






 文章讲述了360创始人周鸿祎如何利用直播、网红身份吸引关注,带货自家公司产品,包括参与迈巴赫拍卖。尽管他努力制造话题,但哪吒汽车的销量并未显著提升,引发了关于企业借助网红效应能否持久成功的讨论。
文章讲述了360创始人周鸿祎如何利用直播、网红身份吸引关注,带货自家公司产品,包括参与迈巴赫拍卖。尽管他努力制造话题,但哪吒汽车的销量并未显著提升,引发了关于企业借助网红效应能否持久成功的讨论。
最近半个月,有两个中年男人仿佛住进了热搜。
一个是刚刚辟谣自己“卡里没有冰冷的 40 亿”的雷军,另一个则是在今年年初就高呼“如果有可能,企业家都要去当网红”的 360 创始人周鸿祎。
他也确实做到了。

先是作为当年 3Q 大战的当事人,周鸿祎与马化腾在中国互联网 30 周年发展座谈会上握手笑谈,上演世纪大和解。
接着又在北京车展上爬上一辆越野车的车顶,成功抢镜。
最近更是直播拍卖自己的二手迈巴赫,要为新能源汽车博流量。根据最新消息,这辆起拍价 600 元、市场价 100 万元的二手车以 990 万元被拍下。
要整活还得看这些企业家,周老板制造话题的能力很多明星都望尘莫及。
「网红」的简历
让我们先通过一份简历,回顾一下这位“红衣主教”的风云过往。
在线查看:https://laoyujianli.com/share/zhouhongyi

可以看得出来,周鸿祎也不是最近受了雷军的启发,而是早就有一颗“网红心”。
一直以来,周鸿祎都是一个饱受争议的人。他的公司这些年来与阿里巴巴、腾讯、联想、小米等有影响力的互联网公司都过过招。
毕竟,周老板有过这样一句名言:“竞争对手就像磨刀石一样,它把我们磨得非常锋利,然后我们就手起刀落,把竞争对手给砍掉了。”
背后的暗流
抢话题、博关注、争流量,都是手段。最终的目的,还是为了带货。
除了雷军和周鸿祎,身价千亿的长城汽车董事长魏建军、哪吒汽车 CEO 张勇都开启了直播。小米集团的总裁卢伟冰、中国区副总裁许斐、Redmi 品牌总经理王腾、小米手机产品经理魏思琪等小米高管也纷纷开通个人抖音账号,一副要大干一场的架势。更不用提早就是车圈风云人物的蔚来汽车创始人李斌、理想汽车创始人李想。
大佬纷纷下场做网红、开直播,终究还是免费的流量香。
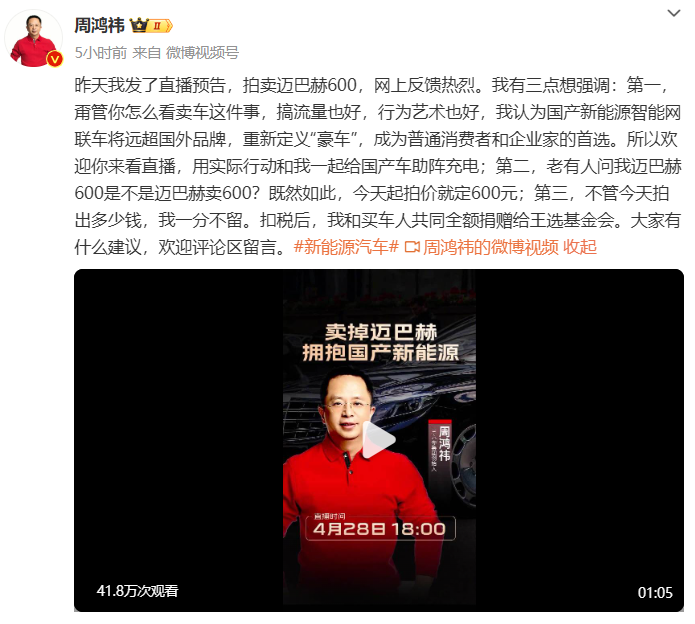
然而周鸿祎卖力吆喝了一圈,自己投资的哪吒汽车依然地位尴尬。热度上来了,但止于种草,还没能变成实打实的销量。
网红的滤镜之下,或许是一层真实的焦虑。能不能凭此奇招带领企业穿越周期?可以期待一下周老板后续的动作。
--完--
我们这个ChatGPT中文网站,终于支持联网了,支持最新的数据了,比如,我们来问问周鸿祎拍卖迈巴赫的事情:
可以在国内同ChatGPT直接进行对话,支持GPT4.0 和 AI绘图,简直太方便了,今天新注册的直接送4.0提问次数 !https://aigc.cxyquan.com感谢你的分享,点赞,在看三连 















 1760
1760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









