





前言
Oracle® Database Concepts 11gRelease 2 (11.2)Part Number E25789-01进行的1:1原文翻译。Memory Architecture 也是oracle中最为重要的一部分,同时也是一个学习的过程,与网上流传的10g concepts中文版有一定的区别,因为11g的内存结构做了很多的改进性的变化。有人说越老的concepts写的越好,确实10g的编写人在力图给人以清晰明了的阐述,另一方面给我感觉11g的concepts感觉要比10g写得内容多且深,同时让我在翻译的时候遇到了很多麻烦,11g的concepts语法写得确实要比10g的晦涩些!本次翻译有很多不足的地方,也全当一次爱好了!
14内存体系结构
本章讨论的Oracle数据库实例的内存架构
本章包含以下部分:
l介绍Oracle数据库内存体系结构
l用户全局区(User Global Area)概述
l程序全局区(Program Global Area)概述
l系统全局区(System Global Area)概述
l软件代码区(Software Code Area)概述
See Also:
lOracle Database Administrator's Guidefor instructions for configuring and managing memory
数据库内存结构介绍
当一个实例启动的时候,oracle会分配一段内存区域并且开始后台进程。这个内存区域存储如下信息:
l程序代码
l每个Session的连接信息,即使是不活跃的连接
l程序的执行信息,例如,一个多行查询需要被提取的状态
l在程序之间那些需要被共享和交互数据的锁信息
l高速缓存的数据,例如数据块和重做记录,还有那些存在于磁盘上的信息
基本内存结构
与oracle数据库有关的基础内存结构有:
l系统全局区(SGA)
SGA是一组共享内存结构,SGA的组件包含一个数据库实例的数据和控制信息。SGA被所有的服务和后台进程所共享,例如,存储在SGA中的存储数据,包括高速缓冲数据块和共享SQL区。
l程序全局区(PGA)
PGA不是一个共享的内存区域,他包含的数据和控制信息只被一个数据库程序所使用,当数据库启动的时候PGA被创建。
每个PGA的区域一一的与服务进程和后台进程所对应,有些个别的PGA集合是整个实例的PGA。数据库初始化参数设置了PGA实例的大小。
l用户全局区(UGA)
UGA内存与一个用户的session相关。
l软件代码区
软件代码区提供了一个区域去存储那些被运行的代码。Oracle数据库代码被存储在软件域,通常用户程序占用不同的区域-一个独占或者是被保护的区域。
Oracle数据库内存体系结构
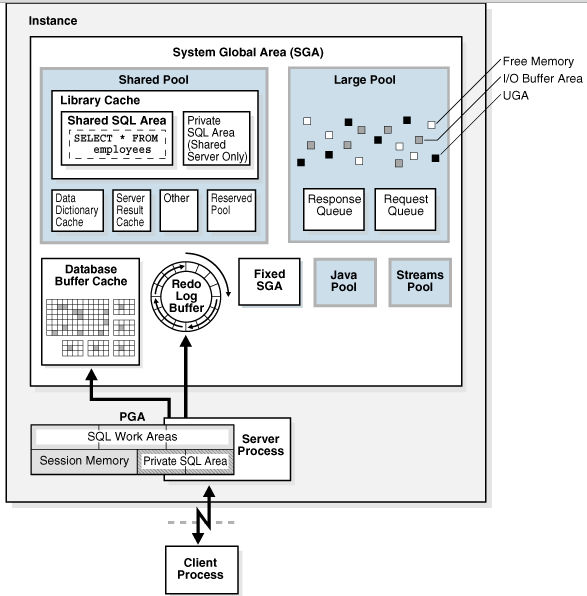
Oracle数据库内存管理
内存管理要求Oracle实例的内存结构对数据库变化的需求保持最佳的尺寸。Oracle数据库管理内存是基于内存相关的初始化参数的设置。用于内存管理的基本选项如下:
l 自动内存管理
你指定了目标实例内存大小。数据库实例的自动调谐到目标内存大小,重新分配内存实例的SGA和PGA之间所需要的。 --11g新特性现在只设置一个内存参数就可以了
l 自动共享内存管理
这种管理模式是部分自动化。你设定的目标SGA的大小,然后可以选择单独设置PGA或管理PGA工作区的总目标大小。 --10g不同于9i的特性
l 手动内存管理
设置的总内存大小,而是你设置的初始化参数单独来管理组件SGA和实例PGA。
如果您创建一个数据库,数据库配置助手(DBCA)和选择基本的安装选项,然后自动内存管理是默认设置。
如果你用DBCA命令去创建了一个数据库,在基础的安装选项中,自动内存管理师默认选项。
See Also:
- "Memory Management"for more information about memory management options for DBAs
- "Tools for Database Installation and Configuration"to learn about DBCA
- Oracle Database 2 Day DBAandOracle Database Administrator's Guideto learn about memory management options
用户全局区概述
用户全局区是一个session内存区域,它为会话变量所用,例如登陆信息,和一些其他被数据库session请求的信息。本质上来说UGA存储的是session状态。
