRE(Perl Compatible Regular Expression)
Perl的正则表达式源自于Henry Spencer于1986年1月19日发布的regex,它已经演化成了PCRE(Perl兼容正则表达式,Perl Compatible Regular Expressions),一个由Philip Hazel开发的,为很多现代工具所使用的库。
perl正则表达式完整格式:
/pattern/flags
1./
叫做分隔符,或者定界符。
perl正则表达式必须以分隔符包围:
(1)分隔符可以使用任意的非字母数字,非反斜线,非空白 ascii 字符,如常用的 / # ~
(2)甚至其首尾可以使用括号闭合 () [] {} <>
(3)但若使用元字符( 如 + * ^)作为分隔符,则该正则表达式中不能再使用该分隔符(转义的除外)。如果分隔符需要在模式内进行匹配,就必须进行转义。如果分隔符经常在模式内出现,更好的选择就是用其他分隔符来提高可读性。
如,
/foo bar/
#^[^0-9]$#
+php+
%[a-zA-Z0-9_-]%
2.pattern
模式字符串,真正的正则表达式。
某些特殊字符具有特殊意义,这些字符称为元字符。如. * + ? () {} \等
有两种元字符:一种在[]之外使用,一种在[]之内使用。
(1)转义符\
因为特殊字符不能原样匹配,所以如果想匹配这些字符,必须在前面加转义符,如\. \*
一些普通字符在前面加转义符,会变得有特殊意义,如\d \w
总结一下就是,\会使元字符变成普通字符,使普通字符变成元字符。
\Q...\E 把\Q和\E中间的字符通通作为原样字符。
(2)替代符
匹配一个字符
替代符可以单独使用。
有如下:
. 匹配除“\n”之外的任何单个字符
[] 匹配[]之内的任意单字符,[]也叫字符类
posix字符类:
要把它们放到[]号内才能使用,如[[:alnum:]]
| 字符类 | 说明 |
|---|---|
| [:alnum:] | 任何一个字母或数字(等价于[a-zA-Z0-9]) |
| [:alpha:] | 任何一个字母(等价于[a-zA-Z]) |
| [:blank:] | 空格或制表符(等价于[\t ]) |
| [:cntrl:] | 任一ASCII控制字符(ASCII0到31,再加上ASCII127) 也叫不可打印[^[:print:]] [\x00-\x1F\x7F] |
| [:digit:] | 任何一个数字(等价于[0-9])\d |
| [:print:] | 任何一个可打印字符 [^[:cntrl:]] [\x20-\x7E] |
| [:graph:] | 和[:print:]一样,但不包括空格 [\x21-\x7E] |
| [:lower:] | 任何一个小写字母(等价于[a-z]) |
| [:upper:] | 任何一个大写字母(等价于[A-Z]) |
| [:punct:] | 既不属于[:alnum:]也不属于[:cntrl:]的任何一个字符 []\[!"#$%&'()*+,./:;<=>?@\^_`{|}~-] |
| [:space:] | 任何一个空白字符,包括空格(等价于[\f\n\r\t\v ]) \s |
| [:xdigit:] | 任何一个十六进制数值(等价于[a-fA-F0-9]) |
| [:word:] | 任一“字”字符,等价于[a-zA-Z0-9_] \w |
转义的替代符,有如下这些:
匹配某一个特定字符
\a alarm (BEL),等价于\x07或\cG
\t tab (HT, TAB) 水平制表符,等价于 \x09\或\cl
\n newline (LF, NL) 换行符,等价于 \x0a 或 \cJ
\v vertical tab(VT)垂直制表符;等价于\x0b或\cK
\f form feed (FF) 换页符,等价于 \x0c 或 \cL
\r carriage return (CR) 回车符,等价于\x0d 或 \cM
\e escape (ESC),等价于\x1b或\c[
\cx “control-x”,其中 x 是任意字符。匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。
\0dd 字符码八进制数为dd的字符
\ddd 字符码八进制数为ddd的字符,或者回溯引用
\o{ddd} 字符码八进制数为ddd的字符
\xhh 字符码十六进制数为hh的字符
\x{hh} 字符码十六进制数为hh的字符
\N{name} Unicode字符名为name的字符
\N{U+263D} Unicode字符码为263D的字符
\u4E00 unicode码为4E00的字符
\u{hhhh} unicode码为hhhh的字符
\U0002EBEF unicode码为0002EBEF的字符
匹配某一类单字符(字符类):
\d 任一数字,等价于[0-9]
\D 任一非数字字符,等价于[^0-9]
