





 本文探讨了手写识别中常见的问题,如笔画粗细、拉伸、偏移和扭曲,并提出了四种算法:最近值法、边界检测、连同连异和笔画识别来解决这些问题。
本文探讨了手写识别中常见的问题,如笔画粗细、拉伸、偏移和扭曲,并提出了四种算法:最近值法、边界检测、连同连异和笔画识别来解决这些问题。
现在软件和硬件越来越趋向于融合,用户的输入不免的从传统的键盘鼠标扩大到触摸板,声音甚至指纹和视频
这次讨论的是如何识别手写的问题,
所谓一万个人有一万个王羲之,书法与人的灵魂一样,都是很玄妙的东西
查找了很多资料未果,于是,求人不如求己
手写输入体现在软件上,最大的问题有如下几个:
1.粗细
输入者,可能拿笔,也可能拿手指,甚至可能拿鸟毛去画,这是很难控制的,所以对所的图像的识别必须考虑笔画的粗细问题.
2.拉伸
输入者可能只在画布的某个角落写字,遇到特定人群,比如小屁孩和小姑娘,他们的天性都是小笔小书,很细腻的写,相当于文字被缩小了,虽然形状可能是一样的
3.偏移
有些人写字不喜欢居中,总是偏向一边,这种情况时有发生,事实上,偏移几乎总是存在的,几乎没人能够写绝对居中的文字.
4.扭曲
由于各种条件限制,这也是很难避免的情况,比如小学生写8字总是睡着的,有些人写字总是头小屁股大等等
解决上面的问题,我设计下面四种算法:
1.最近值法
比较两个图像相同点的像素差异数,累计差异最小的为最接近的图形,对应的字符之一就是待选的字符
最近值可以应对大多数情况,兼容性非常好,但是精度比较差,需要大量的笔迹训练才能得到优秀的识别效果
2.边界检测
这种算法是为了对付缩放设计的,只要框住点阵范围,结合骨架计算就可以得出其对应满屏的字符特征,这个的算法相对比较容易一些
2.连同连异
我暂且给这么一个名称吧,因为大多数手写识别并不公布他们的算法,我就自己拟定一个算法名称,毕竟我自己想出来的
这是针对偏移设计的算法,偏移之后,大多数区域的还是相似甚至相同的,连续相同与便宜紧密关联
同时,此算法可以弥补最近值算法精度上的不足,比如下面两幅图像


