






数据工程

> Photo by Robin Pierre on Unsplash
向实时数据流的转变对应用程序的设计方式和数据工程师的工作产生重大影响。与传统的集成和处理方法(即批处理)相比,处理实时数据流带来了范式的转变和复杂性的增加。
利用实时数据确实有好处,但是在设置数据的接收,处理,存储和提供服务时需要特殊的考虑。它带来了特定的操作需求,并改变了数据工程师的工作方式。在考虑进行实时旅行时应考虑这些因素。
利用实时数据的用例
流数据集成是利用流分析的基础。诸如欺诈检测,上下文营销触发,动态定价之类的特定用例都依赖于利用数据馈送或实时数据。如果您不能实时获取数据,那么尝试解决这些用例就没有什么价值。
除了启用新的用例之外,实时数据提取还带来了其他好处,例如减少了数据着陆时间,需要处理依赖项以及其他一些操作方面:
如果您没有实时流式传输系统,则必须处理诸如此类的问题,因此数据每天都会到来。我要把它带到这里。我要在那边添加它。好吧,我该如何调和?如果某些数据延迟了怎么办?我需要联接两个表,但是该表不在这里。因此,也许我会稍等一下,然后再次运行。— a16z上的Ali Ghodsi
实时数据流的基础架构
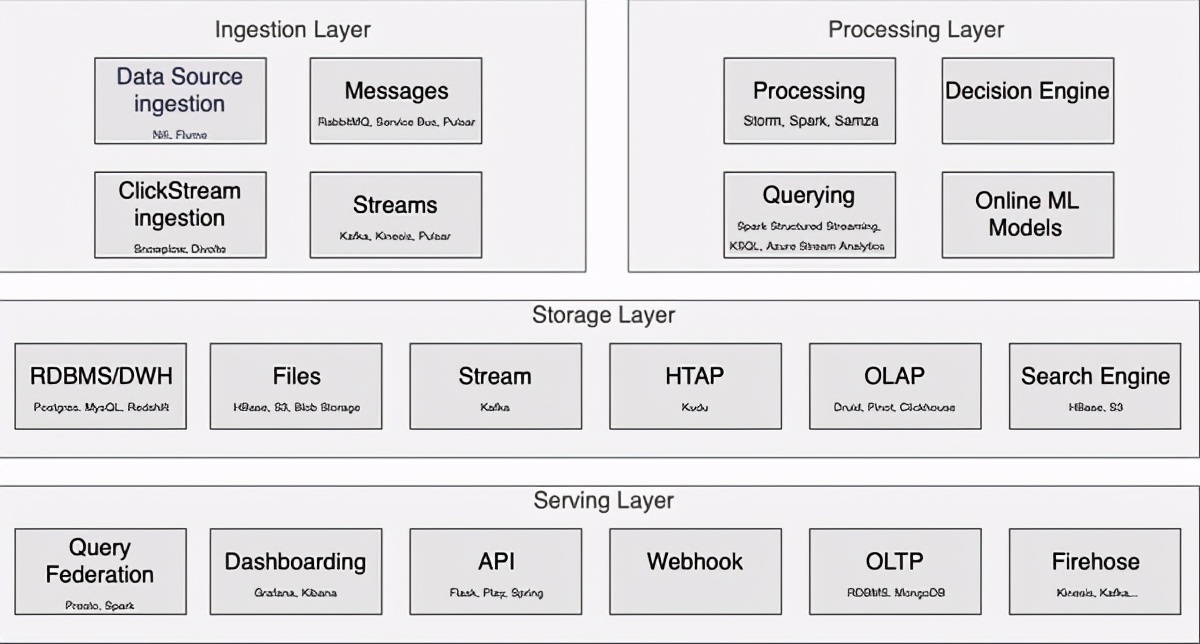
ClickStream摄取:摄取Clickstream数据通常需要使用特定的基础结构组件来促进这一点。Snowplow和Dilvote是两个开源点击流收集器。同时,Google Analytics(分析)360允许将点击流数据原始数据导出到BigQuery,而某些CDP(例如Segment或Tealium)允许捕获点击流数据并将其导出到流或数据库。接收框架:诸如Apache Flumes,Apache Nifi之类的框架提供诸如数据缓冲和反压之类的功能,有助于将数据集成到消息队列/流中。
“当我向人们介绍Nifi时,我通常会说Nifi是获取数据的理想网关。”— Cloudera的高级产品经理Pierre Villard
消息总线/流:消息总线流是用于在实时数据生态系统的不同组件之间传输数据的组件。仅举几例,使用的一些典型技术包括Kafka,Pulsar,Kinesis,Google Pub / Sub,Azure服务总线,Azure事件中心和Rabbit MQ。数据处理:存在不同的处理框架以简化数据流的计算。Apache Beam,Flink,Apache Storm,Spark Streaming等技术可以极大地帮助处理更复杂的数据流。数据流查询:可以使用SQL直接查询流,例如语言类型。Azure事件中心支持Azure流分析,Kafka KSQL,而Spark提供Spark结构化流以查询多种类型的消息流。决策引擎:实时行动需要实时数据以及一种系统地处理此信息的方法。决策引擎有助于使传入的数据流具有可操作性。无状态决策引擎主要有两种类型:无状态决策引擎(例如CLIPS,Easy Rules,Gandalf)和有状态决策引擎(例如Drools)。ML框架+处理:可以在实时架构内利用机器学习模型。他们可以通过计算分数(例如欺诈倾向)来帮助做出更好的决策。存在不同程度的复杂程度的不同类型的框架,例如XGBoost,Tensorflow或Spark MLib。数据存储:根据特定的集成需求,利用实时数据可能需要适合特定目的的数据存储。可能需要特定的OLAP类型的数据库(例如Druid)来对传入数据进行切片和切块分析,可能需要HTAP数据存储区(例如Kudu,Cassandra或Ignite)来处理特定的扩充,在干草堆类型的查询中使用Elastic Search针进行搜索,S3(用于长期存档),RDMBS甚至直接利用流(例如,直接使用Kafka)。查询联合:在如此多样化的数据存储生态系统中,越来越需要具有使用相同界面和工具查询它们的能力。Spark和Presto之类的工具提供了这种类型的查询联合。仪表板:不同类型的仪表板可用于处理实时用例。尽管仍然可以利用Tableau等传统仪表板解决方案,但通常更适合使用Grafana或Kibana等解决方案。摄取资料来源
在实时管道中可以利用不同的数据源。数据可以从外部服务,内部后端应用程序,前端应用程序或数据库中获取-指示可用集成模式的源类型。
