








📃个人主页:island1314
🔥个人专栏:Linux—登神长阶
⛺️ 欢迎关注:👍点赞 👂🏽留言 😍收藏 💞 💞 💞
- 生活总是不会一帆风顺,前进的道路也不会永远一马平川,如何面对挫折影响人生走向 – 《人民日报》
🔥 目录
四、函数
4.1 聚合函数
| 数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的总和 |
| AVG([DISTINCT] expr) | 返回查询到的数据的平均值 |
| MAX([DISTINCT] expr) | 返回查询到的数据的最大值 |
| MIN([DISTINCT] expr) | 返回查询到的数据的最小值 |
-
这里是为
select分组查询做准备的,聚合函数是以 查出来的记录 为单位帮我们进行 数据聚合统计的。这种聚合统计方式通常是产出一个期望的结果,如个数、和、平均值、最大值、最小值。 -
mysql中其实也是有函数的,这个函数可以被直接调用,我们可以在mysql直接使用聚合函数直接对一组结果进行聚合统计。 -
聚合函数()里面可以是全列,可以是指定列。
【案例】:基于我们上面 Retrieve 那建的表 exam_result,同样这里只写指令,不写结果
① 统计班级共有多少同学
select count(*) from exam_result;
② 统计班级去重后数学成绩有多少
select count(distinct math) from exam_result;
③ 统计数学总分
select sum(math) from exam_result;
④ 统计评价总分
select avg(math+chinese+english) from exam_result;
⑤ 返回 > 70 分以上的数学最低分
select min(math) from exam_result where math>70;
假设我们表中数学 > 70 分以上的最低分为 73 分,但是有几个同学都是这个分,如果我们不仅想知道分数还想把名字也带上,结果会怎样呢?如下:
mysql> select name, min(math) from exam_result where math > 70;
ERROR 1140 (42000): In aggregated query without GROUP BY, expression #1 of SELECT list contains nonaggregated column 'learn2.exam_result.name'; this is incompatible with sql_mode=only_full_group_by
聚合统计的前提条件,一定是你先把我要聚合的数据先拿出来,然后才能聚合。
- 做 聚合 的时候必须保证你要显示的或者你要查询的数据列是 被允许聚合 的。
- 最低成绩只有一个,但
name每个人都不一样没有办法做聚合,例如两个人都是 73,那返回谁的名字呢
4.2 分组查询 – group by
- 分组是对表中的数据进行分组,分完组之后,在对表中每一组进行相关聚合统计。
- 而分组的目的是为了进行分组之后,方便进行聚合统计。
- 如班级里有男生女生,我们相对男生女生成绩分别统计,所以可以对性别进行分组然后在进行成绩的聚合统计。
- 在
select中使用group by子句可以对指定列进行分组查询。 - 我们也可以把数据筛选之后再进行分组然后再聚合统计。
语法:
select column1, column2, .. from table group by column;
【案例】:
- 需求是按照组来统计的,根据的 emp 表中 role 列来进行分组。

- 再次强调
group by不是你想用就能用,一定要结合需求。 group by的核心作用是让我们继续分组聚合统计的,所以你要把需求分清楚然后和group by功能对上,才能用group by。- 我们在进行分组统计的时候,
group by后面指定列名,指明我们要分组的列是谁,但实际分组是用 该列的不同的行数据是否相同 进行分组的!(相同的列可以进行压缩聚合) - 当我们分完组之后,那分组的条件(role),组内一定是相同的,因此可以被聚合压缩。
