







一、关于Scala安装
https://www.scala-lang.org/download/
如果你是Java程序员,想学习Scala,请看官网提供的快速入门:
https://docs.scala-lang.org/tutorials/scala-for-java-programmers.html
二、Scala语言Hello World的编写
object HelloWorld{
def main(args: Array[String]){
println("Hello World") //Scala每行不强求使用使用;
}
}Java程序员应该熟悉这个程序的结构:它包含一个调用main命令行参数的方法,一个字符串数组作为参数; 此方法的主体包含对预定义方法的单个调用println ,其中"Hello World"作为参数。该main方法没有返回值(它是一个过程方法)。因此,没有必要声明返回类型。
Java程序员不太熟悉的是object 包含该main方法的声明。这样的声明引入了通常所说的单例对象,即具有单个实例的类。因此,上面的声明声明了一个被调用的类HelloWorld和该类的一个实例,也被称为HelloWorld。该实例是在第一次使用时按需创建的。
精明的读者可能已经注意到该main方法未在static处声明。这是因为Scala中不存在静态成员(方法或字段)。Scala程序员不是定义静态成员,而是在单例对象中声明这些成员。
编译
如果我们将上述程序保存在一个名为的文件中 HelloWorld.scala,我们可以通过发出以下命令来编译它(大于号>表示shell提示符):我们使用 `scalac` Scala编译器,它生成的目标文件是标准的Java类文件。
> scalac HelloWorld.scala运行
使用该scala命令运行Scala程序。它的用法与java用于运行Java程序的命令非常相似,并且接受相同的选项。
> scala HelloWorld
Hello World
三、Scala入门
3.1 val 和 var 的区别
val:值 (类似于Java里面的final) 值不可变
标准格式 val 值名称 : 类型 = 值大小
//标准写法
val age : Int = 20
//写法1 大部分情况Scala可以识别(即省略 :类型)
val age = 20

var:变量 (类似于Java里面的变量) 值可变
标准格式 val 值名称 : 类型 = 值大小
总结:当工作中用到常量(值不需要改变时)用val , 用到变量(值需要被改变)则用var。
3.2 Scala九大基本数据类型【类型转换、类型判断】
Scala与Java一样,有9大基本数据类型:
Byte、Char、Short、Int、Long、Float、Double、Boolean 【注意都为大写开头】 和 Unit
注意:Unit表示无值,和其他语言中的void等同。
用作不返回任何结果的方法的结果类型。Unit只有一个实例值,写成()

Any相当于Java中的Object,Anyval就是我们上面所属的8大数据类型+Unit,其他为AnyRef。

基本使用就是这样子,很简单,但有几个注意点,看下图:
1、数据类型都为大写字母开头,不同于Java的基本数据类型为小写。

2、如何命名一个Float类型的常量呢?

信息1:默认为Double 信息2:需要声明为Float类型时,必须在后面加上"f"
当然这样也是可以的:
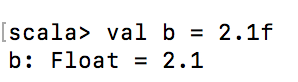
3、如何进行基本数据类型的转换呢?————asInstanceOf[转换后的类型]

4、如何进行基本数据类型的判断呢?————isInstanceOf[是否为该类型]

3.3 lazy在Scala中的应用【延迟加载】
如果一个变量或常量声明为lazy,并不会立刻发生计算输出,只有第一次使用到该变量或常量时候,才会计算返回结果

使用场景:通常使用在耗费资源的计算、占用大量网络/文件IO等情况

注意当使用lazy时候,如文件路径写错了,并不会立刻报错,而是使用到该变量时候才报错
3.4 如何使用IDEA整合Maven构建Scala程序


下一步---Finish
Plus:为什么在IDEA New中找不到Scala Class呢?

请在Plugin中点击Install Jetrains plugin... 在里面搜索Scala并下载安装即可,重启IDEA。

设置Scala-SDK ,添加电脑安装的Scala路径,Scala Class是不是出来拉?

最后附上scala入门程序的pom.xml配置
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.itcats</groupId>
<artifactId>myscala</artifactId>
<version>1.0-SNAPSHOT</version>
<inceptionYear>2008</inceptionYear>
<properties>
<scala.version>2.11.8</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
四、Scala方法与函数
在Scala中方法与函数是不一样的
4.1 方法的定义和使用

例子说明:
object FunctionTest {
//main方法 Unit代表无返回值
def main(args: Array[String]): Unit = {
println(add1(1, 1))
println(add2(1, 1))
//方式3
println(add3())
//方式4 (等同于方式3,当无入参时,可以省略括号)
println(add3)
sayHello
}
//得到 a + b 结果(方式1)
def add1(a: Int, b: Int): Int = {
a + b //最后一行就是返回值,不需要手动书写return
}
//得到 a + b 结果(方式2)
//如果只有一行 {} 可以省略
//另外省略了方法的返回值类型,Scala会猜测返回值类型(Int + Int 那肯定还是Int呀)。实际该方式与方式1相同
def add2(a: Int, b: Int) = a + b
//得到 1 + 1 结果(方式3)————无入参
def add3() = 1 + 1 //省略了方法返回值类型,由于只有一行,省略了{}
def sayHello: Unit ={
println("Hello")
}
}
4.2 函数的定义与调用
f的定义方式1:
scala> var f1 = (x: Int ,y: Int) => x * y
f1: (Int, Int) => Int = <function2>
scala> f1(9,9)
res9: Int = 81
函数的定义方式2:
scala> val f2:(Int,Int) => Int = (x,y) => x * y
f2: (Int, Int) => Int = <function2>
scala> f2(9,9)
res10: Int = 81
函数的定义方式3:
方法变为函数 —— 方法名 _ 【空格不能省略】
scala> def add2(a: Int, b: Int) = a + b
add2: (a: Int, b: Int)Int
scala> add2 _
res7: (Int, Int) => Int = <function2>含义为:<function2>代表 add _ 返回是一个函数,函数拥有两个参数【因为add方法有两个参数,返回的函数也是两个参数】。左侧(Int,Int)是函数的参数列表, => 是函数的重要标志 , 右侧Int表示函数的返回值是Int类型
4.3 传值调用与传名调用
通常,函数的参数是传值参数; 也就是说,参数的值在传递给函数之前确定。
其实, 在 Scala 中, 我们方法或者函数的参数可以是一个表达式, 也就是将一个代码逻辑传递给了某个方法或者函数.
案例1:
object CallByValueOrName {
var money: Double = 100.00;
//定义支付方法
def pay(): Unit = {
money -= 5;
}
//查询当前余额(先支付一次,再查余额)
def queryMoney(): Double = {
pay()
money
}
//传值调用
def callByValue(x: Double): Unit = {
for (i <- 0 until (3)) { // 0 1 2
print(s"money为${x} ") //money为95.0 money为95.0 money为95.0
}
}
//传名(函数)调用 x: => Int 表示的是一个方法的签名 => 是一个没有参数,返回值为Int类型的函数
def callByName(x: => Double): Unit = {
for (i <- 0 until (3)) {
print(s"money为${x} ") //money为90.0 money为85.0 money为80.0
}
}
def main(args: Array[String]): Unit = {
/** 传值调用 (参数为一个具体的数值)
* 1、计算queryMoney的返回值 = 95.0
* 2、将95.0作为参数传递给callByValue方法
*/
callByValue(queryMoney)
/** 传名(函数)调用
* 实际上是将queryMoney方法名称传递到callByName内部执行
*/
callByName(queryMoney)
}
}
案例2:
object Calculate {
//add方法有两个Int类型的参数,返回值为Int类型
def add(a: Int, b: Int): Int = {
a + b
}
//add2方法有三个参数,第一个参数是一个函数(实际上是一个函数的签名,对函数入参个数、类型、返回值类型的约束),
//第二个参数和第三个参数为Int类型的参数
//第一个参数是有两个Int类型参数,返回值类型为Int类型的函数
def add2(x: (Int, Int) => Int, a: Int, b: Int) = {
x(a, b) // x(1, 2) => 1 + 2
}
def add3(x: Int => Int, b: Int) = {
x(b) + b //b * 10 + b
}
//两个参数为Int,返回值为Int的函数
val f1: (Int, Int) => Int = (a, b) => a + b
val f2 = (a: Int, b: Int) => a + b
//一个参数为Int,返回值为Int的函数
val f3 = (a: Int) => a * 10
def main(args: Array[String]): Unit = {
//传值函数
var res1 = add(1, 2 + 2); //执行过程 add(1,4)
//传名函数
add2((a, b) => a + b, 1, 2) // 3
add2(f1, 1, 2) // 3 与上面等效
add2(f2, 1, 2) // 3 与上面等效
//f3(8) + 8
//8 * 10 + 8
add3(f3, 8) //88
}
}
4.4 默认参数的使用
所谓的默认参数就是:在函数定义时,允许指定参数的缺省值,例子如下:
object DefaultParam extends App {
def printMessage(name: String = "itcats", age: Int = 18, country: String = "中国"): Unit = {
println(s"$name $age $country")
}
printMessage()
printMessage("zp")
printMessage(age = 20, country = "美国")
}
4.5 命名参数的使用【不推荐使用】
调用方无序严格按照函数入参的顺序传递参数,只需使用命名参数即可随意调换入参的顺序,例子:
object Function2 {
def main(args: Array[String]): Unit = {
//常规调用方式
speed(100, 10)
//命名参数调用方式1
speed(distance = 100, time = 10)
//命名参数调用方式2 (调换顺序)
speed(time = 10, distance = 100)
}
//演示命名参数
def speed(distance: Int, time: Int): Unit = {
println(distance / time)
}
}
4.6 可变参数的使用
object Function3 {
def main(args: Array[String]): Unit = {
println(sum(1, 2, 3, 4))
}
//演示可变参数 在参数类型后加一个通配符* 即可
def sum(nums: Int*): Int = {
var res = 0;
for (num <- nums) {
res += num;
}
res
}
//可变参数要放在参数列表中最后的位置
def sum1(initValue: Int, nums: Int*): Int = {
var res = initValue;
for (num <- nums) {
res += num;
}
res
}
}
4.7 条件表达式
scala条件判断语句中最后一行可以作为结果返回
//演示scala条件表达式
object IfScala extends App {
val x = 0
val resBoolean = if (x > 0) true else false //false
// 0 > 0 不成立, 且代码没有 else 分支, res2 是什么呢
val res2 = if (x > 0) 2 //() 相当于else ()
// if ... else if ... else 代码较多时可以使用代码块{}
val score = 78
val res4 = {
if (score > 60 && score < 70) "及格"
else if (score >= 70 && score < 80) "良好" else "优秀"
}
println(res4) //良好
}
4.8 循环表达式[for/while/yield关键字]
scala中的循环表达式分为3类:① to ② Range ③ until 【底层实际上都是scala.collection.immutable.Range】

可以设置步长【但注意步长不能为0】

until底层实际上也是调用Range
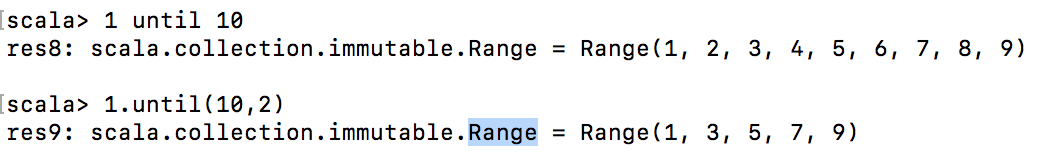
在IDEA中如何使用呢?

