





一、solr 的简介
Apache Solr 是一个开源的搜索服务器。Solr 使用 Java 语言开发,主要基于 HTTP 和 Apache Lucene 实现。Apache Solr 中存储的资源是以 Document 为对象进行存储的。每个文档由一系列的 Field 构成,每个 Field 表示资源的一个属性。Solr 中的每个 Document 需要有能唯一标识其自身的属性,默认情况下这个属性的名字是 id,在 Schema 配置文件中使用:<uniqueKey>id</uniqueKey>进行描述。
Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。文档通过Http利用XML加到一个搜索集合中。查询该集合也是通过 http收到一个XML/JSON响应来实现。它的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,高亮显示搜索结果,通过索引复制来提高可用性,提 供一套强大Data Schema来定义字段,类型和设置文本分析,提供基于Web的管理界面等。
二、solr 3.5 的下载
solr 3.5下载地址:http://www.apache.org/dist//lucene/solr/
tomcat tomcat-7.0.26 下载:http://mirror.bjtu.edu.cn/apache/tomcat/tomcat-7/v7.0.26/bin/apache-tomcat-7.0.26.zip
三、solr 3.5的安装
1、解压tomcat-7.0.26 到 e:\tomcat-7.0.26\下
2、打开tomcat-7.0.26\conf修改server.xml 文件
- <Connectorport="8080"protocol="HTTP/1.1"connectionTimeout="20000"redirectPort="8443"URIEncoding="UTF-8"/>
修改默认端口8080,可以不修改,添加字符编码 URIEncoding="UTF-8" 否则中文会乱码
3、在apache-solr-3.5.0\dist目录下找到apache-solr-3.5.0.war把重命名为solr.war 并上传到tomcat-7.0.26/webapps下。
4、创建一个solr.xml文件,
在tomcat-7.0.14\conf\Catalina\localhost\下创建一个solr.xml文件。内容为:
- <?xmlversion="1.0"encoding="UTF-8"?>
- <ContextdocBase="e:/tomcat-7.0.26/webapps/solr"debug="0"crossContext="true">
- <Environmentname="solr/home"type="java.lang.String"value="e:/tomcat-7.0.26/solr"override="true"/>
- </Context>
docBase:为solr的上传目录
5、把apache-solr-3.5.0\example目录下的solr文件夹上传到e:/tomcat-7.0.26目录下.索引文件会默认会放到 e:/tomcat-7.0.26\solr\data下.
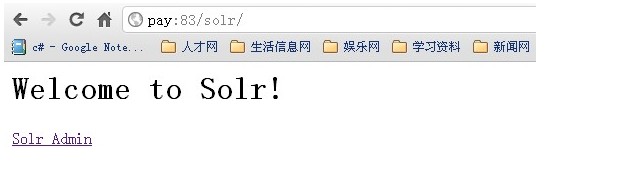
6、重新tomcat 在浏览器中输入:http://localhost:8080/
会出现:welcome to solr
solr admin 说明发布已成功!