注意第一幅右边有一半是白色的,运用最近值算法,此区域的匹配率是100%!而采用连同连异计算,得到的匹配率是50%,相对来说后者是更科学的.
作为我主打的算法,呵呵,有必要做详细一点的描述,我拿QQ的手写输入法来说吧,QQ手写应该是方向识别(笔画识别的),我们输入正常输入一个中字
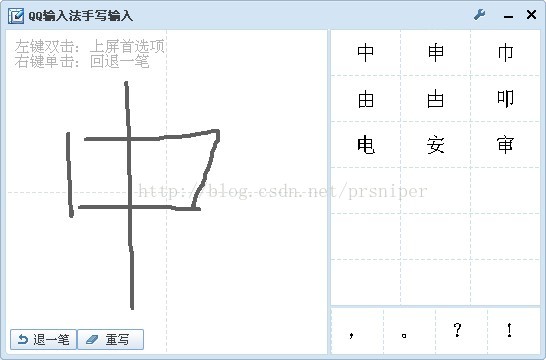
效果很好,正常识别出来,但是我把笔画逆过来写,看看结果
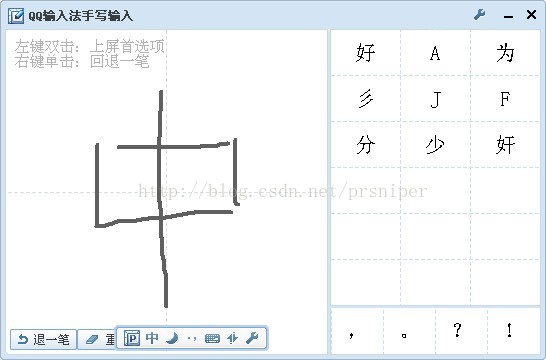
得到的结果完全风牛马不相及,甚至莫名其妙的出现了个"奸"字,奇哉怪也了吧,所以笔画或方向识别是有缺陷的,而且这种缺陷一旦放到文化程度较低的人群
就会被放大N倍,比如农民伯伯写口字都是画一个圈的,而且怎么画都有,更悲催的,把一字从右向左写,看下效果:
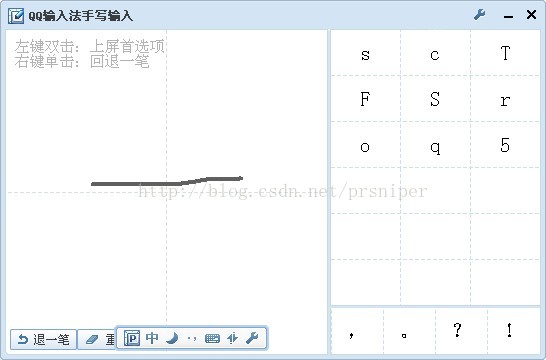
简直就是,怎么说呢,以前骂过的话又浮上心头,什么放烟花,包公车的,都想再骂过一遍了
应用我的DEMO试一下,首先是直接打印幼圆字体进行识别:
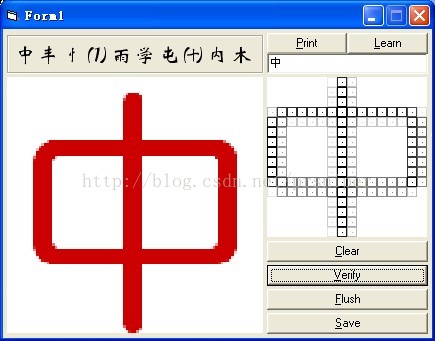
这个简单,很多OCR软件都可以识别打印字体,这里识别率的匹配是100%!,同时由于最近值算法的缺陷,次要的申等并没有识别出来
在用手写一遍,看看效果:
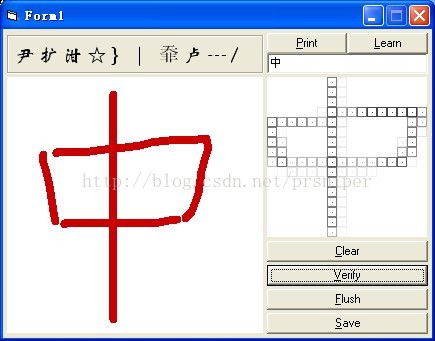
没有识别出来,因为从来没有训练过这个字,因此训练一下,再用类似的写法书写并识别:
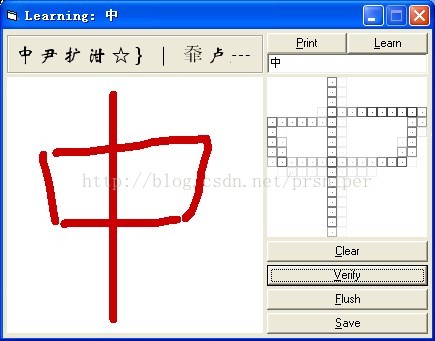
识别良好,重新入一遍看:
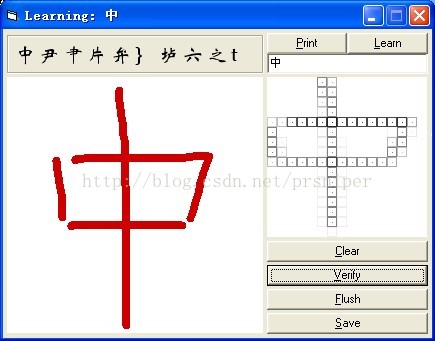
实际运行过不错,现在所缺乏的就是训练了,一旦训练一遍,类似的手写都能够优秀的识别出来,此外值得炫耀一下的是,训练完全相同的写法仅会加深对此写法的偏好
训练任何写法都不会增加库文件的大小,只会修正库文件的特征字段,DEMO在合适的时候上传给大家,看下篇吧
3.笔画识别
这就跟QQ拼音之类的有点类似了,虽然有上面的缺点,但是其优点也正好针对扭曲问题提供了完美的解决方案,但是我的做法并不是去处理笔画,以避免步QQ的后尘
我只处理一点的笔画特征,比如第一笔或最长的一笔等,一笔下去始终两点很容易得到并计算正切值,这些特征就可以确定一类字符,应对扭曲的问题
设计一种新的文件格式是针对以上所设计算法的,我暂定名称是标准点阵文件Standard Lattice File(*.slf),被我老表名字的拼音首字母踩狗屎运撞上了,一模一样
也许有人会说,坑爹的TX居然有这种漏洞,其实不是每个人都像我这样整天找漏洞和缺陷的,也是我对这种东西比较敏感吧,追求完美让我失去很多东西
具体下篇我会把DLL和相关API,类型定义和调用约定发布上来,需要的LD可以拿去用用,我先睡一觉
















 914
914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