\h 水平空白符,包括tab和空格,等价于[\t ]
\H 非水平空白符,等价于[^\t ]
\s 任一空白字符,等价于 [ \f\n\r\t\v]
\S 任一非空白字符,等价于[^ \f\n\r\t\v]
\w 任一“字”的字符,匹配一个英文字母、数字或下划线;等价于[0-9a-zA-Z_]
\W 任一“非字”的字符,匹配除英文字母、数字和下划线以外任何一个字符,等价于[^0-9a-zA-Z_]
\V 任一非垂直空白的字符,[^\v]
\N 任一非换行的字符,[^\n]
\R 一个换行的序列,\n+
\X a Unicode extended grapheme cluster
\p{xx} 拥有xx属性的字符
\P{xx} 没有xx属性的字符
属性有如下:
GENERAL CATEGORY PROPERTIES FOR \p and \P
C Other
Cc Control
Cf Format
Cn Unassigned
Co Private use
Cs Surrogate
L Letter
Ll Lower case letter
Lm Modifier letter
Lo Other letter
Lt Title case letter
Lu Upper case letter
L& Ll, Lu, or Lt
M Mark
Mc Spacing mark
Me Enclosing mark
Mn Non-spacing mark
N Number
Nd Decimal number
Nl Letter number
No Other number
P Punctuation
Pc Connector punctuation
Pd Dash punctuation
Pe Close punctuation
Pf Final punctuation
Pi Initial punctuation
Po Other punctuation
Ps Open punctuation
S Symbol
Sc Currency symbol
Sk Modifier symbol
Sm Mathematical symbol
So Other symbol
Z Separator
Zl Line separator
Zp Paragraph separator
Zs Space separator
PCRE2 SPECIAL CATEGORY PROPERTIES FOR \p and \P
Xan Alphanumeric: union of properties L and N
Xps POSIX space: property Z or tab, NL, VT, FF, CR
Xsp Perl space: property Z or tab, NL, VT, FF, CR
Xuc Univerally-named character: one that can be
represented by a Universal Character Name
Xwd Perl word: property Xan or underscore
(3)限定符
限定符用来指定前面一个组件要出现的次数。所以也叫量词。
限定符不能单独使用。必须在表达式后面。
有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种。
| 贪婪 | 非贪婪 | 描述 |
|---|---|---|
| exp* | exp*? | 匹配前面的子表达式零次或多次。 例如,zo*能匹配"z"以及"zoo"。* 等价于{0,}。 |
| exp+ | exp+? | 匹配前面的子表达式一次或多次。 例如,zo+能匹配"zo"以及"zoo",但不能匹配"z"。+等价于{1,}。 |
| exp? | exp?? | 匹配前面的子表达式零次或一次。 例如,do(es)?可以匹配"do"、"does"、"doxy"中的"do"。?等价于{0,1}。 |
| exp{n} | exp{n} | n是一个非负整数。匹配恰好n次。 例如,o{2}不能匹配"Bob"中的o,但是能匹配"food"中的两个o。 |
| exp{n,} | exp{n,}? | n是一个非负整数。至少匹配n 次。 例如,o{2,}不能匹配"Bob"中的o,但能匹配"foooood"中的所有 o。 |
| exp{n,m} | exp{n,m}? | m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。 例如,o{1,3}将匹配"fooooood"中的前三个o。 请注意在逗号和两个数之间不能有空格。 |
限定符匹配默认为贪婪匹配,也就是尽可能多的向后匹配字符,比如{n,m}表示匹配前面的内容出现n到m次(n 小于 m),在贪婪模式下,首先以匹配m次为目标,而在非贪婪模式是尽可能少的向后匹配内容,也就是说匹配n次即可。
贪婪模式转换为非贪婪模式的方法很简单,在元字符后添加“?”
