







BW:SAP STMS配置
1、SM59,删除所有包含STMS的连接
2、STMS,Overview-System,删除所有配置
3、登陆至Client 000
| UserName | SAP* |
| PassWord | Pass |
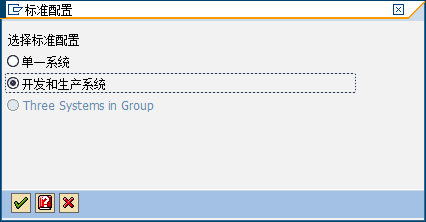
4、STMS,新建传输控制域,新建Visual System
配置Transport Routes,
BW:EU_INIT, EU_REORG, EU_PUT Canceled
SAP Note 18023
Jobs EU_INIT, EU_REORG, EU_PUT
if you have problem, search oss note like
Multiple scheduling of the jobs EU_PUT and EU_REORG
SAP Note Number: 174645
Symptom
What are the jobs EU_INIT (program SAPRSEUC), EU_REORG (program SAPRSLOG), and EU_PUT (program SAPRSEUT), which are automatically scheduled by the ABAP Workbench, used for?
Other terms
SE80
Reason and Prerequisites
The EU jobs are used to reconstruct or update the indexes (where-used lists, navigation indexes, object lists) that are important for the ABAP Workbench.
Solution
When you start transaction SE80 for the first time, the three EU jobs are scheduled automatically: EU_INIT (single start), EU_REORG (periodically each night), and EU_PUT (periodically each night). Alternatively, You can also schedule the three jobs by manually executing program SAPRSEUJ.
Short description of the individual jobs:
EU_INIT:
EU_INIT is used to completely rebuild the indexes and therefore has a correspondingly long runtime. It starts program SAPRSEUI. All customer-defined programs (selection according to the naming convention) are analyzed, and an index is created that is used in the EU for the where-used lists of function modules, error messages, reports, and do on. This index is automatically updated in dialog mode. The job can be repeated at any time. After a termination, the job is automatically scheduled for the next day; it then starts at the point of termination. (EU_INIT can therefore be terminated deliberately, if it disturbs other activities in the system.)
EU_REORG:
As mentioned above, the indexes are automatically updated online by the tools. To keep the effort for updating these indices as low as possible, only the changes are logged, which means a reorganization of the complete index for each program is required from time to time. So that this reorganization does not interfere with the online system, the EU_REORG job runs every night and performs this task. If the EU_REORG job did not run one night, this simply means that the reorganization takes place more often online.
EU_PUT:
The EU_PUT job also runs every night. It starts program SAPRSEUT. This program checks whether customer-defined development objects have been transported into the SAP system with the SAP transport system, and generates or updates the indexes described above whenever required.
To create the indexes, the EU jobs analyze the program sources of the development objects. Faulty ABAP programs (sources with grave syntax errors, for example, a literal that is too long because a concluding inverted comma is missing) are skipped. The relevant job continued the analysis with the next program and issues the names of all programs with errors in a list.
After correcting the faulty programs, you can update the object lists of the relevant programs in the Repository Browser. To do this, proceed as follows:
Up to Release 6.10: Choose “Update”.
As of Release 6. 20: go to context menu “Other functions”->”Rebuild object list”.
源文档 <https://forums.sdn.sap.com/thread.jspa?messageID=2813006?>
Queries
RSZELTDIR Directory of the reporting component elements
RSZELTTXT Texts of reporting component elements
RSZELTXREF Directory of query element references
RSRREPDIR Directory of all reports (Query GENUNIID)
RSZCOMPDIR Directory of reporting components
Workbooks
RSRWBINDEX List of binary large objects (Excel workbooks)
RSRWBINDEXT Titles of binary objects (Excel workbooks)
RSRWBSTORE Storage for binary large objects (Excel workbooks)
RSRWBTEMPLATE Assignment of Excel workbooks as personal templates
RSRWORKBOOK ‘Where-used list’ for reports in workbooks
Web templates
RSZWOBJ Storage of the Web Objects
RSZWOBJTXT Texts for Templates/Items/Views
RSZWOBJXREF Structure of the BW Objects in a Template
RSZWTEMPLATE Header Table for BW HTML Templates
BTW: There are only 26,000 tables in our small installation of BW 3.5.
Posted In: admin , bex , char , delta , elem , event , genuinid , global , infopak , init , lbwq, qrfc , query , rsa7 , settings , tables , text , varia , variant , workbook . By Srinivas Neelam
Custome Infoobjects Tabels:
/BIC/M — View of Master data Tables
/BIC/P — Master data Table, Time Independent attributes
/BIC/Q — Master data Table, Time Dependent attributes
/BIC/X — SID Table, Time Independent
/BIC/Y — SID Tabel, Time Dependent
/BIC/T — Text Table
/BIC/H — Heirarchy Table
/BIC/K — Heirarchy SID Table
Standard Infoobjects Tabels(Buss. Content):
Replace “C” with “0″ in above tables.
