





1. Netty - ByteBuf (2)
1.2. netty的ByteBuf
1.2.1. ByteBuf结构
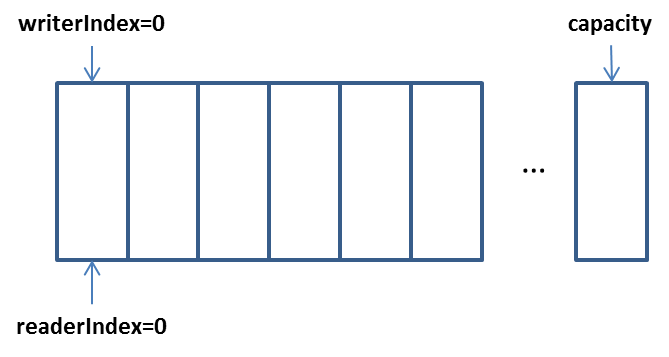
Bytebuf是netty中的ByteBuffer,结构上通过两个位置指针协助缓冲区的读写操作。分别是writerIndex和readerIndex
初始状态:
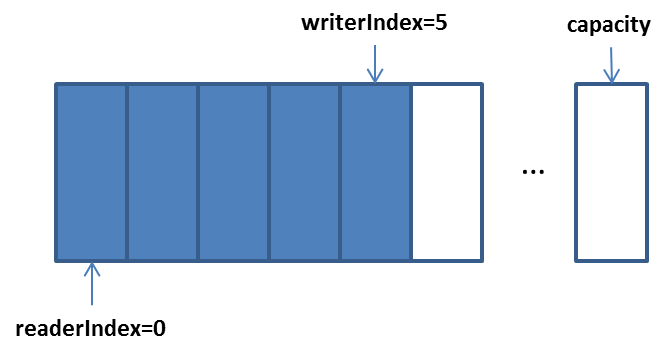
当写入5个字节后:
这时,writerIndex为5,这时如果开始读取,那么这个writerIndex可以作为上面ByteBuffer flip之后的limit。
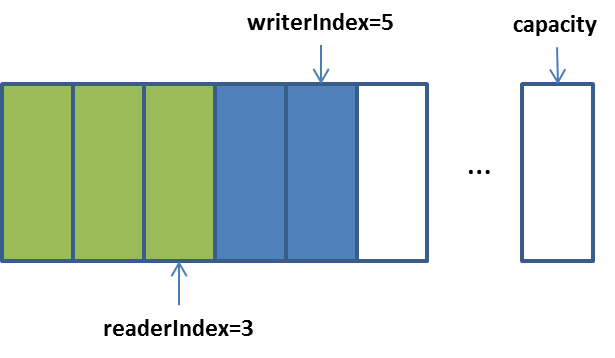
当读取3个字节后:
1.2.2. 写溢出问题
ByteBuf对于写操作进行了封装,防止写入应该被释放的ByteBuf或者写入时空间不够,我们查看下主要类的代码:
AbstractByteBuf.java:
public ByteBuf writeByte(int value) {
//检查buffer是否已经被释放
ensureAccessible();
//确认空间足够写入,否则扩容
ensureWritable(1);
//当前writerIndex的Byte写入value,并把writerIndex+1
_setByte(writerIndex++, value);
//return自己实现流式操作命令
return this;
}AbstractByteBuffer.ensureAccessible():
protected final void ensureAccessible() {
//如果该buffer的引用计数为零,证明应该被释放
if (refCnt() == 0) {
throw new IllegalReferenceCountException(0);
}
}AbstractByteBuffer.ensureWritable():
public ByteBuf ensureWritable(int minWritableBytes) {
if (minWritableBytes < 0) {
throw new IllegalArgumentException(String.format(
"minWritableBytes: %d (expected: >= 0)", minWritableBytes));
}
//如果剩余空间足够写,则返回
if (minWritableBytes <= writableBytes()) {
return this;
}
//如果不够,而且要写入的字节数与原有的加起来大于最大容量,则抛异常(这是一个运行时异常)
if (minWritableBytes > maxCapacity - writerIndex) {
throw new IndexOutOfBoundsException(String.format(
"writerIndex(%d) + minWritableBytes(%d) exceeds maxCapacity(%d): %s",
writerIndex, minWritableBytes, maxCapacity, this));
}
// 新的capacity容量计算,Normalize the current capacity to the power of 2.