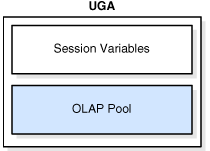
如果一个session载入了PL/SQL包到内存,然后UGA就包含了包的状态,其中存储了一特定时间包变量所设置的值。默认情况下,在这个持久会话中包变量是唯一的。
UGA中也存储了OLAP页面池。该池管理OLAP数据的网页,他等同于数据块。页池在OLAP会话开始的时候创建,结束的时候被释放。无论用户什么时候请求一个空间对象的时候,一个OLAP的会话都会自动开启的。
在一个会话周期内UGA对于数据库必须是可用的。正是由于这个原因,当使用一个共享服务时UGA不可能被存储在PGA中,因为PGA对单独的进程是特殊指定的。因此,当使用共享连接的时候,UGA存在于SGA中的,以便于共享服务进程可以通过它。当使用专有连接服务连接,UGA是存储在PGA中的。
See Also:
l "Connections and Sessions"
l Oracle Database Net Services Administrator's Guideto learn about shared server connections
l Oracle OLAP User's Guidefor an overview of Oracle OLAP
程序全局区概述
PGA指定了一块内存,这块内存被进程或线程所共用,但并不被其他的系统进程或线程所共用。因为PGA是一个特定的进程,从来没有在SGA中分配。
PGA是一个包含会话相关的变量,需要通过专用或共享服务器进程的内存堆。服务器进程分配内存结构,它需要在PGA中。
对于PGA,可以类比成一个临时的台面工作区文件员。在这个比喻中,档案管理员代表客户(客户端程序)服务器进程在做的工作。管理员清除工作区中的一部分,使用工作区来详细的存储解客户的要求和客户所要求的文件夹进行排序,然后给出相应的空间当上述工作完成后。
下图显示了PGA实例并没有被共享服务所配置,你可以使用初始化参数去设置PGA的目标最大值。这个独特的PGA值可以在目标大小范围内增长变化。
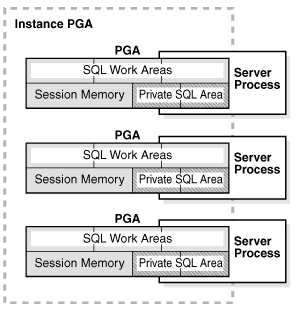
PGA的内容
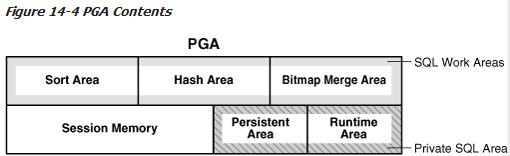
PGA是细分成不同的区域,每个区域都有不同的用途。图14-4显示了一个专用的服务器会话的PGA的可能内容。并非所有的PGA区域在每一个情况下都会存在。
私有SQL区域
一个私有的SQL区域包含SQL的解析的状态信息和其他特定会话的信息,当服务器进程执行的SQL或PL / SQL代码,过程中使用的专用SQL区存储绑定变量的值,查询执行状态信息,以及查询执行工作领域。
不要混淆私有SQL区,认为这是在UGA,共享SQL区,或是SGA中存储的执行计划。相同或不同的会话中的多个私有SQL区可以指向SGA中的一个单独执行计划。例如,20次执行SELECT * FROM Employees在一个会话中和10次在不同的会话中执行相同的查询可以共享相同的计划。每次执行的专用SQL区不共享,并可能包含不同的值和数据。
一个游标就是一个名字或是句柄对于一个特定的私有SQL区域,如图14-5所示,你可以想象成一个指针在客户端和服务端的声明。因为指针是与私有SQL区域紧密相连的,一些时候术语是互相使用的。
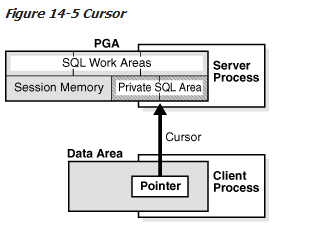
一个私有SQL区域被分为如下几个方面:
l 运行时区
此区域包含查询的执行状态信息。例如,运行时区跟踪全表扫描检索的行数。
Oracle数据库创建运行时区是执行请求的第一步。对于DML语句,当SQL声明被关闭的时候,运行时区会被释放。
l 持久性区域
这个区域包含绑定变量值。绑定变量值提供给SQL语句,当执行该语句时。只有当游标被关闭,持久性区域会被释放。
客户端进程负责管理私有SQL区域。私有SQL区的分配和释放,在很大程度上取决于应用程序,尽管一个客户端的进程能分配的私有SQL区的数量是由初始化参数OPEN_CURSORS限制。
虽然大多数用户依赖于数据库实用程序自动游标处理,Oracle数据库编程接口为开发者提供更多的控制权限在游标方面。在一般情况下,应用程序应该关闭所有打开的游标,将不能再次使用,释放持久的区域,并尽量减少应用程序所需的内存。
See Also:
- "Shared SQL Areas"