Ex: /BI0/M — View of Master data Tables
Standard InfoCUBE Tables :
/BI0/F — Fact Table(Before Compression)
/BI0/E — Fact Table(After Compression)
/BI0/P — Dimension Table - Data Package
/BI0/T — Dimension Table - Time
/BI0/U — Dimension Table - Unit
/BI0/1, 2, 3, …….A,B,C,D : — Dimension Tables
BW Tables:
BTCEVTJOB – To check List of jobs waiting for events
ROOSOURCE — Control parameters for Datasource
ROOSFIELD – Control parameters for Datasource
ROOSPRMSC — Control parameters for Datasource
ROOSPRMSF — Control parameters for Datasource
– More info @ ROOSOURCE weblog
RSOLTPSOURCE – Replicate Table for OLTP source in BW
RSDMDELTA – Datamart Delta Management
RSSDLINITSEL, RSSDLINITDEL
– Last valid Initialization to an OLTP Source
RSUPDINFO — Infocube to Infosource correlation
RSUPDDAT – Update rules key figures
RSUPDENQ – Removal of locks in the update rules
RSUPDFORM — BW: Update Rules - Formulas - Checking Table
RSUPDINFO — Update info (status and program)
RSUPDKEY — Update rule: Key per key figure
RSUPDROUT — Update rules - ABAP routine - check table
RSUPDSIMULD – Table for saving simulation data update
RSUPDSIMULH — Table for saving simulation data header information
RSDCUBEIOBJ – Infoobjects per Infocube
RSIS – Infosouce Info
RSUPDINFO — Update Rules Info
RSTS – Transfer Rules Info
RSKSFIELD – Communication Structure fields
RSALLOWEDCHAR – Special Characters Table(T Code : RSKC, To maintain)
RSDLPSEL – Selection Table for fields scheduler(Infpak’s)
RSDLPIO – Log data packet no
RSMONICTAB – Monitor, Data Targets(Infocube/ODS) Table, request related info
RSTSODS — Operational data store for Transfer structure
RSZELTDIR – Query Elements
RSZGLOBV – BEx Variables
RXSELTXREF, RSCOMPDIR – Reports/query relavent tables
RSCUSTV – Query settings
RSDIOBJ – Infoobjects
RSLDPSEL — Selection table for fields scheduler(Info pak list)
RSMONIPTAB – InfoPackage for the monitor
RSRWORKBOOK – Workbooks & related query genunid’s
RSRREPDIR – Contains Genuin id, Rep Name, author, etc…
RSRINDEXT – Workbook ID & Name
RSREQDONE – Monitor: Saving of the QM entries
RSSELDONE – Monitor : Selection for exected requests
RSLDTDONE – Texts on the requeasted infopacks & groups
RSUICDONE – BIW: Selection table for user-selection update Infocubes’s
RSSDBATCH – Table for Batch run scheduler
RSLDPDEL – Selection table for deleting with full update scheduler
RSADMINSV – RS Administration
RSSDLINIT — Last Valid Initializations to an OLTP Source
BTCEVTJOB –To check event status(scheduled or not)
VARI – ABAP Variant related Table
VARIDESC – Selection Variants: Description
T Code : SMQ1 –> QRFC Monitor(Out Bound)
T Code : SM13 –> Update Records status
T Code : LBWQ –> QRFC related Tables
TRFCQOUT,
QREFTID,
ARFCSDATA
SAP Data Dictionary用表
DD02L - SAP tables
DD02T - R/3 DD: SAP table text
DD03L - Table Fields
DD03T - DD: Texts for fields (language dependent)
EDD04L - Data elements
DD04T - R/3 DD: Data element texts
DD01L - Domains
DD01T - R/3 DD: domain texts
DD07L - R/3 DD: values for the domains
DD07T - DD: Texts for Domain Fixed Values (Language-Dependent)
Transparent tables can be identified using DD02L-TABCLASS = ‘TRANSP’.
1 同一个变量名的UID可能有多个,记得注意
2 在查找时要注意技术名称还是名称,因为查询时会在两个中进行,模糊查询时要细心,FV与V都可以查到
3 复制的时候注意长度,过长的会不能显示
4 开着Query不能删除
5 se01 Transport Organizer
6 行列只是用来放特征和关键值
7 行和列都是死的是固定报表,行和列都是灵活的是灵活报表,行或列有一个是死的,有一个是灵活的是半灵活报表
8 SAP portal增量链接的时候别忘记打开目的地,不然不会显示菜单的
9 P采购 purchasing,I库存 inventory
10 传输请求的时候,DSO传输过,转换会变灰,就是说底层变,上层会有问题
11 M版本不等于A版本,可能是修改以后没有激活
12 SID — Surrogate-ID
13 YTD,QTD,PTD 年初至今,季初至今,期初至今
14 BOM 物料清单
15 报表和BEx请求要进ZBW_LYHG包,其余的都进ZBW包
16 请求出错,到英文系统看明细日志
17 mb51,收+,发-
18 312为测试系统,300-302,200-222
19 收集转换的时候要收集例程,收集DTP的时候要带信息包
20 se03 显示/更改命名空间,可以看到类似于/BIO/ /BIC/的文本描述
/BI0/ 业务信息仓库:SAP 命名空间 SAP AG Walldorf
/BIC/ 业务信息仓库:客户命名空间 客户名称空间
21 有时候,结果行的显示会有错误,可以再Query里将 计算结果 改为 合计
22 主链修改后需要计划之,即执行
23 做完报表要传Portal的
24 用户出口:SD,绑定给一个,不能重用;客户出口,ALL;BTE业务交易事件,FI;BADI业务附加(NEW),用户出口与BTE的结合
25 RRM_SV_VAR_WHERE_USED_LIST_GET
26 01交易数据,02主数据,03层次,04空
27 压缩:F事实表压缩至E事实表,压缩之后F表清空,直接从E表取数,加快速度。如果有聚集,要先上传至聚集,再压缩。
28 开发类:逻辑上相关的一组对象,也就是说,这组对象必须一起开发、维护和传输
本地对象:将对象指派给$TMP,不可传输到其他系统
自建开发类:以Y或者Z开头
29 CCMS: Computer center Management System
30 TCODE: SSAA
31 关于DB Statistics,计算统计数据时,SAP_ANALYZE_ALL_INFOCUBES
使用的信息立方体数据量<=20%时,BW将会使用10%的信息立方体数据来估计统计数据,
否则,BW将计算实际的统计数据。此时,Oracle PL/SQL包DBMS_STATS就是更好的选择,如果可能会调用并行的查询来收集统计数据;否则调用一个顺序查询或者ANALYZE语句。索引统计数据并不是并行收集的。TCODE: DB20
32 每次加载数据时,自动刷新统计信息:Environment–>Automatic Request Processing
33 分区查看:SE11–>Utilities–>Database Object–>Database Utilities–>Storage Parameters–>Partition
34 分区管理:打开Cube–>Extras–>DB Performance–>Partitioning,来个例子,很简单的解释,很透彻
我选择额的是0CALMONTH,按月来分区:
Example
Value range for FYear/Calendar Month
- from 01.1998
- to 12.2003
6 Years * 12 Months + 2 = 74 partitions will be created (2 partitions for values that lie outside of the range, meaning <01.1998 or > 12.2003).
