







希望转载的时候注上本文链接,尊重原文作者。谢谢~http://blog.csdn.net/u010858238/article/details/9029653
说起来很奇怪,为什么超级课程表火了这么久,关于原理的帖子就从来没出现过。这是我第一次在CSDN写博客,以前都写在自己的网站上了,希望大家能够支持我谢谢。
由于我是长沙理工大学的大二在校生,所以我接下来的演示都是基于长沙理工大学的教务平台来写的,其实大家看懂后,就不会区别于学校了,因为原理都一样。然后我使用android平台进行演示,还是那句话,原理都一样,语言自选。
首先需要准备的工具是HttpWatch,这是抓包需要的工具,然后还有一个jar包,叫Jsoup,这是用来解析网页HTML代码的。其次所以要的类是HttpClient、HttpPost、HttpGet。
先来看看最后的效果图,我实现了获取教务平台的考试成绩和考试座位安排的数据,课程表数据一样的原理获取。

关于android的基本知识及我所用的相应组件就不介绍了,直接开始正文了。
一、使用HttpWatch抓取教务平台的数据。
安装好HttpWatch后,打开IE浏览器,打开HttpWatch,先别点记录,因为还没有进入教务平台网站的。 = =
这是我学校的教务平台网站地址 http://210.43.188.41/ ,进入后,选择用户登录。好的,此时点击HttpWatch上的记录。

然后输入学号密码, = = 这里我就打上马赛克了,如果开发者真的需要用我学校的教务平台来进行学习,我愿意给你我的学号密码,不过请私下联系我 。
。
输入学号密码后点击登录,等网页完全加载完毕后点击记录边上的取消,这个时候就要对抓下来的数据进行分析了。接下来的演示可能有点傻瓜制 = = 希望秒懂的人谅解一下像我这样的新手。
大家可以看到HttpWatch有上下两块界面,首先看到上面的界面,找到“方法”为Post的那行数据,单击,就可以看到下面的界面出现了相应的内容。首先我们打开POST数据。
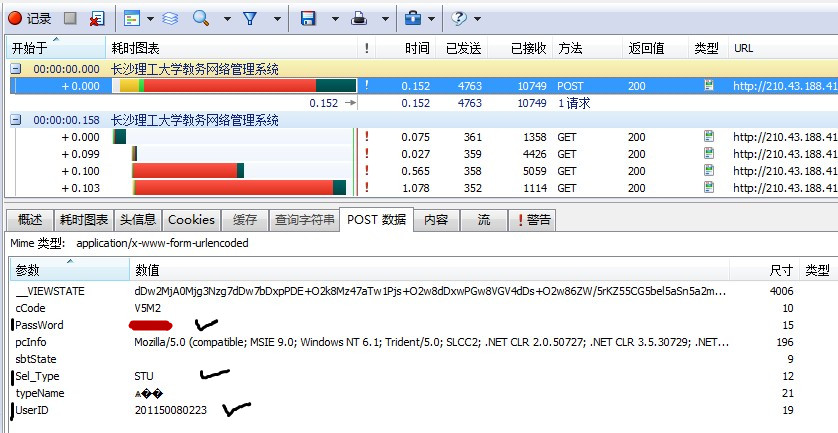
大家可以看到有很多参数和数值,但是!!除了我打钩的这三个参数外,其余的参数对于我们开发客户端而言形同虚设。大家可能会问了,在之前那个登陆页面中,明明有验证码需要输入的啊,但为什么在POST数据中,连cCode(验证码)这个参数都形同虚设呢?关于这个问题,我问了很多人,可是最终得到的结果是。。。。应该是这个教务平台的BUG = = 所以大家先别介意没有输入验证码,我跟大家保证,我们不需要输入验证码,也可以登录!!!!