输出结果为: Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
下面将演示for循环、foreach循环、while循环
//循环表达式
object Function5 {
def main(args: Array[String]): Unit = {}
//循环演示1 (for)
// for (i <- 1 to 10 ; if i % 2 == 0)也可以
for (i <- 1 to 10 if i % 2 == 0) {
println(i)
}
//循环演示2 (for)
var skills = Array("Hadoop", "Spark", "Storm", "Hive", "HBase", "Kafka")
for (skill <- skills) {
println(skill)
}
//循环演示3 (foreach)
//skill实际上是skills里面的每个元素
// => 实际上是将左边的skill作用到右边的一个函数,输出另外一个结果
skills.foreach(skill => println(skill))
//循环演示4 累加100到0的每个数(while)
var (sum, num) = (0, 100)
while (num >= 0) {
sum += num;
num = num - 1; //scala不能num -- 步长
}
println(sum)
}细心观察的朋友可能会发现,scala中的for和while都不需要书写在某个方法体里面即可执行,这不同于Java。
双重for循环演示:
//两种for循环等价
for(i <- 1 to 3 ; j <- 1 to 3 ; if i != j){
println((10 * i + j) + " ")
}
for(i <- 1 to 3){
for(j <- 1 to 3){
if(i != j){
println((10 * i + j) + " ")
}
}
}yield关键字的主要作用就是记住每次迭代中的相关值,并逐一存入到一个数组中
yield关键字演示:
object LoopYield extends App {
var arr = Array(1,2,3,4,5)
val res = for(e <- arr if e % 2 == 0) yield e //res为数组类型
}比如Java场景中从List过滤出商品价格大于10的商品,那么先要遍历List,再判断,再装入一个新的List中。
scala> var arr = Array(1,2,3,4,5)
arr: Array[Int] = Array(1, 2, 3, 4, 5)
scala> val res = for(x <- arr if x % 2 == 0) yield x
res: Array[Int] = Array(2, 4)
4.9 运算符/运算符重载
Scala 中的+ - * / %等操作符的作用与 Java 一样,位操作符 & | ^ >> <<也一样。只是有一点特别的:这些操作符实际上是方法。例如:
a+b
是如下方法调用的简写:
a.+(b)
a 方法 b 可以写成 a.方法(b) 在Scala中,这叫运算符重载方法
4.10 高阶函数
//高阶函数
object HighFunction extends App {
//高阶函数: 将其他函数作为参数或其结果是函数的函数
//定义一个方法,其参数为含一个整数的参数,返回值为String的函数f 和 一个整数的参数v ,返回值为一个函数
def apply(f: Int => String, v: Int) = f(v) //"[" + 10.toString + "]"
//定义一个方法其参数为含一个整数的参数,返回值为String
def layout(x: Int) = "[" + x.toString + "]" //layout: Int => String
//调用
println(apply(layout, 10))
}
4.11 部分参数应用函数
如果函数传递所有预期的参数,则表示已完全应用它。 如果只传递几个参数并不是全部参数,那么将返回部分应用的函数。这样就可以方便地绑定一些参数,其余的参数可稍后填写补上。

五、Scala面向对象
5.1 类的定义和使用
plus:占位符_ 的使用【不能使用val】

例子演示:
object Test1 {
def main(args: Array[String]): Unit = {
//创建Person对象
val person = new Person()
println(person.name + " " + person.age) //null 18
person.name = "小明"
//person.age = 19 报错 val age 不可变
println(person.name + " " + person.age) //小明 18
println(person.eat) //调用person的eat()方法 小明is eating
person.watchMovie("泰坦尼克号") //小明 is watching 泰坦尼克号
person.printInfo //调用person中的printInfo()方法 小明的性别是 male
// person.gender 报错 private [this] 所修饰的变量只能在其本类访问,故编译不通过s
}
}
//在scala中定义一个类
class Person{
//相当于书写了getter/setter(var)
var name : String = _ //占位符_ 必须为var,不能为val,否则报错 String占位符默认为null
//相当于书写了setter(val)
val age : Int = 18 //也可以写成 val age = 18
private [this] val gender = "male"
def printInfo: Unit ={
println(name + "的性别是 "+ gender) //private [this] 可以在本类Person中使用
}
//定义方法
def eat():String = {
name + "is eating"
}
def watchMovie(movieName : String) :Unit = {
println(name + " is watching " + movieName)
}
}
5.2 构造器【主构造器与附属构造器】
//scala构造器演示
object Constructor {
def main(args: Array[String]): Unit = {
val student = new Student("小明", 20)
println("姓名:" + student.name + " 年龄:" + student.age + " 职业:" + student.occupation) //姓名:小明 年龄:20 职业:学生
val student2 = new Student("张三", 21, "男")
println("姓名:" + student2.name + " 年龄:" + student2.age + " 职业:" + student2.occupation) //姓名:小明 年龄:20 职业:学生
}
}
//主构造器:紧跟在类后面的参数列表 val或var不可省略,否则第行student.属性(省略var或val的报错,无法访问)
//如果成员属性var修饰相当于对外提供getter/setter方法 val修饰相当于对外提供getter方法
class Student(val name: String, val age: Int) {
println("主构造器执行")
val occupation: String = "学生"
var gender: String = _
//附属构造器
def this(name: String, age: Int, gender: String) {
this(name, age) //附属构造器第一行代码必须调用主构造器或其他附属构造器
this.gender = gender
}
println("主构造器结束")
}运行结果:
主构造器执行
主构造器结束
姓名:小明 年龄:20 职业:学生
主构造器执行
主构造器结束
姓名:张三 年龄:21 职业:学生
私有主构造器,设置主构造器的访问权限【注意private是放在主构造器前面】
class Teacher private(var name: String, age: Int) {}私有附属构造器
class Teacher(var name: String, age: Int) {
var sex: String = _
//私有辅助构造器
private def this(name: String, age: Int, sex: String) = {
//在辅助构造器中必须先调用主构造器
this(name, age)
this.sex = sex
}
}类的成员属性访问权限:如果类的主构造器中成员属性是private修饰的,它的getter/setter方法都是私有的
class Teacher(private var name: String, age: Int) {
//...
}修饰类的访问权限,私有类private [this] class XXX
//类的前面加上private 标识这个类在当前包下都见,而且当前包下的子包不可见 默认private[this]
private[this] class Teacher(var name: String, val age: Int){}
//类的前面加上private[包名] 如private[itcats]表示这个类在itcats包及其子包下都可见
private[itcats] class Teacher(var name: String, val age: Int){}
5.3 继承与重写
继承:
在创建子类对象时候,首先会执行父类的构造方法
object Test2 {
def main(args: Array[String]): Unit = {
var an = new Bird("鹦鹉",2,"黑色")
println(an.name + " "+an.age + " "+ an.color)
}
}
//父类主构造器
class Animal(val name: String, val age: Int) {
println("Animal Constructor in")
println("Animal Constructor out")
}
//子类主构造
//这里需要注意,从父类继承过来的name,age,在子类主构造器中不需要写var/val , 而color没有继承过来,必须要写var/val
class Bird(name: String, age: Int, val color: String) extends Animal(name, age) {
println("Bird Constructor in")
println("Bird Constructor out")
}运行结果:
Animal Constructor in
Animal Constructor out
Bird Constructor in
Bird Constructor out
鹦鹉 2 黑色
重写:
对于父类已有的属性和方法,子类重写需要加上override关键字
//重写
object Test3 {
def main(args: Array[String]): Unit = {
var apple = new Apple("iPhone Xs",4999.9,"黑色")
println(apple.toString)
}
}
//父类主构造器
class Phone(var name: String, val price: Double) {
val country = "中国" //注意: 此处必须为val类型
}
//子类主构造
//这里需要注意,从父类继承过来的name,age,在子类主构造器中不需要写var/val , 而color没有继承过来,必须要写var/val
class Apple(name: String, price: Double, val color: String) extends Phone(name, price) {
//重写父类的name属性
override val country = "美国" //val country = "美国"报错,必须要加override关键字,并且必须为val 类型 否则将会显示mutable变量不可改变的错误
//重写toStirng()方法
override def toString() : String = {
"name = " + name +" , price = "+ price+" , "+"color = " +color+" , "+"country = " +country
}
}
输出结果:
name = iPhone Xs , price = 4999.9 , color = 黑色 , country = 美国
5.4 抽象类
抽象类使用abstract关键字修饰,且抽象类中[属性、方法]可以有具体的实现,也可以没有具体的实现,抽象类不能new
object AbstractTest {
def main(args: Array[String]): Unit = {
//抽象类不能被new new Plane() 报错
var boeing = new Boeing(); //可以new实现类 编译通过
}
}
/*
* 类的一个或者多个方法没有完整的实现(只有定义,没有实现)
*/
abstract class Plane {
def speak
val name: String
val age: Int
}
//创建Plane的实现类 即可以是class 也可以是object
class Boeing extends Plane {
override def speak: Unit = ??? // ???等同于 {}
override val name: String = "737" //使用IDEA提示生成的 override val name: String = _ 运行报错 unbound placeholder parameter
override val age: Int = 2 //override val age: Int = _ 报错unbound placeholder parameter
}关于抽象类与Trait的顺序问题
//先extends 后 with
class AbsClassImpl extends AbsClass with Trait1{} //这种是可以的,先继承抽象类,后with特质
class AbsClassImpl extends Trait1 with Abstract{} //这种是禁止的~~~
//在Scala中第一个继承抽象类或特质,只能先使用extends关键字
//如果想继承多个特质,在extends后面再使用with关键字
5.5 伴生类与伴生对象
在 Scala 中,是没有 static 这个东西的,但是它也为我们提供了单例模式的实现方法,那就是使用关键字 object。
Scala中的object对象也会被翻译为class字节码文件,但没办法new。
object中定义的成员变量和方法都是静态的
Scala 中使用单例模式时,除了定义的类之外,还要定义一个同名的 object 对象,它和类的区别是,object对象不能带参数。
类和它的伴生对象可以互相访问其私有成员方法和属性
伴生对象可以访问类中的私有方法private,不能访问private[this]修饰的成员变量即方法
object ApplyApp {
}
//伴生类与伴生对象
class ApplyTest{
}
object ApplyTest{
}如果有一个class,还有一个与之同名的object,那么就称这个object是是class的伴生对象,class是object的伴生类
其中class ApplyTest是object ApplyTest的伴生类,object ApplyTest是class ApplyTest的伴生对象。
5.6 apply
object ApplyApp {
def main(args: Array[String]): Unit = {
for (i <- 1 to 10) { //循环10次
ApplyTest.incr
}
println(ApplyTest.count) //10 object本身就是一个单例对象
}
}
//伴生类与伴生对象
class ApplyTest {}
object ApplyTest {
println("object ApplyTest start")
var count = 0
def incr: Unit = {
count = count + 1
}
println("object ApplyTest end")
}输出结果
object ApplyTest start
object ApplyTest end
10
面试高频考点:
object ApplyApp {
def main(args: Array[String]): Unit = {
//3.
val b = ApplyTest() //==>调用了object.apply()
//4.
println("------------分割线------------")
var c = new ApplyTest
println(c)
c() //==>调用了class.apply()
/*总结:
* 类名() ==> object.apply()
* 对象() ==> class.apply()
* 通常做法是在object中的apply()中最后一行new class
*/
}
}
//伴生类与伴生对象
class ApplyTest {
def apply(): Unit ={
println("class ApplyTest apply")
}
}
object ApplyTest {
println("object ApplyTest start")
//1.在object中书写一个apply()方法 注意此处apply()括号不可省略,否则ApplyTest()报错
def apply(): ApplyTest ={
println("object ApplyTest apply")
//2.在object中的apply()方法内new class
new ApplyTest
}
println("object ApplyTest end")
}
5.7 case class样例类和case object样例对象
//支持模式匹配
//样例类和样例对象默认实现了Serializable接口、Product接口
//通常用在模式匹配
object CaseClass {
def main(args: Array[String]): Unit = {
println(Language("English").name)
}
}
//特点case class不用new即可使用
case class Language(name : String){ //case class className {}没有参数是不允许的,但可以使用case class className() {}
}
//样例对象 样例类不能有属性
case object CaseObject
5.8 Trait
Scala Trait(特征) 相当于 Java 的接口,实际上它比接口还功能强大。
与接口不同的是,它还可以定义属性和方法的实现。
一般情况下Scala的类只能够继承单一父类,但是如果是 Trait(特征) 的话就可以继承多个,从结果来看就是实现了多重继承。
如果特质中trait某个方法有具体的实现,在子类继承重写的时候必须使用override关键字
如果特质方法没有具体的实现,子类在实现的时候可以不加override关键字也可以加
Trait(特征) 定义的方式与类类似,但它使用的关键字是 trait,如下所示:
trait Equal {
def isEqual(x: Any): Boolean
def isNotEqual(x: Any): Boolean = !isEqual(x)
}以上Trait(特征)由两个方法组成:isEqual 和 isNotEqual。isEqual 方法没有定义方法的实现,isNotEqual定义了方法的实现。子类继承特征可以实现未被实现的方法。
一个类可以扩展多个特质使用with进行连接,如
trait xxx extends ATrait with BbTraitobject Person extends App{
//ScalaTrait为自定义的特质类
val student = new Student with ScalaTrait
//此时student对象就具有ScalaTrait的所有方法或属性
//在Scala中可以动态的混入特质
//可以with多个Trait
val student = new Student with ScalaTrait with STrait
}
//可以在定义的时候混入特质,也可以在创建对象的时候混入特质
object ScalaTraitImpl extends ScalaTrait with STrait{}总结:
1、类与对象都可以混入一个或多个特质
2、特质中可以定义有具体实现的方法和没有具体实现的方法
3、如果一个类或者一个对象(继承)混入了某一个特质,这个特质中有一个未被实现的方法A和一个已实现的方法B
这个类或对象必须实现这个没有实现的方法A,且可选择性的重写方法B,必须使用override关键字。
提问:Scala中特质trait与抽象类abstract的区别?
- 优先使用特质trait。一个类扩展多个特质trait是很方便的,但却只能扩展一个抽象类。
- 如果你需要构造函数参数,使用抽象类。因为抽象类可以定义带参数的构造函数,而特质不行。例如:
trait t(i: Int) {},参数i是非法的。
5.9 final关键字
与Java一致。
在父类中使用final关键字修饰的类,子类不能继承
在父类中使用final关键字修饰的变量,不能被修改/重新赋值
在父类中使用final关键字修饰的方法,子类不能重写
需要注意的一点是,final可以修饰abstract类,但是这么做没有意义。
5.10 type关键字
type的作用类似于别名
scala> type S = String
defined type alias S
scala> val str: S = "hello"
str: S = helloScala代码示例:
trait TypeDefined {
//约定一个type变量而不实现
type T
def myPrint(x: T): Unit = {
println(x)
}
}object TypeDefindImpl1 extends App with TypeDefined {
override type T = String
//可见,参数类型为String类型,特质种的 type t 起到的是一个约定作用
override def myPrint(x: String): Unit = {
println(x)
}
TypeDefindImpl1.myPrint("haha")
}
六 Scala集合
Scala 的集合有三大类:序列 Seq、集 Set、映射 Map,所有的集合都扩展自 Iterable 特质 在 Scala 中集合有可变(mutable)和不可变(immutable)两种类型,immutable 类型的集合 初始化后就不能改变了(注意与 val 修饰的变量进行区别)
可变集合是指:长度可变,内容可变
不可变集合是指:长度不可变,内容不可变
6.1 数组
不可变长数组[scala.collection.immutable] plus:Array是内容可变,但长度不可变的数组

