







数据的读取
torch.utils.data.Dataset
对Dataset的具体介绍
Dataset是一个抽象类,相比于自己写的迭代器,它可以方便地实现多线程读取,shuffle,batch操作
自定义一个类继承它,需要自己实现__getitem__ () len__(),写完之后,就可以对整个数据进行索引等操作
接下来就是用dataloader,进行batch_size的设置和shuffle操作
transform
对输入图片和标签进行预处理设置,做分割主要是把label先变为灰度图,然后再把每个像素进行one-hot编码
one-hot
先看看onehot长啥样
tensor([[0., 1., 0., 0.],
[0., 0., 1., 0.],
[1., 0., 0., 0.],
[0., 0., 0., 1.]])
制作流程
class onehot(object):
def __init__(self):
self.n_classes = 21
def __call__(self, image_tensor):
h, w = image_tensor.size()
onehot = torch.LongTensor(self.n_classes, h, w).zero_() 生成一个相同形状的全0 tensor
# print(onehot)
image_tensor = image_tensor.unsqueeze_(0)
onehot = onehot.scatter_(0, image_tensor, 1) 0指定纬度 用1填充
return onehot
u-net的代码实现
先进行下采样,再上采样
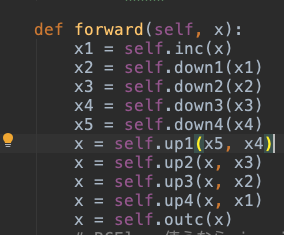
最后输出的格式为 batch_sizex224x224x21(假如图片大小为224x224,算上背景为21分类)
loss
loss的输入为 预测值:batch_sizex224x224x21(未做softmax,未做one-hot),label batch_sizex224x224x21(已做onehot), loss 做的工作是把预测值做softmax再做one-hot,再和label做交叉熵得出损失,最后在进行反向传播,更新权重。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