int newCapacity = alloc().calculateNewCapacity(writerIndex + minWritableBytes, maxCapacity);
// Adjust to the new capacity.
capacity(newCapacity);
return this;
}新的capacity计算策略:
AbstractByteBufAllocator.calculateNewCapacity(int minNewCapacity, int maxCapacity):
public int calculateNewCapacity(int minNewCapacity, int maxCapacity) {
if (minNewCapacity < 0) {
throw new IllegalArgumentException("minNewCapacity: " + minNewCapacity + " (expectd: 0+)");
}
if (minNewCapacity > maxCapacity) {
throw new IllegalArgumentException(String.format(
"minNewCapacity: %d (expected: not greater than maxCapacity(%d)",
minNewCapacity, maxCapacity));
}
//基础为4MB,步长也为4MB
final int threshold = 1048576 * 4;
//如果4MB恰好,则返回4MB
if (minNewCapacity == threshold) {
return threshold;
}
// 如果不够,每次增长4MB,直到足够或者到达最大容量限制
if (minNewCapacity > threshold) {
int newCapacity = minNewCapacity / threshold * threshold;
if (newCapacity > maxCapacity - threshold) {
newCapacity = maxCapacity;
} else {
newCapacity += threshold;
}
return newCapacity;
}
// 如果4MB大于minNewCapacity,则从64B开始,每次乘以2,直到大于minNewCapacity
int newCapacity = 64;
while (newCapacity < minNewCapacity) {
newCapacity <<= 1;
}
return Math.min(newCapacity, maxCapacity);
}1.2.3. Mark和Reset
和ByteBuffer中的Mark还有Reset类似,mark记录当前标记,reset回滚到之前标记的位置
AbstractByteBuffer.java
public ByteBuf markReaderIndex() {
markedReaderIndex = readerIndex;
return this;
}
public ByteBuf resetReaderIndex() {
readerIndex(markedReaderIndex);
return this;
}
public ByteBuf markWriterIndex() {
markedWriterIndex = writerIndex;
return this;
}
public ByteBuf resetWriterIndex() {
writerIndex = markedWriterIndex;
return this;
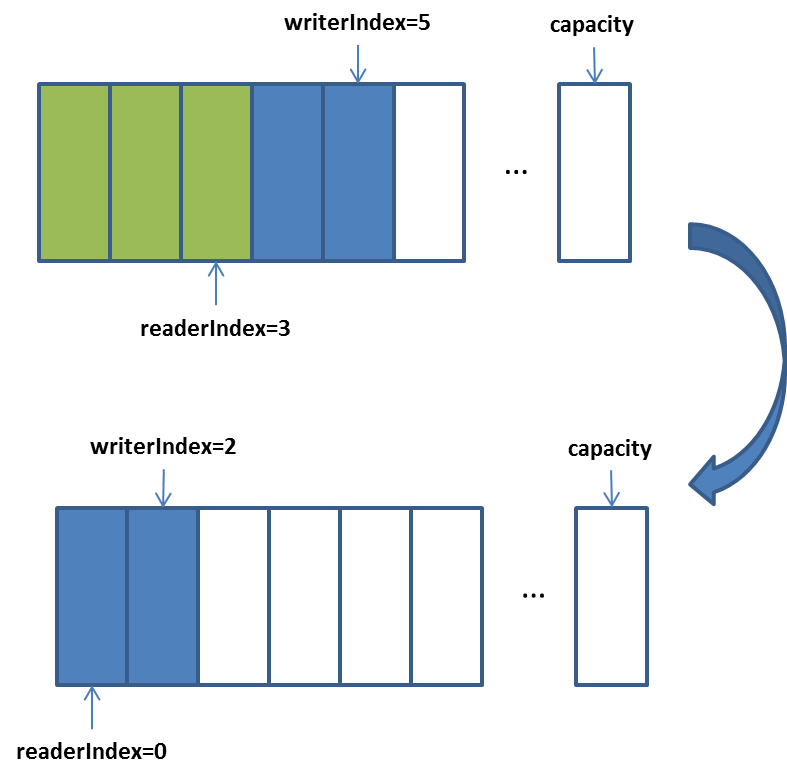
}1.2.4. discardReadBytes操作
和ByteBuffer中的compact()类似:
AbstractByteBuffer.java
public ByteBuf discardReadBytes() {
ensureAccessible();
//如果一个字节也没有读取过,则不作任何操作
if (readerIndex == 0) {
return this;
}
//如果没有全都读取完
if (readerIndex != writerIndex) {
//将这个ByteBuf的从readerIndex开始长度为writerIndex - readerIndex的内容移动到从0开始的位置
setBytes(0, this, readerIndex, writerIndex - readerIndex);
//修改writerIndex为writerIndex - readerIndex
writerIndex -= readerIndex;
//修改markers
adjustMarkers(readerIndex);
readerIndex = 0;
}
//如果全都读取完了
else {
adjustMarkers(readerIndex);
writerIndex = readerIndex = 0;
}
return this;
}
protected final void adjustMarkers(int decrement) {
int markedReaderIndex = this.markedReaderIndex;
//如果小于decrement就置为0,如果不就减去decrement
if (markedReaderIndex <= decrement) {
