





 本文详细介绍了树的基本概念、分类及其存储方式,重点阐述了二叉树的三种遍历方法:先序、中序和后序遍历,并通过实例展示了链式二叉树的创建与遍历过程。
本文详细介绍了树的基本概念、分类及其存储方式,重点阐述了二叉树的三种遍历方法:先序、中序和后序遍历,并通过实例展示了链式二叉树的创建与遍历过程。
树
树可以简单理解为是由节点和边(存放指针域,指向下一个结点的地址)组成,每个节点只有一个父节点(根节点除外),但可以有多个子节点。树只有一个称为根的节点,树有若干个子树,且这些子树本身也是一棵树。树里面有很多专业术语,常用的有:深度(从根节点到最底层结点的层数,根节点是第一层),叶子节点(没有子节点的节点),非叶子节点(也叫非终端节点,含有子节点),度(某个节点含有子节点的个数,树的都按节点的最大度算),节点的层次(根作为第1层,根的子节点作为第2层,以此类推到该节点的层数)。树的分类分为一般树(任何一个节点的子节点的个数都不受限制);二叉树(有序):任何一个节点的子节点的个数最多两个,且子节点的位置不可更改;森林(n个互不相交的树的集合)。我们用的最多的是二叉树,而二叉树又分为:一般二叉树,满二叉树(每一层节点数都是最大节点数),完全二叉树(只是删除了或未删除满二叉树最底层最右边的连续若干个节点);可以看出满二叉树只是完全二叉树的一个特例。一般树的存储可以通过将其转化成二叉树来存储(森林也是这样做的)再来存储二叉树,具体做法是:设法保证任意一个节点的左指针域指向它的第一个孩子,右指针域指向它的下一个兄弟。不难发现一般树转成二叉树一定没有右子树(因为根节点没有兄弟节点)。树的应用非常广泛,如操作系统中子父进程的关系本身就是一棵树、树是数据库中组织的一种重要形式,还有面向对象中类的继承关系都可以看做是树。
二叉树的三种遍历
二叉树的三种遍历在考试中经常会遇到,三种遍历分为:先序遍历,中序遍历,后序遍历。先序遍历的操作是先访问根节点,然后先序遍历左子树,再先序遍历右子树;中序遍历的操作是中序遍历左子树,然后访问根节点,再中序遍历右子树;后序遍历的操作是后序遍历左子树,然后后序遍历右子树,再访问根节点。可以看到这里的先中后是针对根节点而言的。遍历的思想是把非线性结构通过线性方式来遍历。如何通过先序和中序遍历或中序和后序遍历来求另外一种遍历(但已知先序和后序不能)也经常考。
链式二叉树
实例说明

#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
typedef struct BTNode
{
char data;//数据域
struct BTNode *pLchild;//左指针域
struct BTNode *pRchild;//右指针域
}BTNODE;
BTNODE *CreateBTree(void);//创建二叉树,并返回根节点的地址
void PreTraverseBTree(BTNODE *);//先序遍历
void InTraverseBTree(BTNODE *);//中序遍历
void PostTraverseBTree(BTNODE *);//后序遍历
int main()
{
BTNODE *pT=CreateBTree();//让pT指向CreateBTree()函数返回的根节点
printf("先序遍历:");
PreTraverseBTree(pT);
printf("\n");
printf("中序遍历:");
InTraverseBTree(pT);
printf("\n");
printf("后序遍历:");
PostTraverseBTree(pT);
printf("\n");
return 0;
}
BTNODE *CreateBTree(void)//这里只造5个节点
{
BTNODE *pA=(BTNODE *)malloc(sizeof(BTNODE));//造根节点
BTNODE *pB=(BTNODE *)malloc(sizeof(BTNODE));
BTNODE *pC=(BTNODE *)malloc(sizeof(BTNODE));
BTNODE *pD=(BTNODE *)malloc(sizeof(BTNODE));
BTNODE *pE=(BTNODE *)malloc(sizeof(BTNODE));
if(NULL==pA||NULL==pB||NULL==pC||NULL==pD||NULL==pE)
{
printf("动态内存分配失败!\n");
exit(-1);//终止程序
}
pA->data='A';
pB->data='B';
pC->data='C';
pD->data='D';
pE->data='E';
pA->pLchild=pB;
pA->pRchild=pC;
pB->pLchild=pB->pRchild=NULL;
pC->pLchild=pD;
pC->pRchild=NULL;
pD->pLchild=NULL;
pD->pRchild=pE;
pE->pLchild=pE->pRchild=NULL;
return pA;//返回根节点地址
}
/*先序遍历*/
void PreTraverseBTree(BTNODE *bT)
{
printf("%c ",bT->data);
if(NULL!=bT->pLchild)
{
PreTraverseBTree(bT->pLchild);
}
if(NULL!=bT->pRchild)
{
PreTraverseBTree(bT->pRchild);
}
}
/*中序遍历*/
void InTraverseBTree(BTNODE *bT)
{
if(NULL!=bT->pLchild)
{
InTraverseBTree(bT->pLchild);
}
printf("%c ",bT->data);
if(NULL!=bT->pRchild)
{
InTraverseBTree(bT->pRchild);
}
}
/*后序遍历*/
void PostTraverseBTree(BTNODE *bT)
{
if(NULL!=bT->pLchild)
{
PostTraverseBTree(bT->pLchild);
}
if(NULL!=bT->pRchild)
{
PostTraverseBTree(bT->pRchild);
}
printf("%c ",bT->data);
}
运行结果:
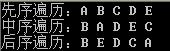
结束语
从某种角度而言,数据结构中的数据存储最核心的就是个体关系的存储,而通过泛型我们知道同一种逻辑结构(如必须都是线性结构、树、图等),无论该逻辑结构的物理存储(线性存储或非线性存储)是什么样子的,我们都可以对它进行相同的操作。今天就写到这,明天开始学习排序。

















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









