





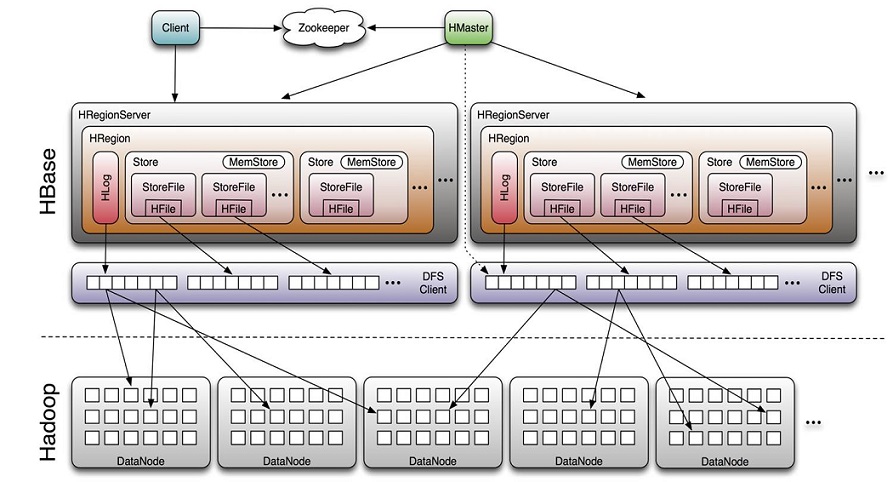
- Client
--包含访问HBase的接口并维护cache,加快对HBase的访问
- Zookeeper
–保证任何时候,集群中只有一个master
–存贮所有Region的寻址入口。
–实时监控Region server的上线和下线信息。并实时通知给Master
–存储HBase的schema和table元数据
- Master
–为Region server分配region
–负责Region server的负载均衡
–发现失效的Region server并重新分配其上的region
–管理用户对table的增删改查操作
- RegionServer
–Region server维护region,处理对这些region的IO请求
–Region server负责split在运行过程中变得过大的region
ZooKeeper存储所有Region的入口,Client通过访问它获得-ROOT-表的的location信息,接着通过-ROOT-表获得.META.表Region信息,最后再通过.META.表获得用户表的Region信息。Client会缓存这些信息,这样下次就可以直接获得用户表的Region信息。
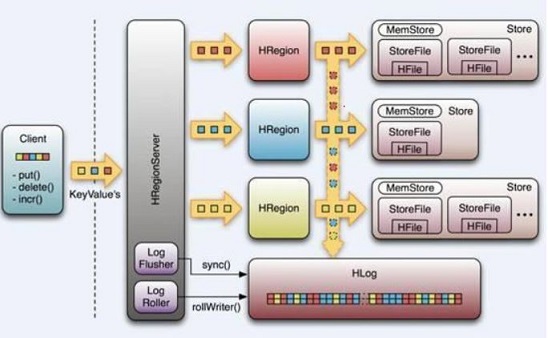
如上图所示,当Client连上HReigonServer后,后者会打开相应的HRegion对象,为每个HColumeFamily创建Store实例,每个Store实例有一个MemStore,一个或多个StoreFile,StoreFile是HFile轻量级的包装。
1 写数据过程
首先是把Log写入到HLog中,HLog是标准的Hadoop Sequence File,由于Log数据量小,而且是顺序写,速度非常快;同时把数据写入到内存MemStore中,成功后返回给Client,所以对Client来说,HBase写的速度非常快,因为数据只要写入到内存中,就算成功了。
接着检查MemStore是否已满,如果满了,就把内存中的MemStore Flush到磁盘上,形成一个新的StoreFile。
当Storefile文件的数量增长到一定阈值后,系统会进行合并(Compact),在合并过程中会进行版本合并和删除工作,形成更大的storefile。
当Storefile大小超过一定阈值后,会把当前的Region分割为两个(Split),并由Hmaster分配到相应的HRegionServer,实现负载均衡
2 读数据过程
由于无法直接修改HBase里的数据,所有的update和delete操作都转换成append操作,而且HBase里也没有索引,因此读数据都是以Scan的方式进行。
Client在读数据时,一般会指定timestamp和ColumnFamily.
首先,根据ColumnFamily可以过滤掉很大一部分Store,这也是HBase作为列式数据库的一大优势。
然后,根据timestamp和Bloom Filter排除掉一些StoreFiles
最后,在剩下的StoreFile (包含MemStore)里Scan查找

















 728
728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