- Oracle Database Advanced Application Developer's GuideandOracle Database PL/SQL Language Referenceto learn how to use cursors
SQL工作区
一个工作区是在PGA中被私有化的分配用于内存中密集型操作。例如,一个排序操作使用的排序区去排序调整一组行信息。同样,一个哈希联接操作使用散列区建立一个哈希表从左边输入,而一个位图合并使用位图合并区域合并多个位图索引扫描检索的数据。
如下查询计划:
SQL> SELECT *
2 FROM employees e JOIN departments d
3 ON e.department_id=d.department_id
4 ORDER BY last_name;
.
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 106 | 9328 | 7 (29)| 00:00:01 |
| 1 | SORT ORDER BY | | 106 | 9328 | 7 (29)| 00:00:01 |
|* 2 | HASH JOIN | | 106 | 9328 | 6 (17)| 00:00:01 |
| 3 | TABLE ACCESS FULL| DEPARTMENTS | 27 | 540 | 2 (0)| 00:00:01 |
| 4 | TABLE ACCESS FULL| EMPLOYEES | 107 | 7276 | 3 (0)| 00:00:01 |
----------------------------------------------------------------------------
在例14-1中,运行时区跟踪全表扫描的进度。会话执行哈希联接在哈希区域通过两个表去行匹配。在排序排序区中执行order by操作。
如果要被处理的数据,不能插入到一个工作区,Oracle数据库将会把输入数据划分成更小的碎片。在这种方式中,当要把剩余且稍后要执行的数据写入到临时的磁盘存储中,数据库处理一些数据碎片在内存中。
数据库自动调谐工作区的大小,当启用自动PGA内存管理时。您也可以手动控制和调整工作区的大小。有关更多信息,请参阅“内存管理”。
用户可以对工作区的容量进行控制与调优。一般来说,更大的工作区能够显著地提高 SQL操作的性能,但代价是消耗更多的内存。最理想的情况是,工作区能够容纳 SQL语句的全部输入数据及额外的控制内存结构。否则语句的响应时间将增加,因为部分输入数据必须放入临时磁盘区。在极端情况下,如果工作区容量远小于输入数据,那么输入数据需要在临时磁盘区与工作区间多次交换。这将显著地增加 SQL操作的响应时间。
See Also:
Oracle Database Administrator's Guideto learn how to use automatic PGA management
Oracle Database Performance Tuning Guideto learn how to tune PGA memory
PGA在共享和专用服务模式下的使用
PGA内存的使用依赖于数据库是否使用了共享连接还是专用连接。表14-1给出了不同:
| 内存区 | 专用服务器 | 共享服务器 |
|
| ||
| 会话内存(session memory)的性质 | 私有的 | 共享的 |
| 持续数据区(persistent area)的位置 | PGA | SGA |
| SELECT语句的运行时区(run-time area)的位置 | PGA | PGA |
| DML/DDL 语句的运行时区的位置 | PGA | PGA |
See Also:
Oracle Database Net Services Administrator's Guideto learn how to configure a database for shared server
系统全局区概述
SGA是一个读/写存储器区域,与Oracle后台进程,构成了数据库实例。代表用户执行所有服务进程都可以读取信息,在SGA实例中。几个进程写信息到SGA中在数据库操作过程。
Note:
不驻留在SGA中的服务和后台进程,是存在于一个特殊的内存空间中的
每个数据库实例有它自己的SGA区,当数据库启动或者关闭回收内存的时候,oracle数据库自动分配SGA的内存空间。当你通过SQL*Plus和OEMu组件启动实例的,SGA的大小参数显示如下:
SQL> STARTUP
ORACLE instance started.