例子1:
代码如下:
#!/usr/bin/python3
import re
str = 'aaa'
regex1 = re.compile('a+?')
regex2 = re.compile('a+')
relist1 = regex1.findall(str)
relist2 = regex2.findall(str)
print(relist1)
print(relist2)
执行结果:
['a', 'a', 'a']
['aaa']
(4)定位符
定位符指定一个表达式的位置。也叫断言。
定位符一般也不能单独使用,要和表达式一起使用。
| 字符 | 描述 |
|---|---|
| ^exp | 指定表达式是行的开头 |
| exp$ | 指定表达式是行的结尾 |
| \bexp exp\b | 指定表达式是词的边界。\bis匹配头为is的词,is\b匹配尾为is的词,/\bis\b/匹配is单词 |
| \Bexp exp\B | 指定表达式不是词的边界。\Bis匹配单词“This”中的“is” |
| \Aexp | 指定表达式是行的开头 |
| exp\Z | 指定表达式是行的结尾 |
| exp\z | 指定表达式是行的结尾 |
| exp(?=pattern) | 指定exp必须在pattern的紧前面。也叫肯定式向前查找,lookahead |
| exp(?!pattern) | 指定exp必须不在pattern的紧前面。否定式向前查找,lookahead |
| (?<=pattern)exp | 指定exp必须在pattern的紧后面。肯定式向后查找,lookbehind,向后查找pattern必须是固定长度 |
| (?<!pattern)exp | 指定exp必须不在pattern的紧后面。否定式向后查找,lookbehind,向后查找pattern必须是固定长度 |
例子:
1)肯定式向前查找
匹配必须在 test紧前面的start
正则模式:start(?= test)
$ cat xx.txt
start test ieog trewg;qw start ketmq
start plll so eti start testo ogoqwet
start xx kk o3wq0tjo;mlv
klvkldmgq qosstart etlkg
lsjkr0934k ir03t42
$ grep -n -P 'start(?= test)' xx.txt
2:start test ieog trewg;qw start ketmq
3:start plll so eti start testo ogoqwet
$ grep -n -P 'start test' xx.txt
2:start test ieog trewg;qw start ketmq
3:start plll so eti start testo ogoqwet
$ grep -o -n -P 'start(?= test)' xx.txt
2:start
3:start
$ grep -o -n -P 'start test' xx.txt
2:start test
3:start test
如果只打印匹配的部分,可以发现start(?= test)与start test还是不太一样匹配必须在.some紧前面的some
正则模式:some(?=.some)
2)否定式向前查找
匹配必须不在 test紧前面的start
正则模式:start(?! test)
3)肯定式向后查找
匹配必须在rt 紧后面的test
正则模式:(?<=rt )test
4)否定式向后查找
匹配必须不在rt 紧后面的test
正则模式:(?<!rt )test
不匹配模式
^.*(?!if).*$ 这种写法使用了零宽度断言,表面意思看起来好像是说任意字符+非if+任意字符组成了整个字符串,但是仔细研究匹配过程就知道这个是错的,(?!if)匹配的是一个位置,所以对于字符串aifb他也是可以匹配到的,而实际上这样的字符正是我们不要的。
按照这个正则表达式,对于aifb 首先匹配行首,其次.*是贪婪模式(匹配优先),会一直匹配到字符串的末尾(此时传动装置定位在$位置前面),此时(?!if)需要匹配一个位置,这个位置的后面不能是if,这个时候正好位置在b字符的后面,符合匹配条件,紧接着匹配行尾,到这里整个全局匹配成功。
也就是说对于一个字符串例如我要排除abc这个字串,那么对于任意一个字符串 helloworld abc helloworld 在匹配的时候(?!abc)可以匹配h、e、l、l、o、w、o、r、l、d等这些字符后面的位置,都是成功的。所以匹配根本还没有进行到abc这个地方,(?!abc)就会匹配成功。这个时候根本起不到排除的作用
例如我要匹配行首不是abc的话,那么此时^(?!abc) 这个时候(?!abc)实际上在匹配的时候其传动装置的位置被行首进行了限定,所以对于那些以abc开头的字符串来说就会匹配失败了。
当我要找到不包含某些字符串(如test)时, 可以使用^((?!test).)*$
(5)分组
也叫捕获组。
(exp)表示将exp作为一个整体子表达式。同时按顺序标记它。如(love)(you),love标记为1,you标记为2
非捕获组
(?:exp)表示exp作为一个整体子表达式,但是不标记它。
(...) capture group
(?<name>...) named capture group (Perl)
(?'name'...) named capture group (Perl)
(?P<name>...) named capture group (Python)
(?:...) non-capture group
(?|...) non-capture group; reset group numbers for
capture groups in each alternative
In non-UTF modes, names may contain underscores and ASCII letters
and digits; in UTF modes, any Unicode letters and Unicode decimal
digits are permitted. In both cases, a name must not start with a digit.