理解:
- 分组,不就是把一组按照条件拆分多个组,进行各组内的统计。
- 分组(" 分表 "),不就是把一张表按照条件在逻辑上拆成多个子表,然后分别对各自的子表进行 聚合统计
- 拆成各个组不就是在逻辑上拆成各个表,然后分别在每个表里做聚合统计,以前我们做的聚合统计是在一张表里进行的
- 换句话说,只要掌握在一张表里查询,在查询之前先做好分组,后面的工作和思路理解上和之前单表上的聚合统计是一模一样的。
HAVING
🍅 GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用HAVING
- having经常和group by搭配使用
- 作用:对聚合后的统计数据,进行条件筛选

having 和 where 区别理解?执行顺序?构建对 “结果” 的理解。❓
首先having和where都是够进行条件筛选,但是它们两个是完全不同的筛选。
where是对具体的任意列进行条件筛选having对分组聚合之后的结果进行条件筛选**。**
它们俩的应用场景是完全不同的。换句话说where是先对原始表进行条件过滤,对过滤后的结果在进行分组
题目训练 如下:
牛客:批量插入数据
牛客:找出所有员工当前(to_date=‘9999-01-01’)具体的薪水salary情况,对于相同的薪水只显示一次,并按照逆
序显示
牛客:查找最晚入职员工的所有信息
牛客:查找入职员工时间排名倒数第三的员工所有信息
牛客:查找薪水涨幅超过15次的员工号emp_no以及其对应的涨幅次数t
leetcode: duplicate-emails
leetcode: big-countries
leetcode: nth-highest-salary
4.3 日期函数
| 函数名称 | 描述 |
|---|---|
current_date() | 获取当前日期 |
current_time() | 获取当前时间 |
current_timestamp() | 获取当前时间戳 |
date(datetime) | 返回 datetime 参数的日期部分 |
date_add(date, interval d_value_type) | 在 date 中添加日期或时间,interval 后的数值单位可以是 year、minute、second、day |
date_sub(date, interval d_value_type) | 在 date 中减去日期或时间,interval 后的数值单位可以是 year、minute、second、day |
datediff(date1, date2) | 计算两个日期之间的差值,单位是天 |
now() | 获取当前日期时间 |
【案例】:
① 获取当前日期
SELECT current_date();
② 获取当前时间
SELECT current_time();
③ 获取当前时间戳
SELECT current_timestamp();
④ 获取当前日期时间
SELECT now();
⑤ 截断当前时间,只获得日期部分
SELECT date(now());
⑥ 在日期的基础上加日期
SELECT date_add(now(), interval 10 year);
⑦ 在日期的基础上减去时间
SELECT date_sub(now(), interval 10 minute);
⑧ 计算两个日期之间相差多少天
SELECT datediff(now(), '1949-10-01'); # 前面减后面
这些函数有什么用呢,下面有两个案例
**案例 1 **:创建一张记录生日的表
create table tmp(id int primary key auto_increment, birthday date); # 建表
insert into tmp (birthday) values (current_date()); # 插入数据
mysql> select * from tmp;
+----+------------+