外部应用程序:可以通过多种方式将外部应用程序集成到实时管道中。典型的方式依赖于Webhook,创建特定的API使用者或以“ firehose”方式将其直接发布到流/消息队列中。
内部后端应用程序:内部后端应用程序有多种方法可以通过调用API,直接连接到流或利用集成SDK来将事件发布到其他应用程序。
前端:通常通过组合事件提取框架(例如扫雪机),跟踪像素和跟踪脚本来处理来自前端的实时事件。除了允许捕获粒状点击数据之外,这种方法还具有允许某些广告拦截程序绕过的附加好处。
数据库:要从数据库实时获取数据,可以利用数据库bin日志。数据库bin日志包含数据库上发生的所有更改的记录。Bin日志传统上已用于数据库复制,但也可用于更通用的实时数据提取。
基础设施
要从前端接收流数据,需要几个组件:
收集器应用程序,本质上是一个API,用于从前端和希望通过Web服务调用数据的任何后端应用程序接收数据。消息代理,可跨应用程序实时传输数据架构注册表,用于验证传入的事件。一个(通常是前端)SDK以结构化的方式将信息发送到事件收集管道一个跟踪像素,用于跟踪可能(始终)未启用Javascript的活动。
收集器应用程序:有多种方法可以设置流式摄取的基础结构。基本的收集器应用程序可以使用低/无代码类型的工具在大约10分钟内设置(包括模式验证)。例如,可以通过利用开源软件组件(例如Snowplow)获得更广泛的设置。
消息代理:关于消息代理,它们有不同的变体。例如,有些服务器更面向“流”处理,更容易支持事件的重放。Kafka和Kinesis等解决方案就是这种情况;它们特别适合于实时聚合的计算和处理架构模式,例如Kappa Architecture,该架构模式用于直接从历史流数据中获取数据。
处理这类消息代理的主要缺点是它们的“事务性”处理不善,使其不适合处理高价值消息类型的集成。例如,如果您希望集成到CRM系统中,那么知道给定的订单无法推送到目标系统,并且在重试10次后仍然无法达到目标订单将是有益的。更多事务类型的消息代理(例如Service Bus)提供了这类功能,例如事务锁定和死信队列。
处理不同类型的消息还涉及如何配置消息代理。像Kafka这样的消息代理可以提供不同的“传递保证”,以保证消息是否可以至少,最多或仅被处理一次。根据选择的选项,它可能导致事件重复的可能性更高。
对于消息代理,在事务方面不强。如果消息没有得到正确的处理,则需要将它们处理到单独的流中并存储以进行进一步处理,希望消息在事实或“精心策划”之后可以被该进一步的流正确处理,从而增加了开销。
模式验证:关于模式验证,存在各种类型的工具来帮助管理模式并实时启用模式验证,例如iglu,融合模式注册表,例如Kafka与模式注册表直接集成。并提供了一种进行模式验证的内置方法,在这种情况下,验证错误可以直接引发给生产者,以提供有关问题的反馈。其他方法依赖于更异步的验证方式。
SDK:SDK对简化通过实时管道的数据流集成特别有用。在处理前端事件时尤其如此。SDK简化了将事件集成到通用结构中的过程,并基于上下文自动为这些事件提供属性(请考虑属性,例如环境是否是生产环境,与事件关联的userId是什么,IP的IP是什么)。客户端)。这些增强功能中的许多增强功能已经在诸如Google Analytics(分析)之类的SDK中预先构建,但是相当多的数据驱动公司自行开发了自己的功能来支持其数据收集计划。例如,在这种情况下,slack会创建用于处理前端事件数据获取的特定库。
跟踪像素:跟踪像素提供了一种方法,可以将跟踪范围扩展到可能不支持Javascript的站点。例如,在电子邮件客户端中,很少支持Javascript。
值得注意的是,关于在基础架构中包含什么组件的决定很大程度上取决于是否存在直接跟踪前端点击流数据的特定需求,以及是否有利用现有资源获得额外速度的优势生态系统。
例如,如果仅需要从后端应用程序获取数据,则可能不需要事件收集器,SDK或跟踪像素。后端应用程序可以负责验证其前端组件并直接集成到消息主题/流中。大多数消息服务器(例如Kafka)可以处理来自各种应用程序的并发写入。因此,它们可以支持直接从多个应用程序接收消息,而无需集中的“事件收集器”。