四、solr 3.5与IKAnalyzer 3.2.8分词的整合
1、IKAnalyzer下载地址:IKAnalyzer 3.2.8
2、添加IKAnalyzer3.2.8.jar
把IKAnalyzer3.2.8.jar放到tomcat-7.0.14\webapps\solr\WEB-INF\lib下;
3、schema.xml 增加信息
进入目录编辑schema.xml文件,在<Types>下添加以下内容:
- <fieldTypename="text"class="solr.TextField">
- <analyzerclass="org.wltea.analyzer.lucene.IKAnalyzer"/>
- <analyzertype="index">
- <tokenizerclass="org.wltea.analyzer.solr.IKTokenizerFactory"isMaxWordLength="false"/>
- <filterclass="solr.StopFilterFactory"
- ignoreCase="true"words="stopwords.txt"/>
- <filterclass="solr.WordDelimiterFilterFactory"
- generateWordParts="1"
- generateNumberParts="1"
- catenateWords="1"
- catenateNumbers="1"
- catenateAll="0"
- splitOnCaseChange="1"/>
- <filterclass="solr.LowerCaseFilterFactory"/>
- <filterclass="solr.EnglishPorterFilterFactory"
- protected="protwords.txt"/>
- <filterclass="solr.RemoveDuplicatesTokenFilterFactory"/>
- </analyzer>
- <analyzertype="query">
- <tokenizerclass="org.wltea.analyzer.solr.IKTokenizerFactory"isMaxWordLength="false"/>
- <filterclass="solr.StopFilterFactory"
- ignoreCase="true"words="stopwords.txt"/>
- <filterclass="solr.WordDelimiterFilterFactory"
- generateWordParts="1"
- generateNumberParts="1"
- catenateWords="1"
- catenateNumbers="1"
- catenateAll="0"
- splitOnCaseChange="1"/>
- <filterclass="solr.LowerCaseFilterFactory"/>
- <filterclass="solr.EnglishPorterFilterFactory"
- protected="protwords.txt"/>
- <filterclass="solr.RemoveDuplicatesTokenFilterFactory"/>
- </analyzer>
- </fieldType>
然后在<fields>下添加:
- <fieldname="name1"type="text"indexed="true"stored="true"required="true"/>
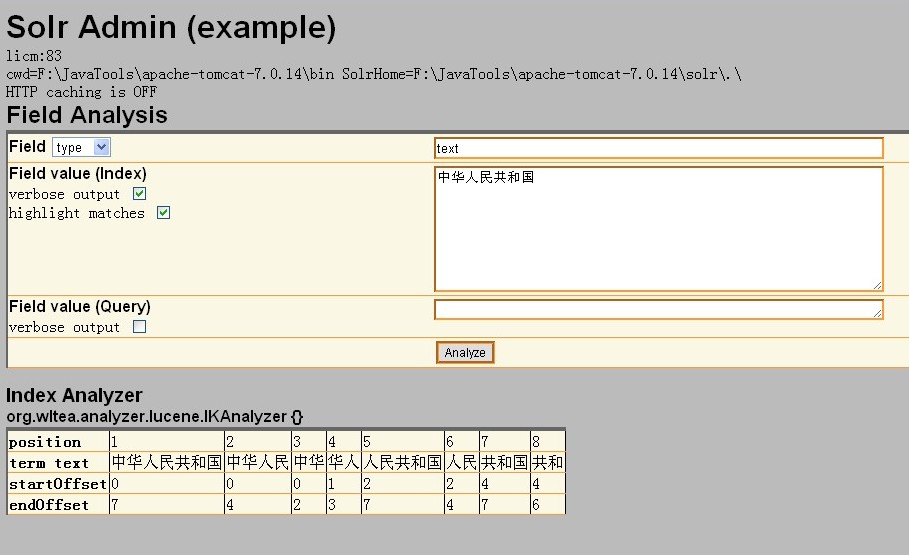
5、重新tomcat 在浏览器中输入:http://localhost:80/solr/analysis.jsp 进去solr admin显示:
一、solr 的简介
Apache Solr 是一个开源的搜索服务器。Solr 使用 Java 语言开发,主要基于 HTTP 和 Apache Lucene 实现。Apache Solr 中存储的资源是以 Document 为对象进行存储的。每个文档由一系列的 Field 构成,每个 Field 表示资源的一个属性。Solr 中的每个 Document 需要有能唯一标识其自身的属性,默认情况下这个属性的名字是 id,在 Schema 配置文件中使用:<uniqueKey>id</uniqueKey>进行描述。
Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。文档通过Http利用XML加到一个搜索集合中。查询该集合也是通过 http收到一个XML/JSON响应来实现。它的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,高亮显示搜索结果,通过索引复制来提高可用性,提 供一套强大Data Schema来定义字段,类型和设置文本分析,提供基于Web的管理界面等。
二、solr 3.5 的下载
solr 3.5下载地址:http://www.apache.org/dist//lucene/solr/
tomcat tomcat-7.0.26 下载:http://mirror.bjtu.edu.cn/apache/tomcat/tomcat-7/v7.0.26/bin/apache-tomcat-7.0.26.zip
三、solr 3.5的安装
1、解压tomcat-7.0.26 到 e:\tomcat-7.0.26\下
2、打开tomcat-7.0.26\conf修改server.xml 文件