35 如果可能,在传输规则而不是更新规则中执行数据的转换。传输规则:PSA–>DSO,更新规则:DSO–>Cube
36 考虑使用数据库的NOARCHIVELOG模式
37 将实例的描述参数rdisp/max_wprun_time设置为0,允许对话工作进程占用无限的CPU时间
38 加载交易数据时:
1、加载所有的主数据
2、删除信息立方体及其聚集的索引
3、打开数字范围缓冲(Number range buffering)
4、设置一个合适的数据包大小
5、加载交易数据
6、重建索引
7、关闭数字范围缓冲
8、刷新统计数据
39 事实表命名:</BIC|/BIO>/F<信息立方体名>,同理,E事实表
| </BIC|/BIO>/D<信息立方体名>P | 数据包维度 | Package |
| </BIC|/BIO>/D<信息立方体名>T | 时间维度 | Time |
| </BIC|/BIO>/D<信息立方体名>U | 单位维度 | Unit |
40 SID:Surrogate-ID(替代标识)
| </BIC|/BIO>/S<特征名> | SID表 |
| </BIC|/BIO>/P<特征名> | 主数据表 |
| </BIC|/BIO>/T<特征名> | 文本表 |
| </BIC|/BIO>/H<特征名> | 层次表 |
| </BIC|/BIO>/I<特征名> | 层次表I |
| </BIC|/BIO>/K<特征名> | 层次表K |
| </BIC|/BIO>/S<特征名> | 层次表S |
| </BIC|/BIO>/M<特征名> | 主数据视图 |
维度表和SID表之间,主数据表和SID表之间,都是虚线关系,虚线关系表示由ABAP程序维护,不受到外键补充。使得我们能够加载交易数据,即使数据库中不存在任何主数据也可以。Always update data, even if no master data exists for the data!
41 BW多种建模,参照BW Accelerator, Multi-Dimensional Modeling with BW
42 维度特征 or 维度属性:
1、如果**数据包含在交易数据中,那么应将**用作为维度特征,而不要用做维度属性。
2、如果**频繁用于导航,那么应将**用做维度特征,而不要用做维度属性。
43 维度:
1、如果特征具有一对多的关系,那么应将它们组合在同一维度中。
2、如果特征具有多对多的关系,那么应将他们组合在不同维度中。(合并关系很小除外)
44 复合属性(组合属性 Compounding):
除非绝对必要,不要采用复合属性,代价比较大。
理解:IO_HOUSE拥有一条White house的记录,为了区别是来自政府源系统还是家居网站,将IO_HOUSE和0SOURCESYSTEM复合起来澄清特征的具体含义。
45 线性项维度:
如果维度只有一个特征,可以设为线性项特征。导致并未创建维度表,关键字是SID表的SID,事实表通过SID表连接到主数据、文本和层级表,同时删除了维度表的一个中间层,提高效率。
46 粒度(Granularity):信息具体的程度
47 PSA:数据以包为单位进行传输
48 IDoc:数据以IDoc为单位进行传输,字符格式中,传输结构不能超过1000字节
49 BW收集传输数据步骤:
1、BW传递一个加载请求IDoc给R/3
2、在加载请求IDoc触发时,R/3将启动一个后台任务。后台任务从数据库中收集数据,并保存在事先定义好大小的包中
3、收集了第一个数据包以后,后台任务启动一个对话工作进程(如果可用),将第一个数据包从R/3传递给BW
4、如果需要传递更多数据,后台工作将继续收集第二个包的数据,而不必等第一个数据包完成其传递过程。收集完毕发送
5、在前面的步骤进行时,R/3传递信息IDoc给BW,通知BW数据抽取的传输状态
6、按照上面的方式过程继续进行,直到所有请求的数据得以传输和选择
因此,信息包的大小很重要

上面两张图,一个是表ROIDOCPRMS,里面存储的是关于信息包的设置
设置方法:SBIW–>General Settings–>Maintain Control Parameters for Data Transfer
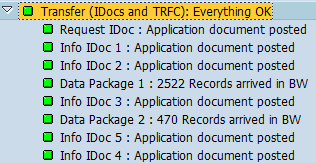
另一个是数据抽取的过程:几个IDoc的Info status分别是:
| 0 | Data request received |
| 1 | Data selection started |
| 2 | Data selection running |
| 5 | Error in data selection |
| 6 | Transfer structure obsolete, transfer rules regeneration |
| 8 | No data available, data selection ended |
| 9 | Data selection ended |
这里的几个状态分别为:
| Info IDoc 1 | Info Idoc 2 | Info Idoc 3 | Info Idoc 4 | Info Idoc 5 |
| 0 | 1 | 2 | 2 | 9 |
很简单的逻辑,收到请求,开始数据选择,一直跑一直跑,一直跑到结束
50 加载数据到InfoCube时,会使用数据范围缓冲(Number range buffering)
是通过数据范围对象(Number range object)来实现的。
设置方式:
SE37–>RSD_CUBE_GET–>I_INFOCUBE和I_BYPASS_BUFFER=X–>E_T_DIME–>NOBJECT–>SNRO–>Edit–>Set-up buffering–>Main memory
也许会用到的是SE03–>Set System Change Option–>General SAP name Range=Modifiable
例子里设置的是500
51 对SAP传输,自己有一点点小的见解
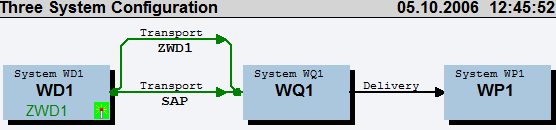
| D系统 | Development | 开发系统 |
| Q系统 | Quality Assurance | 质量保障系统 |
| P系统 | Production | 生产系统 |
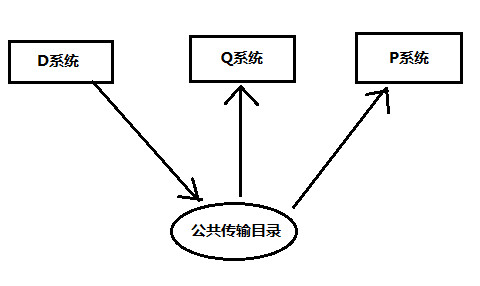
释放:从技术角度来讲,释放一个传输请求实际上就是把传输对象从传输请求中导出。
52 状态:
| D | SAP传输(Delivery)状态 |
| A | 活动(Active)状态 |
| M | 修改(Modified)状态 |
安装BC的时候,选Install,覆盖A状态;选Match,无操作;都选,合并(未必全合并)
53 STMS Transport Management System
54 InfoCube 类型:
| Basic Cube | 基本CUBE |
| Multi Cube | 多立方体 |
| SAP Remote Cube | SAP远程立方体 |
| Gen Remote Cube | 一般远程立方体 |