当希望从前端获取点击流数据时,诸如Snowplow之类的应用程序提供了已内置的附加功能,例如Geolocation查找,跟踪脚本,像素和DBT之类的应用程序中的插件,以提供对数据的通用处理类型,或者google Analytics(分析)可提供对GA跟踪的简单了解,以提供详尽的网站访问数据。
活动内容
以不同的方式处理不同类型的事件。
最好区分不同类型的事件,包括技术事件,前端事件或后端“业务事件”,或替代数据库更新事件。
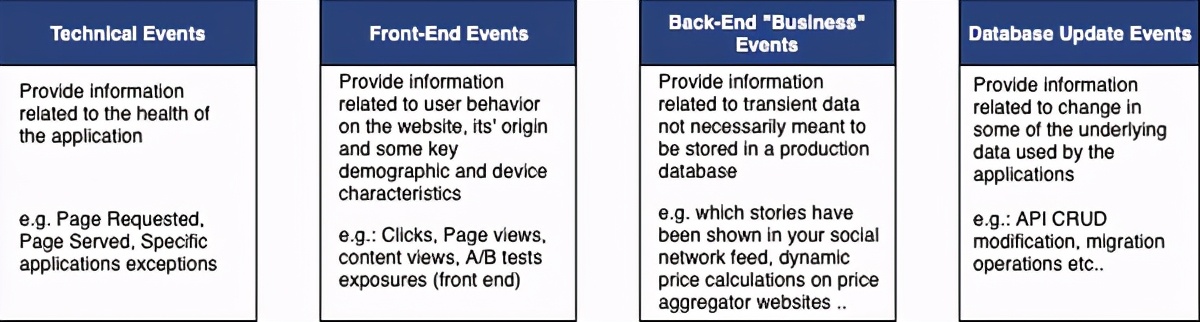
重要的是要提供一种结构,该结构可以轻松地区分这些不同的事件类型,以尽可能地以编程方式处理它们的摄取和更改。
不同类型的事件也需要不同类型的信息。要完全跟踪的数据库事件需要具有与创建和更新日期相关的字段。前端数据可能需要特定的数据(例如UserAgent,IP地址等)进行充实以充分发挥作用(例如,地理位置,设备等)或客户端时间,以便更准确地进行计算。
它们还具有不同的存储需求。技术事件很可能仅需要存储在热存储(例如Elastic Search)和冷存储(例如S3)中,通常只需要将摘要指标公开到“热”存储中。虽然业务事件和数据库实体的更改最经常需要存储在热存储(例如数据仓库)中。
标准化与规划
为了最大程度地减少维护实时数据流所需的工作,重要的是要对模式定义采取几个步骤,并在原始应用程序和使用数据仓库等使用应用程序之间建立数据契约。
在这种情况下,需要特别注意事件结构。设置正确的事件结构可以避免额外的工作,使数据更易于访问并提高总体数据质量。
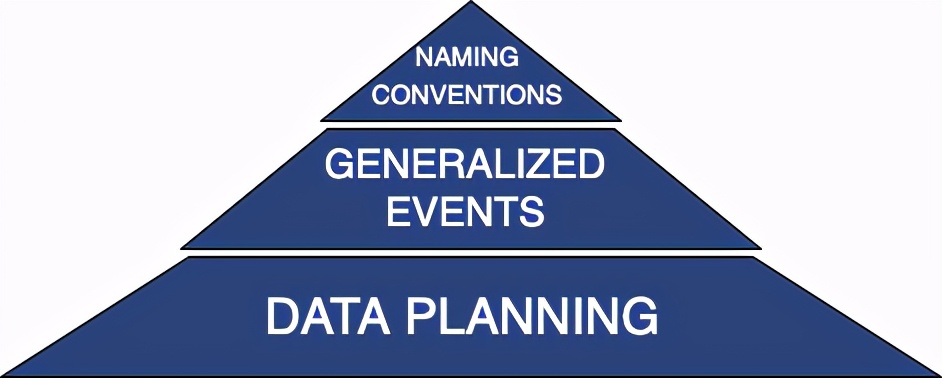
数据计划:这是定义对将要发送的数据的共识的第一步。此步骤可确保要通过发送的数据满足要求。增加的可见性允许正确地创建适当的下游表结构,实施数据质量检查并正确推断所得数据。
在数据计划阶段,了解数据周围的不同业务流程非常重要。这对于提供有关如何处理数据的正确见解是必需的。例如,沃尔玛解释说,这是其准备事件驱动数据的过程的一部分。
构建事件模式:在定义事件的模式,事件的概括性与特殊性,最终将如何处理和访问其中包含的信息,在不影响正在运行的流程的情况下向消息中添加新信息的灵活性等方面,有许多折衷需要处理。,以及消息对未来需求的适应性。
尽管出于完全不同的目的而创建(将结构化数据用于SEO的目的),schema提供的模式通常为提供事件的结构及其属性提供了一个很好的起点。
根据将如何处理数据,应考虑是否在模式中允许深度嵌套的结构,或者是否需要使其扁平化或将其某些关键属性提升为事件的根源。例如,SQL对处理深层嵌套的结构不是特别友好。
在事件模式中提供extra_data属性可以使事件处理某种程度的结构,例如,对于需要在多个源,事件之间通用或需要强力实施的属性。
事件概括:随着数据量及其复杂性的增长,确保通用发送数据以减轻变更对下游的影响非常重要。
通用化使得在无需太多修改的情况下更易于在下游应用扩展或处理,例如从摄取的数据中计算A / B测试实验结果。
它还使直接从原始数据进行分析变得更加容易。想象一下在处理一个名为“ customer_interaction”的事件与包含必须进行交互的事件之间的比较,该事件包含所有渠道交互(渠道进入:电子邮件,电话,SMS,店内…)和交互类型(例如,WELCOME,PURCHASE…)经历10多个事件,例如SMS_WELCOME或STORE_ADVICE。发生特定事件会使分析变得更加困难,并难以确保每种渠道/互动类型都将包含在分析中。
取决于上下文,通常通过设置特定合同(专用架构/ API)或通过将特定实体目标的特定日志记录框架/ SDK合并,来实现这种类型的事件概括。不能低估特定日志框架的重要性。它们提供了启用和执行特定事件结构的起点。
命名约定:命名约定可帮助人们更快,更好地理解数据,并协助事件的下游处理和即席分析。它们适用于事件字段以及这些字段的内容。
以字段utm_campaign为例。字段名称本身表明它与将访问者带到网站的活动有关。它的内容(字符串)也很可能通过命名约定获得。utm_campaign参数(例如
ENNL_FB_Retargeting_Cat_BuyOnline)可以例如指示广告系列的语言(EN),定位国家(NL),定位平台(FB),定位模式(例如,重新定位),以及按受众特征或兴趣定位),投放方式(FB上的目录广告)以及Campaign BuyOnline的类型。