(6)回溯引用
\n n 是一个数字,表示第 n 个圆括号括住的子表达式已匹配的子字符串。如(love)(you)\1\2,love被标记为1,you标记为2。那么\1就表示love,\2表示you
\n reference by number (can be ambiguous)
\gn reference by number
\g{n} reference by number
\g+n relative reference by number (PCRE2 extension)
\g-n relative reference by number
\g{+n} relative reference by number (PCRE2 extension)
\g{-n} relative reference by number
\k<name> reference by name (Perl)
\k'name' reference by name (Perl)
\g{name} reference by name (Perl)
\k{name} reference by name (.NET)
(?P=name) reference by name (Python)
(7)选择
exp1|exp2表示匹配exp1或者exp2
| 代表匹配几个选项中的其一,比如:a|bc|cde,匹配有a,bc,cde其一的行
(8)条件
(?(condition)yes-pattern)
(?(condition)yes-pattern|no-pattern)
(?(n) absolute reference condition
(?(+n) relative reference condition
(?(-n) relative reference condition
(?(<name>) named reference condition (Perl)
(?('name') named reference condition (Perl)
(?(name) named reference condition (PCRE2, deprecated)
(?(R) overall recursion condition
(?(Rn) specific numbered group recursion condition
(?(R&name) specific named group recursion condition
(?(DEFINE) define groups for reference
(?(VERSION[>]=n.m) test PCRE2 version
(?(assert) assertion condition
Note the ambiguity of (?(R) and (?(Rn) which might be named reference
conditions or recursion tests. Such a condition is interpreted as a
reference condition if the relevant named group exists.如模式:(0X)?(?(1)[A-F0-9]{6}|\d{6})
(0X)?作为条件,当这个条件满足的时候, 后面的条件将会执行[A-F0-9]{6},而不满足的时候会执行\d{6}。
注意,回溯引用条件中的 (1) 不需要加 \, 即不需要 (\1) 这样。
如模式: \d{5}(?(?=-)-\d{4}), (?=-)
(?=-)作为条件,当查找成功后,会执行-\d{4}表达式
(9)[]中使用的元字符
注意:方括号中的元字符会失去原有含义变为普通字符
但是,下面字符除外:-连字符,但是只有连字符在最后时才作为普通字符使用; \转义字符; ]如果放在第1位才表示普通字符;^不在第1位时才是普通字符。
比如: []1-9^\\-] 表示右括号、数字1到9、尖角号、反斜杠、连字符
- 用在[]中,匹配一个范围如[a-d]代表匹配abcd中任意一个
[^] [^pattern] 代表取反匹配,不匹配pattern的模式,如[^abc]代表除abc之外的其他单字符
(10)元字符的优先级
从高到低:
转义符 \
圆括号 ()
限定符 *+?