object ArrayApp extends App {
//创建定长数组
//方式1 使用new Array[类型](数组长度方式)
val array1 = new Array[String](3);
array1.length //长度为3
array1(1) //获取数组中索引为1的元素
array1(1) = "haha" //将数组中索引为1的元素改为haha
//方式2:使用Array object中的apply(),底层帮我们new了Array,返回值类型为Array[T]
val b = Array("hadoop", "spark", "storm", "flink")
val c = Array(1,2,3,4,5)
c.sum
c.min
c.max
//将数组转换为一个字符串
c.mkString //12345
c.mkString(",") // 1,2,3,4,5
c.mkString("(",",",")") // (1,2,3,4,5)
}可变长数组[scala.collection.mutable] ArrayBuffer是内容可变,而且长度可变的数组
/**
* 可变长度的数组 ArrayBuffer
*/
object ArrayBufferApp {
def main(args: Array[String]): Unit = {
var c = scala.collection.mutable.ArrayBuffer[Int](1,2,3) //创建一个可变长度的数组ArrayBuffer
c += 4 //ArrayBuffer(1, 2, 3, 4)
c += (5,6,7) //ArrayBuffer(1, 2, 3, 4, 5, 6, 7)
c ++= Array(9,10) //ArrayBuffer(1, 2, 3, 4, 5, 6, 7, 9, 10)
c.insert(0,0) //def insert(index: Int ,elems: A*) 向index位置添加elems(可变) ArrayBuffer(0, 1, 2, 3, 4, 5, 6, 7, 9, 10)
c.remove(0,1) //def remove(n: Int,count: Int) 从索引为n开始,向后删除count个元素 ArrayBuffer(1, 2, 3, 4, 5, 6, 7, 9, 10)
c.trimEnd(4) //从尾巴开始删除4个元素 ArrayBuffer(1, 2, 3, 4, 5)
c.toArray //将可变数组ArrayBuffer转换为不可变数组Array
c.remove(1) //ArrayBuffer(1, 3, 4, 5)
//遍历方式1
for(ele <- c){
println(ele)
}
//遍历方式2,使用to Range Until
for(i <- 0 to c.length - 1) { //length = 4 c(0)、c(1)、c(2)、c(3)
print(c(i))
}
for(i <- Range(0,c.length)){ //i 0~3
print(c(i))
}
for(i <- 0.until(c.length)){ //i 0~3
print(c(i))
}
//如何将数组倒序输出呢?
for(i <- (0 until c.length).reverse){ //实际上反转了i的输出顺序
print(c(i))
}
}
}
6.2 List【有序可重复有索引的集合】
内容不可变长度不可变的List【注意var和val】
scala> var list = List(1,2,3)
list: List[Int] = List(1, 2, 3)
scala> list ++=List(4,5) //var指内存地址可变,生成新的List,list指向新的内存地址
scala> list
res20: List[Int] = List(1, 2, 3, 4, 5)
scala> val list1 = List(1,2,3)
list1: List[Int] = List(1, 2, 3)
scala> list1 ++= List(4,5)
<console>:13: error: value ++= is not a member of List[Int]
list1 ++= List(4,5)
Nil就是一个空的不可变的(immutable)的List


