







二进制的世界,来往管道的串,将去往何方。是自由的散列,还是明确的前行,万千冲突的耦合,以何构成一个世界,玄妙的结界---hashTable
一.哈希表的是什么
众说纷纭哈希表,起初我以为哈希是个人,现在经过了一连串的深入了解,哈希是散列的意思。而真正的内涵在于,哈希表的哈希,无论是在集群云端还是在Java中的源码,散列永远是哈希表的真谛。
首先,哈希表是什么?哈希表是一种数据结构,废话定义,哈希表这种数据结构的关键在于Hash(Key)->indexof(Hash(Key))的过程。而哈希表是一种把数据使用(key,value)包装后映射到哈希表的容器中的某个位置的数据结构,方便在于相同的key值产生相同的位置,查找很快。
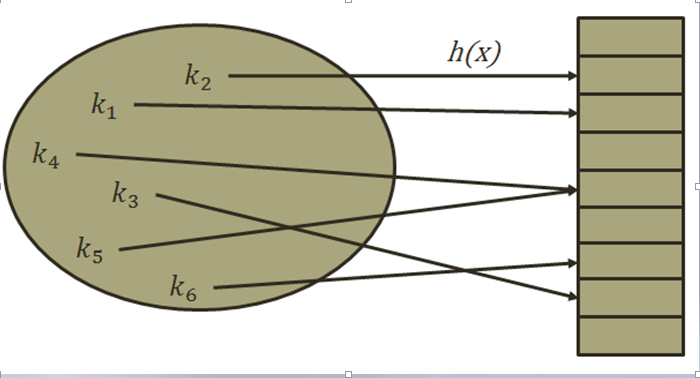
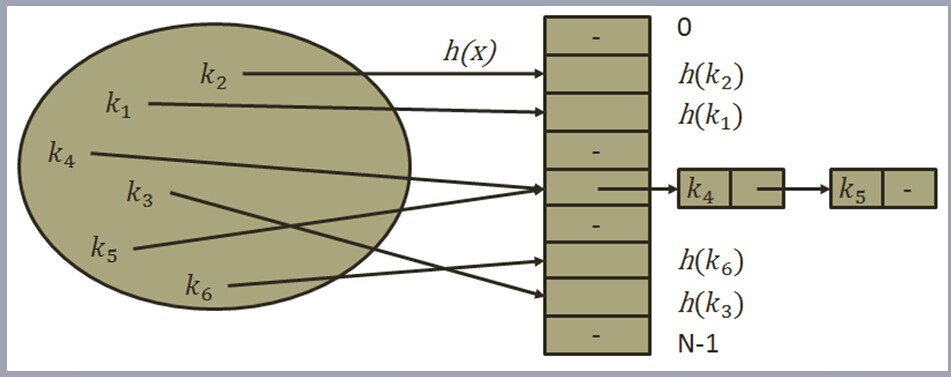
我们看到的这张图,就是哈希表的一个开始,左边这个集合中我们统一把数据存放在一个包中,(k,v)对应的一个包,k值是唯一的。而把数据hash到表中使用的是indexof(Hash(Key))算出来的一个对应的位置,然后存储进去。从图中我们马上可以知道,要映射到一个有限长度的表中,必然会有不同K值经过indexof(Hash(Key))得到相同的值,这就产生了冲突,我们称为hash冲突。
二.哈希冲突
不同的key值生成的同样的下标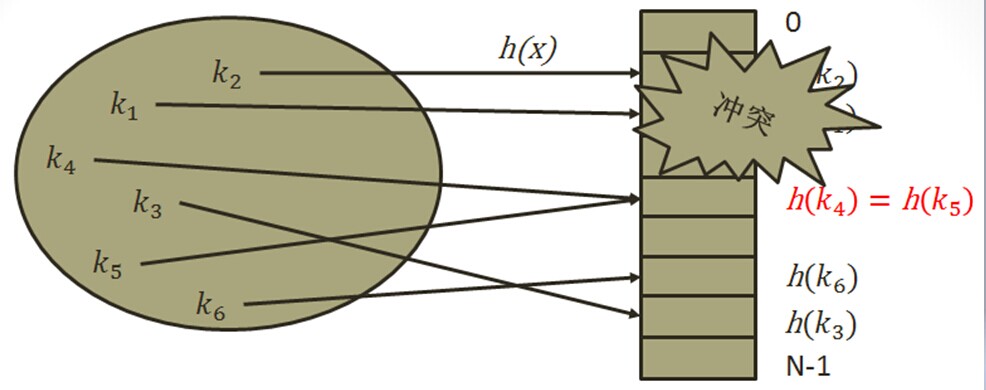
哈希冲突的产生主要是因为无限数据到达有限表长的映射必须产生冲突,这是必然的。处理冲突的方法通常有两种:(1)地址跳转法 (2)链表法
地址跳转法:
我们设计一个哈希函数簇,让其第一冲突之后使用下一阶的哈希函数进行计算,产生一个不同的地址值,如果还有冲突,再使用下一阶的函数进行计算,目的只有一个,不冲突为止,而表的空间问题下面再介绍。
链表法:
链表法就是在冲突位置形成一个链表,将冲突数据链在后方,横向是扩展了,而纵向的空间还是没有考虑,也就是和上一方法一样,要考虑数组空间的问题。
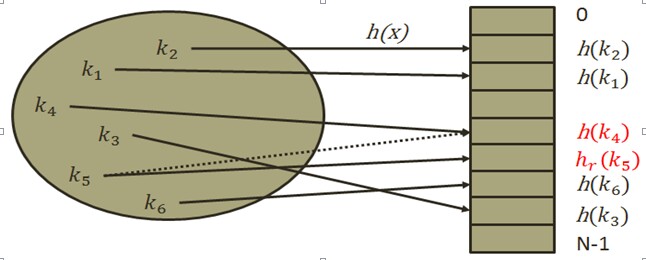
一种哈希函数簇的设计如下,也是从别的地方挖来的,总之目的只有一个,就是实现存在地推公式的散列函数计算到没有冲突为止。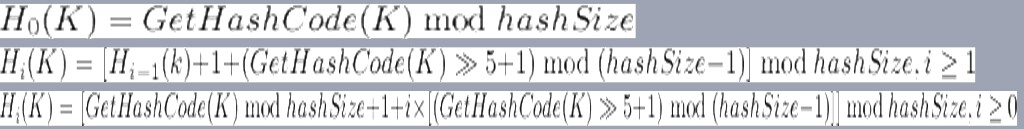
空间问题(rehash):
无论怎么处理冲突,如果表的纵向(数组容量)已经填满,那么冲突是不是必然的?我们的地址跳转法完全无效,链表越拉越长,对性能的影响是很大的,特别是在云端服务器,并发访问严重的时候,我们要维护哈希表的稳定和性能最佳。所以我们要进行纵向扩容,也就是众说纷纭的(rehash)过程。首先新建一个比原来数组容量大的一个新的数组,然后把原来的数据经过新的下标计算函数映射到新的表上,然后拷贝过去,一般Java中的实现类都是在容量到达0.72(实际容量/表长)的时候进行rehash过程。
下面是Java中hashmap的大致流程:
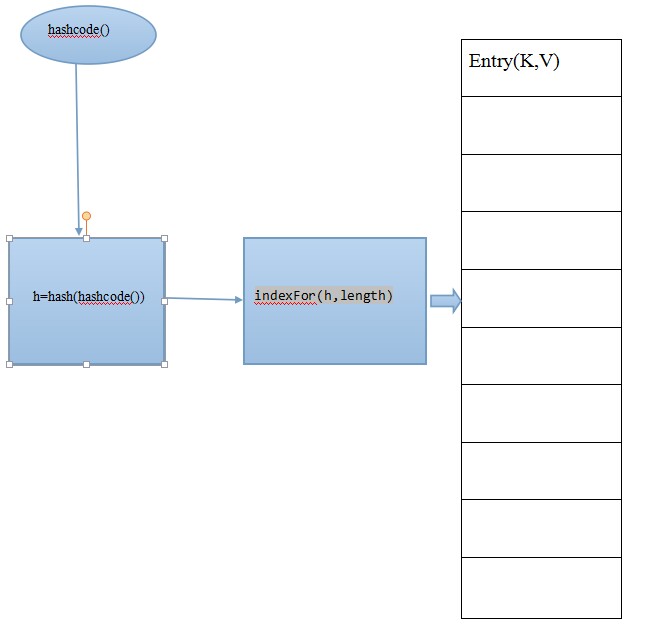