在上面的示例中,这些命名约定使信息比仅包含一个标识符更易于使用,并且不需要将某些元数据表加载到其中即可解释。
事件语法和词汇表:建立事件语法是下一步,使事件数据更易于理解,并提高数据的泛化程度。事件语法描述了不同的交互和不同的实体。活动流标准提供了用于捕获不同事件“动作”的结构和词汇。
技术活动
通常需要吸收和公开技术事件,以便工程团队可以访问适当的日志数据来调试其代码。有时,鉴于集成的类型和应用程序的性质,可能有必要利用历史日志并回顾给定人员或流程在一个月或一年前发生的情况。
处理订阅类型的产品时可能就是这种情况。诸如是否已同意存储付款令牌之类的问题最终没有得到正确保存,现在处理付款失败时可能会出现“到期日期”问题。
一些开发人员主张记录应用程序中发生的所有事情,包括跟踪和唯一序列号,捕获每跳的元信息,例如特定请求花费的时间。
技术事件倾向于被访问,存储或处理的方式通常不需要像业务或数据库变更事件那样需要严格的结构严格性,而是倾向于在事件中搜索特定事件的能力。这些要求应体现在更灵活的模式中,并且需要比业务事件更严格的字段级别验证。
前端数据并绑定到Google Analytics(分析)
在寻求捕获前端事件时,经常会出现一个问题,即如何确保我们可以捕获并访问推送到Google Analytics(分析)的所有原始事件。
有多种方法可以实现这一目标,所有方法都需要在灵活性和集成成本之间进行权衡。根据所采用的方法,从前端利用流式数据摄取可能会重复工作,或者可能导致某些事件没有传播到Data Lake。
Google Analytics 360-提供一种近乎实时地从Google Analytics(分析)导出原始事件数据的方法。Google Analytics 360与Big Query直接集成,可以直接轻松访问数据。这种方法对于哪些数据可以通过此集成传输(例如没有PII)具有与Google Analytics(分析)相同的限制,并且需要Google Analytics 360套件的前期费用(每年约15万美元)。Google Analytics(分析)自定义任务:存在可能的集成模式,例如为Google Analytics(分析)创建自定义任务,以向数据添加其他接收者,从而可以连接到Google Analytics(分析),但在提供其他属性发送到后端和将跟踪脚本置于与Google Analytics(分析)相同的同意限制。此外,Google Analytics(分析)跟踪脚本经常被多个广告拦截器拦截,从而覆盖不良事件。类似于标记管理工具:使用标记管理工具,自定义跟踪脚本以及利用与Google Analytics(分析)相同的数据层等中间方法,在属性选择以及如何处理GDPR同意限制方面提供了更大的灵活性,但要在标记管理器中添加配置。当利用特定的客户数据平台(例如细分)时,也可以在服务器端采用类似的方法,该平台允许路由特定的数据(例如Google Analytics(分析)和数据库)。特定集成:创建单独的集成可提供所有功能中的最大灵活性,可降低跟踪数据被adblocker阻止的可能性,但以增加集成工作为代价。
业务后端活动
对于“业务”后端事件,即特定的“事实”事件,在处理事件时利用某种类型的标准化很重要。在集成特定类型的数据流时,利用通用的统一或规范模型有助于确保每种事件类型的永久集成数据流。
例如,一个电子商务网站可能对特定事件感兴趣,例如已购买的订单,已发货的订单/项目。这些事件可以在一定程度上通过这些规范模型的不同解决方案进行标准化。此标准化也适用于为每个事件提供的最小属性集,例如特定的商店ID。
在推送这些类型并需要跨时间关联它们时,通常需要提供其他类型的信息,尤其是在处理分布式应用程序上下文时。
重要的是要确保不要依赖于由应用程序/事件处理管道生成的created_at时间戳,而是依赖于会话/动作和序列号。依赖created_at时间戳可能会导致错误地假设在分布式上下文中排序。直接依赖于create_at时间戳的影响高度依赖于1)应用程序的数据速度,2)总体接收速度,3)技术基础架构设置-例如,是否已为基础架构配置了会话亲和力。
数据库变更事件
事件的数据库更改类型应以事件编程CDC类型的方式提供。将事件编程方法用于CDC而不是直接利用bin日志(典型的CDC)有几个原因:
将操作数据存储的实现与数据流分离。提供我们可能不想/不需要存储在运营数据存储中的其他信息。
在这种方法中,基础数据库实体更改最终通过事件操作(例如“创建”,“更新”,“删除”)反映在数据平台中。因此,应在不同的事件名称,数据库目标实体和所应用的更改类型之间进行分隔。
应一致地提供对数据库执行更新的方式,即,作为事件传播的字段应仅包含更改的字段或实体的整体视图(最后快照),或明确区分应如何处理它们。
日志记录框架/ SDK应该强制包含某些数据字段,例如源自数据库实体的“创建”和“更新”时间戳。
具有一致的操作集以及这些不同的时间戳和集成方式,可以将源自不同域的更改传播和集成回数据平台。
控制结构
需要某种程度的控制和检查-数据操作以利用事件并确保体面的数据质量水平。
结束2结束测试
在利用实时摄取时,至关重要的是要采取正确的防护措施,以免在馈入数据平台的数据上出现退化。应该执行涵盖从原始应用程序到数据存储的数据生产过程的端到端测试,以保护最终在数据平台中的数据质量。
验证,数据质量检查和数据监视
处理通过事件推送的数据需要适当的验证。模式和属性应经过验证。可以通过本机消息代理功能(例如,Kafka)或通过特定的应用程序(例如,Snowplow)来验证模式;验证属性是一件更复杂的事情。
我们需要区分静态属性验证,可以将其包含在诸如AVRO / JSON或Protobuf之类的架构中以进行验证。更多动态类型的属性完全需要另一种形式的验证。
在很大程度上,在动态验证中,验证数据的大部分责任应在原始应用程序上。但是,应该在接收端(即数据平台)上建立一个过程,以确保它符合期望。
为确保数据平台可以执行自己的验证过程,重要的是要有特定而非通用的定义或要发送的不同事件,例如,以确保该字段真正对应于其内容(例如,order_id最终出现在cart_id字段中)。
数据验证和监视不仅止于模式和属性验证。应该执行自动检查以识别是否在X天之内未发送某些属性,或者不同事件之间的参照完整性。回归会在代码中发生,并且建立适当的控制结构有助于最大程度地减少影响,或者可能未正确传达或处理应用程序中的更改。
在处理事件类型的源时,验证和检查应在多层中进行:
在原始来源处:确保接收到的数据符合预期值和/或业务逻辑在摄取时:确保该模式是预期的,并且该数据平台未收到意外事件。以及引用后:检查诸如引用完整性之类的事情,因为这些假设最终会在数据传输期间放宽,或者进行生命周期检查,以确保针对给定的一系列操作接收到所有事件。处理中实时处理
流/消息充实
通常需要丰富流以提供旨在实时使用的其他数据。他们可以在其他服务,数据库上进行查找,可以进行第一阶段的ETL转换,也可以在流中添加机器学习分数。
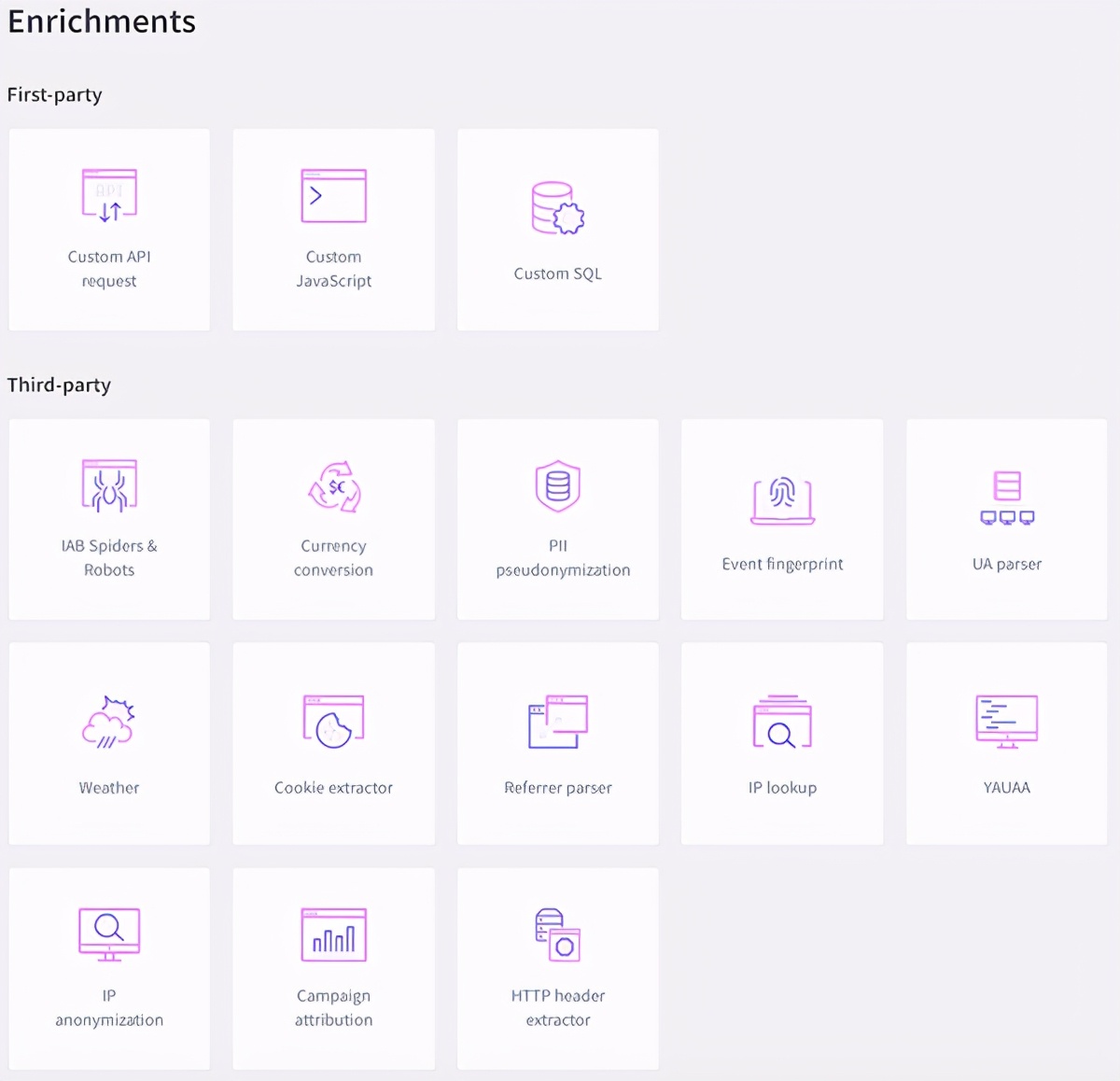
> List of Enrichments available for Snowplow
消息的丰富通常通过生产者/消费者或发布者/订户类型的模式发生。

这些丰富的应用程序可以用任何语言进行编码,并且通常不需要特定的框架来进行此类丰富。尽管存在专用框架和工具,例如Spark Streaming,Flink或Storm,但在大多数情况下,普通服务应用程序将能够在没有开销,复杂性或流计算框架特定专业知识的情况下充分执行。
有状态的浓缩和清理
可能需要在下游使用状态丰富和数据清理。
有状态充实:事件驱动的应用程序可能需要使用包含以历史数据(即状态)充实的数据的数据。如果您在过去24小时内至少有3次没有订购该网站,那么就想想一个潜在的触发因素,可以为您提供购买产品的折扣。最终将决定是否向您提供折扣的下游应用程序将需要知道您当前正在访问该网站(实时事件),访问历史(24小时内访问X次)以及您的订单历史记录(已订购)在过去24小时内),以决定是否提供折扣。
有状态清理:在尝试使用来自多个来源的客户数据以在想要利用客户的360度视图的CRM系统中使用的情况下,例如,利用上下文营销触发器:
“数字业务的成功在于与每次互动的客户相关。相关性是上下文相关的。因此,我们从实时性的基本要求入手,并且能够响应客户时间轴而非营销活动时间轴中的事件。这就是为什么必须将Customer 360黄金记录制作成客户影片(每个唯一客户的时间线事件),并使其成为事件驱动的数据体系结构的核心” – Lourdes Arulselvan,Grandvision数据架构负责人,前产品经理决策Pegasystems