Total System Global Area368283648 bytes
Fixed Size1300440 bytes
Variable Size343935016 bytes
Database Buffers16777216 bytes
Redo Buffers6270976 bytes
Database mounted.
Database opened.
SGA由几个内存组件组成,这些池被用来满足一个特殊级别的内存分配请求。所有SGA组件除了重做日志缓冲区在分配和释放连续的空间单元时候都叫做颗粒。颗粒大小是特定于平台,并由SGA总大小决定。
您可以查询V $SGASTAT视图了解相关组件的信息。
最重要的SGA组件如下:
· Database Buffer Cache
· Redo Log Buffer
· Shared Pool
· Large Pool
· Java Pool
· Streams Pool
· Fixed SGA
See Also:
l "Introduction to the Oracle Database Instance"
l Oracle Database Performance Tuning Guideto learn more about granule sizing
数据缓存区
该数据库缓冲区高速缓存,也称为高速缓冲区,存储从数据文件中读取的数据块副本的内存区。一个缓冲是一个主要的内存地址,缓冲器管理器临时高速缓存一个当前或最近使用的数据块。所有并发地连接到实例上的用户进程(user process)都将共享同一个数据缓存区。
数据库用缓存区去实现如下目的:
l 优化物理I / O
数据库更新的数据块缓存和元数据存储在重做日志缓冲区的变化。一个COMMIT后,数据库的重做缓冲区写入磁盘,但不会立即将数据块写入到磁盘。相反,数据库写进程(DBWn)执行懒惰写在后台
l 保持频繁访问的块在高速缓存中,不常访问的数据块写入到磁盘
数据库智能闪存缓存(flash cache)启用时,缓冲区高速缓存的一部分可以驻留在flash cache中。对此缓冲区高速缓存扩展存储在闪存盘的移动设备,它是一种使用闪存的固态的存储设备。该数据库可以提高性能通过缓存中的缓冲区,而不是从磁盘读取闪存。
注意事项:
Database Smart Flash Cache is available only in Solaris and Oracle Enterprise Linux.
缓冲状态(buffer states)
数据库用内部算法管理缓存区的缓冲,一个缓冲区可以是下列任何的互斥状态:
未使用
缓冲是可用的因为它从来没有被使用或当前未被使用。该类型的缓冲将被数据库最早使用。
清洁状(clean)
该缓冲先前被使用且包含了一个某个时间点的一致性读的数据块。虽然包含数据但是一个“clean”的状态,所以不需要检查点。数据库可以拴住该快并且重用。
脏
该缓冲区包含了被修改的数据,此时脏数据并未提交到磁盘上。在重用它之前数据库必须执行检查点。
每个缓冲区还有一通过模式:被锁定或者是空闲状态。在内存中,当缓冲被锁而用户又想访问他的时候会导致它不能被溢出内存。多个会话不能在同一时间访问一个被锁的数据块。
数据库使用一个复杂的算法去使缓冲被频繁的访问。脏块和非脏块的指针同时存在于同一个最少使用的列表(LRU)上,LRU有热端和冷端。冷端是那个当前最少使用的,热端就是那种频繁被访问和使用的缓冲。
注意事项:
概念上来讲,这只有一个LRU算法,但是对于并发性的数据库实际上应用了多个LRU链表
缓冲模式
当一个客户端请求数据的使用,oralce将会在下列模式中从数据库中检索缓冲
| 当前模式
当前模式获取,也叫做数据块获取,就是从高速缓冲区中检索当前出现的数据块。例如,一个没有被提交的事物在一个块中被修了2行,然后当前模式检索到这些未被提交的行数据。当处于修改状态时,数据库使用数据块(DB BLOCK GETS)的获取方式最频繁,这时数据库必须更新当前块的版本。
l 一直性读模式
读一直性获取方式就是一个块的读一致性检索。这个检索可能要用到Undo数据。例如,如果一个未被提交的数据更新了一个块中的2行数据,并且如果一个单独的session要求访问这个块,然后数据库将会利用Undo数据区创建一个一致性读的数据,这些不包括未提交的更新。典型的,一个查询检索在数据库一致性读模式中。