| id | birthday |
+----+------------+
| 1 | 2025-02-08 |
+----+------------+
虽然 current_time() 这里显示的是时分秒,实际上插入的时候也能插入,所有的时间在获取的时候都是年月日 时分秒,只不过显示时是不一样的。
**案例 2 **:创建一张记录生日的表
create table msg(id int primary key auto_increment, sendtime datetime);
insert into msg values(1, now());
mysql> select id, date(sendtime) from msg; # 显示所有留言信息
+----+----------------+
| id | date(sendtime) |
+----+----------------+
| 1 | 2025-02-08 |
+----+----------------+
mysql> select * from msg; # 显示所有留言信息
+----+---------------------+
| id | sendtime |
+----+---------------------+
| 1 | 2025-02-08 19:53:08 |
+----+---------------------+
-- 查询在2分钟内发布的帖子
mysql> select * from msg where date_add(sendtime, interval 2 minute) > now();
+----+---------------------+
| id | sendtime |
+----+---------------------+
| 1 | 2025-02-08 19:53:08 |
+----+---------------------+
4.4 字符串函数
| 函数名称 | 描述 |
|---|---|
charset(str) | 返回字符串字符集(编码集) |
concat(string [,…]) | 连接字符串 |
instr(string, substring) | 返回子字符串在字符串中的位置,无则返回0(mysql 起始从 1 开始) |
ucase(string) | 转换成大写 |
lcase(string) | 转换成小写 |
left(string, length) | 从字符串左边起取 length 个字符 |
right(string, length) | 从字符串右边起取 length 个字符 |
length(string) | 字符串长度 |
replace(str, search_str, replace_str) | 在字符串中用 replace_str 替换 search_str |
strcmp(string1, string2) | 逐字符比较两个字符串大小 |
substring(str, position [,length]) | 从字符串的 position 开始,取 length 个字符 |
ltrim(string), rtrim(string), trim(string) | 去除前后空格 |
【案例】:
① 获取某个表的某列的 字符集
mysql> select charset(id) from msg;
+-------------+
| charset(id) |
+-------------+
| binary |
+-------------+
② 连接字符串
SELECT concat(name, '的语文是', chinese, '分,', '数学', math, '分,', '英语', english, '分') from exam_result;
+-------------------------------------------------------------------------------------------------+