在这种特定情况下,可能需要先对客户数据进行一些初始合并和统一,然后再将其输入下游应用程序。之后,可以在离线/批处理中传播更广泛的处理,传播不同应用程序的更改。
有状态重复数据删除:某些消息代理至少提供一次传递选项,这就需要对事件进行重复数据删除。根据所选的特定选项,某些解决方案(例如Azure Service Bus)提供本机消息重复数据删除选项,而其他解决方案则可能需要外部有状态重复数据删除。
集合体
在数据流上执行聚合有两个主要用例。
例如,通过仪表板提供最新的实时分析数据。加快非常大的数据集的下游计算(通常是批处理)的速度。
这些操作通常可以通过可执行时间窗口聚合的应用程序spark(请参见spark结构化流)或Presto处理。
规则引擎,复杂事件处理和触发器
规则引擎,复杂事件处理(CEP)和实时触发器可帮助将收集的数据转换为运营情报。
规则引擎有不同的类型。CLIPS,Pyke,Pyknow和Drools只是可用的一些不同的开源规则引擎。规则引擎具有不同的风格,并支持不同的标准和语言。有些是无国籍的;有些是有状态的;他们可以支持OSP5,Yasp,CLIPS,JESS之类的规则语言,或者它们自己的语言结构和标准(如RuleML或DMN)。
利用DMN标准的业务规则管理系统可以从大量的编辑器中受益,这些编辑器允许以DMN格式对决策逻辑进行建模,可视化和导出,而无需为其实现编写代码。因此,在执行复杂的事件触发逻辑时,允许与分析人员和业务部门加强协作。DMN格式的缺点是它依赖于无状态计算。
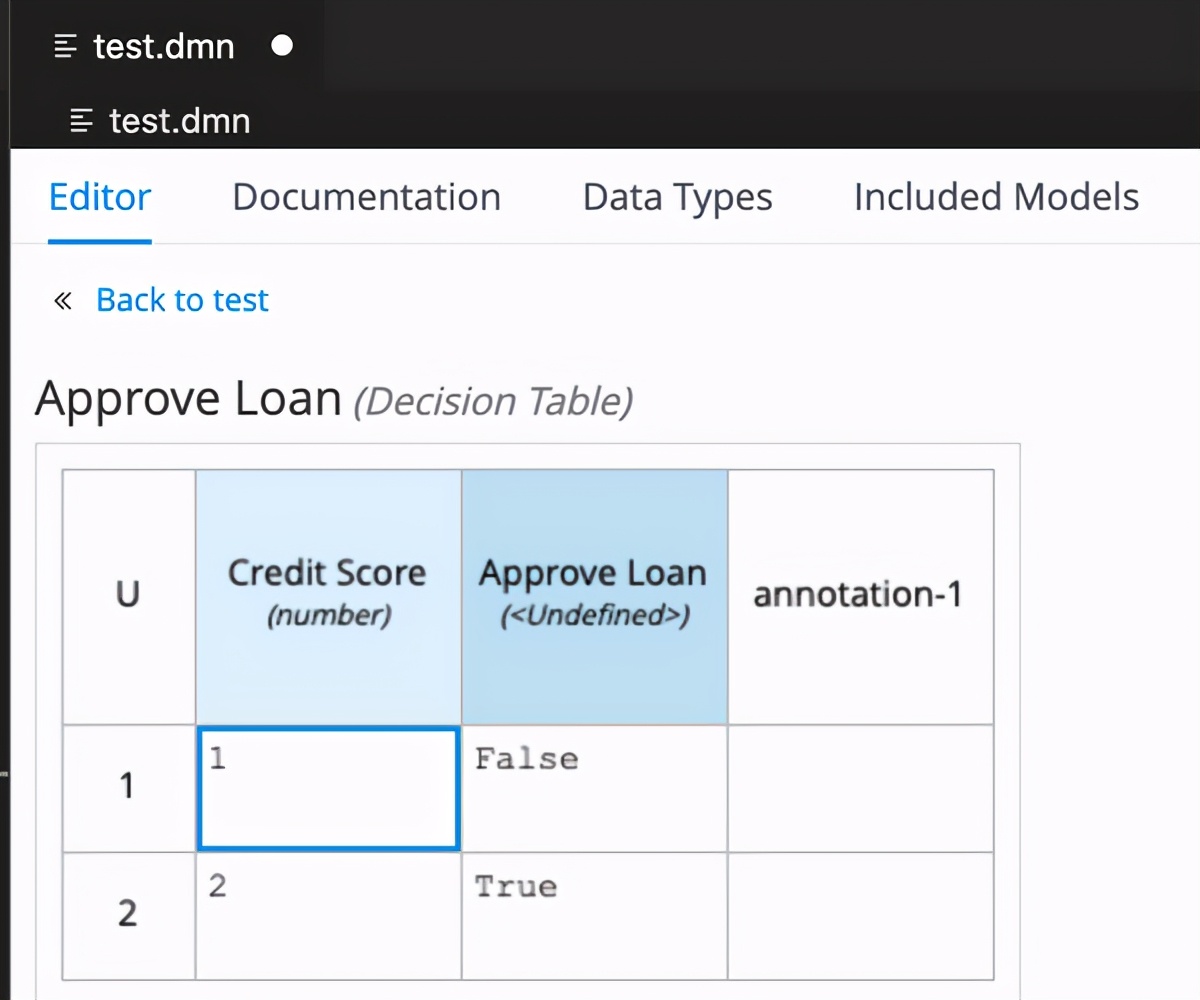
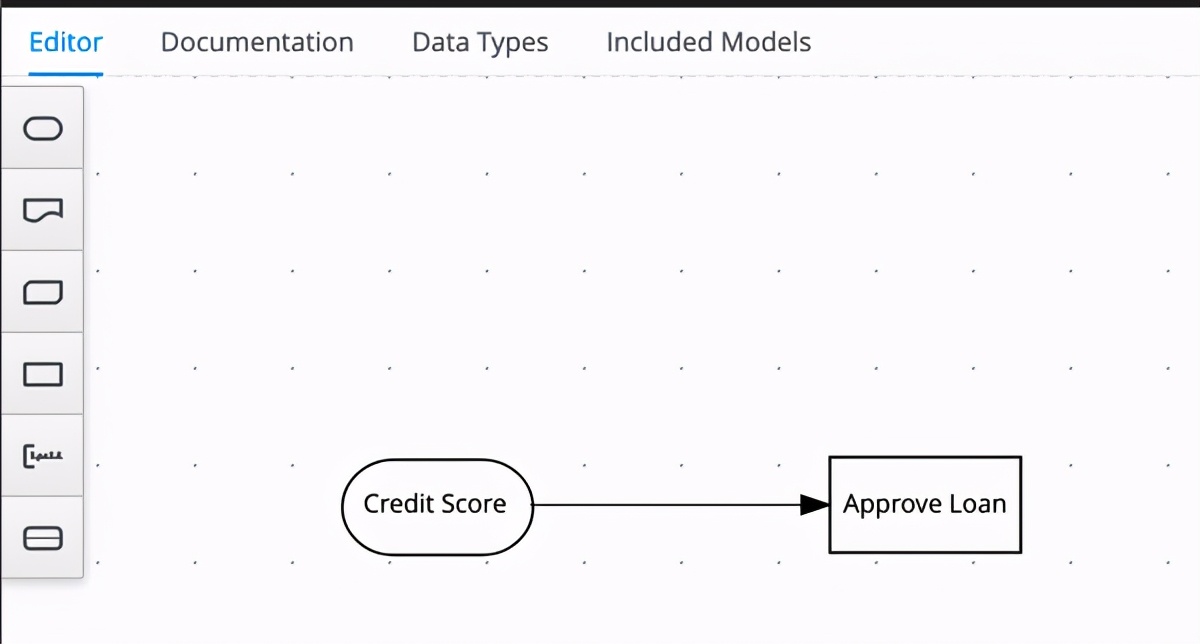
> Example of a simple decision implemented using Redhat DMN editor extension for VSStudio Code
有两种主要类型的技术可帮助支持此类技术,即决策引擎/业务规则管理系统,它们结合了构建决策逻辑并直接利用状态流处理应用程序(如Apache Flink或Storm)。
一些决策引擎,例如Drools,可以合并状态决策并处理CEP的要求。Drools利用其.drl格式而不是DMN格式来支持有状态竞争。
Flink或Storm等框架允许对特定的应用程序逻辑进行编码以生成决策。例如,Flink提供了欺诈检测的示例,该示例根据触发异常的不同规则生成不同的警报。
实时机器学习
对数据进行的另一种处理类型是机器学习。可以使用特定的“在线学习者”来训练机器学习模型,也可以根据传入的数据生成预测。
储存与服务
实时数据在存储和服务收集的数据和过程数据方面带来了不同的挑战。数据倾向于具有不同的访问模式,延迟或一致性要求,从而影响数据的存储和服务方式。
接收器 Sink
接收器通常与数据管道的最后阶段有关,在该阶段中,数据被导出到目标系统。如果需要将数据从同一数据源导出到不同的系统,则给定的数据流可以具有多个接收器。这在实时数据中非常典型,在这种情况下,适合目标集成的情况很普遍。
储存层
为了正确处理实时处理引起的各种需求,拥有合适的系统来处理工作负载类型和数据访问模式非常重要。根据数据的使用方式和数据的量/速度,可能会使用OLAP,OLTP,HTAP或搜索引擎系统来补充数据平台。
对于仪表板/聚合类型的用例,OLAP类型的数据库提供的延迟比典型的数据湖/数据仓库组件低。Facebook之前描述了他们如何使用内部数据库Scuba来支持查询深入研究和实时仪表板聚合,以用于性能监控,趋势分析和模式挖掘等用例。Netflix讨论了他们对Druid(一种开放源OLAP数据库)的使用,以增强其实时洞察力。其他著名的开源替代方案是Clickhouse和Pinot。
用于在线事务处理的OLTP是一种数据库类型,通常会被用作核心生产系统的一部分。与OLAP数据库相比,OLTP数据库可处理相对简单的查询,并能很好地处理读写操作。适用于此类别的典型数据库类型是典型的关系数据库(RDBMS)或NoSQL数据库,例如MongoDB或DynamoDB。