See Also:
l "Read Consistency and Undo Segments"
l Oracle Database Referencefor descriptions of database statistics such as db block get and consistent read get
缓冲IO(Buffer I/O)
一个逻辑I/O,就是buffer I/O的别称,在高速缓冲区它涉及了缓冲的读和写。当一个被请求的缓冲没有在内存中找到的时候,数据库将会从flash cache或磁盘上拷贝缓冲到内存中,然后一个逻辑I/O将会读取这个缓冲内存。
l 缓存写
数据库的DBWn进程会定期的将缓存额脏数据写入到磁盘。DBWn在以下环境中写数据:
1. 一个服务进程在读取新块到数据库缓存是而不能找到清洁的缓存块。
由于缓存是脏的,空闲的缓存数量在减少。如果数量降低到内部阀值以下,并且如果清空缓存被要求,然后服务进程会进行单独的DBWn写操作。
数据库利用LRU算法去决定哪个脏块被写。当脏块被移动到LRU表的冷端,数据库会将他们从LRU链表移动到写队列。在队列中的DBWn写缓存写入到磁盘上,如果可能使用多块写入方式。这种方式可以阻止LRU端被脏块阻塞,并允许被找到的脏块被重新利用。
2. 数据库必须推进检查点,从实例恢复开始,该操作是在redo线程中的位置开始的。
3. 表空间被在只读模式或者离线模式中被改变
See Also:
l "Database Writer Process (DBWn)"
l Oracle Database Performance Tuning Guideto learn how to diagnose and tune buffer write issues
l 缓存读
当没有被使用的缓存数据块较低的时候,数据库必须从数据缓存区中移除buffers。这
个算法依赖于flash cache是否被启用。
n Flash cache 未被启用
当需求的时候,数据库重用每个清空的缓存,覆盖它。当这个被覆盖的内存以后被需求的时候,数据库必须要从磁盘上读取它。
n Flash cache 启用
DBWn可以将清空的内存整体写入的闪存(Flash cache)中,使它在内存中可以被重用。数据库可以保持这个内存头部在内存的LRU队列中,以使它可以跟踪状态信息和分配缓存在闪存中。如果这个缓存以后被需要,数据库就会从闪存中读取它来代替在磁盘中读取它。
当客户端程序需求一个buffer时,服务进程会搜索缓存为这个Buffer。缓存命中与是否在内存中找到该buffer有关。搜索顺序如下:
1、服务进程会在缓存区中搜索整个Buffer
如果进程找到整个的buffer,然后数据库会执行这个buffer的逻辑读。
2、服务进程会搜索缓存区中的buffer块头在闪存中的LRU链上
若果程序找到了buffer块头,然后数据库将会执行一个优化了的物理读从闪存到缓存中。
3、如果程序不能在内存中找到Buffer,服务进程将会执行如下步骤:
A、从数据文件中拷贝到内存中(物理读)
B、执行一个逻辑读,这将会到达内存中
图14-6所示的缓冲搜索顺序。扩展内存中的缓冲区高速缓存,它包含整个缓冲区和闪存缓存,其中包含缓。在图中,数据库搜索高速缓存中的缓存信息,缓冲区没有找到,从磁盘读取到内存中。

在一般情况下,访问数据通过缓存命中的速度比通过高速缓存未命中的快。缓冲区高速缓存命中率的措施往往是数据库需要在高速缓冲区中发现了一个请求块,而不需要从磁盘读取它。
该数据库可以执行的物理读取,无论是从数据文件或临时文件。从数据文件中读取的操作相伴的是逻辑I / O。读取临时文件时出现的内存不足,强制数据库到一个临时表中的数据写入和以后读取回来。这些物理读取绕过高速缓存,并不会产生一个逻辑I / O
See Also:
Oracle Database Performance Tuning Guideto learn how to calculate the buffer cache hit ratio