55 工作簿在数据库中保存为二进制大对象(Binary Large Object, BLOB)的。
56 BW场景:
| Today-is-yesterday | 时间>当前 |
| Yesterday-is-today | 时间<当前 |
| Yesterday-or-today | |
| Yesterday-and-today |
57 对于主特性,聚集中能采用SUM、MIN和MAX而不能采用AVG
58 Info Cube层级设计:
依赖于时间的整体层级
维度特征
依赖于时间的导航属性
59 D包不要把灯从黄色改成绿色,可是适当的改成红色,如果没有数据传输的话。尽量不要改
60 尴尬,NWDS 和 WAS一定要是同一个版本才行,很烦人啊很烦人,另外Notes号码是:718949
61 DSO,三个表
| A表 | 激活后的数据 |
| LOG表 | 存放数据详细动作,用于上载到CUBE |
| N表 | 数据抽取到DSO后存放在N表,激活后清空 |
62 DSO分为覆盖和合计两种,在转换中点Detail,双击Key Figure,可以选。
63 DTP:
如果是单转换,会有:
语义组(错误堆栈关键字段选择),会有包大小的选择(一般为5w),执行的处理模式为连续提取,立即平行处理
如果有信息源,则:
没有语义组,包大小与源中的包大小一致.在运行时间动态确定,执行的处理模式为连续提取和源包的处理(这俩是一个意思)
64 Variable Processing By:
Manual Input/Default Value
Replacement Path
Customer exit
Authorization
65 Cube<–DSO
| DELTA | LOG表 |
| FULL | A表和LOG表 |
66 BW3.5的数据包直接上载,是不生成请求的
67 BW报表权限:角色中的业务智能分析权限
业务浏览器 - 业务浏览器可重复使用的 web 项目 (NW 7.0+)
业务浏览器 - BEx Web 模板(NW 7.0+)
业务浏览器 - 组件
业务浏览器 - 组件: 对所有人的增强
业务浏览器 - 数据访问服务
68 制作进程链的时候,要注意3.5的DSO,他们会选择自动激活和自动更新
69 几种DSO:
-
标准数据存储对象
- 使用数据传输进程提供的数据
- 可以生成的主数据标识值
- 在激活期间集合了带有相同代码的数据记录
- 激活后数据可用于报告
-
写优化的数据存储对象
- 使用数据传输进程提供的数据
- 不能生成的主数据标识值
- 未集合带有相同代码的记录
- 装载数据后此数据后可立即用于报告
-
直接更新的数据存储对象
- 使用应用程序接口提供的数据
- 不能生成的主数据标识
- 未集合带有相同代码的记录
关于更多信息, 请通过以下路径参阅 SAP 库:
http://help.sap.com/saphelp_nw04s/helpdata/en/F9/45503C242B4A67E10000000A114084/content.htm
70 千万不要忘记主数据的Change Run
71 激活的时候,要求有连续性,就是从第一个开始,到最后一个结束,前置的请求必须执行
72 主数据有权限相关,可以细分权限,权限TCode:RSECADMIN
73 激活的时候,默认会把一起激活的数据放在一个请求里
74 Reconstruction,重新建造是针对3.5的抽取来讲的,请求到达其下级的时候,这里会显示传输结构状态为成功
数据目标中有效的请求为 失败,点重建或插入,则类似于执行DTP操作,填充数据
75 几个处理后台事务的TCode:
| SE06 | 全局配置 |
| SCC4 | 集团配置 |
| SM59 | RFC配置 |
| STMS | 传输配置 |
| SU02 | 参数文件(权限) |
| SM50 | 后台进程控制 |
| SM21 | 系统日志 |
| ST11 | 轨迹日志 |
| ST22 | ABAP Runtime Error |
| SM37 | 作业选择 |
| ST04 | 后台监控 |
| ST06 | OS监控 |
| ST06N | OS监控 |
| ST05 | 执行分析(追踪) |
| SM30 | 初始屏幕 |
| SM64 | 事件历史 |
| SM51 | SAP Server |
76 几个财务的TCode:
| VF03 | BILLING凭证 |
| VA43 | 合同 |
| VA03 | 销售凭证 |
| FD10N | 客户余额 |
77 货币转换步骤:
RSUOM设置,然后到Query里这是Conversions
Unit Conversion:Conversion Type和Target Unit选上
78 InfoSet的outer join是需要谨慎操作的,不然会出大问题
79 关于SAP与其他程序的接口,我有了一点新的理解:
从外部到SAP,可以调用BAPI,如果外部也是SAP就CALL FUNCTION,如果外部不是SAP,就用.NET或者JAVA来做
还可以写在EXCEL里,做个任务,定期执行
从SAP到外部,可以让外部掉BAPI,取数
80 查用户名:USER21,USR12,ADRP
81 RRM_SV_VAR_WHERE_USED_LIST_GET
82 RSBBS,可以设置从一个Query跳转到另一个Query
83 RSDS,迁移回3.X必备
84 取一个月的最后一天,可以使用FM:
SLS_MISC_GET_LAST_DAY_OF_MONTH
85 维度越多,Cube可以合并的数据就越少,效率就越低
86 对于单价这种KF,可以做成特性,因为Cube对同样的数据只能做合计,而DSO却可以覆盖
96 DSO能做分区么:在SP13以及之前是可以的(Write-Optimized DSO是按照请求号)
DSO能做聚集么:如果数据库是DB2的话,标准和直接写入的DSO是可以的,写优化的不行
97 RZ11
98 啥是Data Mart啊,the bw system can be a source to another bw system or to itself
the ods/cube/infoprovider which provide data to another systm are called data marts。
99 Event:SM62
100 都100条了,来点儿有意思的。3.x的时候,multi provider不能加DSO,只能用CUBE
infoset不能加CUBE,只能用DSO和Master Data,现在看来,有点儿不可思议了。
101 InfoCube:最大维度16个,去掉三个预先定义的time、unit、request,有13个可用
最大key figure数233
最大characteristic数248
DSO:
- You can create a maximum of 16 key fields (if you have more key fields, you can combine fields using a routine for a key field (concatenate).)