this.markedReaderIndex = 0;
int markedWriterIndex = this.markedWriterIndex;
if (markedWriterIndex <= decrement) {
this.markedWriterIndex = 0;
} else {
this.markedWriterIndex = markedWriterIndex - decrement;
}
} else {
this.markedReaderIndex = markedReaderIndex - decrement;
markedWriterIndex -= decrement;
}
}注意,这个操作很费时,因为需要大量的复制操作,是一种时间换空间的操作,如果可以,尽量避免。
1.2.5. Clear 操作
也和ByteBuffer中的clear()类似:
AbstractByteBuffer.java
public ByteBuf clear() {
readerIndex = writerIndex = 0;
return this;
}1.2.6. 转换成标准的ByteBuffer
ByteBuffer nioBuffer()与ByteBuffer nioBuffer(int index, int length)
查看其中一种实现:
PooledDirectByteBuf.java
public ByteBuffer nioBuffer(int index, int length) {
checkIndex(index, length);
index = idx(index);
return ((ByteBuffer) memory.duplicate().position(index).limit(index + length)).slice();
}可以断定,和原来的ByteBuf公用同一块内存空间。
1.2.7. 查找
- public int indexOf(int fromIndex, int toIndex, byte value)
起点是fromIndex,终点是toIndex,找到第一个值为value的索引。fromIndex可以大于或者小于toIndex,没找到返回-1 - bytesBefore,检查第一个value的索引与index的相对位置大小
public int bytesBefore(byte value) {
//从readerIndex开始,检查所有可读字节
return bytesBefore(readerIndex(), readableBytes(), value);
}
public int bytesBefore(int length, byte value) {
//首先检查length与可读字节大小比较
checkReadableBytes(length);
//从readerIndex开始,检查length字节
return bytesBefore(readerIndex(), length, value);
}
public int bytesBefore(int index, int length, byte value) {
int endIndex = indexOf(index, index + length, value);
//如果小于零,代表没找到
if (endIndex < 0) {
return -1;
}
//返回value的位置索引减去起始索引
return endIndex - index;
}- forEachByte
ByteBufProcessor.java
package io.netty.buffer;
public interface ByteBufProcessor {
/**
* Aborts on a {@code NUL (0x00)}.
*/
ByteBufProcessor FIND_NUL = new ByteBufProcessor() {
@Override
public boolean process(byte value) throws Exception {
return value != 0;
}
};
/**
* Aborts on a non-{@code NUL (0x00)}.
*/
ByteBufProcessor FIND_NON_NUL = new ByteBufProcessor() {
@Override
public boolean process(byte value) throws Exception {
return value == 0;
}
};
/**
* Aborts on a {@code CR ('\r')}.
*/
ByteBufProcessor FIND_CR = new ByteBufProcessor() {
@Override
public boolean process(byte value) throws Exception {
return value != '\r';
}
};
/**
* Aborts on a non-{@code CR ('\r')}.
*/
ByteBufProcessor FIND_NON_CR = new ByteBufProcessor() {
@Override
public boolean process(byte value) throws Exception {
return value == '\r';
}
};
/**
* Aborts on a {@code LF ('\n')}.
