







一、背景知识
1.内存问题
早期程序直接运行在物理地址上,有以下几个问题:
(1)地址空间不隔离:所有程序直接访问在物理地址上,程序所使用内存不相互隔离;
(2)内存使用效率低:没有有效内存管理机制,将整个程序载入并且执行;
(3)程序运行的地址不确定:程序每次装入运行时,需要给其分配足够大空闲内存,此空闲内存不确定。
关于隔离:虚拟地址空间是虚拟的,逻辑上的。现在每个程序都有自己独立的虚拟空间,且只能访问自己的地址空间,有效的实现进程间地址空间的隔离。
分段:
其基本思想是将一段与程序所需要的内存空间大小的虚拟空间映射到某个物理地址空间。

以上分段机制解决了(1)和(3)两个问题,程序A和B被映射到两个不同物理地址,没有交叉相互隔离;同时对于程序原来说无需关心被分配到哪个物理地址,只需按照虚拟地址编写程序,而虚拟地址是确定的。
分段机制的问题:分段的粒度太大,实际上根据程序局部性原理,程序可以被分成更小的单元,即分页机制。
分页:
分页基本思想是将程序分割成更小的固定大小的页,目前几乎所有操作系统使用4KB大小的页。同样的,虚拟地址空间页叫虚拟页(VP),物理内存页叫物理页(PP)。
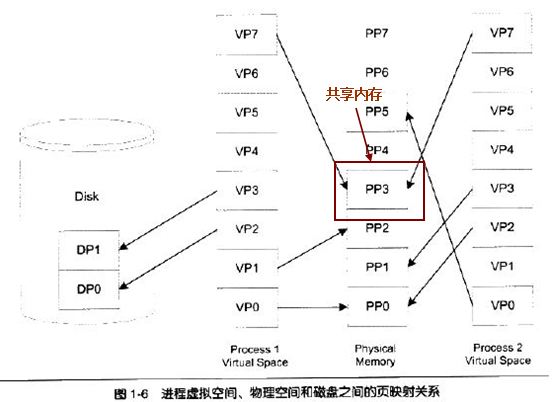
我们程序看到的是虚拟地址,需要依靠内存管理单元MMU来进行虚拟地址到物理地址的映射。
2.线程问题
线程是轻量级的进程,是程序执行的最小单元。通常进程由多个线程组成,并且各个线程之间共享代码段、数据段和堆等内存数据。线程与进程共享的数据:程序代码(.text)、全局变量和局部静态变量(.data)和堆上数据(malloc申请);
线程私有数据:局部变量和函数参数、寄存器数据,即栈上数据。
线程调度:优先级改变的三种方式:1. 用户指定优先级; 2.根据进入等待状态的频繁程度提升或降低优先级; 3.长时间得不到执行而被提升优先级。
linux中线程创建函数如下,具体关于线程编程可参考 http://blog.csdn.net/feixiaoxing/article/details/7243664
#include <pthread.h>
int pthread_create(pthread_t *tidp,constpthread_attr_t*attr,
(void*)(*start_rtn)(void*),void*arg);线程安全
在多线程并发环境中,由于各线程共享同一进程的全局变量以及堆数据,此时保证数据的一致性显得尤为重要。
举最简单的例子,全局变量i = 1; 线程1: ++i; 线程2: --i; 实际上++(--)操作并非一步完成,实现过程如下所示:(1)读取 i 到寄存器A; (2)寄存器A++; (3)将A内容写回 i 。
此时两个线程的执行序列并不确定,因此最终i可能会是0,1,2的任意数值(具体原因不在细说)。
同步和锁:通过同步手段,相当于对数据的访问原子化。通常有信号量(semaphore)和互斥量(mutex)等方式。
信号量:可以在被系统的一个线程获取,而在另一个线程释放;而互斥量必须是同一线程获取和释放。
函数可重入
即允许多个线程同时执行该函数,该函数执行可随时被中断。可重入函数仅使用自身栈上变量。
过度优化
1. 编译器可能因为效率会将毫无相干的相邻两条指令改变执行顺序,从而导致多线程出错。可以使用关键字volatile解决:
(1)防止编译器为提高速度将一变量缓存到寄存器而不写回;(2)防止编译器调整volatile变量指令执行顺序。
2.CPU过度优化改变执行顺序
volatile T * pInst=0;
T * GetInstance(){
if(pInst==NULL){
lock();
if(pInst==NULL)
pInst=new T;
unlock();
}
return pInst;
}上述代码使用双重if,可以让lock的调用开销降低到最小。PInst逻辑上总是指向一个有效对象。但是,由于C++里的new包含两个步骤:(1)分配内存 (2)调用构造函数
因此,pInst=new T包含: (1)分配内存;(2)在内存位置上调用构造函数;(3)将内存地址赋予pInst。
由于2和3可以颠倒,所以完全可能被换序而出现如下情况: pInst值不是NULL,但是对象依然没有构造完成。这个时候,
另外一个对GetInstance的并发调用因为pInst不是NULL而会直接返回尚未构造完成的对象的地址,即pInst。此时如果对该pInst指向的类进行操作,有可能导致程序崩溃。
解决方法如下:
T * temp =new T;
barrier(); //防止CPU将该指令之前的指令交换到barrier之后
pInst=temp;
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
二、静态链接-编译与链接
1.过程
整个过程包括:预编译、编译、汇编和链接。

(1)预编译:1)删除宏定义#define,并进行展开 2)处理条件预编译指令(#if)
3)处理#include,将包含头文件插入到预编译指令位置 4)删除所有注释
(2)编译:最核心部分。编译过程主要包括对文件的词法、语法、语义进行分析以及优化生成后汇编代码。
(3)汇编:汇编器as将汇编代码转换成机器指令。
(4)链接:链接的主要内容是把各个模块之间相互引用的部分处理好,使得各个模块之间能够正确的衔接。链接过程主要包括:地址和空间的分配、符号决议和重定位。对于指令中使用了定义在其他目标文件中的全局变量和函数,该目标文件需要在链接时重定位。
2.编译过程
编译过程一般分为6步:扫描(词法分析)、语法分析、语义分析、源代码优化、代码生成和目标代码优化。(1)词法分析:通过扫描器将源代码的字符串序列分割成一系列记号:关键字、标示符、字符串、特殊符号(+,-)等。
(2)语法分析:语法分析器将记号进行语法分析,产生语法树。语法树就是以表达式为节点的树。
(3)语义分析:编译器能够分析的语义是静态语义,包括:声明和类型的匹配和类型转换。经过分析后,整个语法树的表达式被标识了类型。
(4)中间代码生成:源码器级优化器能在源代码级级别进行优化,将代码树生成中间代码,他跟目标机器和运行环境无关,因此是编译器前端。
(5)目标代码的生成和优化.















 2608
2608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