定位符 ^$
连接,连接就是两个符号写在一起,如,ab就是a连接b
选择 |
3.修饰符
修饰符也称为标记,正则表达式的标记用于指定额外的匹配策略。
常用的修饰符:
| 修饰符 | 含义 | 描述 |
|---|---|---|
| i | ignore - 不区分大小写 | 将匹配设置为不区分大小写 |
| g | global - 全局匹配 | 查找所有的匹配项。 |
| m | multiline - 多行匹配 | 使边界字符^和$匹配每一行的开头和结尾,记住是多行,而不是整个字符串的开头和结尾 |
| s | 圆点.匹配换行符\n | 默认情况下的圆点.是匹配除换行符\n之外的任何字符,加上s修饰符之后,.中包含换行符\n。 |
(二)posix正则表达式
由电气和电子工程师协会(IEEE)制定的POSIX Extended 10兼容正则
posix正则表达式有两类:
1.基本型正则表达式(Basic Regular Expression,BRE)
2.扩展型正则表达式(Extended Regular Expression,ERE)
这两种正则表达式的区别在于,一些元字符形式不同,以下是这些元字符在不同环境下的形式:
| PCRE | BRE | ERE |
|---|---|---|
| . | . | . |
| [] | [] | [] |
| * | * | * |
| ? | \? | ? |
| + | \+ | + |
| {} | \{\} | {} |
| () | \(\) | () |
| | | \| | | |
| \ | \ | \ |
可以看到,主要的问题就出现在元字符 (, ), +, ?, |, { 和 } 上,其中,ERE 的表现形式和 PCRE 是一致的,而 BRE 的表现形式就略显奇怪。
在兼容POSIX的UNIX系统上,grep和egrep之类的工具都遵循POSIX规范。
grep、vi、sed都属于BRE。
egrep、awk则属于ERE。
posix正则表达式没有分隔符和修饰符,格式为:
pattern
1.转义符
与pcre一样
2.替代符
与pcre一样,除了一点,posix环境中,是不存在诸如 \d, \s 的特殊元字符的,就算有,那也应该是那个工具提供的额外扩展。所以只能使用posix字符类。
3.限定符
与pcre含义一样
除了一点,posix没有非贪婪匹配
4.定位符
与pcre含义一样
除了前后查找
5.分组
与pcre一样
6.引用
与pcre一样
7.选择
与pcre一样
8.[]内的元字符
与pcre一样
三、ascii字符
ASCII 定义了 128 个字符,包括 33 个不可打印的控制字符(non-printing control characters)和 95 个可打印的字符。
分为可打印与不可打印两种:
1.可打印字符95个
[\x20-\x7E] [:print:]
(1)图形字符
[\x21-\x7E] [:graph:]
(2)空格
\x20
2.不可打印字符33个
也叫控制字符
[\x00-\x1F\x7F] [:cntrl:]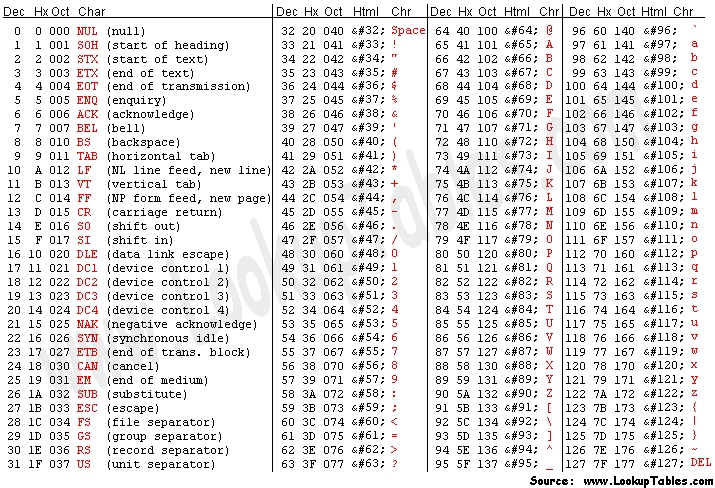
四、正则表达式匹配汉字
提到用正则表达式匹配汉字,很容易搜到这个[\u4e00-\u9fa5],但是它不算全面,不包含一些生僻汉字。
在一个只有汉字和ascii字符的文件中,可以用[^\x00-\x7f]匹配汉字,因为除了ascii就剩汉字了。但是还可能有中文标点,这就难办了
中文标点:
名称 Unicode 符号
间隔号 00B7 ·
连接号 2013 –
破折号 2014 需要输入两个字符 ——
2E3A 只需要输入一个字符 ⸺
单引号 2018 ‘
2019 ’
双引号 201C “
201D ”
省略号 2026 需要输入两个字符 ……
顿号 3001 、
句号 3002 。
单书名号 3008 〈
3009 〉
书名号 300A 《
300B 》
单引号 300C 「
300D 」
引号 300E 『
300F 』
括号 3010 【
3011 】
括号 3014 〔
3015 〕
叹号 FF01 !