- You can create a maximum of 749 fields
- You can use 1962 bytes (minus 44 bytes for the change log)
- You cannot include key figures as key fields
Pasted from <http://help.sap.com/saphelp_nw04/helpdata/en/4a/e71f39488fee0ce10000000a114084/content.htm>
TABLE:
- All the key fields of a table must be stored together at the beginning of the table. A non-key field may not occur between two key fields.
- A maximum of 16 key fields per table is permitted. The maximum length of the table key is 255.
- If the key length is greater than 120, there are restrictions when transporting table entries. The key can only be specified up to a maximum of 120 places in a transport. If the key is larger than 120, table entries must be transported generically.
- A table may not have more than 249 fields. The sum of all field lengths is limited to 1962 (whereby fields with data type LRAW and LCHR are not counted).
- Fields of types LRAW or LCHR must be at the end of the table. Only one such field is allowed per table. There must also be a field of type INT2 directly in front of such a field. The actual length of the field can be entered there by the database interface.
Pasted from <http://help.sap.com/saphelp_nw04/helpdata/en/cf/21eb6e446011d189700000e8322d00/content.htm>
87 将黄灯状态改成红灯状态:运行事物码SE37,执行函数RSBM_GUI_CHANGE_USTATE
88 sap时间是从19910101开始的(??)
89 几个新认识的Tcode
| SCOT | SAP Connect |
| SOST | SAP |
| SE14 | ABAP Dictionary |
| SM30 | Maintain Table |
| RSPCM | Monitor of RSPC |
| RSMO | Monitor of All |
| ALRTCATDEF | |
| ME22N | PO |
| ME23N | PO |
| ME21 | PO List |
| ME53N | Purchasing Plan |
| XD03 | Customer |
| KS03 | Cost Center |
| FSS0 | 总账科目 |
| FB03 | 总账凭证 |
| AFAB | 折旧记账 |
| FAGLL03 | 总账科目行项目 |
| CHANGERUNMONI | Change run monitor |
| ST01 | System trace |
| ST05 | Performance Analysis |
| FB03 | 显示凭证 |
| FD10N | 客户余额 |
| FAGLB03 | 总账余额 |
| SHDB | Transaction Recorder |
| SM19 | BADI |
| RSCUR | 货币转换 |
| RSZC | Query 复制 |
| SE24 | Class Builder |
| SE91 | MSG |
| SNOTE | Note |
| SU21 | Maintain Authorization Object |
| SE54 | Generate the required maintenance dialog. |
90 PC建议并行4条
91 CT是基于小汇总的百分比, GT是基于total的计算,
92 你看这是啥:Data Flow Overview in BI

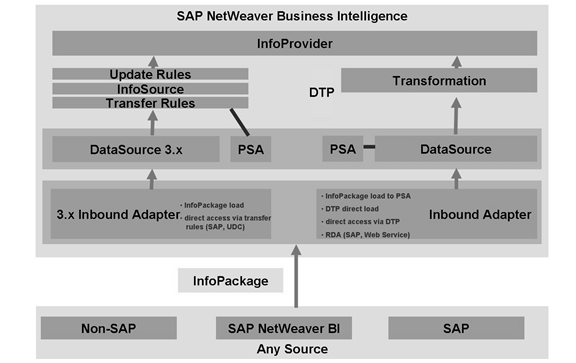