| concat(name, '的语文是', chinese, '分,', '数学', math, '分,', '英语', english, '分') |
+-------------------------------------------------------------------------------------------------+
| 唐三藏的语文是67分,数学98分,英语56分 |
| 孙权的语文是70分,数学73分,英语78分 |
| 宋公明的语文是75分,数学65分,英语30分 |
| zs的语文是88分,数学73分,英语80分 |
+-------------------------------------------------------------------------------------------------+
③ 求学生表中姓名占用的字节数
select name,length(name) from exam_result;
+-----------+--------------+
| name | length(name) |
+-----------+--------------+
| 唐三藏 | 9 |
| 孙权 | 6 |
| 宋公明 | 9 |
| zs | 2 |
+-----------+--------------+
以前说过 mysql 的字符真的就是一个字符,utf8中一个汉字占 3 个字节
length函数返回字符串长度,以 字节为单位。- 如果是多字节字符则计算多个字节数;如果是单字节字符则算作一个字节。
- 比如:字母,数字算作一个字节,中文表示多个字节数(与字符集编码有关)
④ 查询学生表名字的第二个到第三个字符
mysql> select id, substring(name, 2, 2) from exam_result;
+----+-----------------------+
| id | substring(name, 2, 2) |
+----+-----------------------+
| 1 | 三藏 |
| 2 | 权 |
| 3 | 公明 |
| 4 | s |
+----+-----------------------+
⑤ 以首字母小写的方式显示所有学生的姓名
select name, concat(lcase(substring(name, 1, 1)), substring(name, 2)) FROM exam_result;
4.5 日期函数
| 函数名称 | 描述 |
|---|---|
abs(number) | 绝对值函数 |
bin(decimal_number) | 十进制转二进制 |
hex(decimalNumber) | 转换成十六进制 |
conv(number, from_base, to_base) | 进制转换 |
ceiling(number) | 向上去整(数据变大) |
floor(number) | 向下去整 |
format(number, decimal_places) | 格式化,保留小数位数 |
rand() | 返回随机浮点数,范围 [0.0, 1.0) |
mod(number, denominator) | 取模,求余 |
ceiling(number)向上去整floor(number)向下去整
一般我进行取整的时候是进行四舍五入取整,但是除了 四舍五入 还有其他的取整方式。
- 我们把丢弃小数部分的取整方式称为0向取整,以前我们在 C学的9/2=4 就是向 0 取整,还有向大的方向取的向上取整、向小的方向取的向下取整
4.6 其他函数
① 查询当前用户
SELECT user();
② 显示当前正在使用的数据库
SELECT database();
③ 对一个字符串进行 MD5 摘要
md5(str) 对一个字符串进行md5摘要,摘要后得到一个32位字符串
比如密码在数据库绝对不能是明文保存的。万一表结构泄漏了,用户信息就全部被泄漏了。
- 这里有一个细节
mysql对于sql里面涉及核心密码password关键字之类的这个sql语句就不会被保存,不能上翻下翻了 - 密码被变成固定32位字符串,就不用担心密码被泄漏了。但是登录的时候也必须是数据库的摘要密码。