可见:List第一个元素为head,后面的元素都为tail

头 :: 尾 ,所以最后一条命令 4是head ,List(1,2,3)为tail。

scala> val list1 = List(1,2,3)
list1: List[Int] = List(1, 2, 3)
scala> (-1)::(0)::list1
res24: List[Int] = List(-1, 0, 1, 2, 3)
scala> list::List(5,6)
res25: List[Any] = List(List(1, 2, 3), 5, 6)
scala> list:::List(5,6)
res26: List[Int] = List(1, 2, 3, 5, 6)
内容可变长度可变的ListBuffer
object ListApp extends App {
val l = List(1,2,3,4,5) //底层是object List的apply()
//定义可变的List
val l1 = scala.collection.mutable.ListBuffer[Int]() //底层是apply() 所以()括号不能省略
l1 += 1 //ListBuffer(1)
l1 += (2,3,4) //ListBuffer(1, 2, 3, 4)
l1 ++= List(5,6) //ListBuffer(1, 2, 3, 4, 5, 6) ++= 相加的是List集合
l1 ++:(List(999)) //List[Int] = List(1, 2, 3, 4, 5, 6, 999)
l1.++: (List(0)) //ListBuffer(0, 1, 2, 3, 4, 5, 6)
//将0插入list1的前面生成新的list
val list1 = List(1,2,3)
val r1 = 0 :: list1
val r2 = list1.::(0)
val r3 = 0 +: list1
val r4 = list1.+:(0)
//在list1后面插入0
val r5 = list.:+(0)
//减少元素
l1 -= 3 //减去元素3 ListBuffer(1, 2, 4, 5, 6)
l1 -= (0,4,6) //没有0但不报错,没有就不减去0呗 ListBuffer(1, 2, 5)
l1 --= List(1,5) //ListBuffer(2)
l1.toList //转换为List(不可变长)
l1.toArray //转换为Array
l1.isEmpty
l1.head
l1.tail
l1.mkString("|") //使用|分割List中的每个元素,返回String
println(l1)
l1.count(x => x > 2) //l1.count(f: Int => Boolean) : Int 计算l1中大于2的值有多少个
l1.filter(x => x > 2) //返回值为List[Int] 返回集合中符合x > 2的元素集合
l1.slice(1,3) //从Index 1开始截取 到 Index 2(不包括3 方法签名是until)
l1.sum
//递归求和算法
def sum(nums : Int* ):Int = {
if(nums.length == 0){
0
}
else {
nums.head + sum(nums.tail:_*)
}
}
}排序:
scala> val words = List(("a",3),("b",2),("c",1))
words: List[(String, Int)] = List((a,3), (b,2), (c,1))
scala> words.sortBy(x => x._2)
res29: List[(String, Int)] = List((c,1), (b,2), (a,3))
scala> words.sortBy(x => - x._2)
res30: List[(String, Int)] = List((a,3), (b,2), (c,1))分组
scala> val list: List[Int] = List(1,2,3,4)
list: List[Int] = List(1, 2, 3, 4)
scala> list.grouped(2).toList //如果不toList的话是一个Iterator
res1: List[List[Int]] = List(List(1, 2), List(3, 4))
6.3 Set【无序不可重复无索引的集合】
可变Set collection.mutable.HashSet
scala> val hset = collection.mutable.HashSet(1,3,4)
hset: scala.collection.mutable.HashSet[Int] = Set(1, 3, 4)
scala> val set = Set(1,2,3,3)
set: scala.collection.immutable.Set[Int] = Set(1, 2, 3)
scala> hset.add(5)
res26: Boolean = true
scala> hset
res27: scala.collection.mutable.HashSet[Int] = Set(1, 5, 3, 4)
scala> hset.add(1)
res28: Boolean = false
scala> hset.remove(1)
res29: Boolean = true
scala> hset.remove(999)
res30: Boolean = false
scala> hset.-=(3)
res31: hset.type = Set(5, 4)
scala> hset ++ Set(0,9) //++ 原集合数值无变化
res33: scala.collection.mutable.HashSet[Int] = Set(0, 9, 5, 4)
scala> hset ++= Set(0,9) //++=原集合数据发生变化
res34: hset.type = Set(0, 9, 5, 4)不可变Set
scala> val set = collection.mutable.HashSet(1,3,4)
set: scala.collection.mutable.HashSet[Int] = Set(1, 3, 4)
6.4 Map
Map(映射)是一种可迭代的键值对(key/value)结构。
所有的值都可以通过键来获取。
Map 中的键都是唯一的。
Map 也叫哈希表(Hash tables)。
Map 有两种类型,可变与不可变,区别在于可变对象可以修改它,而不可变对象不可以。
默认情况下 Scala 使用不可变 Map。如果你需要使用可变集合,你需要显式的引入 import scala.collection.mutable.Map 类
在 Scala 中 你可以同时使用可变与不可变 Map,不可变的直接使用 Map,可变的使用 mutable.Map。以下实例演示了不可变 Map 的应用
// 空哈希表,键为字符串,值为整型
var A:Map[Char,Int] = Map()
// Map 键值对演示
val colors = Map("red" -> "#FF0000", "azure" -> "#F0FFFF")
// Map键值对演示2
val colors = Map[String,String]("red" -> "#FF0000", "azure" -> "#F0FFFF") 内容不可变,长度不可变Map
scala> val map = Map[String,String]("red" -> "#FF0000", "azure" -> "#F0FFFF")
map: scala.collection.immutable.Map[String,String] = Map(red -> #FF0000, azure -> #F0FFFF)
scala> map("red") = "xxx"
<console>:13: error: value update is not a member of scala.collection.immutable.Map[String,String]
map("red") = "xxx"内容可变,长度可变的scala.collection.mutable.HashMap
scala> val hmap = scala.collection.mutable.HashMap[String,Int]()
hmap: scala.collection.mutable.HashMap[String,Int] = Map()
scala> hmap.+=("a" -> 1)
res2: hmap.type = Map(a -> 1)添加元素
定义 Map 时,需要为键值对定义类型。如果需要添加 key-value 对,可以使用 + 号,如下所示:
A += ('I' -> 1)
A += ('J' -> 5)
A += ('K' -> 10)
A += ('L' -> 100)scala> hmap.put
override def put(key: String,value: Int): Option[Int]
scala> hmap.put("bb",8)
res3: Option[Int] = None
scala> hmap += (("xx",66)) //添加对偶元组
res9: hmap.type = Map(bb -> 8, a -> 1, age -> 100, name -> 100, xx -> 66)删除元素
scala> hmap
res10: scala.collection.mutable.HashMap[String,Int] = Map(bb -> 8, a -> 1, age -> 100, name -> 100, xx -> 66)
scala> hmap.remove("aa")
res11: Option[Int] = None
scala> hmap.remove("a")
res12: Option[Int] = Some(1)
scala> hmap
res13: scala.collection.mutable.HashMap[String,Int] = Map(bb -> 8, age -> 100, name -> 100, xx -> 66)
scala> hmap.-=("bb")
res14: hmap.type = Map(age -> 100, name -> 100, xx -> 66)获取元素
scala> hmap.-=("bb")
res14: hmap.type = Map(age -> 100, name -> 100, xx -> 66)
scala> hmap.get("age")
res16: Option[Int] = Some(100)
scala> hmap.get("age").get
res17: Int = 100
scala> hmap.get("bbb") //不存在bbb这个key 返回就是None对象
res18: Option[Int] = None
scala> hmap.get("bbb").get
java.util.NoSuchElementException: None.get
at scala.None$.get(Option.scala:347)
at scala.None$.get(Option.scala:345)
... 32 elided
scala> hmap.getOrElse("a",0)
res21: Int = 0
scala> hmap.getOrElse("age",0)
res22: Int = 100
Scala Map 有三个基本操作:
| 方法 | 描述 |
|---|---|
| keys | 返回 Map 所有的键(key) Set(key1,key2...) |
| values | 返回 Map 所有的值(value) MapLike(v1,v2...) |
| isEmpty | 在 Map 为空时返回true |
Map 合并:
object Test {
def main(args: Array[String]) {
val colors1 = Map("red" -> "#FF0000",
"azure" -> "#F0FFFF",
"peru" -> "#CD853F")
val colors2 = Map("blue" -> "#0033FF",
"yellow" -> "#FFFF00",
"red" -> "#FF0000")
// ++ 作为运算符
var colors = colors1 ++ colors2
println( "colors1 ++ colors2 : " + colors )
// ++ 作为方法
colors = colors1.++(colors2)
println( "colors1.++(colors2)) : " + colors )
}
}执行以上代码,输出结果为:
$ scalac Test.scala
$ scala Test
colors1 ++ colors2 : Map(blue -> #0033FF, azure -> #F0FFFF, peru -> #CD853F, yellow -> #FFFF00, red -> #FF0000)
colors1.++(colors2)) : Map(blue -> #0033FF, azure -> #F0FFFF, peru -> #CD853F, yellow -> #FFFF00, red -> #FF0000)输出 Map 的 keys 和 values
object Test {
def main(args: Array[String]) {
val sites = Map("runoob" -> "http://www.runoob.com",
"baidu" -> "http://www.baidu.com",
"taobao" -> "http://www.taobao.com")
sites.keys.foreach{ i =>
print( "Key = " + i )
println(" Value = " + sites(i) )}
}
}执行以上代码,输出结果为:
$ scalac Test.scala
$ scala Test
Key = runoob Value = http://www.runoob.com
Key = baidu Value = http://www.baidu.com
Key = taobao Value = http://www.taobao.com
6.5 Option&Some&None
Scala 程序使用 Option 非常频繁,在 Java 中使用 null 来表示空值,代码中很多地方都要添加 null 关键字检测,不然很容易出现 NullPointException。因此 Java 程序需要关心那些变量可能是 null,而这些变量出现 null 的可能性很低,但一但出现,很难查出为什么出现 NullPointerException。
Scala 的 Option 类型可以避免这种情况,因此 Scala 应用推荐使用 Option 类型来代表一些可选值。使用 Option 类型,读者一眼就可以看出这种类型的值可能为 None。
Scala Option(选项)类型用来表示一个值是可选的(有值或无值)。
Option[T] 是一个类型为 T 的可选值的容器: 如果值存在, Option[T] 就是一个 Some[T] ,如果不存在, Option[T] 就是对象 None 。
// 虽然 Scala 可以不定义变量的类型,不过为了清楚些,我还是
// 把他显示的定义上了
val myMap: Map[String, String] = Map("key1" -> "value")
val value1: Option[String] = myMap.get("key1")
val value2: Option[String] = myMap.get("key2")
println(value1) // Some("value1")
println(value2) // None
//println(value2.get) //抛出异常 java.util.NoSuchElementException: None.get
println(value1.get) //value在上面的代码中,myMap 是一个 Key 的类型是 String,Value 的类型是 String 的 hash map,但不一样的是他的 get() 返回的是一个叫 Option[String] 的类别。
Scala 使用 Option[String] 来告诉你:「我会想办法回传一个 String,但也可能没有 String 给你」。
myMap 里并没有 key2 这笔数据,get() 方法返回 None。
Option 有两个子类别,一个是 Some,一个是 None,当他回传 Some 的时候,代表这个函式成功地给了你一个 String,而你可以透过 get() 这个函式拿到那个 String,如果他返回的是 None,则代表没有字符串可以给你。
getOrElse() 方法【没有值就给默认值,避免抛出异常】
你可以使用 getOrElse() 方法来获取元组中存在的元素或者使用其默认的值,实例如下:
object Test {
def main(args: Array[String]) {
val a:Option[Int] = Some(5)
val b:Option[Int] = None