l 缓存触摸计数
数据库测量访问缓冲区的频率是通过LRU列表使用触摸计数器。这种机制是通过使数据库增加一个计数,当缓存被锁,而不是去不断的阻塞缓存中的LRU链。
Note:
数据库不是物理的移动内存中的数据块,这种移动是通过改变链表上的指针方式完成的
当缓冲区被锁定,数据库确定触摸计数最后一次是什么时间增加的。如果计数递增超过3秒前,那么递增计数,否则,计数保持不变。三秒规则防止内存中突发性的锁当多次碰触时。例如,一个会话可能会在数据块中插入几行,但数据库认为这些插入操作作为一次碰触。
如果缓冲区的LRU的冷端,但它的触摸计数高,则缓冲区移动到热端。如果触摸计数低,则该Buffer移除高速缓存。
l 缓存和全表扫描
当buffer块必须从磁盘上读取时,数据库会将buffer插入到LRU链表的中间部位。通过这种方式热块可以被保留在内存中以至于不必在从磁盘再次读取。
一个全表扫描,顺序读取表的高水位标记(见"Segment Space and the High Water Mark")下的所有行所会带来的一个问题。假设一个表段中的块的总大小是大于高速缓存的大小。完整扫描此表可能会清理掉缓存区,阻止数据库对缓冲区的维护和被频繁的访问。
作为一个大表的全扫描的结果读入数据库缓存的块是区别于其他类型的读取。数据块立即可以重用的,以防止频繁的扫描被清理出缓冲区。
在罕见的情况下,默认的行为是不希望,你可以改变缓存表中的属性。在这种情况下,数据库不强制或锁块在高速缓存中,但会将他们想起他块一样从缓存中移除。行使此选项时,请小心,因为一个完整的一个大表扫描可能将其他的数据块清除出缓存。
See Also:
l Oracle Database SQL Language Referencefor information about theCACHEclause
l Oracle Database Performance Tuning Guideto learn how to interpret buffer cache advisory statistics
缓冲池(buffer pool)
一个缓冲次就是缓冲的集合,数据缓冲区被划分成一个或多个缓冲池。
你可以手动配置分割缓冲池,这样可以保持数据在缓存中或使那些新被使用后的数据立即进入到缓存中。用户可以指定方案对象(schema object)(表,簇,索引,及分区)使用相应的缓冲池,以便控制数据被移出缓存区的时机。
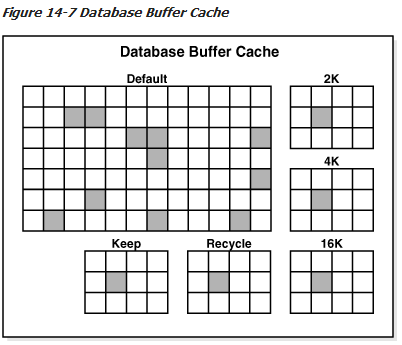
可设置的缓冲池如下:
- KEEP 缓冲池将一直保留存储在其中的方案对象的数据。
- RECYCLE 缓冲池将随时清除存储在其中不再被用户需要的数据。
- DEFAULT 缓冲池中存储的是没有被指定使用其他缓冲池的方案对象的数据,以及被显式地指定使用 DEFAULT缓冲池的方案对象的数据。
数据库有一个标准的块大小。您可以创建一个不同于标准尺寸的块大小的表空间,每个非默认块大小有自己的池。Oracle数据库管理这些池的的方式与默认池的管理方式一样。
缓冲区高速缓存使用多个池时,图14-7所示的结构。缓存区包含默认池,keep池和recycle池。缺省情况下块大小为8KB。缓存使用非标准块大小为2 KB,4 KB和16 KB,这些表空间使用独立池。
See Also:
lOracle Database 2 Day DBAandOracle Database Administrator's Guideto learn more about buffer pools
lOracle Database Performance Tuning Guideto learn how to use multiple buffer pools
重做日志缓冲区
重做日志缓冲区在SGA中是一个循环的缓冲,他记录了描写数据库变化的信息。重做
记录包含了必要的重建信息,或那些DML或DDL操作产生的重做信息。数据库恢复利用数据文件的重做条目去重建丢失的更改。
Oracle数据复制重做条目到SGA中的重做日志缓冲区中从用户的内存中。重做条目在缓冲中的组成是连续、有顺序的。后台进程LGWR将重做日志buffer写到磁盘上的联机在线日志组中。图14-8生动的显示了这个环节。
