





最近在写一个采集程序,其中一个任务是提取下图中表格内的所有链接。这原本很简单,甚至根本就不用考虑table的存在,但问题就在于在提取链接的同时还需要保存链接的标题及该链接所属的类别。如“龟甲占卜文”的链接的标题是龟甲占卜文,同时属于甲骨文这个类别。
这就不得不通过分析table来确定其归属关系了。因此我特意写了一个类解决这个问题,同时方便日后处理另外的table。这里把这个类的用法介绍一下,希望也能帮到你 呵呵...这个类及其测试文件可以在这下载到http://download.csdn.net/source/1516540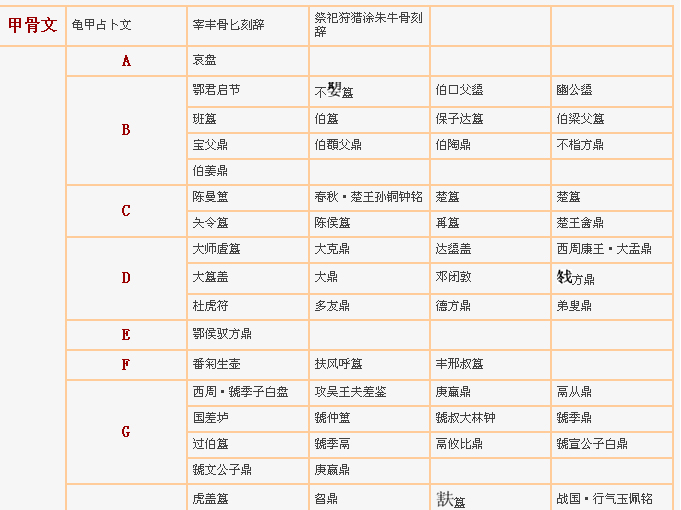
名称: table_parser
构造函数:
table_parser($url,$pattern)
->$url string 表格所在的url
->$pattern string 正则表达式,用以把表格从整个页面中分离出来
例:
<?php $tbp=new table_parser('http://www.yingbishufa.com/ldbt/xianqin.htm','/<table width="98%"[^>]*?>[/s/S]*?<//table>/'); ?>
核心方法:
a.array get_item($x , $y ,$catids)
->$x number 要提取的表格单元的x坐标,如“龟甲占卜文”的x坐标 1
->$y number 要提取的表格单元的y坐标,如“龟甲占卜文”的y坐标 0
->$catids array 由类别列组成的数组,如array(0,1)表示将第一,第二列用作类别
例:
<?php $tbp=new table_parser('http://www.yingbishufa.com/ldbt/xianqin.htm','/<table width="98%"[^>]*?>[/s/S]*?<//table>/'); $item = $tbp->get_item(3,3,array(0,1)); print_r($item); ?>
输出如下:
Array
(
[0] => <div align="center" class="style1">钟<br>
<br>
鼎<br>
<br>
器<br>
<br>
皿</div> <div align="center"></div>
[1] => <div align="center"><span class="style1">B</span></div>
[2] => <a href="0157.htm" target="_blank">伯簋</a>
)
b.array get_items($x,$y,$width,$height,$catids)
->$x number 要提取的表格单元的x坐标,如“龟甲占卜文”的x坐标 1
->$y number 要提取的表格单元的y坐标,如“龟甲占卜文”的y坐标 0
->$width number 要提取的列数
->$height number 要提取的行数
->$catids array 由类别列组成的数组,如array(0,1)表示将第一,第二列用作类别
辅助函数:
a.string get_link($str) 获取$str中可能存在的链接
b.string get_img($str) 获取$str中可能存在的图片
c.mix remove_tags($mix) 清除$mix的html及php标记,$mix可以是数组















 500
500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