println("a.getOrElse(0): " + a.getOrElse(0) )
println("b.getOrElse(10): " + b.getOrElse(10) )
}
}执行以上代码,输出结果为:
$ scalac Test.scala
$ scala Test
a.getOrElse(0): 5
b.getOrElse(10): 10
isEmpty() 方法
你可以使用 isEmpty() 方法来检测元组中的元素是否为 None,实例如下:
object Test {
def main(args: Array[String]) {
val a:Option[Int] = Some(5)
val b:Option[Int] = None
println("a.isEmpty: " + a.isEmpty )
println("b.isEmpty: " + b.isEmpty )
}
}执行以上代码,输出结果为:
$ scalac Test.scala
$ scala Test
a.isEmpty: false
b.isEmpty: true
6.6 Tuple(Scala 元组)
与列表一样,元组也是不可变的,但与列表不同的是元组可以包含不同类型的元素。
元组的值是通过将单个的值包含在圆括号中构成的。例如:
val t = (1, 3.14, "Fred") 以上实例在元组中定义了三个元素,对应的类型分别为[Int, Double, java.lang.String]。
此外我们也可以使用以下方式来定义:
val t = new Tuple3(1, 3.14, "Fred")元组的实际类型取决于它的元素的类型,比如 (99, "runoob") 是 Tuple2[Int, String]。 ('u', 'r', "the", 1, 4, "me") 为 Tuple6[Char, Char, String, Int, Int, String]。
目前 Scala 支持的元组最大长度为 22。对于更大长度你可以使用集合,或者扩展元组。
访问元组的元素可以通过数字索引,如下一个元组:
val t = (4,3,2,1)我们可以使用 t._1 访问第一个元素, t._2 访问第二个元素,如下所示:
object Test {
def main(args: Array[String]) {
val t = (4,3,2,1)
val sum = t._1 + t._2 + t._3 + t._4
println( "元素之和为: " + sum )
}
}$ scalac Test.scala
$ scala Test
元素之和为: 10迭代元组
你可以使用 Tuple.productIterator() 方法来迭代输出元组的所有元素:
object Test {
def main(args: Array[String]) {
val t = (4,3,2,1)
t.productIterator.foreach{ i =>println("Value = " + i )}
}
}$ scalac Test.scala
$ scala Test
Value = 4
Value = 3
Value = 2
Value = 1scala> val tuple = (1,true,"xx",Unit)
tuple: (Int, Boolean, String, Unit.type) = (1,true,xx,object scala.Unit)
scala> tuple.productIterator.toList
res24: List[Any] = List(1, true, xx, object scala.Unit)
scala> tuple.productIterator.foreach(println)
1
true
xx
object scala.Unit
元组转为字符串
你可以使用 Tuple.toString() 方法将元组的所有元素组合成一个字符串,实例如下:
object Test {
def main(args: Array[String]) {
val t = new Tuple3(1, "hello", Console)
println("连接后的字符串为: " + t.toString() )
}
}执行以上代码,输出结果为:
$ scalac Test.scala
$ scala Test
连接后的字符串为: (1,hello,scala.Console$@4dd8dc3)元素交换【只适用于对偶元组】
你可以使用 Tuple.swap 方法来交换元组的元素。如下实例:
object Test {
def main(args: Array[String]) {
val t = new Tuple2("www.google.com", "www.runoob.com")
println("交换后的元组: " + t.swap )
}
}执行以上代码,输出结果为:
$ scalac Test.scala
$ scala Test
交换后的元组: (www.runoob.com,www.google.com)
6.7 Seq序列
不可变的序列 import scala.collection.immutable._
在 scala 中列表要么为空(Nil 表示空列表)要么是一个 head 元素加上一个 tail 列表。9 :: List(5, 2) :: 操作符是将给定的头和尾创建一个新的列表
scala> Nil
res0: scala.collection.immutable.Nil.type = List()
scala> val list = List(1,2,3,4)
list: List[Int] = List(1, 2, 3, 4)
scala> list.head
res1: Int = 1
scala> list.tail
res2: List[Int] = List(2, 3, 4)
scala> 100::Nil
res3: List[Int] = List(100)
scala> var list = Nil
list: scala.collection.immutable.Nil.type = List()
scala> var list1 = List(1)
list1: List[Int] = List(1)
scala> list1.::(list)
res5: List[Any] = List(List(), 1)
scala> 1::2::3::Nil
res6: List[Int] = List(1, 2, 3)
6.8 并行化集合
val list = List(1,2,3,4,5)
list.par.fold(0)(_+_)
list.par.foldLeft(0)(_+_)
list.par.aggregate()
七 Scala模式匹配
7.1 基本数据类型的模式匹配
object BaseMatch {
val a: Array[String] = Array("a,", "b", "c", "d")
val name: String = a(Random.nextInt(a.length))
name match {
case "a" => println("This is a")
case "b" => println("This is b")
case "c" => println("This is c")
case "d" => println("This is d")
case _ => println("Can not find it")
}
def matchMethod(num : Int) :String = num match {
case 1 => "This is a"
case 2 => "This is b"
case 3 => "This is c"
case 4 => "This is d"
case 4 => "This is e"
case _ => "Can not fiSnd it"
}
def main(str: Array[String]): Unit = {
//一旦匹配上就直接退出模式匹配
matchMethod(4) //返回是"This is d"
}
}
7.1.1 条件过滤
object BaseMatch extends App {
print(matchMethod("haha",4)) //This is d
def matchMethod(keyword: String, num: Int): String = num match {
case 1 => "This is a"
case 2 => "This is b"
case 3 => "This is c"
case 4 if (keyword == "haha") => "This is d"
case _ => "Can not fiSnd it"
}
}
7.2 Array模式匹配
def who(arr : Array[String]): Unit = arr match {
//只匹配数组中含有一个"zhangsan"的case
case Array("zhangsan") => println("This is zhangsan")
case Array("zhangsan","lisi") => println("This is zhangsan and lisi")
//匹配数组中只含三个元素的case(对元素没有要求)
case Array(x,y,z) => println("This is x,y,z")
//匹配第一个为wangwu,后可有可无任意多个元素的case
case Array("wangwu",_*) => println("This is wangwu and others")
case _ => println("who is it?")
}
7.3 List模式匹配
与Array的模式匹配十分相似
def whoList(list : List[String]): Unit = list match {
//只匹配数组中含有一个"zhangsan"的case
case "zhangsan"::Nil => println("This is zhangsan")
case "zhangsan"::"lisi"::Nil => println("This is zhangsan and lisi")
//匹配数组中只含三个元素的case(对元素没有要求)
case x::y::z::Nil => println("This is x,y,z")
//匹配第一个为wangwu,后可有可无任意多个元素的case
case "wangwu"::tail => println("This is wangwu and others")
case m :: n => println("匹配拥有head,tail的List集合")
case _ => println("who is it?")
}
7.4 Scala异常处理【catch中类型模式匹配】
//Scala中的异常处理
object MyException extends App {
try{
val i = 1 / 0; //制造异常
}catch {
case e:ArithmeticException => println("除数不能为0")
case e:Exception => println("出现了未知异常")
}finally {
println("关闭资源处理")
}
}
7.5 case class模式匹配
object CaseClassMatch extends App {
def caseMatch(plane : Plane): Unit = plane match {
case Boeing(name: String, age: Int) => println("This is boeing 787 , age is 2")
case Airbus(name: String, age: Double) => println("This is airbus 330 , age is 0.8")
case Other(name: String, age: Int) => println("This is 战斗机 , age is 7")
}
caseMatch(Boeing("播音787",2))
caseMatch(Airbus("空客330",0.8))
caseMatch(Other("战斗机",7))
}
class Plane
case class Boeing(name: String, age: Int) extends Plane {}
case class Airbus(name: String, age: Double) extends Plane {}
case class Other(name: String, age: Int) extends Plane {}
7.6 Some&None模式匹配
操作map中的数据,需要频繁地调用get方法
object TestOption {
def main(args: Array[String]): Unit = {
val bigDataSkills =
Map("Java" -> "first",
"Hadoop" -> "second",
"Spark" -> "third",
"storm" -> "forth",
"hbase" -> "fifth",
"hive" -> "sixth",
"photoshop" -> null)
println(bigDataSkills.get("Java") == Some("first"))
println(bigDataSkills.get("photoshop").get == null)
println(bigDataSkills.get("Spark").get == "third")
println(bigDataSkills.get("abc123") == None)
}
}
2、通过模式匹配操作map中的数据,这是一个非常函数化的概念,它允许有效地 “启用” 类型和/或值,更不用说在定义中将值绑定到变量、在 Some() 和 None 之间切换,以及提取 Some 的值(而不需要调用麻烦的 get() 方法)。
object TestOption2 {
def main(args: Array[String]): Unit = {
val bigDataSkills =
Map("Java" -> "first",
"Hadoop" -> "second",
"Spark" -> "third",
"storm" -> "forth",
"hbase" -> "fifth",
"hive" -> "sixth",
"photoshop" -> null)
def show(value: Option[String]) =
{
value match {
case Some(a) => a
case None => "No this Skill"
}
}
println(show(bigDataSkills.get("Java")) == "first")
println(show(bigDataSkills.get("photoshop")) == null)
println(show(bigDataSkills.get("Spark")) == "third")
println(show(bigDataSkills.get("abc123"))== "No this Skill")
}
}
7.7 数据类型模式匹配
//类型模式匹配
matchType(Map("haha" -> "hehe"))
def matchType(obj : Any): Unit = {
obj match{
case x:Int => println("Int")
case y:String => println("String")
case z:Map[_,_] => z.foreach(println)
case _ => println("unkown")
}
}
7.8 对象匹配
//匹配对象
def objectCaseMatch(obj: Any) = obj match {
case SendHeartBeat(x,y) => println(s"$x $y") //只能匹配样例类
case CheckTimeOutWorker => println("This is CheckTimeOutWorker") //可以匹配对象或样例对象
case "registerWorker" => println("registerWorker")
}
case class SendHeartBeat(id: String, time: Long)
case object CheckTimeOutWorker
八 Scala函数的高级操作
8.1 字符串的高级操作
8.1.1 插值和多行
object StringApi extends App {
val name = "itcats_cn"
val job = "student"
val age = 999.999d
//普通输出 加了, 会自动产生一个()
println("name=" + name, "job=" + job) //输出结果 (name=itcats_cn,job=student)
// 文字'f'插值器允许创建一个格式化的字符串,类似于 C 语言中的 printf。
// 在使用'f'插值器时,所有变量引用都应该是 printf 样式格式说明符,如%d,%i,%f 等。
println(f"姓名: $name%s 年龄: $age%1.2f 职业: $job") // 该行输出有换行