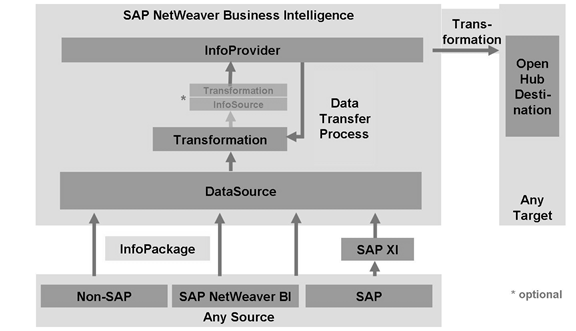
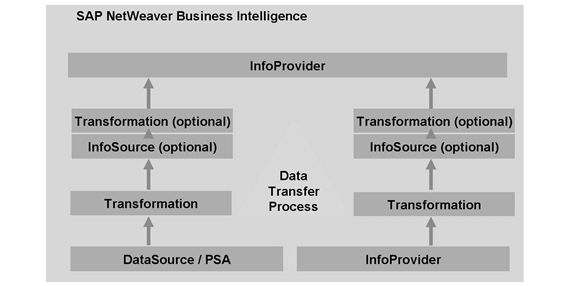
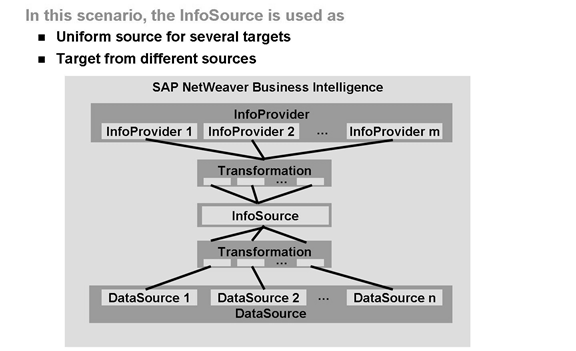
BW3.5
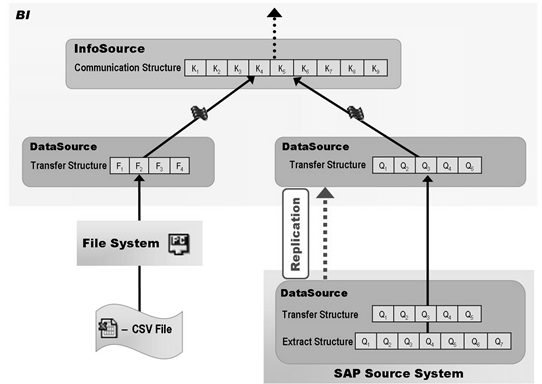
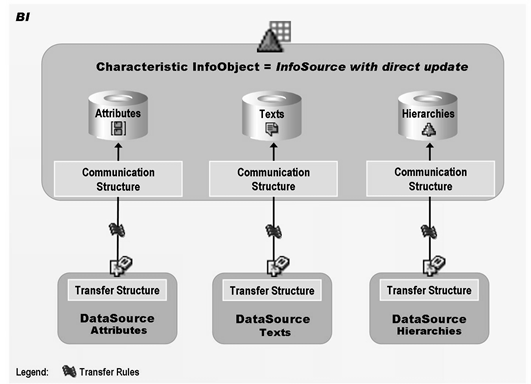
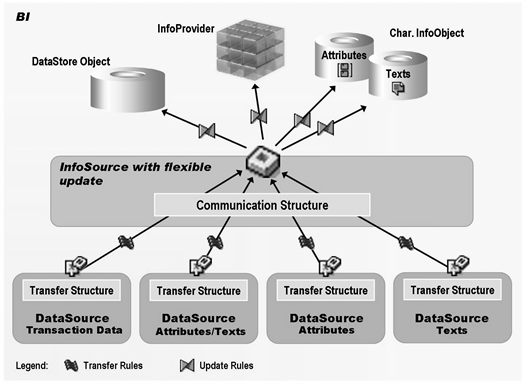
93 写优化的DSO是不能做报表的,因为没有SID?不是的,可以出报表,只是没有意义,因为key都是些请求啊,数据编号之类的
94 数据源中,选择:BW提取时,可以当做选择条件进行筛选的字段。隐藏:在BW中不体现的字段
95 货币问题事务码:
OX15 OX02 OX06
96 DSO能做分区么:在SP13以及之前是可以的(Write-Optimized DSO是按照请求号)
DSO能做聚集么:如果数据库是DB2的话,标准和直接写入的DSO是可以的,写优化的不行
97 RZ11
98 啥是Data Mart啊,the bw system can be a source to another bw system or to itself
the ods/cube/infoprovider which provide data to another systm are called data marts。
99 Event:SM62
100 都100条了,来点儿有意思的。3.x的时候,multi provider不能加DSO,只能用CUBE
infoset不能加CUBE,只能用DSO和Master Data,现在看来,有点儿不可思议了。
101 InfoCube:最大维度16个,去掉三个预先定义的time、unit、request,有13个可用
最大key figure数233
最大characteristic数248
DSO:
- You can create a maximum of 16 key fields (if you have more key fields, you can combine fields using a routine for a key field (concatenate).)
- You can create a maximum of 749 fields
- You can use 1962 bytes (minus 44 bytes for the change log)
- You cannot include key figures as key fields
Pasted from <http://help.sap.com/saphelp_nw04/helpdata/en/4a/e71f39488fee0ce10000000a114084/content.htm>
TABLE:
- All the key fields of a table must be stored together at the beginning of the table. A non-key field may not occur between two key fields.
- A maximum of 16 key fields per table is permitted. The maximum length of the table key is 255.
- If the key length is greater than 120, there are restrictions when transporting table entries. The key can only be specified up to a maximum of 120 places in a transport. If the key is larger than 120, table entries must be transported generically.
- A table may not have more than 249 fields. The sum of all field lengths is limited to 1962 (whereby fields with data type LRAW and LCHR are not counted).
- Fields of types LRAW or LCHR must be at the end of the table. Only one such field is allowed per table. There must also be a field of type INT2 directly in front of such a field. The actual length of the field can be entered there by the database interface.