好的,在分析完POST数据后,我们点击另一个选项卡,“头信息”。
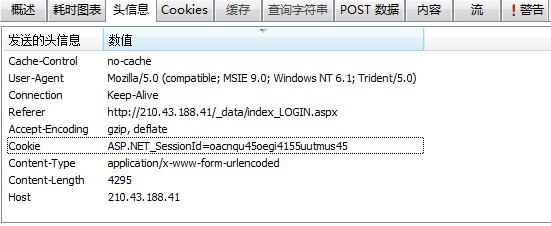
同样,在众多发送的头信息中,我们所需要的只是Cookie,Cookie是什么?从本质上讲,他可以看成你的身份证,也就是说你在接下来的网页操作中,Cookie可以证明操作对象是你而不是别人。好的,关于其余参数的作用,如果你对抓包很有兴趣的话可以继续深究,但是对我们现在做客户端已经无用了~
对了,其实还有一个参数还是相当重要的,那就是在HttpWatch中上方的那个页面中有一列叫做URL,这个就是我们Post或者Get的直接网址,一定要注意!!不然你Post的时候没有Post到相对应的网站就等于白Post了 = =
第一步基本就已经完成了,就是关于使用HttpWatch抓包和分析数据的事基本就已经搞定了~(不过这只是第一个抓包内容,之后还需要抓包的,就是抓成绩或者课表的页面)。
二、将抓下来的数据运用在代码中
- List<Cookie> cookies; //保存获取的cookie
- HttpClient client = new DefaultHttpClient();
- HttpResponse httpResponse;
- String uriAPI = "http://210.43.188.41/_data/index_LOGIN.aspx";
- /* 建立HTTP Post连线 */
- HttpPost httpRequest = new HttpPost(uriAPI);
- List<NameValuePair> params = new ArrayList<NameValuePair>();
- /**
- * 以下三个数据就是我们的之前在POST里的数据,不用在意验证码
- */
- params.add(new BasicNameValuePair("PassWord", "*****"); //这里的密码我用*取代了
- params.add(new BasicNameValuePair("UserID", "201150080223"); //这是学号
- params.add(new BasicNameValuePair("Sel_Type", "STU")); //以学生身份登录
- try {
- // 发出HTTP request
- httpRequest.setEntity(new UrlEncodedFormEntity(params, HTTP.UTF_8));
- // 取得HTTP response
- httpResponse = client.execute(httpRequest); //执行