select md5("good"); # SELECT PASSWORD(str);
+----------------------------------+
| md5("good") |
+----------------------------------+
| 755f85c2723bb39381c7379a604160d8 |
+----------------------------------+
④ MySQL 密码函数
除了md5进行保存密码之外,数据库还提供更复杂的密码设定的函数 password(),MySQL数据库使用该函数对用户加密
select password('root'); # SELECT PASSWORD(str);
+-------------------------------------------+
| password('root') |
+-------------------------------------------+
| *81F5E21E35407D884A6CD4A731AEBFB6AF209E1B |
+-------------------------------------------+
**注意:**由于新版版本MySQL移除了 password(),在使用的时候是会发生语法报错问题
之前我写这里难怪一直说是语法错误❌,检查发现是我是的 MySQL 是
8.0,查看MySQL 8.0 Reference Manual已经移除了PASSWORD加密函数,因此8.0以后版本的加密压缩函数只能采用以下函数
- MD5()
- SHA1()
- SHA()
**解决:**建议使用MD5()替代 password()函数即可解决 password() 不兼容问题。
⑤ 条件判断函数
ifnull(val1, val2) 如果val1为null,返回val2,否则返回val1的值
类似于三目操作符 ? : 为真返回第一个,为假返回第二个
IFNULL(val1, val2) -- 如果 `val1` 为 `NULL`,返回 `val2`,否则返回 `val1` 的值
mysql> select ifnull(null, 1);
+-----------------+
| ifnull(null, 1) |
+-----------------+
| 1 |
+-----------------+
mysql> select ifnull(1, 2);
+--------------+
| ifnull(1, 2) |
+--------------+
| 1 |
+--------------+
五、复合查询
5.1 多表查询
在实际开发中,数据通常来自不同的表,需要进行多表查询,显示雇员名、雇员工资以及所在部门的名字如下:
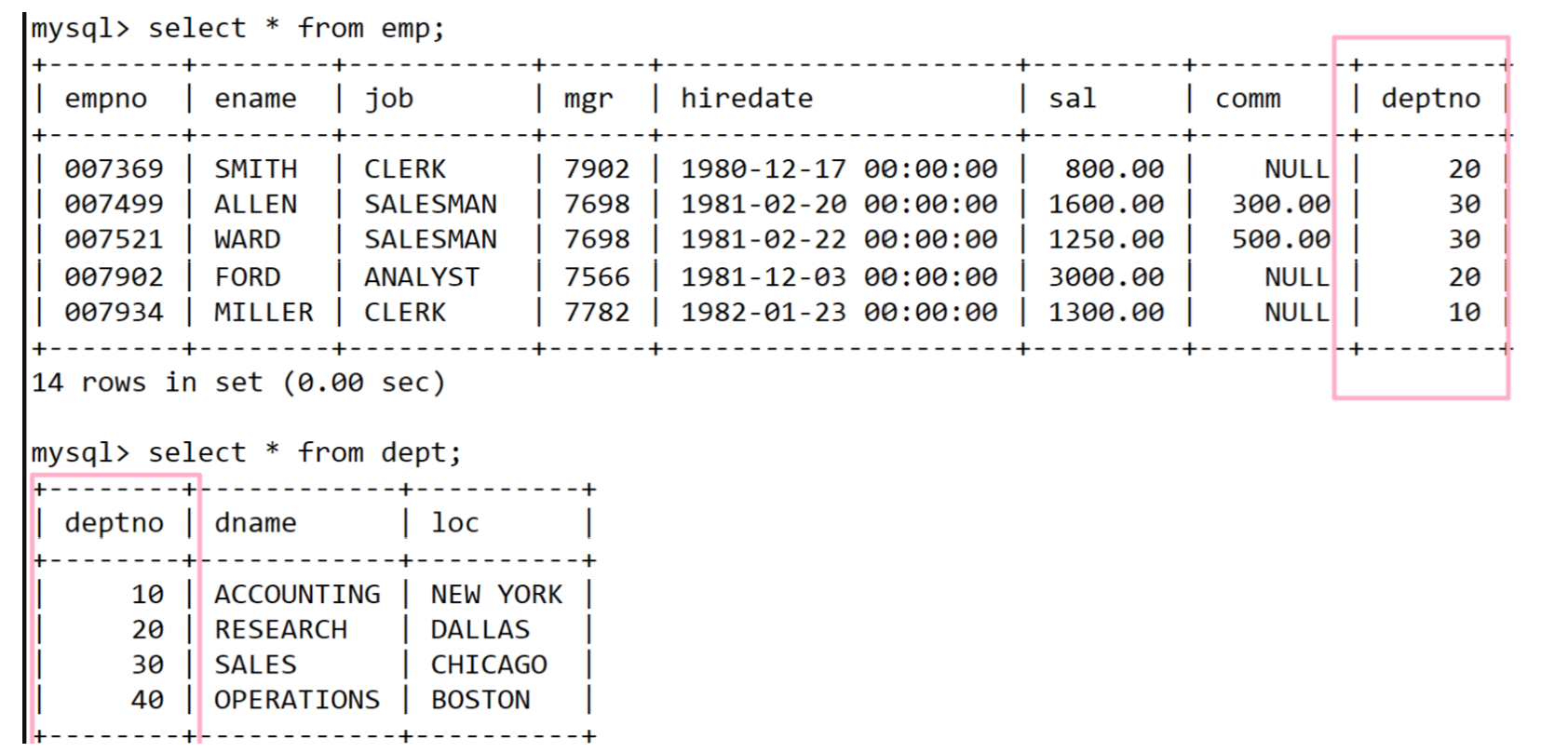
我们发现上面emp表中是没有部门名称的,换句话说要的数据是从两张表来的。
- 员工名和员工工资来自于emp表,部门名称来来自于dept表,因此需要我们要将 两个表做整合然后在查询
可以看到形成了一张大表,仔细观察一下,将两张表信息做整合的时候,就光SMITH这一条消息就和整个dept表做组合形成了更多的记录,发现下面都是这样的。

新形成表本质是将两张表中数据进行穷举组合的结果。我们把它称之为 笛卡尔积
- 在我们看来这不就是把两张表变成了一张表嘛。
- 所以未来在做数据的查找的时候,不就还是相当于单表的查找吗!
- 然后就可以按照条件筛选出想要的信息。
注意 :穷举 是把所有组合结果都放在一起了,但是有些信息是有无意义的,因此可以先去除无意义的信息(不过还是看具体情况在决定是否保留),然后在按条件查找
去除无效信息后筛选 如下:

在我们看来mysql一切皆表,换句话说这里做笛卡尔积之后,它形成的组合结果也是表结构,然后按照 条件筛选
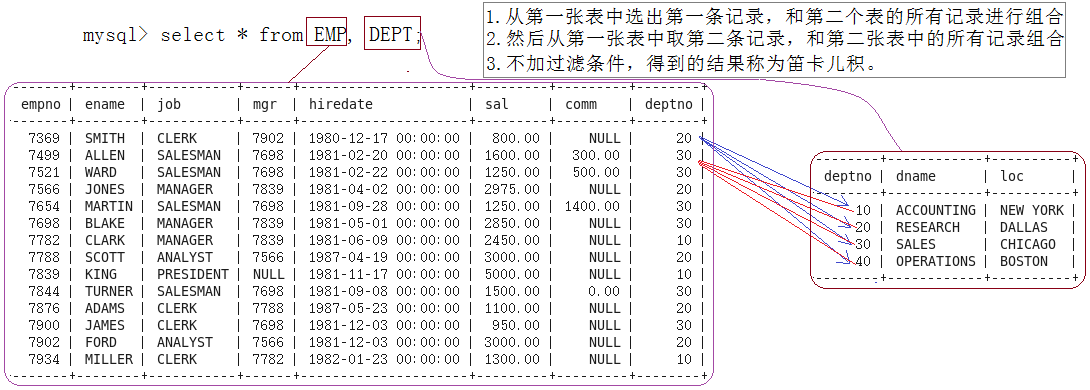
上面我们是将两个不同的表做笛卡尔积,那可不可以把同一张表做笛卡尔积呢?