- <Connectorport="8080"protocol="HTTP/1.1"connectionTimeout="20000"redirectPort="8443"URIEncoding="UTF-8"/>
修改默认端口8080,可以不修改,添加字符编码 URIEncoding="UTF-8" 否则中文会乱码
3、在apache-solr-3.5.0\dist目录下找到apache-solr-3.5.0.war把重命名为solr.war 并上传到tomcat-7.0.26/webapps下。
4、创建一个solr.xml文件,
在tomcat-7.0.14\conf\Catalina\localhost\下创建一个solr.xml文件。内容为:
- <?xmlversion="1.0"encoding="UTF-8"?>
- <ContextdocBase="e:/tomcat-7.0.26/webapps/solr"debug="0"crossContext="true">
- <Environmentname="solr/home"type="java.lang.String"value="e:/tomcat-7.0.26/solr"override="true"/>
- </Context>
docBase:为solr的上传目录
5、把apache-solr-3.5.0\example目录下的solr文件夹上传到e:/tomcat-7.0.26目录下.索引文件会默认会放到 e:/tomcat-7.0.26\solr\data下.
6、重新tomcat 在浏览器中输入:http://localhost:8080/
会出现:welcome to solr
solr admin 说明发布已成功!
四、solr 3.5与IKAnalyzer 3.2.8分词的整合
1、IKAnalyzer下载地址:IKAnalyzer 3.2.8
2、添加IKAnalyzer3.2.8.jar
把IKAnalyzer3.2.8.jar放到tomcat-7.0.14\webapps\solr\WEB-INF\lib下;
3、schema.xml 增加信息
进入目录编辑schema.xml文件,在<Types>下添加以下内容:
- <fieldTypename="text"class="solr.TextField">
- <analyzerclass="org.wltea.analyzer.lucene.IKAnalyzer"/>
- <analyzertype="index">
- <tokenizerclass="org.wltea.analyzer.solr.IKTokenizerFactory"isMaxWordLength="false"/>
- <filterclass="solr.StopFilterFactory"
- ignoreCase="true"words="stopwords.txt"/>
- <filterclass="solr.WordDelimiterFilterFactory"
- generateWordParts="1"
- generateNumberParts="1"
- catenateWords="1"
- catenateNumbers="1"
- catenateAll="0"
- splitOnCaseChange="1"/>
- <filterclass="solr.LowerCaseFilterFactory"/>
- <filterclass="solr.EnglishPorterFilterFactory"
- protected="protwords.txt"/>
- <filterclass="solr.RemoveDuplicatesTokenFilterFactory"/>
- </analyzer>
- <analyzertype="query">
- <tokenizerclass="org.wltea.analyzer.solr.IKTokenizerFactory"isMaxWordLength="false"/>
- <filterclass="solr.StopFilterFactory"
- ignoreCase="true"words="stopwords.txt"/>
- <filterclass="solr.WordDelimiterFilterFactory"
- generateWordParts="1"
- generateNumberParts="1"
- catenateWords="1"
- catenateNumbers="1"
- catenateAll="0"
- splitOnCaseChange="1"/>
- <filterclass="solr.LowerCaseFilterFactory"/>
- <filterclass="solr.EnglishPorterFilterFactory"
- protected="protwords.txt"/>
- <filterclass="solr.RemoveDuplicatesTokenFilterFactory"/>
- </analyzer>
- </fieldType>
然后在<fields>下添加:
- <fieldname="name1"type="text"indexed="true"stored="true"required="true"/>
5、重新tomcat 在浏览器中输入:http://localhost:80/solr/analysis.jsp 进去solr admin显示:















 95
95

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