括号 FF08 (
FF09 )
逗号 FF0C ,
冒号 FF1A :
分号 FF1B ;
问号 FF1F ?
以下是比较全面的汉字Unicode分布,参考Unicode 10.0标准(2017年6月发布):
| 区块 | 范围 | 实际汉字个数/ 备注 | 正则式 |
| CJK统一汉字 | 4E00-62FF, 6300-77FF, 7800-8CFF, 8D00-9FFF. | 20,971 常见 | [\u4E00-\u9FFF] 或 [一-鿆] |
| CJK统一汉字扩展A区 | 3400-4DBF. | 6,582 罕见 | [\u3400-\u4DBF] |
| CJK统一汉字扩展B区 | 20000-215FF, 21600-230FF, 23100-245FF, 24600-260FF, 26100-275FF, 27600-290FF, 29100-2A6DF. | 42,711 罕见,历史 | [\U00020000-\U0002A6DF] |
| CJK统一汉字扩展C区 | 2A700-2B73F. | 4,149 罕见,历史 | [\U0002A700-\U0002B73F] |
| CJK统一汉字扩展D区 | 2B740–2B81F. | 222 不常见,仍在使用 | [\U0002B740-\U0002B81F] |
| CJK统一汉字扩展E区 | 2B820–2CEAF. | 5,762 罕见,历史 | [\U0002B820-\U0002CEAF] |
| CJK统一汉字扩展F区 | 2CEB0-2EBEF. | 7,473 罕见,历史 | [\U0002CEB0-\U0002EBEF] |
| CJK兼容汉字 | F900–FAFF. | 472 重复、可统一变体、公司定义 | [\uF900-\uFAFF] |
| CJK兼容汉字增补 | 2F800-2FA1F. | 542 可统一变体 | [\U0002F800-\U0002FA1F] |
★ 如果想表示最普遍的汉字,用:
[\u4E00-\u9FFF] 或 [一-鿆]
共有20950个汉字,包括了常用简体字和繁体字,镕等字。
基本就是GBK的所有(21003个)汉字。也包括了BIG5的所有(13053个)繁体汉字。
一般情况下这个就够用了。
说明:
仅仅未包括出现在GBK里的CJK兼容汉字的21个汉字:郎凉秊裏隣兀嗀﨎﨏﨑﨓﨔礼﨟蘒﨡﨣﨤﨧﨨﨩
CJK兼容汉字用于转码处理,日常中是用不到的,所以不包括也没什么问题。
注意此凉非彼凉,兀也不是常用的那个,虽然用眼睛看是一样的,参见 为什么 Unicode 中会存在「凉」和「凉」这样两个极其相像的字符? - 知乎
★ 如果想表示BMP之内的汉字,也就是Unicode值<=0xFFFF之内的所有汉字,用:
[\u4E00-\u9FFF\u3400-\u4DBF\uF900-\uFAFF]
这个包含但不限于GBK定义的汉字,共有28025个汉字。
说明:
和上面相比,主要是多了CJK统一汉字扩展A区,这是1999年收录到Unicode 3.0标准里的6,582个汉字。
CJK统一汉字扩展A区,包括了东亚各地区(陆港台日韩新越)的汉字,有很多康熙字典的繁体字。
★ 如果想尽可能表示所有的汉字,用:
[\u4E00-\u9FFF\u3400-\u4DBF\uF900-\uFAFF\U00020000-\U0002EBEF]
这个包含上表的所有88342个汉字
说明:
1, 以上正则表达式不会匹配(英文、汉字的)标点符号,不会匹配韩国拼音字、日本假名。
2, 会匹配一些日本、韩国独有的汉字。
3, 包含了一些没有汉字的空位置,这通常不碍事。
4, \u及\U的正则语法在Python 3.5上测试通过。
有些正则表达式引擎不认\uFFFF和\UFFFFFFFF这样的语法,可以换成\x{FFFF}试一下;有些不支持BMP之外的范围,这就没办法处理CJK统一汉字扩展B~E区了,如notepad++。















 602
602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









