







JVM的运行的流程:

图一:JVM运行流程
所有的Java程序必须保存在*.java的文件之中,称为源代码。
这些源代码不能直接执行,必须使用javac.exe命令把源代码编译成为*.class文件(编译器)。
使用java.exe命令在JVM进程中解释此程序。
JVM将所需要运行的*.class文件加载到JVM进程中需要有一个类加载器(ClassLoader,系统会提供默认类加载器,我们也可以自己写),类加载器的好处就在于我们可以随意指定*.class文件的位置(包括网络上的)。
Java中可以使用native关键字实现本地C函数的调用,程序运行的辅助手段
真正的程序运行都在“Runtime Data Area (运行时数据区)”中
JVM基本结构
下图是jvm的整体结构,在这里,笔者仅仅简单介绍一下,后面将部分内容会有文章详细介绍。
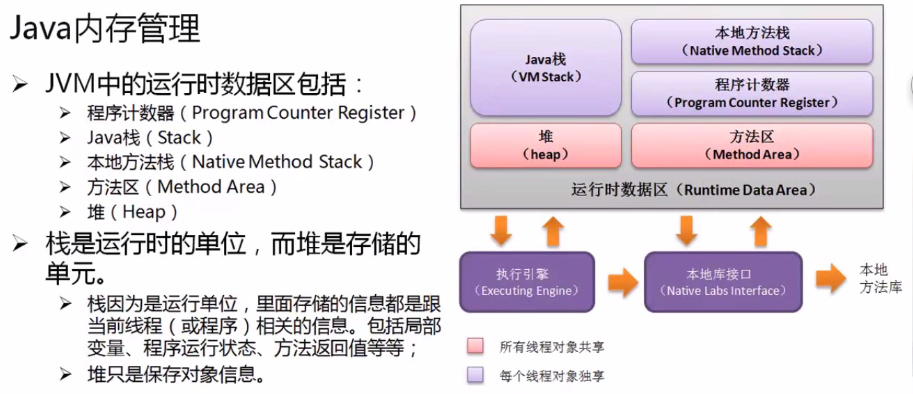
图二:jvm的整体结构
1、PC寄存器
每个线程拥有一个PC寄存器;
每个PC寄存器在所属线程创建时创建;
PC寄存器存储的是该线程下一条指令的地址,就是所谓的PC指针;
当执行本地方法时,PC的值是undefined;
2、方法区
保存装载的类信息,包括(类型的常量池,字段和方法信息,方法字节码等信息)。
3、java堆(后面笔者将详细讲述这一部分)
java堆和开发密切相关,应用系统对象都保存在java堆中;
所有的线程共享java堆中的数据;
对于分代GC而言,堆也是分代的;
GC的主要工作区间就是堆;
4、java栈
java栈是线程私有的;
栈是有一系列的帧组成,因此java栈也被称为帧栈;
帧保存了一个方法的局部变量,操作数栈,常量池指针等信息;
每调用一次方法就创建一个帧,并压栈;
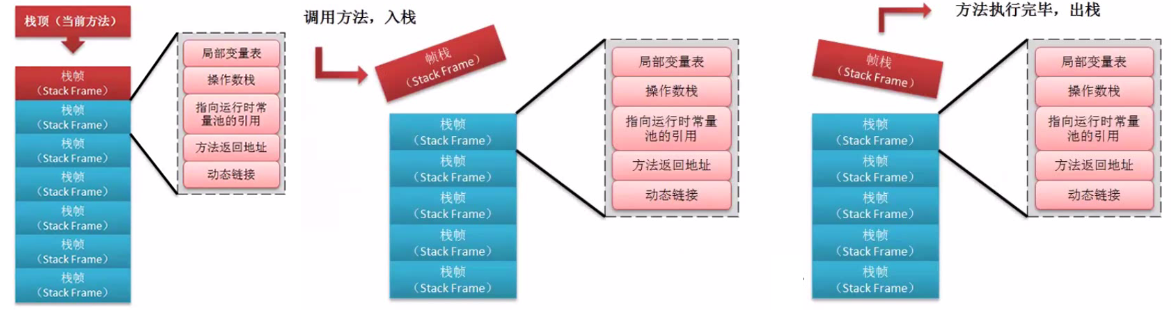
图三:java的栈帧结构
Java中的引用类型数据模型
Java数据的引用类型是最为重要得多数据处理模型,整个的引用数据类型处理之中会牵扯到:堆内存、栈内存、方法区。以下以一个最简单的程序代码为主:“Object object = new Object()”,实例化了一个Object类对象
1) “Object object” 描述是保存在栈内存之中,而保存有堆内存的引用,这个数据会保存在本地变量表中;
2) “new Object()”一个真正的对象,对象保存在堆内存中
直观的思路整个引用的操作:
1、 新定义的对象的名称保存在本地变量表中,在这块区域里面需要确定与之对应的栈内存空间;
2、 通过变量表中的栈地址可以找到堆内存;
3、 利用堆内存的对象进行本地方法的调用(方法区);
对于所有引用数据类型的访问实际存在两种模式:
通过句柄访问(稳定):
引用 —》 对象实例数据指针—》 对象实例数据 —》 对象类型数据指针 —》 对象类型数据

图四:通过句柄访问引用类型
通过直接指针访问(常用)
Java中用的是对象保存的模式,也就是说堆内存里面不在需要保存句柄,而是直接保存具体的对象,省略了句柄到对象的查找过程,这个对象可以直接进行Java的方法区的调用,这就是它的整体操作流程

图五:通过直接指针访问















 386
386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