printf("姓名: %s 年龄: %1.2f 职业: %s", name, age, job) // 该行输出没有换行
// 's'允许在处理字符串时直接使用变量。
// 在println语句中将String变量($name)附加到普通字符串中。
println()
println(s"姓名: ${name} 年龄: $age 职业: $job") //可以{}也可以不{}
// 字符串插入器还可以处理任意表达式。
// 使用's'字符串插入器处理具有任意表达式(${1 + 1})的字符串(1 + 1)的以下代码片段。 任何表达式都可以嵌入到${}中。
println(s"1 + 1 = ${1 + 1}") // 1 + 1 = 2
//多行字符串演示(连续输入三个"后按回车)
val c =
"""
|Hello
|World
""".stripMargin
println(c)
}
8.2 匿名函数
//匿名函数:函数是可以命名也可以匿名的
object AnonymityApp extends App {
//命名函数定义
def hello(name: String): Unit = {
println(s"Hello : $name")
}
//匿名函数可以传递给变量
val f = (name:String) => println(s"Hello : $name")
//也可以传递给函数
def an = (name:String) => println(s"Hello : $name")
//调用
hello("a")
f("b")
an("c")
}
8.3 curry函数
object CurryApp extends App {
//curry函数:将原来接收两个参数的一个函数,转换成2个
//原函数写法
def sum(a: Double, b: Double): Double = {
a + b
}
//curry函数
def currySum(a: Double)(b: Double): Double = {
a + b
}
//柯里化的演变过程
def add(x: Int) = (y: Int) => x + y //(y: Int) => x + y 为一个匿名函数,
//也就意味着 add 方法的返回值为一个匿名函数
//高阶函数,方法的参数是函数或方法的返回值是函数的函数
//调用
println( sum(1,1) )
println( currySum(1)(1) )
}
8.4 高阶函数【重点掌握】
object HighLevelFunction extends App {
val l = List(1, 2, 3, 4, 5)
//1.map 逐个操作集合里面的每个元素 实际上是建立一种映射关系,返回的是一个新的数组
l.map((x: Int) => x + 1) //将List内的每个元素(x:Int) + 1
l.map(x => x + 1) //scala能帮我们推断出List内每个元素是Int,且只有一个元素时候,括号可以省略
l.map(_ + 1) //对List中的任意元素都 + 1
//遍历
l.map(_ + 1).foreach(print) //23456 List[Int]
println()
println("-------------")
//2.在map取出每个元素 + 1的基础上,使用filter过滤出 < 4的数字
l.map(_ + 1).filter(_ < 4).foreach(print) //23 List[Int]
println()
println("-------------")
//3.使用take取集合中的前3个元素
l.take(3).foreach(print) //123 List[Int]
println()
println("-------------")
//4.reduce
print( l.reduce(_ + _) ) //15 Int 将l集合中的前后元素两两相加 1+2 3+3 6+4 10+5
println()
println("-------------")
//5.reduceLeft = reduce
print( l.reduceLeft(_ - _) ) //-13 1 - 2 - 3 - 4 - 5 = -13
println()
println("-------------")
//6.reduceRight
print( l.reduceRight(_ - _) ) //3 ( 1 - ( 2 - ( 3 - ( 4 - 5 ))))
println()
println("-------------")
//7.fold(第一个括号代表初始值)
print( l.fold(0)(_ - _) ) //-15 0-1-2-3-4-5 = -15
println()
println("-------------")
//8.foldLeft = fold (0在最左边)
print( l.foldLeft(0)(_ - _)) //-15 0-1-2-3-4-5 = -15
println()
println("-------------")
//9.foldRight (0在最右边)
print( l.foldRight(0)(_ - _) ) //3 ( 1 - ( 2 - ( 3 - ( 4 - (5 - 0) ) ) ) )
println()
println("-------------")
//10.flatten
val f = List(List(1,2),List(3,4),List(5,6)) //List内部是一个List类型的元祖
print(f.flatten) //flatten可以理解为压扁 List(1, 2, 3, 4, 5, 6)
//11.flatMap(可以理解为map + flatten)
println()
println("-------------")
//先来看一个例子,将f中List元祖都扩大两倍(使用map) 第一次使用map取出来的是List(x,y) 第二次用map取出来的是(x,y)
print(f.map(_.map(_ * 2))) //List(List(2, 4), List(6, 8), List(10, 12))
println()
println("-------------")
//flatMap所实现的效果是 List(2, 4, 6, 8, 10, 12)
print(f.flatMap(_.map(_ * 2)))
println()
println("-------------")
//12.flatMap的一些应用
val t = List("hello,hello,world,hello")
// t.flatMap(_.split(",")) List(hello, hello, world, hello)
t.flatMap(_.split(",")).map(x => (x,1)).foreach(println)
/**
* 输出:
* (hello,1)
(hello,1)
(world,1)
(hello,1)
*/
}并行聚合
def aggregate[B](z: =>B)(seqop: (B, A) => B, combop: (B, B) => B): B = foldLeft(z)(seqop)scala> list.aggregate
def aggregate[B](z: => B)(seqop: (B, Int) => B,combop: (B, B) => B): B
scala> list.aggregate(0)(_ + _ , _ + _)
res6: Int = 10并集union 【返回一个新的集合】
scala> list
res7: List[Int] = List(1, 2, 3, 4)
scala> val list1 = List(1,6)
list1: List[Int] = List(1, 6)
scala> list.union(list1)
res20: List[Int] = List(1, 2, 3, 4, 1, 6)交集intersect
scala> list.intersect(list1)
res21: List[Int] = List(1)差集diff
scala> list.diff(list1)
res22: List[Int] = List(2, 3, 4)角标元素合并组合成元组zip
scala> list
res23: List[Int] = List(1, 2, 3, 4)
scala> list1
res24: List[Int] = List(1, 6)
scala> list.zip(list1)
res25: List[(Int, Int)] = List((1,1), (2,6))
8.5 偏函数
被包在花括号内没有match的一组case语句
//演示偏函数 被包在花括号内没有match的一组case语句
object PartialFunctionApp extends App {
//正常的match..case匹配
def baseMatch(name : String): Unit = name match{
case "zhangsan" => "This is zhangsan"
case "lisi" => "This is lisi"
case _ => "I don't know who is it"
}
/*
* 使用偏函数 def functionName:PartialFunction[入参类型,返回参数类型] = {
* case "case1" => "return1"
* case "case2" => "return2"
* case _ => "return3"
* }
*/
def partialFunction:PartialFunction[String,String] = {
case "zhangsan" => "This is zhangsan"
case "lisi" => "This is lisi"
case _ => "I don't know who is it"
}
//调用 传递入参即可
println(partialFunction("zhangsan")) //This is zhangsan
}
九 Scala中隐式(implicit)详解
为已存在的类添加一个新的方法,在Scala中通常使用隐式转换解决
Scala中隐式类型转换的初体验。
scala> val a: Int = 3.14
<console>:11: error: type mismatch;
found : Double(3.14)
required: Int
val a: Int = 3.14
^
scala> implicit def doubleToInt(d: Double) = d.toInt
warning: there was one feature warning; re-run with -feature for details
doubleToInt: (d: Double)Int
scala> val a: Int = 3.14
a: Int = 3在Scala中有一个很重要的类Predef,内部定义了大量的隐式转换,如下为自动的装箱操作:
implicit def int2Integer(x: Int) = java.lang.Integer.valueOf(x)可以在scala控制台中输入:
scala> :implicit -v将返回Predef对象中69条的隐式转换 /* 69 implicit members imported from scala.Predef */
implicit可以分为:
- 隐式参数
- 隐式转换类型
- 隐式类
9.1 隐式参数
指的是在函数或者方法中,定义一个用implicit修饰的参数,此时Scala会尝试找到一个指定类型的,用implicit修饰的对象,即隐式值,并注入参数
//隐式参数
object ImplicitParam extends App {
implicit val c: Int = 100
//柯里化函数,scala中很多方法/函数都用到了implicit参数,不需要所有柯里化的参数都传递
def sum(a: Int)(implicit b: Int) = a + b
def implicitTest(implicit name: String): Unit = {
println(s"Hello : $name")
}
/**implicitTest所定义的参数是隐式参数,在调用该方法时如果没有传递参数,那么编译器在编译时期会从上下文找一个隐式参数值
* 需要注意的是 隐式参数的类型需要符合方法的入参类型
*/
implicit val name: String = "zhangsan"
//implicit val s: String = "s" 输出结果 : Hello : s
//如果同时书写两个implicit参数,在调用方法时候不传递,则会报错,因为不知道调用哪个参数
implicitTest //不传递参数,但结果为 : Hello : zhangsan
sayHello //Hello World
println(sum(1)) //101
}发现map方法的签名为一个柯里化函数,其中就包含了一个implicit参数,所以我们在使用map方法时一般只传递了一个参数。
final override def map[B, That](f: Int => B)(implicit bf: scala.collection.generic.CanBuildFrom[List[Int],B,That]): That
def map[B](f: Int => B): scala.collection.TraversableOnce[B]
需要注意的是,implicit需要放在参数的末尾,如果方法的参数有多个隐式参数,只需要使用一个implicit关键字即可
def addPlus(a: Int)(implicit b: Int, c: Int) = a + b + c
9.2 隐式类型转换
object ScalaImplicit {
def sum(a: Int)(implicit b: Int) = a + b
def addPlus(a: Int)(implicit b: Int, c: Int) = a + b + c
//定义一个隐式的方法
implicit def doubleToInt(double: Double) = {
println("doubleToInt")
double.toInt
}
//定义一个隐式的函数
implicit val fdoubleToInt = (double: Double) => {
println("fdoubleToInt")
double.toInt
}
def main(args: Array[String]): Unit = {
println("-------隐式类型转换-------")
val age: Int = 20.5 //fdoubleToInt 先找函数 后找方法
println(age) //20
}
}隐式转换切面封装
创建一个ImplicitAspect类,将隐式转换语句拷贝到该类,最后再import ImplicitAspect._
//隐式转换
object ImplicitApp extends App {
//普通人只有吃的方法,那么如何将超人飞的方法添加到普通人上呢? ————使用隐式转换
//套路 implicit def functionName(需要增强的类类型) : 返回含有增强方法的类类型 = new 含有增强方法的类()
implicit def manTosuperMan(man:Man) : SuperMan = new SuperMan(man.name)
//创建被增强对象
var man = new Man("普通人");
//发现man已包含了fly()方法
println( man.fly ) //superman[普通人] can fly
}
//普通人只会吃
class Man(val name:String){
def eat(): Unit ={
println(s"Man[$name] only can eat")
}
}
//超人会飞
class SuperMan(val name:String){
def fly(): Unit ={
println(s"superman[$name] can fly")
}
}File类中内置的方法不能返回文件信息的行数,通过定义MyFile类增强方法,并使用implicit关键字使File可以自动转换为RichFile类,那么File类就"新增"了返回文件信息的行数的方法
import java.io.{BufferedReader, File, FileReader}
class RichFile(val file: File){
def count(): Int = {
val fileReader = new FileReader(file)
val bufferReader = new BufferedReader(fileReader)
var sum = 0
try {
var line = bufferReader.readLine()
while (line != null) {
sum += 1
line = bufferReader.readLine()
}
} catch {
case _: Exception => 0
} finally {
bufferReader.close()
fileReader.close()
}
sum
}
}
object FileToRichFile {
//隐式类型转换,达到增强File类中方法的效果