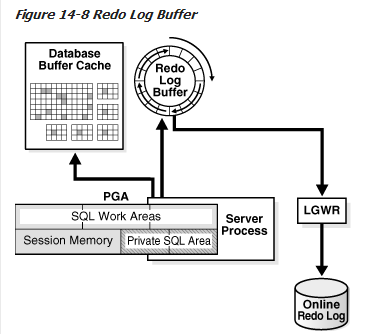
当DBWn将数据块分散的写到磁盘上的时候,LGWR将重做信息有序的写道磁盘上。散列写会比顺序写更慢些,因为LGWR可以使用户避免当DBWn完成它缓慢写的等待,是数据库显示出更佳的性能。
LOG_BUFFER这个数据库初始化参数指定了oracle数据库日志内存的大小。不想SGA其他的组件,重做日志缓冲区和固定的SGA缓冲内存不能被细分成颗粒。
See Also:
l"Log Writer Process (LGWR)"and"Importance of Checkpoints for Instance Recovery"
lOracle Database Administrator's Guidefor information about the online redo log
共享池(share pool)
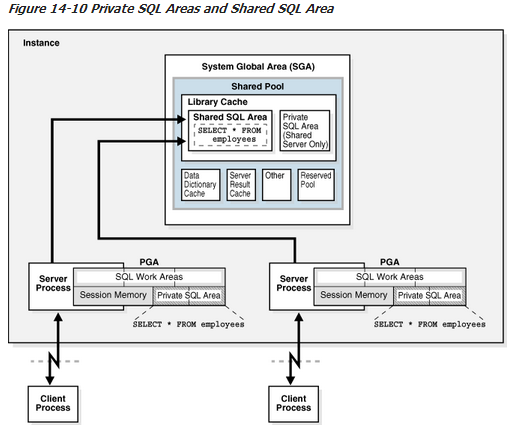
该共享池缓存各类程序数据。例如,共享池存储SQL、PL / SQL代码,系统参数和数据字典信息。在几乎每一个在数据库中发生的操作,都共享池参与。例如,如果用户执行一个SQL语句,那么Oracle数据库需要访问共享池。
共享池被分成几个子组件,其中最重要的是,如图14-9所示。
See Also:
- Oracle Database Performance Tuning Guideto learn more about managing the library cache
- Oracle Database Advanced Application Developer's Guidefor more information about shared SQL
程序单位和库高速缓存(library cache)
库高速缓存存放可执行的PL / SQL程序和Java类。这些产品被统称为程序单元。
数据库处理程序单元类似于SQL语句。例如,数据库中分配一个共享区来保存一个PL / SQL程序编译形式的解析。该数据库分配一个私人有域缓存特定会话中运行的程序,包括本地,全局和包变量,缓冲区执行的SQL值。如果有多个用户运行相同的程序,然后每个用户维护一个单独的副本,他或她的私有SQL区,其持有特定会话的值,并访问一个共享SQL区。
PL/SQL内所包含的独立 SQL语句的处理方式与上节所讲述的相同。尽管这些 SQL语句包含于程序结构内,她们依然使用自己的共享区存储解析结果,每个执行此语句的会话也将拥有一个与此语句相关的私有区。
共享池内存的分配与重用
当一条新的SQL语句被解析的时候,数据将会分配共享池内存,这个内存大小取决于
该语句的复杂程度。
一般来说,共享池(shared pool)内的数据(共享 SQL 区(shared SQL area)或数据字典行缓存(dictionary row))始终有效,直到改进的 LRU 算法(modified LRU algorithm)决定将此数据清除。当新数据需要从共享池分配空间时,共享池内较少使用的数据就将被释放。应用改进的 LRU 算法后,被多个会话所使用的共享池数据将被一直保存在内存中(只要还有会话在使用),即便最初创建此共享池数据的进程已经结束。因此,在多用户的 Oracle系统中,处理 SQL语句的开销能够被最小化。
如果空间被新项目需求则数据库会释放那些不经常使用的内存。如果一个打开但有一段时间没有使用过的游标所持有的SQL共享区域,也会被移除,如果这个打开的游标后来也被用来执行它的语句,数据库会为他重新解析语句被分配一个新的共享SQL区。
当以下情况出现时,也会将共享 SQL区清除出共享池
- 当用户使用 ANALYZE语句更新或删除了方案对象(表,簇,索引等)的统计信息后,如果一个共享 SQL区内的 SQL语句引用了被分析过的方案对象,那么此共享 SQL区将被清除出共享池。当被清除的 SQL语句再次运行时,此 SQL语句将被重新解析并保存到新的共享 SQL区内,以反映方案对象最新的统计信息。
- 如果 SQL语句引用的方案对象经过了修改,则相应的共享 SQL区将被标记为无效(invalidated),且此 SQL语句下次运行时必须被重新解析。