用于混合事务处理/分析处理的HTAP提供了处理OLTP和OLAP类型的工作负载的能力。Apache Kudu的目标是“对快速数据启用快速分析”,是该类别中的开源引擎之一。
诸如Elastic search之类的搜索引擎可以与诸如Grafana或Kibana之类的仪表板解决方案集成在一起,以进行实时分析,但是在执行特定的搜索分析时会获得真正的价值,从而大大减少了查询的等待时间。
数据仓库:有两种用于处理实时数据的主要架构,即lambda和kappa架构。当想要利用实时事件的好处和批处理保证的一致性时,在利用lambda架构时需要更高的复杂性。lambda体系结构要求批处理和实时“速度”层的代码部分重复。另一种架构是Kappa的架构,它没有提供如此高的一致性保证。尽管如此,它提供了更简单的计算。当前(即实时)和历史数据都来自同一事件流。
数据湖/仓库
过渡层
在数据仓库的暂存层中提取数据时,在构造事件数据时会考虑不同的方法。
存在不同的方法,每种方法提供不同级别的特异性和统一性。三种主要方法是:1)针对收集的每种类型的事件使用特定的表2)利用通用结构,但JSON字段中的特定属性(例如额外数据方法3)利用嵌套结构存储特定数据。
应根据您的具体情况平衡采用哪种方法的决定;不同事件之间如何相互关联,如何将它们集成到数据仓库中以及预先完成的处理和统一级别,通常如何访问和使用它们……
数据质量层
属性查询/键
有必要在登台结构内创建公共查找表,以确保适当的数据质量。有很多原因可能需要通过这些查找表来丰富事件/消息:
更改架构,架构可能会在不同的应用程序版本之间发生巨大变化—通常需要进行某种架构统一以补充某些架构版本中缺少的信息。数据质量问题来自代码的回归。由于代码中的回归,可以停止向下游提供数据,并且需要执行适当的数据质量增强(在可能的情况下补充这些回归)。数据的后验富集(例如,在购买后将cart_id映射到order_id),并不是我们想要利用的所有数据都在生成时出现,并且接收到的事件/消息仅包含的不可变表示他们生成时的数据。有必要对后验数据进行补充,以提供必要的查找关键字,以获取数据仓库内的其他信息。
领域含义的变化
事件字段中属性的含义可能会随时间变化。
在某些字段中,可能需要对数据进行额外的后处理,以正确隔离不同的字段变化。考虑一下一个order_id字段,该字段曾经包含来自ERP系统的order_id作为直接与其集成的前端,而该字段开始代表网上商店的order_id。在收集到的事件中,两个order_id可能表示在相同的order_id字段中,但根据时间戳(当时发生的更改)或数据类型可以解析为erp_order_id和shop_order_id。例如,一个可以是INT,另一个可以是GUID。
除了根据字段的不同含义将字段划分为不同的字段外,有时还需要根据新的分类重新映射以前收到的事件(例如,客户服务工具以前包含12个类别,现在只有6个类别)。
分析层
在数据湖/仓库的分析层中,重要的是适当地重组事件并从事件中重建DIM,HDIM和FCT表,而不是直接利用它们。这样做为事件的技术实现提供了一个接口,该接口可能会随着时间的流逝而发生变化,并使数据仓库的不同用户更容易使用。
总体而言,当尝试使用事件数据构建分析层时,需要考虑多个因素:
本质上,不同事件中的属性倾向于被规范化,并且值倾向于浮出水面而不是标识符。这非常适合用于实时处理用例,但是当需要维护数据的历史视图时,通常需要利用某种形式的规范化。参考数据和主数据应与事件中包含的其余信息分开处理。最好的方法通常会同时包含属性值和标识符。这样可以确保数据流对于实时和长期使用案例均有用。
本质上,不同事件中的属性倾向于被规范化,并且值倾向于浮出水面而不是标识符。这非常适合用于实时处理用例,但是当需要维护数据的历史视图时,通常需要利用某种形式的规范化。在这种情况下,确保在传播事件时为事件提供属性值和标识符,以确保数据流对于实时和长期使用情况有用。
从事件数据构建分析层时需要考虑的另一个方面是记录或属性“幸存者”。需要定义“黄金”记录中将代表哪些值。
服务层
集成实时数据有多种方法。最典型的是通过仪表板,查询接口,API,Webhook,Firehose或Pub / Sub,并直接集成到OLTP数据库中。数据将通过的特定方法将在很大程度上取决于预期用例的性质。