5.2 自连接
自连接是指同一张表进行 笛卡尔积
- 我们发现直接把同一张表做笛卡尔积是不行的。
- 主要原因:这是同一张表这样不太好,字段名有重复不知道用的是那个表的字段名。
mysql> select * from msg, msg;
ERROR 1066 (42000): Not unique table/alias: 'msg'
因此我们可以给两个表做重命名。
- 重命名也可以对表进行重命名,一旦对表进行重命名之后几乎可以在这条sql语句任何地方出现。因为sql语句执行一定是先告诉是从那个表拿数据。
mysql> select * from msg t1, msg t2;
+----+---------------------+----+---------------------+
| id | sendtime | id | sendtime |
+----+---------------------+----+---------------------+
| 1 | 2025-02-08 19:53:08 | 1 | 2025-02-08 19:53:08 |
+----+---------------------+----+---------------------+
我们看到同一个表也是拿着前面的表每一条记录去和后面的表中所有记录做组合。所以哪怕是同一张表也可以做笛卡尔积,只不过是对表名重新命名一下即可。
比如:要查找 某个员工的上级领导的编号和姓名,方法如下:
- 通过子查询找到FORD的领导编号,然后根据这个编号找到领导信息
- 我们可以通过自连接来查找,相比于上面方法就更加方便
5.3 子查询
之前编写的时候,子查询 之前也写了一些。现在来正式说一下查询的概念。除了刚才的 笛卡尔积 是一种整合表的做法,子查询 也是多表查询或者一张表中复杂查询时常用的做法。
- 子查询是指嵌入在其他sql语句中的
select语句,也叫 嵌套查询
一般我们在子查询时依赖的永远都是子查询查出来的结果,根据结果我们可以把子查询划分为
单列单行子查询、单列多行子查询、多列单行子查询、多列多行子查询
1, 行列子查询
① 单行子查询
查询数学成绩和孙权相同的同学,如下:
select * from exam_result where math = (select math from exam_result where name = '孙权');
+----+--------+---------+------+---------+
| id | name | chinese | math | english |
+----+--------+---------+------+---------+
| 6 | 孙权 | 70 | 73 | 78 |
| 8 | zs | 88 | 73 | 80 |
+----+--------+---------+------+---------+
② 多行子查询
in关键字: 表示相同,判断一个列值是否在集合中。all关键字: 表示全部any关键字: 表示任意
查询和10号部门的工作岗位相同的雇员的名字、岗位、工资、部门号,但不包含10号部门:

我们不仅仅用子查询把要的结果筛选出来,我想说的是,一个SQL整体的查询结果本身就是表结构,mysql一切皆表,所以不要认为只有物理上真实存在的表才可以做笛卡尔积,我们可以将一个查出来的表结构也可以和其他表或者其他查询结果做笛卡尔积。
- 其次,子查询不仅能出现在
where后面充当判断条件,而且也能出现在from后面充当笛卡尔积。
③ 多列子查询
单行子查询是指子查询只返回单列,单行数据;
多行子查询是指返回单列多行数据,都是针对单列而言的,而多列子查询则是指查询返回多个列数据的 子查询语句
查询和SMITH的部门和岗位完全相同的所有雇员,但不包含SMITH本人:

2, 在 from 子句中使用子查询
子查询不仅可以出现 where 中充当判断条件,也可以出现在 from 中,from 是在sql中告诉数据库去那个表里拿数据。
在这里说一下任意查出来的表结构在我看来全都是表结构。
- 子查询语句出现在
from子句中,把一个子查询结果当做一个临时表使用,可以解决很多问题。
显示每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资
-- 首先统计每个部门的平均工资
SELECT deptno, AVG(sal) AS myavg FROM emp GROUP BY deptno;
-- 然后与员工表进行笛卡尔积,并筛选出符合条件的记录
SELECT ename, emp.deptno, sal, myavg FROM emp, (SELECT deptno, AVG(sal) AS myavg FROM emp GROUP BY deptno) tmp WHERE emp.deptno = tmp.deptno AND sal > myavg;
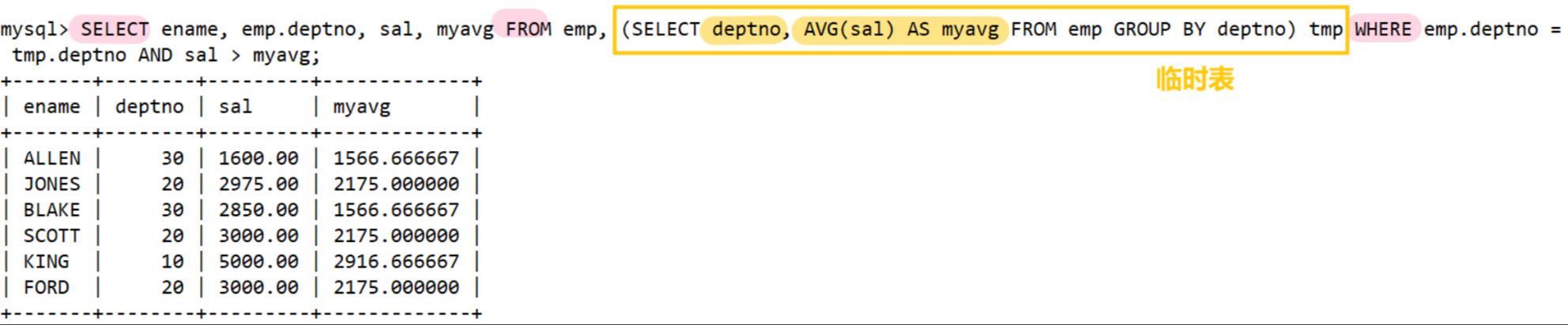
子查询做表必须要给一个别名
只要你想做还可以在笛卡尔积。所以我们面对非常复杂的查询本质上都是在任务分解,复杂问题是由简单问题构成的。
查找每个部门工资最高的人的姓名、工资、部门、最高工资
- 首先也是要分组聚合统计找每个部门的最高工资,只不过只能统计到部门号和部门工资,这个人其他信息是没有办法在group by找到的。
- 然后我们把这个临时表结构和emp做笛卡尔积。
- 最后在筛选出来部门号相同的,这个时候不有我们想要的信息的一张表了吗,然后在筛选自己想要的信息。
- 然后筛选出部门号相同的信息,最后找出自己要的数据就可以了

记住mysql一切皆表,所谓的一切皆表就意味着可以把查询出来的临时结果在from后面也充当表。
总结一下:
mysql在我的心里是没有多表结构的,永远就是一张表,group by在我看来也是一张表,分组就是分表。
只要解决一个问题其他都是解决,多张表我可以在where中充当 判断条件,在from中也做一个 临时表表然后和其他表做笛卡尔积。
所以根本就没有多表问题。
⭕ 解决多表问题的本质:想办法将多表转化成为单表,所以mysql中,所有select的问题全部都可以转成单表问题!这就是我们多表查询的指导思想!
