







简单的了解了下爬虫的教程,然后自己写了个小程序。
公司使用jira管理各种问题及流程跟踪,我主要负责域名解析这块的,目前想把jira上所有的域名相关的单号给爬出来
由于jira需要登录,因此首先看看登录需要POST的信息:
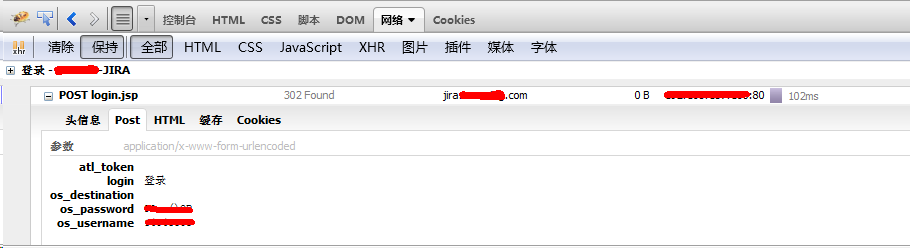
需要POST5个字段信息:
具体代码:
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:jira爬虫
# 版本:0.1
# 作者:Aaron
# 日期:2015-02-06
# 语言:Python 2.7
# 操作:输入 工号和密码
# 功能:输出 jira单号: 报告人工号 - 报告人姓名 报告人部门
#---------------------------------------
import urllib
import urllib2
import cookielib
import re
#需要POST的数据#
postdata=urllib.urlencode({
'os_username':'username',
'os_password':'password',
'atl_token':'',
'login':'登录',
'os_destination':''
})
#初始化一个CookieJar来处理Cookie的信息#
cookie = cookielib.CookieJar()
#创建一个新的opener来使用我们的CookieJar#
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
#自定义一个请求#
req = urllib2.Request(
url = 'http://jira.XXX.com/login.jsp',
data = postdata
)
#访问登陆链接#
result = opener.open(req)
#file = open("DNS.conf" ,"wb")
#访问jira(JIRA-8000到12000)链接#
for i in range(8000,12000):
rsp = opener.open('http://jira.XXX.com/browse/JIRA-' + str(i))
#判断是否能正常访问
if rsp.code == 200:
pageData = rsp.read()
#只匹配包含域名的
isYuming = re.findall('域名',pageData,re.S)
if len(isYuming) != 0:
#判断是不是子任务
refList = re.findall('href="/browse/JIRA-(.*?)"(.*?)id="parent_issue_summary"',pageData,re.S)
if len(refList) != 0:
#如果是子任务,则取父任务的URL
jiraNum = refList[0][0]
pageData = opener.open('http://jira.XXX.com/browse/JIRA-' + jiraNum).read()
#获取报告人工号
Num = re.findall(r'id="issue_summary_reporter_(\d+)"',pageData,re.S)[0]
#获取报告人姓名及部门
Depart = re.findall(r'<span class="aui-avatar aui-avatar-small"><span class="aui-avatar-inner"><img src=".*?" /></span></span>(.*?)</span>',pageData,re.S)[1]
print "JIRA-" + str(i) + ":" + Num + "-" + Depart.strip('\r\n')
#file.close()















 1112
1112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