*/
ByteBufProcessor FIND_LF = new ByteBufProcessor() {
@Override
public boolean process(byte value) throws Exception {
return value != '\n';
}
};
/**
* Aborts on a non-{@code LF ('\n')}.
*/
ByteBufProcessor FIND_NON_LF = new ByteBufProcessor() {
@Override
public boolean process(byte value) throws Exception {
return value == '\n';
}
};
/**
* Aborts on a {@code CR ('\r')} or a {@code LF ('\n')}.
*/
ByteBufProcessor FIND_CRLF = new ByteBufProcessor() {
@Override
public boolean process(byte value) throws Exception {
return value != '\r' && value != '\n';
}
};
/**
* Aborts on a byte which is neither a {@code CR ('\r')} nor a {@code LF ('\n')}.
*/
ByteBufProcessor FIND_NON_CRLF = new ByteBufProcessor() {
@Override
public boolean process(byte value) throws Exception {
return value == '\r' || value == '\n';
}
};
/**
* Aborts on a linear whitespace (a ({@code ' '} or a {@code '\t'}).
*/
ByteBufProcessor FIND_LINEAR_WHITESPACE = new ByteBufProcessor() {
@Override
public boolean process(byte value) throws Exception {
return value != ' ' && value != '\t';
}
};
/**
* Aborts on a byte which is not a linear whitespace (neither {@code ' '} nor {@code '\t'}).
*/
ByteBufProcessor FIND_NON_LINEAR_WHITESPACE = new ByteBufProcessor() {
@Override
public boolean process(byte value) throws Exception {
return value == ' ' || value == '\t';
}
};
/**
* @return {@code true} if the processor wants to continue the loop and handle the next byte in the buffer.
* {@code false} if the processor wants to stop handling bytes and abort the loop.
*/
boolean process(byte value) throws Exception;
}
对于forEachByte方法,一般为根据ByteBufProcessor 的实现,查找匹配的字节并返回对应的索引
@Override
public int forEachByte(ByteBufProcessor processor) {
int index = readerIndex;
int length = writerIndex - index;
ensureAccessible();
//默认为顺序操作
return forEachByteAsc0(index, length, processor);
}
@Override
public int forEachByte(int index, int length, ByteBufProcessor processor) {
checkIndex(index, length);
return forEachByteAsc0(index, length, processor);
}
private int forEachByteAsc0(int index, int length, ByteBufProcessor processor) {
if (processor == null) {
throw new NullPointerException("processor");
}
if (length == 0) {
return -1;
}
final int endIndex = index + length;
int i = index;
try {
do {
if (processor.process(_getByte(i))) {
i ++;
} else {
return i;
}
} while (i < endIndex);
} catch (Exception e) {
PlatformDependent.throwException(e);
}
return -1;
}
@Override
public int forEachByteDesc(ByteBufProcessor processor) {
int index = readerIndex;
int length = writerIndex - index;
ensureAccessible();
return forEachByteDesc0(index, length, processor);
}
@Override
public int forEachByteDesc(int index, int length, ByteBufProcessor processor) {
checkIndex(index, length);
return forEachByteDesc0(index, length, processor);
}
private int forEachByteDesc0(int index, int length, ByteBufProcessor processor) {
if (processor == null) {
throw new NullPointerException("processor");
}
if (length == 0) {
return -1;
}
int i = index + length - 1;
try {
do {
if (processor.process(_getByte(i))) {
i --;
} else {
return i;
}
} while (i >= index);
} catch (Exception e) {
PlatformDependent.throwException(e);
}
return -1;
}1.2.8. 视图与复制
和ByteBuffer中的类似:
- duplicate:复制,共享空间,但是各自维护自己的内容指针
- copy:复制,各自独立空间,各自维护自己的内容指针
copy(int index,int length)从index开始复制length长度,各自独立空间,各自维护自己的内容指针 - slice:复制从readerIndex到writerIndex的内容,共享空间,各自维护自己的内容指针。
slice(int index,int length)从index开始复制length长度,共享空间,各自维护自己的内容指针。
1.2.9. 随机读写
会检查有效性















 622
622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