3, 合并查询
在实际应用中,为了合并多个 select 的执行结果,可以使用集合操作符 union ,union all
- 合并并不是笛卡尔积,笛卡尔积是将两个表的信息穷举。合并就是单纯的合起来。
union把两条sql合并起来并且去掉重复的- 不想去重使用
union all,就会把所有信息保留
union
该操作符用于取得两个结果集的并集。当使用该操作符时,会 自动去掉结果集中的重复行
- 注意合并时,两个表结构列必须是一样的才能把两个表合并起来
mysql> select * from exam_result where math > 90;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 唐三藏 | 67 | 98 | 56 |
| 3 | 猪悟能 | 88 | 98 | 90 |
+----+-----------+---------+------+---------+
mysql> select * from exam_result where english > 70;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
| 6 | 孙权 | 70 | 73 | 78 |
| 8 | zs | 88 | 73 | 80 |
+----+-----------+---------+------+---------+
-- 结合上面两个表进行合并,如下:
mysql> select * from exam_result where math > 90 UNION select * from exam_result where english > 70;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 唐三藏 | 67 | 98 | 56 |
| 3 | 猪悟能 | 88 | 98 | 90 |
| 2 | 孙悟空 | 87 | 78 | 77 |
| 6 | 孙权 | 70 | 73 | 78 |
| 8 | zs | 88 | 73 | 80 |
+----+-----------+---------+------+---------+
mysql> select * from exam_result where math > 90 UNION ALL select * from exam_result where english > 70;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 唐三藏 | 67 | 98 | 56 |
| 3 | 猪悟能 | 88 | 98 | 90 |
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
| 6 | 孙权 | 70 | 73 | 78 |
| 8 | zs | 88 | 73 | 80 |
+----+-----------+---------+------+---------+
六、内外连接
表的连接分为内连接和外连接。
6.1 内连接
内连接实际上是利用 WHERE 子句对两个表形成的 笛卡尔积 进行筛选。我们前面学习的查询都是内连接,这也是开发过程中最常用的连接查询。
- 除了使用
FROM逗号连接两个表然后用WHERE筛选有效信息,还可以使用INNER JOIN连接两个表,并用ON和AND(更推荐where) 级联多个筛选条件来对笛卡尔积进行筛选。 - 之前学到的其实就是内连接的一种。
语法:
SELECT 字段 FROM 表1 INNER JOIN 表2 ON 连接条件 AND 其他条件;
示例:
之前的写法:显示SMITH的名字和部门名称,如下:
SELECT ename, emp.deptno, dname FROM emp, dept where emp.deptno = dept.deptno and ename = 'SMITH';
标准内连接写法:
select ename, emp.deptno, dname from emp innet join dept ON emp.deptno = dept.deptno where ename = 'SMITH';

- 两种写法都可以得到同样的数据
- 换句话说这种标准写法可以让我们的sql逻辑更清楚 ,哪一个部分是要形成笛卡尔积的,那一部分是进一步做条件筛选的。
- 内连接中后面的条件也可以用
and连接,不过还是建议用where,逻辑更清楚。
6.2 外连接
外连接分为 左外连接 和 右外连接
左外连接
如果多表查询,我们想让左侧的表完全显示不要过任何过滤筛选,如果和右侧的表配不上,让右侧的都为空也可以。必须保持左侧表的全貌。叫做左外连接。
语法:
SELECT 字段名 FROM 表名1 LEFT JOIN 表名2 ON 连接条件
示例:
- 查询所有学生的成绩,如果这个学生没有成绩,也要将学生的个人信息显示出来如果用 ID 做内连接,只有1号和2号学生符合条件,而我们需要保留左侧表结构的完整性,因此使用左外连接:
SELECT * FROM stu LEFT JOIN exam ON stu.id = exam.id;
左侧表完全保留,右侧表按条件拼接,条件满足直接拼上,条件不满足拼 NULL。
右外连接
右外连接用于让右侧的表完全显示。如果右侧表的记录在左侧表中找不到匹配项,则左侧表的字段显示为 NULL。必须保持右侧表的全貌。
语法:
SELECT 字段 FROM 表名1 RIGHT JOIN 表名2 ON 连接条件;
示例:
对 stu 表和 exam 表联合查询,把所有的成绩都显示出来,即使这个成绩没有学生与之对应,也要显示出来
SELECT * FROM stu RIGHT JOIN exam ON stu.id = exam.id;


















 3412
3412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









