









1、首先要找到wordcount的源代码,在http://svn.apache.org/repos/asf/hadoop/中,用svn客户端check out下来,找到svn.apache.org_repos_asf\hadoop\hadoop-mapreduce-project\hadoop-mapreduce-examples\src\main\java\org\apache\hadoop\examples\WordCount.java
2、创建文件夹并且把wordcount文件拷出来:
mkdir playground
mkdir playground/src
mkdir playground/classes
cp src/examples/org/apache/hadoop/examples/WordCount.java playground/src/WordCount.java
3、在hadoop框架中编译和执行这个副本
javac -classpath hadoop-core-1.0.1.jar:lib/commons-cli-1.2.jar -d playground/classes/ playground/src/WordCount.java
jar -cvf playground/wordcount.jar -C playground/classes/ .
- 标明清单(manifest)
- 增加:org/(读入= 0) (写出= 0)(存储了 0%)
- 增加:org/apache/(读入= 0) (写出= 0)(存储了 0%)
- 增加:org/apache/hadoop/(读入= 0) (写出= 0)(存储了 0%)
- 增加:org/apache/hadoop/examples/(读入= 0) (写出= 0)(存储了 0%)
- 增加:org/apache/hadoop/examples/WordCount.class(读入= 1911) (写出= 996)(压缩了 47%)
- 增加:org/apache/hadoop/examples/WordCount$IntSumReducer.class(读入= 1789) (写出= 746)(压缩了 58%)
- 增加:org/apache/hadoop/examples/WordCount$TokenizerMapper.class(读入= 1903) (写出= 819)(压缩了 56%)
4、运行你的程序,出现如下信息说明执行成功:
$ bin/hadoop jar playground/wordcount.jar org.apache.hadoop.examples.WordCount input my_output
- 11/12/05 21:33:30 INFO input.FileInputFormat: Total input paths to process : 1
- 11/12/05 21:33:31 INFO mapred.JobClient: Running job: job_201111281334_0014
- 11/12/05 21:33:32 INFO mapred.JobClient: map 0% reduce 0%
- 11/12/05 21:33:41 INFO mapred.JobClient: map 100% reduce 0%
- 11/12/05 21:33:53 INFO mapred.JobClient: map 100% reduce 100%
- 11/12/05 21:33:55 INFO mapred.JobClient: Job complete: job_201111281334_0014
- 11/12/05 21:33:55 INFO mapred.JobClient: Counters: 17
- 11/12/05 21:33:55 INFO mapred.JobClient: Job Counters
- 11/12/05 21:33:55 INFO mapred.JobClient: Launched reduce tasks=1
- 11/12/05 21:33:55 INFO mapred.JobClient: Launched map tasks=1
- 11/12/05 21:33:55 INFO mapred.JobClient: Data-local map tasks=1
- 11/12/05 21:33:55 INFO mapred.JobClient: FileSystemCounters
- 11/12/05 21:33:55 INFO mapred.JobClient: FILE_BYTES_READ=25190
- 11/12/05 21:33:55 INFO mapred.JobClient: HDFS_BYTES_READ=44253
- 11/12/05 21:33:55 INFO mapred.JobClient: FILE_BYTES_WRITTEN=50412
- 11/12/05 21:33:55 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=17876
- 11/12/05 21:33:55 INFO mapred.JobClient: Map-Reduce Framework
- 11/12/05 21:33:55 INFO mapred.JobClient: Reduce input groups=1857
- 11/12/05 21:33:55 INFO mapred.JobClient: Combine output records=1857
- 11/12/05 21:33:55 INFO mapred.JobClient: Map input records=734
- 11/12/05 21:33:55 INFO mapred.JobClient: Reduce shuffle bytes=25190
- 11/12/05 21:33:55 INFO mapred.JobClient: Reduce output records=1857
- 11/12/05 21:33:55 INFO mapred.JobClient: Spilled Records=3714
- 11/12/05 21:33:55 INFO mapred.JobClient: Map output bytes=73129
- 11/12/05 21:33:55 INFO mapred.JobClient: Combine input records=7696
- 11/12/05 21:33:55 INFO mapred.JobClient: Map output records=7696
- 11/12/05 21:33:55 INFO mapred.JobClient: Reduce input records=1857
5、查看结果,在文件系统的my_output中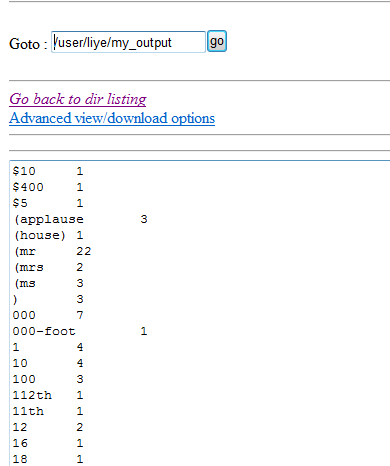
















 116
116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