//定义了一个隐式方法,将File类型变成RichFile类型
implicit def fileToRichFile(file: File) = new RichFile(file)
def main(args: Array[String]): Unit = {
val file = new File("/Users/fatah/Desktop/20170815/part-m-00000")
println(file.count)
}
}
9.3 隐式类
隐式类只能在object静态对象中使用,不能在class类中使用
使用隐式类增强File中的方法,实现使用的read()方法一次性读取文件的所有内容
import java.io.File
import scala.io.Source
//隐式类 --只能在静态对象中使用
object ScalaImplicitClass {
//因为包含在object内,所以不会报错 隐式类
implicit class FileRead(file: File){
def read() = Source.fromFile(file).mkString
}
def main(args: Array[String]): Unit = {
val file = new File("/Users/fatah/Desktop/20170815/part-m-00000")
/**
* 发现read()包含下划线,所有隐式转换的地方都会有下划线
* File类并没有内置的read方法实际上调用的是FileRead类的read方法
* 只不过隐式转换对用户是不可见的,内部发生的
*/
println("内容为:" + file.read())
}
}
十 Scala操作外部数据
包括文件、网络数据、MySQL、XML等外部数据
10.1 操作文件/网络资源
//使用scala操作File文件
object FileTest {
def main(args: Array[String]): Unit = {
//读取文件
var file = scala.io.Source.fromFile("/Users/fatah/Desktop/1.txt")(scala.io.Codec.UTF8);
//var file = scala.io.Source.fromFile("/Users/fatah/Desktop/1.txt");
def readLine(): Unit = {
for (line <- file.getLines()) {
println(line)
}
}
//调用读取文件资源
//readLine
//调用读取网络资源
readNet
//读取网络数据
def readNet(): Unit ={
var file = scala.io.Source.fromURL("https://www.baidu.com");
for(line <- file.getLines()){
println(line)
}
}
}
}
10.2 操作XML
//方式1
var xml1 = XML.load(this.getClass.getClassLoader().getResource("test.xml"))
//方式2
val xml2 = XML.load(new FileInputStream("/Users/fatah/Desktop/Java开发工具/workspace/myscala/src/main/resources/test.xml"))
println(xml1)解析XML
Scala XML API提供了类似XPath的语法来解析XML。在NodeSeq这类父类里,定义了两个很重要的操作符("\"和"\\"),用来获得解析XML:
在resources下创建test.xml
- \ :Projection function, which returns elements of this sequence based on the string that--简单来说,\ 根据条件搜索下一子节点
- \\:Projection function, which returns elements of this sequence and of all its subsequences, based on the string that--而 \\ 则是根据条件搜索所有的子节点
<fix major="4" minor="2">
<header>
<field name="BeginString" required="Y">FIX4.2</field>
<field name="MsgType" required="Y">Test</field>
</header>
<trailer>
<field name="Signature" required="N"/>
<field name="CheckSum" required="Y"/>
</trailer>
<messages>
<message name="Logon" msgtype="A" msgcat="admin">
<field name="ResetSeqNumFlag" required="N"/>
<field name="MaxMessageSize" required="N"/>
<group name="NoMsgTypes" required="N">
<field name="RefMsgType" required="N"/>
<field name="MsgDirection" required="N"/>
</group>
</message>
<message name="ResendRequest" msgtype="2" msgcat="admin">
<field name="BeginSeqNo" required="Y"/>
<field name="EndSeqNo" required="Y"/>
</message>
</messages>
<fields>
<field number="1" name="TradingEntityId" type="STRING"/>
<field number="4" name="AdvSide" type="STRING">
<value enum="X" description="CROSS"/>
<value enum="T" description="TRADE"/>
</field>
<field number="5" name="AdvTransType" type="STRING">
<value enum="N" description="NEW"/>
</field>
</fields>
</fix>1. 首先来个简单的,如果要找header下的field,那么这样写即可:
val headerField = xml1 \"header"\"field" //xml1对应的是你之前读xml的变量名2.找所有的field:
val field = xml1 \\"field"3. 找特定的属性(attribute),如找header下的所有field的name属性的值:
val fieldAttributes = (xml1 \"header"\"field").map(_\"@name")
val fieldAttributes = xml1 \"header"\"field"\\"@name"两个都能找到header下面所有field的name属性,但问题是输出的格式不一样。前者会返回一个List-List(BeginString, MsgType),而后者仅仅是BeginStringMsgType。中间连空格也没有。所以建议用前一种方法获得属性。
之前以为,下面的方法,和第二种方法一样能够获得属性的值:
val fieldAttributes = xml1 \"header"\"field"\"@name"根据\操作符的定义,理论上应该可以输出name属性的。实际上输出的结果是空,什么也没有。
\操作符的源码里有这么一段:
that match {
case "" => fail
case "_" => makeSeq(!_.isAtom)
case _ if (that(0) == '@' && this.length == 1) => atResult
case _ => makeSeq(_.label == that)
}第三个case表面,只有当this.length==1时,才可以这样做。原因其实很简单,somXml\"header"\"field"返回的是一个Seq[Node]的集合,包含多个对象。而\"@"的操作无法确定操作哪一个对象的属性:
val x = <b><h id="bla"/><h id="blub"/></b>
val y = <b><h id="bla"/></b>
println(x\\"h"\"@id") //Wrong
println(y\\"h"\"@id") //Correct with output: bla4. 查找并输出属性值和节点值的映射:
(xml1 \"header"\"field").map(n=>(n\"@name", n.text, n\"@required"))这样的输出是List((BeginString,FIX4.2,Y), (MsgType,Test,Y))
5. 有条件地查找节点,例如查找name=Logon的message:
val resultXml1 = (xml1 \\"message").filter(_.attribute("name").exists(_.text.equals("Logon")))
val resultXml2 = (xml1 \\"message").filter(x=>((x\"@name").text)=="Logon")6. 通过 \\"_" 获得所有的子节点,例如:
println(resultXml1\\"_")<message msgcat="admin" msgtype="A" name="Logon">
<field required="N" name="ResetSeqNumFlag"/>
<field required="N" name="MaxMessageSize"/>
<group required="N" name="NoMsgTypes">
<field required="N" name="RefMsgType"/>
<field required="N" name="MsgDirection"/>
</group>
</message>
<field required="N" name="ResetSeqNumFlag"/>
<field required="N" name="MaxMessageSize"/>
<group required="N" name="NoMsgTypes">
<field required="N" name="RefMsgType"/>
<field required="N" name="MsgDirection"/>
</group>
<field required="N" name="RefMsgType"/>
<field required="N" name="MsgDirection"/>
10.3 操作MySQL
//使用scala连接数据库,操作MySQL
object MySQLTest {
def main(args: Array[String]): Unit = {
//书写连接数据库相关信息
val url = "jdbc:mysql://localhost:3306/crash_course"
val username = "root"
val password = "root"
//在scala中这一步与Java的class.forName写法有所不同
try {
classOf[com.mysql.jdbc.Driver]
val conn = DriverManager.getConnection(url,username,password)
val sql = "select * from orders"
val stmt = conn.prepareStatement(sql)
val rs = stmt.executeQuery();
while(rs.next()){
val order_num = rs.getString("order_num")
val order_date = rs.getString("order_date")
val cust_id = rs.getString("cust_id")
println(s"$order_num , $order_date , $cust_id")
}
}catch {
case e : Exception => e.printStackTrace()
}finally {
//关闭资源,懒得关了,懂就行
}
}
}
十一 Scala中的泛型
11.1 泛型约束
import cn.itcats.GenericType.ShoesBrandEnum.ShoesBrandEnum
/**
* 泛型: 就是对类型的约束
*/
abstract class Message[C](content: C)
class StrMessage[String](content: String) extends Message
class IntMessage[Int](value: Int) extends Message
//定义一个衣服的泛型类
class Shoes[A, B, C](val brand: A, val color: B, val size: C)
//创建一个枚举类型
object ShoesBrandEnum extends Enumeration {
type ShoesBrandEnum = Value //声明枚举对外暴露的类型
val nike, adidas, skechers = Value
}
object ScalaGenericType {
def main(args: Array[String]): Unit = {
//创建几款鞋子
val type1 = new Shoes[ShoesBrandEnum, String, Int](ShoesBrandEnum.nike, "black", 42)
println(type1.brand) //nike
val type2 = new Shoes[ShoesBrandEnum, String, Double](ShoesBrandEnum.adidas, "white", 41.5)
println(type2.size) //41.5
}
}
11.2 上界与下界约束
Upper Bounds
在Java泛型里表示某个类型是List类型的子类型,使用extends关键字:
<T extends List>
//或者使用通配符的形式
<? extends List>这种形式叫做upper bounds(上限或上界),同样的意思在Scala中的写法为:
[T <: List]
//或者使用通配符
[_ <: List]
//例如: List中存储的是Any类型的子类
def getEleFromList(list: List[T <: Any]){
ele.foreach(print)
}Lower Bounds
在Java泛型里表示某个类型是Teacher类型的父类型,使用super关键字:
<T super Teacher>
//或者使用通配符
<? super Teacher>这种形式也叫lower bounds(下限或下界),同样的意思在Scala中的写法为:
[T >: Teacher]
[_ >: Teacher]例子:
//只支持Int类型的比较
class CmpInt(a: Int, b: Int) {
def bigger = if (a > b) a else b
}
//定义一个通用的比较器类
class CmpCommon[T <: Comparable[T]](t1: T, t2: T) {
def bigger = if (t1.compareTo(t2) > 0) t1 else t2
}
object UpperLowerBounds {
def main(args: Array[String]): Unit = {
val cmpInt = new CmpInt(5, 10)
println(cmpInt.bigger)
val cmpCommon = new CmpCommon[Integer](1, 2) //发生隐式转换
println(cmpCommon.bigger)
}
}
11.3 视图界定
视图界定会发生隐式转换
def method [A <% B](arglist): R = ...
//等价于:
def method [A](arglist)(implicit viewAB: A => B): R = ...
//或等价于:
implicit def conver(a:A): B = ...
// <% 除了方法使用之外,class 声明类型参数时也可使用: class A[T <% Int]//定义一个通用的比较器类 <% 和 >% 都是视图界定
class CmpCommon[T <% Comparable[T]](t1: T, t2: T) {
def bigger = if (t1.compareTo(t2) > 0) t1 else t2
}
object UpperLowerBounds {
def main(args: Array[String]): Unit = {
val cmpInt = new CmpInt(5, 10)
println(cmpInt.bigger)