例如,当需要集成到生产应用程序时,可以使用不同的选项,提供API,通过webhook,firehose或pub / sub机制发布事件;或者直接集成到OLTP数据库中。
另一方面,分析人员可能会找到仪表板或查询界面工具。
操作上的考虑
在考虑建立实时事件处理系统时,有一些具体的操作考虑因素;它需要24/7基础架构监视和维护,而批处理过程可能不需要任何特定的SLA。
当需要根据传入数据量或节流摄取或处理需求进行弹性扩展时,对操作支持的需求更加突出。这些类型的考虑在很大程度上取决于在数据平台方面和核心/产品平台上选择的特定基础结构和体系结构,以及所需的提取/处理速度。
在处理数据重放(例如,源处更改的数据),处理对帐流程(例如,调用API)时,利用实时管道还会导致更高的操作负担,对未经验证,丰富或集成的数据进行重新处理正确地。
数据工程师需要适应这种二分法,并根据所使用的转换类型和建模方法,为数据的事件日志及其不可变的属性构建适当的数据结构。如果粒度/关系的变化率很高,那么像Kimball这样的建模方法通常非常适合此类数据,而当处理具有高变化率的不可变日志数据时,数据仓库方法可以证明是合适的。
处理不可变的数据会增加数据工程师进行某些类型的转换的复杂性,同时又提供了更准确,更易于访问的历史记录。例如,可以通过在事件日志数据之上应用分析转换来轻松构造此类数据的历史化,而在更传统的数据仓库中,则需要对数据进行快照。同时,可能需要从一组“创建”或“更新”事件中重新创建维度1的表。这可以通过数据库摘录直接访问,而无需执行任何转换。
实时管道环境下的数据工程团队的工作
利用实时提取和管道,数据工程师需要对实践进行一些适当的调整。当应用于事件日志而不是更传统的数据工程类型时,他们的工作的不同方面会发生变化。
实时的整体推送架构减少了数据工程团队处理提取特定数据集的需求,例如,调用API,使用依赖项管理来设置CRON作业等。。。对不可变数据提要进行转换,解析和结构化非结构化或半结构化数据,并通过重构表支持基础数据更改。
通过事件和实时管道处理不可变的数据馈送,将额外的责任重新架构更改应用于数据平台(如果处理CDC之类的东西,无论是直接的CDC还是程序性的),都可以将这些更改反映到将目标数据库作为自动化过程。
利用实时数据管道还具有将清理数据的责任推到更靠近源头的作用,而不是依赖数据仓库/数据湖作为事后清理的地方。实时清除数据的机会有限,并且对某些用例(例如实时分析仪表板和从这些数据流中馈送的其他应用程序(例如CRM应用程序)必须具有干净的数据才能正常工作)的需求推动了责任做一些初始数据清理工作,可以使这些用例更强大。
您应该实施实时管道吗?
有许多原因使您可能不想立即投资建立实时管道,这是因为它依赖于遗留系统,无法实时推送数据,没有一支具备正确技能的团队来真正采用实时的优势,或者尚未拥有合适的用例或系统,以真正利用实时数据的馈送。
首先,走向实时数据流是成熟性的问题。实时数据变得越来越重要。如果愿意在一天之内冒险使用需要实时处理和集成的用例,则为接收和处理这种类型的数据建立正确的基础是至关重要的。如果没有建立正确的基础,可能会导致很高的重新平台和重新集成需求,最终导致延迟和额外成本,有时使某些用例在财务上不可行。
但是,在某些情况下,进行实时数据之旅可能没有意义。如果您已经拥有一个完善的批处理平台,并且不打算解决任何需要真正的上下文或实时集成的用例,那么与采用真实的数据库相比,可以以最小的成本获得更新的数据。时间管道。在某些情况下,通过微型批处理或微型批处理加快提取和处理速度可以带来显著效果,而无需大量更改代码,基础结构或流程。
实时数据走向何方?
事件驱动的微服务和事件源的重要性日益提高,这使得实时数据流处于中心位置。
有些人已经在倡导面向流的数据库,共享实时流处理器和数据库的好处。这些,再加上SQL框架(例如Puma,KSQL或Spark结构化流),将继续使实时数据更加可访问。
我提供的有关Hacking Analytics的更多信息:
数据工程的发展之一将机器学习(ML)模型投入生产的不同方法概述学习SQL并掌握以成为数据工程师的途径大数据工程中的效率概念概述有抱负的初级数据工程师的5个技巧















 4046
4046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