Pasted from <http://help.sap.com/saphelp_nw04/helpdata/en/cf/21eb6e446011d189700000e8322d00/content.htm>
102 你觉得Activate Data Automatically和Update Data Automatically能省事儿么,其实不是滴,因为Process Chain对这俩flag ignored
103 DSO的SID?我开始还以为在Activation Queue里,因为那个表里有SID这个字段,里面填的是Request_ID,
后来才知道根本不是这个,显示数据,里面有SID的,其实就是把文本的Key换成数字Key,能提速。
104 看DSO的请求用TCODE:RSICCONT
105 权限:InfoCube based approach info area, cube, dso
Query name based approach query
Dataset approach characteristics, key figures
106 How many fields you can assign to authorization object : 10
107 权限值‘:’
1、使用户可以访问不包含权限所限制对象的query,就是说,假如在Cube A里有IO_A,如果Query里不含IO_A,则用上‘:’之前也不能访问,之后就可以。
2、可以查看统计值,如果不去看明细的话。就是说,假如我们限制用户只能看客户A的资料,但是他还是可以看该公司的全部收入的。只要不明细到客户这一层。
108 权限值:‘$’
109 Templates of authorizations : SU24
110 Archival: SARA
111 Table:RSBFILE, Open Hub Files
112 DSO中包含从两个模型里上载过来的请求,必须分开激活
113 BW 单位:T006,货币:TCURR
114 从7.0 Query转到3.5 Query
There’s a reversal tool you can run….with which you can undo the query migratie to 7.0.
Go to SE38 and run COMPONENT_RESTORE
Not sure if it’s a custom program, but the coding can be found on OSS/SDN
115 activate master data 其实是 Change run:因为你手动加,是M版本(对于已经存在的,如果没有存在,就直接是A版本),要activate 起A版本,query 只取A版本。
116 sm66
117 看一个表是否使用了buffer:SE11,然后技术设置
118 如何传输设置到$TMP的object:

119 时间相关的特性没有P表,只有Q表
120 SU21,授权对象
121 System –> Status
122 ALPHA,数字自动填0
123 RSSDLINIT?RSREQDONE?SE38–RSREQUEST?
Yeah!查PSA的请求,用这个就靠谱。
查ODS和CUBE的,用Table:RSICCONT。
124 SE14,删除各种数据库表
125 SE93,查看Tcode
126 DSO,数据先上再到N表,然后激活到A表和LOG表
127 传输Table的时候,技术设置要单独进去保存才能进请求
128 想看Request,表RSBKREQUEST
129 做断点的时候,用BREAK USERNAME.
130 修复SID,RSRV
131 PSA查看,RSTSODS
132 RSPRECADMIN,预计算
133 权限Table:
| Role | AGR_1251 |
| Authorization | RSECVAL |
134 收集信息对象的时候,信息范围最好不要放里面
135 会计上,法律实体一定是会计主体,而会计主体未必一定是法律主体。就像上面的,分公司是会计主体,却并非法律实体。因此,会计主体对应到CompanyCode层次,而法而法律实体对应到Company层次是可以满足两个层次分别出具报表要求的。
136 收集权限时,组合角色下的角色会被一起收集进去
137 想查请求内容,E071
138 BI Content升级影响的是D版本
139 和Query相关的几个Table
RSZCOMPDIR
RSZCOMPIC
140 If the number of records to be loaded is larger than 15%-20% of the target table, then drop indexes. Otherwise, do not drop.
141 DSO的Secondary Index
1. Call transaction RSA1 (Administrator Workbench: Modeling → InfoProvider).
Double-click the ODS object on which you want to create a secondary index.
2. On the Edit ODS Object screen, right-click Indexes and choose Create
142 查看转换内容,RSTRANFIELD
143 属性的层次结构有修改时,在change run之前必须加保存层次结构
144 BX数据取的是初始库存,之后用BF和UM(填Setup table的时候要按照公司)
145 收集处理链的时候可以把相关的变式、信息包、处理链一起添加进去
146 Note 750156 - Entry <XXX…> not found in the DKF
147 T.Codes to fill up the Set Up tables for all the applications.
- 02 Purchasing => OLI3BW
- 03 Inventory Controlling => OLI1BW, OLIZBW
- 04 Shop Floor Control => OLI4BW, OLIFBW
- 08 Shipments => VIFBW, VTBW
- 11 SD Sales BW => OLI7BW
- 12 LE Shipping BW => OLI8BW
- 13 SD Billing BW => OLI9BW
148 STO:公司间销售
149 Note 559119 - Call disconnections in the syslog or dev_rd
Operating system call recv failed (error no. 73 )
Communication error, CPIC return code 020, SAP return code 223
150 WorkBook:RSRWORKBOOK
元数据仓库里面也可以看到,但是没有表里准确(只包含有效的Query)
151 AL11,查看服务器上的文件
152 角色的传输和模型不同,传输后,最后修改人将和开发机一致…
153 Query提示没有权限修改,可能是因为Patch打的比上次更改人的低
154 HR组织机构维护 PPOCE,PPOME,PPOSE
155 处理弹窗:SY-BINPT为空则弹出,为X则不弹
156 传输处理链的时候,如果有必要,需要调整源系统分配,甚至传输源系统
另外,转换的对应设置在:RSA1,工具,转换逻辑系统名称
157 For All Entry 之前要判断是否为空,否则效率很低
158 看虚拟Cube的FM:复制一下,看看Detail里的函数名。
eg: RSSEM_CONSOLIDATION_INFOPROV
RSSEM_CONSOLIDATION_INFOPROV3
159 OAER,更换excel模板
160 从模型删除字段的时候,需要把模型的数据清空,添加字段却不需要
161 IDOC WE21
162 RFC RSCUSTA
163 COPA KE24,CPB1
164 AGR_HIER表可以看到WorkBook对应的权限
165 RSZELTDIR Query元素查找
166 查看query运行的时间的事务代码是ST03
167 总账科目余额FBL5N,FS10n能查余额
168 RS_VC_GET_QUERY_VIEW_DATA可以做APD的Backup
169 SRET_TIME_DIFF_GET,通过seconds和hours来计算timestamp的时间差
170 处理链的明细视图还可以用来查看单个变式的执行时间
| 1 | RSA1 | Administrator Work Bench |
| 2 | RSA11 | Calling up AWB with the IC tree |
| 3 | RSA12 | Calling up AWB with the IS tree |
| 4 | RSA13 | Calling up AWB with the LG tree |
| 5 | RSA14 | Calling up AWB with the IO tree |
| 6 | RSA15 | Calling up AWB with the ODS tree |
| 7 | RSA2 | OLTP Metadata Repository |
| 8 | RSA3 | Extractor Checker |