- // 若状态码为200 ok
- if (httpResponse.getStatusLine().getStatusCode() == 200) { //返回值正常
- // 获取返回的cookie
- cookies = ((AbstractHttpClient) client).getCookieStore().getCookies();
- } else {
- }
- } catch (Exception e) {
- e.printStackTrace();
- }
上面的代码应该还是比较易懂的,关于部分不熟悉的类请大家自行阅读API文档哈。
第二步的目的一是将三个数据(学号、密码、登陆身份)Post到教务网站上,另一个是获取到登陆成功后的cookie。
三、继续抓包,不过这次是非常有针对性的抓包
之前已经提到了,我们之所以在登陆页面进行了第一次抓包操作,完全只是为了登陆成功并且获取成功后的cookie,这样,我们才能带着cookie继续访问我们接下来想要访问的东西。下面我以成绩为例子演示,课程表也是一样的!!
在教务平台上找到成绩查询界面并进入。
同样,先别记录,你这时可以清除一下你之前抓下的数据 (= = 当然,如果你觉得不妨碍你分析抓下来的数据,你也可以不清除)。清除后,点击HttpWatch的记录,然后检索,这时HttpWatch上又会出现很多很多数据。我们继续分析。
同样的,按照第一次抓包的方法,我们先找到POST数据的选项卡。
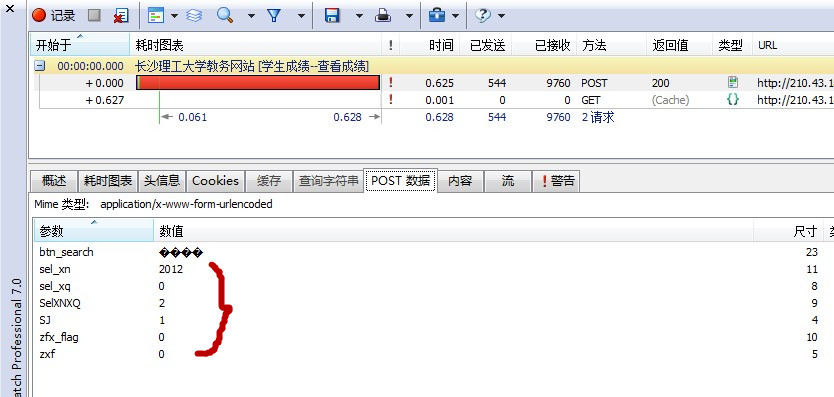
这些就是我们刚才Post的数据,反正这些数据我们大体上能理解,比如说sel_xn就是select的学年的意思,sel_xq就是学期,按道理来说这个数据我们都应该在代码里Post的,但是经过我自己的尝试,第一个参数btn_search可以不用post,这个估计就是我们点击“检索”那下所产生的效果。好的,这个时候你可以去看看“头信息”里的cookie,你会发现这个cookie和我们之前的那个cookie是一样的 = = 这是当然的,因为这样才能说明从刚开始到现在一直是同一个对象在操作。
第三步的作用很明显,就是为了POST一些数据到我们想要查询的网页上。
慢着,这里一个非常非常非常重要的东西没有讲到!第三步其实还有一个作用的,那就是!!!!!大家点击“POST数据”边上的那个“内容”选项卡。
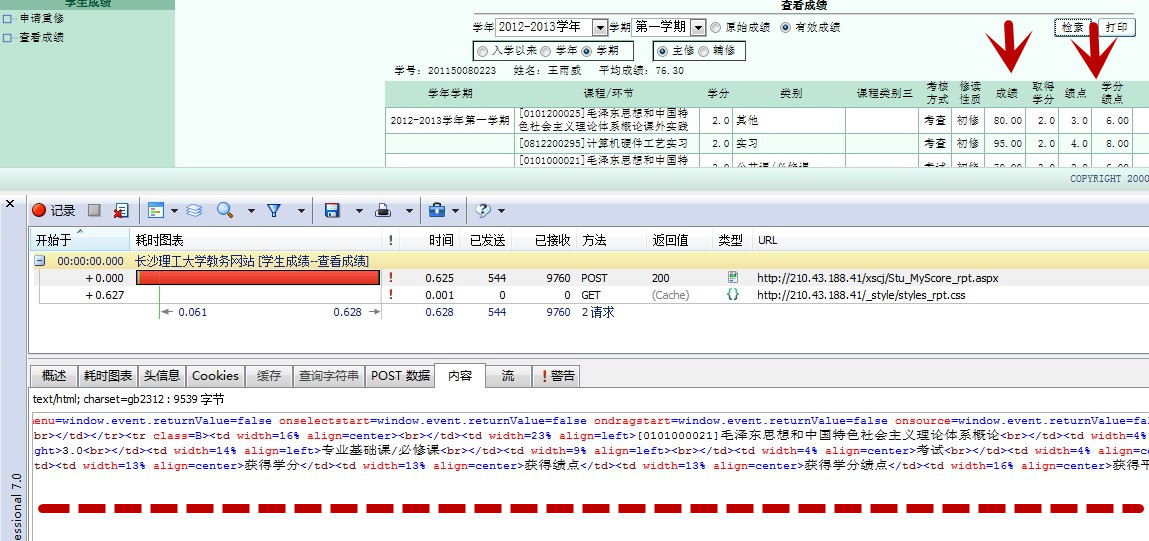
看到没?“内容”里的数据原来就是我们网页上成绩的HTML源代码!哈哈,大家懂了吧?其实抓包的目的很纯粹的!就是为了获取相应的网页信息。你像什么QQ农场外挂啥的其实都是抓包的原理哟!