val cmpCommon = new CmpCommon(1, 2) //视图界定发生隐式转换
println(cmpCommon.bigger)
}
}
视图界定+隐式转换的例子
//定义一个通用的比较器类 视图界定,可以自动隐式转换
class CmpCommon[T <% Comparable[T]](t1: T, t2: T) {
def bigger = if (t1.compareTo(t2) > 0) t1 else t2
}
//注意Student并没有显式地实现Ordered特质
class Student(val name: String, val age: Int){
override def toString = s"姓名: ${this.name} 年龄: ${this.age}"
}
object UpperLowerBounds {
def main(args: Array[String]): Unit = {
//发生隐式转换,在视图界定时候会自动扫描到该隐式转换,将Student类型转换为Ordered[Student]类型,使Student可比较
implicit def studentToOrderedStudent(stu: Student) = new Ordered[Student] {
override def compare(that: Student): Int = stu.age - that.age
}
val zhangsan = new Student("zhangsan",18)
val lisi = new Student("lisi",28)
val cmpStu = new CmpCommon[Student](zhangsan,lisi)
println(cmpStu.bigger)
}
}
11.4 上下文界定
也会发生隐式转换,实际上是视图界定的语法糖
class Student(val name: String, val age: Int) {
override def toString = s"姓名: ${this.name} 年龄: ${this.age}"
}
//上下文界定方式1
class CmpCommon[T: Ordering](t1: T, t2: T)(implicit cmptor: Ordering[T]) {
def bigger = if (cmptor.compare(t1, t2) > 0) t1 else t2
}
//上下文界定方式2
class CmpCommon2[T: Ordering](t1: T, t2: T){
def bigger = {
def inner(implicit cmptor: Ordering[T]) = cmptor.compare(t1,t2)
if(inner > 0) t1 else t2
}
}
//上下文界定方式3
class CmpCommon3[T: Ordering](t1: T,t2: T){
def bigger = {
val cmptor = implicitly[Ordering[T]]
if(cmptor.compare(t1,t2) > 0) t1 else t2
}
}
object UpperLowerBounds {
def main(args: Array[String]): Unit = {
//一个隐式对象实例 -> 一个有具体实现的Comparator
implicit val cmptor = new Ordering[Student] {
override def compare(x: Student, y: Student) = x.age - y.age
}
val zhangsan = new Student("zhangsan", 18)
val lisi = new Student("lisi", 28)
val cmpStu = new CmpCommon(zhangsan, lisi)
println(cmpStu.bigger)
}
}
十二 排序
Java中的排序
public class OrderApp {
public static void main(String[] args) {
Phone phone1 = new Phone("iPhone XS", 5555.55);
Phone phone2 = new Phone("HUAWEI P30", 5999.55);
Phone phone3 = new Phone("HUAWEI MATE30", 6299.55);
List<Phone> phones = new ArrayList<>();
phones.add(phone1); phones.add(phone2); phones.add(phone3);
//比较三款手机的价格 sort无返回值
Collections.sort(phones, new Comparator<Phone>() {
@Override
//按照降序排列 价格高的在前 价格低的在后
public int compare(Phone o1, Phone o2) {
if(o1.getPrice() > o2.getPrice())
return -1;
else if(o1.getPrice() < o2.getPrice())
return 1;
else return 0;
}
});
//使用foreach查看结果
phones.stream().forEach(x -> {
System.out.println(x.getBrand());
});
}
}Scala中的排序[与Java中的对应关系]
Java ---> Scala
Comparable ---> Ordered
Comparator ---> Orderingtrait Ordering[T] extends Comparator[T] with PartialOrdering[T] with Serializable {}trait Ordered[A] extends Any with java.lang.Comparable[A] {}object OrderedPhone extends App{
private val orderImpl = new OrderImpl[Ticket](new Ticket("欢乐谷",220),new Ticket("长隆",280))
println(orderImpl.smaller().name) //欢乐谷
println(orderImpl.bigger().name) //长隆
}
//泛型T 为 Ordered[T] 的子类
class OrderImpl[T <: Ordered[T]](val first: T, val second: T){
//比较的时候直接使用 < 符号 进行对象间的比较
//它最终调用的是 Ticket 中 compare 方法,来比较出两个值的大小
def smaller() = {
if(first < second) first else second //内置的 < 方法
}
def bigger() = {
if(first.>(second)) first else second //内置的 > 方法
}
}
class Ticket(val name: String, val price: Int) extends Ordered[Ticket]{
override def compare(that: Ticket) = {
this.price - that.price
}
}
十三 使用Scala编写WordCount
scala> var arr = Array("hello good nice bye","hello hi good bye")
arr: Array[String] = Array(hello good nice bye, hello hi good bye)
scala> arr.flatMap(x => x.split(" "))
res3: Array[String] = Array(hello, good, nice, bye, hello, hi, good, bye)
scala> arr.flatMap(x => x.split(" ")).groupBy(x => x)
res4: scala.collection.immutable.Map[String,Array[String]] = Map(bye -> Array(bye, bye), good -> Array(good, good), nice -> Array(nice), hi -> Array(hi), hello -> Array(hello, hello))
scala> arr.flatMap(x => x.split(" ")).groupBy(x => x).map(x => x._2)
res5: scala.collection.immutable.Iterable[Array[String]] = List(Array(bye, bye), Array(good, good), Array(nice), Array(hi), Array(hello, hello))
scala> arr.map(_.split(" ")).flatten.groupBy(x => x).map(yz => (yz._1, yz._2.length))
res6: scala.collection.immutable.Map[String,Int] = Map(bye -> 2, good -> 2, nice -> 1, hi -> 1, hello -> 2)
scala> arr.flatMap(x => x.split(" ")).groupBy(x => x).mapValues(x => x.length)
res7: scala.collection.immutable.Map[String,Int] = Map(bye -> 2, good -> 2, nice -> 1, hi -> 1, hello -> 2)
scala> var arr = Array("hello","itcats","hello","itcats_cn","hello","cn")
arr: Array[String] = Array(hello, itcats, hello, itcats_cn, hello, cn)
scala> arr.map((_,1))
res0: Array[(String, Int)] = Array((hello,1), (itcats,1), (hello,1), (itcats_cn,1), (hello,1), (cn,1))
scala> arr.map((_,1)).groupBy(_._1)
res1: scala.collection.immutable.Map[String,Array[(String, Int)]] = Map(itcats -> Array((itcats,1)), cn -> Array((cn,1)), itcats_cn -> Array((itcats_cn,1)), hello -> Array((hello,1), (hello,1), (hello,1)))
scala> arr.map((_,1)).groupBy(_._1).mapValues(_.length)
res2: scala.collection.immutable.Map[String,Int] = Map(itcats -> 1, cn -> 1, itcats_cn -> 1, hello -> 3)
scala> arr.map((_,1)).groupBy(_._1).mapValues(_.length).toList
res3: List[(String, Int)] = List((itcats,1), (cn,1), (itcats_cn,1), (hello,3))
scala> arr.map((_,1)).groupBy(_._1).mapValues(_.length).toList.sortBy(- _._2)
res4: List[(String, Int)] = List((hello,3), (itcats,1), (cn,1), (itcats_cn,1))
scala> arr
res10: Array[String] = Array(hello word hello java hello scala java, hello hi)
scala> arr.flatMap(_.split(" "))
res11: Array[String] = Array(hello, word, hello, java, hello, scala, java, hello, hi)
scala> arr.flatMap(_.split(" ")).map(x => (x,1))
res13: Array[(String, Int)] = Array((hello,1), (word,1), (hello,1), (java,1), (hello,1), (scala,1), (java,1), (hello,1), (hi,1))
scala> arr.flatMap(_.split(" ")).map(x => (x,1)).groupBy(_._1)
res14: scala.collection.immutable.Map[String,Array[(String, Int)]] = Map(java -> Array((java,1), (java,1)), scala -> Array((scala,1)), hi -> Array((hi,1)), hello -> Array((hello,1), (hello,1), (hello,1), (hello,1)), word -> Array((word,1)))
scala> arr.flatMap(_.split(" ")).map(x => (x,1)).groupBy(_._1).mapValues(t =>t.foldLeft(0)(_ + _._2))
res17: scala.collection.immutable.Map[String,Int] = Map(java -> 2, scala -> 1, hi -> 1, hello -> 4, word -> 1)
scala> arr.flatMap(_.split(" ")).map(x => (x,1)).groupBy(_._1).mapValues(t =>t.foldRight(0)(_._2 + _))
res18: scala.collection.immutable.Map[String,Int] = Map(java -> 2, scala -> 1, hi -> 1, hello -> 4, word -> 1)
Scala代码:
object WordCount extends App {
def wordCountApp(): Unit = {
var arr: Array[String] = Array.apply("hello good nice bye", "hello hi good bye")
var arr_arr: Array[Array[String]] = arr.map((str: String) => str.split(" "))
var flatArr: Array[String] = arr_arr.flatten
//Map[String,Array[String]] hello -> Array(hello,hello)
var groupMap: Map[String,Array[String]] = flatArr.groupBy((wd: String) => wd)
val yzRes: Map[String,Int] = groupMap.map(yz => (yz._1,yz._2.length))
//map结构中不能sort,需要转换为List
//toList后的结果 List[(String, Int)] = List((bye,2), (good,2), (nice,1), (hi,1), (hello,2))
val sortRes: List[(String,Int)] = yzRes.toList.sortBy(t => t._2)
sortRes.foreach(println)
}
wordCountApp()
}
可以借助spark-shell直接读取文件
scala> sc.textFile("/Users/fatah/Desktop/wc.txt").flatMap(_.split(" ")) 
scala> sc.textFile("/Users/fatah/Desktop/wc.txt").flatMap(_.split(" "))
res24: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[75] at flatMap at <console>:25
scala> sc.textFile("/Users/fatah/Desktop/wc.txt").flatMap(_.split(" ")).collect
res25: Array[String] = Array(hello, itcats, hello, itcats_cn, hello, cn)最终基于Spark的WordCount代码如下:
scala> sc.textFile("/root/w.txt").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