hashmap处理冲突的方法是拉链法,形成链表,rehash是容量达到0.72时候,可自行设置。
三步走实现index的计算,第一取得类的hashcode(),这个方法可重写,所以不可靠,但是系统是这么用了。第二根据hashcode()的值进行散列,获取一个hash值,为每个Entry(K,V)对象标记一个final,贴个标签,可能是由于不可靠所以才实现一个散列吧。第三通过按位与(length-1)找到一个下标并存入,冲突则next链上。
hash():
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
indexfor():
static int indexFor(int h, int length) {
return h & (length-1);
}put():
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
然后我们抽象一下这个过程,我们有一个哈希表,数据要进来,必须有特征码Key,经过一个函数进行散列到这个表上,而这个哈希表冲突达到一个阈值的时候进行rehash过程,降低下次进来数据时候的冲突率。而存取的时候保证高效性。
三.哈希函数的设计规则
哈希函数的设计抛个概念出来,就是:
1、平衡性(Balance):平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
2、单调性(Monotonicity):单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
3、分散性(Spread):在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
4、负载(Load):负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同 的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
其实唯一一点就是hash,真谛就是散列,散列的意义就是平均,为了负载均衡,好的哈希函数拥有好的散列性。
四.哈希表的性能
其实这个才是最主要哈希表诞生的原因,而网传其性能的优越到底体现在哪里我却还没有认识到,接下来就深入研究一下哈希表的性能,在大数据的时代下为何哈希表是一种完美的数据结构,数组和链表的结合真实的性能到底会是怎么样的?
这个学期学习的东西很多,自己也比之前更用心去钻研和思考了,归结起来哈希表这个模型(未应用到实际中)就是散列-存取策略-冲突处理,这三个构造,无论是在HashMap或者是HashTable中,都是一样的。有时候思考是种乐趣,再难的问题想通了比谈上十个女朋友都有意思(个人感觉),未来可能是迷茫的,而眼下确是清晰的,无论如何,坚持,思辨,乐观,承受,征服,should be kept!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