| 9 | RSA5 | Install Business Content |
| 10 | RSA6 | Maintain DataSources |
| 11 | RSA7 | BW Delta Queue Monitor |
| 12 | RSA8 | DataSource Repository |
| 13 | RSA9 | Transfer Application Components |
| 14 | RSD1 | Characteristic maintenance |
| 15 | RSD2 | Maintenance of key figures |
| 16 | RSD3 | Maintenance of units |
| 17 | RSD4 | Maintenance of time characteristics |
| 18 | RSDBC | DB connect |
| 19 | RSDCUBE | Start: InfoCube editing |
| 20 | RSDCUBED | Start: InfoCube editing |
| 21 | RSDCUBEM | Start: InfoCube editing |
| 22 | RSDDV | Maintaining |
| 23 | RSDIOBC | Start: InfoObject catalog editing |
| 24 | RSDIOBCD | Start: InfoObject catalog editing |
| 25 | RSDIOBCM | Start: InfoObject catalog editing |
| 26 | RSDL | DB Connect - Test Program |
| 27 | RSDMD | Master Data Maintenance w.Prev. Sel. |
| 28 | RSDMD_TEST | Master Data Test |
| 29 | RSDMPRO | Initial Screen: MultiProvider Proc. |
| 30 | RSDMPROD | Initial Screen: MultiProvider Proc. |
| 31 | RSDMPROM | Initial Screen: MultiProvider Proc. |
| 32 | RSDMWB | Customer Behavior. Modeling |
| 33 | RSDODS | Initial Screen: ODS Object Processng |
| 34 | RSIMPCUR | Load Exchange Rates from File |
| 35 | RSINPUT | Manual Data Entry |
| 36 | RSIS1 | Create InfoSource |
| 37 | RSIS2 | Change InfoSource |
| 38 | RSIS3 | Display InfoSource |
| 39 | RSISET | Maintain InfoSets |
| 40 | RSKC | Maintaining the Permittd Extra Chars |
| 41 | RSLGMP | Maintain RSLOGSYSMAP |
| 42 | RSMO | Data Load Monitor Start |
| 43 | RSMON | BW Administrator Workbench |
| 44 | RSOR | BW Metadata Repository |
| 45 | RSORBCT | BI Business Content Transfer |
| 46 | RSORMDR | BW Metadata Repository |
| 47 | RSPC | Process Chain Maintenance |
| 48 | RSPC1 | Process Chain Display |
| 49 | RSPCM | Monitor daily process chains |
| 50 | RSRCACHE | OLAP: Cache Monitor |
| 51 | RSRT | Start of the report monitor |
| 52 | RSRT1 | Start of the Report Monitor |
| 53 | RSRT2 | Start of the Report Monitor |
| 54 | RSRTRACE | Set trace configuration |
| 55 | RSRTRACETEST | Trace tool configuration |
| 56 | RSRV | Analysis and Repair of BW Objects |
| 57 | SE03 | Transport Organizer Tools |
| 58 | SE06 | Set Up Transport Organizer |
| 59 | SE07 | CTS Status Display |
| 60 | SE09 | Transport Organizer |
| 61 | SE10 | Transport Organizer |
| 62 | SE11 | ABAP Dictionary |
| 63 | SE18 | Business Add-Ins: Definitions |
| 64 | SE18_OLD | Business Add-Ins: Definitions (Old) |
| 65 | SE19 | Business Add-Ins: Implementations |
| 66 | SE19_OLD | Business Add-Ins: Implementations |
| 67 | SE21 | Package Builder |
| 68 | SE24 | Class Builder |
| 69 | SE80 | Object Navigator |
| 70 | RSCUSTA | Maintain BW Settings |
| 71 | RSCUSTA2 | ODS Settings |
| 72 | RSCUSTV* |
|
| 73 | RSSM | Authorizations for Reporting |
| 74 | SM04 | User List |
| 75 | SM12 | Display and Delete Locks |
| 76 | SM21 | Online System Log Analysis |
| 77 | SM37 | Overview of job selection |
| 78 | SM50 | Work Process Overview |
| 79 | SM51 | List of SAP Systems |
| 80 | SM58 | Asynchronous RFC Error Log |
| 81 | SM59 | RFC Destinations (Display/Maintain) |
| 82 | LISTCUBE | List viewer for InfoCubes |
| 83 | LISTSCHEMA | Show InfoCube schema |
| 84 | WE02 | Display IDoc |
| 85 | WE05 | IDoc Lists |
| 86 | WE06 | Active IDoc monitoring |
| 87 | WE07 | IDoc statistics |
| 88 | WE08 | Status File Interface |
| 89 | WE09 | Search for IDoc in Database |
| 90 | WE10 | Search for IDoc in Archive |
| 91 | WE11 | Delete IDocs |
| 92 | WE12 | Test Modified Inbound File |
| 93 | WE14 | Test Outbound Processing |
| 94 | WE15 | Test Outbound Processing from MC |
| 95 | WE16 | Test Inbound File |
| 96 | WE17 | Test Status File |
| 97 | WE18 | Generate Status File |
| 98 | WE19 | Test tool |
| 99 | WE20 | Partner Profiles |
| 100 | WE21 | Port definition |
| 101 | WE23 | Verification of IDoc processing |
| 102 | DB02 | Tables and Indexes Monitor |
| 103 | DB14 | Display DBA Operation Logs |
| 104 | DB16 | Display DB Check Results |
| 105 | DB20 | Update DB Statistics |

















 6609
6609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









