





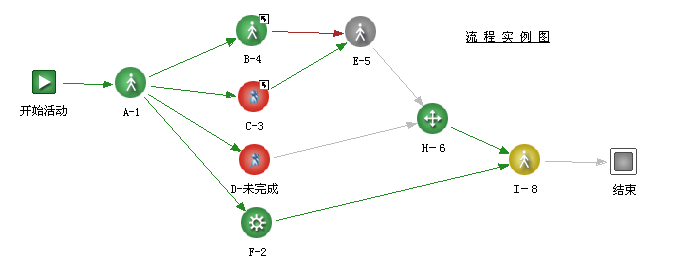
这个流程图的拓扑结构,如果采用图形深度优先遍历算法来遍历一遍,遍历顺序的部分应该是
开始活动-> A-1=>B-4=>E-5=>NEXT
这种运行顺序在实际流程运行过程中显然有问题,实际运行过程中从流程A-1节点分支到后面的四个并行节点,这四个并行节点应该是同时被引擎触发,但是如果采用深度优先遍历算法,算法是从第一个分支一直往最深的支路上面遍历,直到走到该分支的最后一个节点,然后才往回复到最初分支的第二个分支支路上面,继续往这个分支的最深处遍历,如此往复,遍历完所有节点,这样的遍历过程显然和流程实际运行过程是不吻合的
那么如果用广度优先遍历算法呢? 似乎也有问题
开始活动->A-1 然后 四个分支节点全部依次被访问,注意,广度优先遍历算法是和深入优先算法相对应,即从图的起点开始遍历,遍历的顺序是先把同一层次的所有并行点都依次访问,然后再访问第二层次的所有并行点,这样的话,访问顺序就是 开始活动->A-1->B-4->C-3->D-未完成->F-2->E-5->NEXT ,这个遍历顺序也和实际运行过程不相符合,所以流程引擎在应用图形遍历算法的时候,必须对算法进行自定义的改造,才能够让流程引擎在遍历流程的过程中,做到符合流程的实际业务运行过程。。。。。
因此我在05年设计JWFD工作流引擎的时候,就采用对广度优先算法进行改造的方法,实现了一个很初级的基于遍历算法的引擎,现在我手上的代码不是当时的代码,因为最初的设计思路好像和这个伪代码不一样,05年的时候,苏州大学一个硕士研究生做毕业设计,用到JWFD,他在测试过程中,发现算法在并行汇聚的时候会出问题,然后我们两个就这个问题,进行多很多次的沟通和交流,后来在他的协助下,把这个算法又修改了,才解决了并行汇聚的问题,但是当时的修改过程没有做文字的记录,所以为什么要这样修改,怎么修改的过程就没有记录下来,很可惜。。。
DFS伪码描述算法--修改版本
前驱路由点: 该点是N个节点的source点(N>1)
分支属性判断: 是单节点支路还是多节点串行支路
后驱路由点: 该点有N个节点的target点(N>1)
在返回访问序列的时候,当遇到有支路的时候,整个该支路用符号Nx表示,遍历的时候把这一路做为一个单节点来处理
在最后返回序列的时候,用支路的串行序列代替Nx,返回完整的访问序列
这个算法基本上可以解决分支和发散,与汇聚的流程图遍历问题
for(int i =0 i < 当前节点的邻接点个数){
if (该点是个前驱路由点) {
if (该点没有被访问过) {
设置访问次数加(从递归方法中获得的循环控制变量)
返回
}
else if( 如果已经访问过,但是访问次数<它的前驱节点总数){
设置访问次数加(从递归方法中获得的循环控制变量+1)
返回
}
else if(总计访问次数=它的前驱节点总数){
递归进入下一个节点的访问(把大循环体的,循环变量带进去递归方法中)
}
}
else if(如果是普通节点){
设置访问标志
递归进入下一个节点的访问(把大循环体的,循环变量带进去递归方法中)
}
}
}
最初的引擎算法DFS其实还比现在的这个版本的更加自动化,因为当时出发点是设计一个运行后不需要人工干预的引擎,所以整个遍历的过程都是全自动的,但是后来有新的需求,要求加入人工触发的节点,所以慢慢的,这个自动引擎就变成半自动,后来彻底抛弃自动的过程了。。。。。做产品,哪怕是开源的,如果要考虑来自各种用户的需求,那么有一个现象就是:你最初的设计理念会逐渐的走样,逐渐的变成连你自己都无法理解的模型。。。















 983
983

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