好的,这样一来,我们大部分的事情就做完了,我们回忆一下之前的操作。
首先是在登陆页面抓包,从而获取相应的cookie,接着是在JAVA代码中实现POST过程,然后我们再进行抓包操作,对查询成绩页面进行的抓包,我们找到了我们所需要POST的数据和页面所返回的内容,这样我们就明朗了,我们只要合理的解析一下获取的HTML代码就可以了!不过在此之前,我们先把第三步的操作在JAVA代码里实现。
四、在代码里实现第三步操作
- String result = "";
- /* 声明网址字符串 */
- String uriAPI = "http://210.43.188.41/xscj/Stu_MyScore_rpt.aspx"; //这个网站之前说了,查看HttpWatch里相应的URL
- /* 建立HttpPost联机 */
- HttpPost httpRequest = new HttpPost(uriAPI);
- List<NameValuePair> params = new ArrayList<NameValuePair>();
- /**
- * 以下六个参数必须要用
- */
- params.add(new BasicNameValuePair("sel_xn", "2011")); // 学年
- params.add(new BasicNameValuePair("SelXNXQ", "2"));
- params.add(new BasicNameValuePair("SJ", "1"));
- params.add(new BasicNameValuePair("sel_xq", term)); // 学期:0 第一学期,1 第二学期
- params.add(new BasicNameValuePair("zfx_flag", "0"));
- params.add(new BasicNameValuePair("zfx", "0"));
- try {<span style="font-family: Arial, Helvetica, sans-serif;">//把之前的cookie放到此次POST所需要的头信息中</span>
- httpRequest.setHeader("Cookie","ASP.NET_SessionId="+ cookies.get(0).getValue());
- httpRequest.setEntity(new UrlEncodedFormEntity(params2, HTTP.UTF_8));
- /* 发出HTTP request */
- HttpResponse httpResponse2 = new DefaultHttpClient().execute(httpRequest3);
- /* 若状态码为200 ok */
- if (httpResponse2.getStatusLine().getStatusCode() == 200) {
- <span style="white-space:pre"> </span>//接下来的代码是为了把从网页获取到的内容读出来
- StringBuffer sb = new StringBuffer();
- HttpEntity entity = httpResponse2.getEntity();
- InputStream is = entity.getContent();
- BufferedReader br = new BufferedReader(new InputStreamReader(is, "GB2312"));
- //是读取要改编码的源,源的格式是GB2312的,安源格式读进来,然后再对源码转换成想要的编码就行
- String data = "";
- while ((data = br.readLine()) != null) {
- sb.append(data);
- }
- result = sb.toString(); //此时result中就是我们成绩的HTML的源代码了
- } else {
- }
- } catch (Exception e) {
- e.printStackTrace();
- }
老规矩,对于一些大家不熟悉的类依旧自行查看API文档。
五、使用Jsoup解析获取的HTML代码
好样的,做完第四步的时候其实我们已经基本完成了百分之80的操作了,用Jsoup解析说难不难,说易不易,我这里就只是把解析我所需要的内容进行一下讲解。
先上代码。
- private String filterHtml(String source) {
- if (null == source) {
- return "";
- }
- StringBuffer sff = new StringBuffer();
- String score[];
- int i = 0, j = 0;
- String html = source;
- Document doc = Jsoup.parse(html); //把HTML代码加载到doc中
- Elements links_class = doc.select("td[width=23%]"); // 这是课程名,因为课程名的HTML标签事<td width=23% align=left>,然后我发现<span style="font-family: Arial, Helvetica, sans-serif;">width=23%是这个标签特有的,所以我就把它给提出来了</span>
- Elements links_grade = doc.select("td[width=5%]"); // 这是分数,原因同上
- score = new String[links_grade.size()];
- for (Element link_grade : links_grade) {
- score[i++] = link_grade.text();
- }
- for (Element link : links_class) {
- sff.append(link.text()).append(" : ").append(score[j]).append("\n");
- j = j+2; //这里之所以+2是因为分数的标签是<td width=5% align=right>,而学分也是这样的标签,所以我就每提取一次分数标签跳过一次学分标签
- }
- html = sff.toString();
- return html;
- }
好了,这样子整个操作就结束了。其实最后总结一下也不难哈。
先是在登陆页面获取登录成功后的cookie,之后便是带着这个cookie到处跑 = = 这样说很形象吧。然后获取你要的页面的内容(也就是HTML代码),最后便是合理的解析这个代码。是的吧,不难吧!!
 写了这么多,手都打累了,希望对大家有帮助!!我的辛苦就没有白费了
写了这么多,手都打累了,希望对大家有帮助!!我的辛苦就没有白费了
希望转载的时候注上本文链接,尊重原文作者。谢谢~http://blog.csdn.net/u010858238/article/details/9029653
by 长沙理工大学计算机1102班 王雨威















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