- 当管理员改变了数据库的全局数据库名(global database name)后,共享池内的所有数据都将被清除。
- 管理员能够手工清除共享池内的全部信息以便评估系统性能(此种评估针对共享池,而非数据缓存(buffer cache)),而无需关闭实例再重新打开。这项工作是通过 ALTER SYSTEM FLUSH SHARED_POOL 语句完成的。
·如果一个SQL语句中涉及到了用户对象的统计信息,并且如果稍后它被一个DDL语句所更改,随后数据库将会是这块SQL共享区域失效。优化器必须在下一次运行的时候重新解析这个新状态。
See Also:
- Oracle Database SQL Language Referencefor information about usingALTER SYSTEM FLUSH SHARED_POOL
- Oracle Database Referencefor information aboutV$SQLandV$SQLAREAdynamic views
数据字典缓存区
数据字典是一系列保存了数据库参考信息(例如数据库结构,数据库用户等)的表和视图。Oracle需要频繁地使用经过解析的 SQL语句访问数据字典。数据字典信息对 Oracle能否正常运行至关重要。
由于 Oracle对数据字典的访问极为频繁,因此内存中有两个特殊区域用于存储数据字典信息。一个区域是数据字典缓存区(data dictionary cache),因为数据在其中是以数据行的形式存储的(通常缓冲区内保存的是完整的数据块),所以此区域也被称为行缓存(row cache)。另一个区域为库缓存(library cache)。所有 Oracle数据库进程在访问数据字典信息时都能够共享这两个缓存区。
数据字典被数据库经常访问以至于如下的特殊内存区域会被设计去保存字典数据:
1、Data dictionary cache
该缓存保存数据库对象的信息。这个缓存也被行缓存所知,因为它拥有行数据,而不是内存块。
2、Library cache
所有服务进程通过数据字典信息共享这行缓存。
See Also:
- Chapter 6, "Data Dictionary and Dynamic Performance Views"
- Oracle Database Performance Tuning Guideto learn how to allocate additional memory to the data dictionary cache
服务结果缓存
不像缓冲池一样,服务结果池拥有结果的集合而不是数据块。结果缓冲池包含SQL查询的结果缓存和PL/SQL结构结果的缓存,他们共享相同的基础结构。
客户端结果缓冲不同于服务结果缓冲,客户端缓存是在应用级别上被配置的并且在客户端的内存中分配,而不是在数据库的内存中。
See Also:
- Oracle Database Administrator's Guidefor information about sizing the result cache
- Oracle Database PL/SQL Packages and Types Referencefor information about theDBMS_RESULT_CACHEpackage
- Oracle Database Performance Tuning Guidefor more information about the client result cache
SQL查询结果缓存
数据库可以存储查询的结果并且可以在SQL查询结果缓存中区查询这些碎片,利用这些缓存结果为未来的查询和碎片查询。大多数的应用获益于这个性能上的改进。
例如,假设一个应用程序反复运行相同的SELECT语句。如果结果被缓存,那么数据库立即返回。该数据库以这种方式,避免了昂贵重读块的操作和重新计算的结果。每当一个事务修改那些用于构建缓存的结果的数据或数据库对象的元数据,该数据库会自动缓存结果无效。
用户可以注释查询用RESULT_CACHE提示来提示,数据库来存储SQL查询结果到缓存中。该的初始化RESULT_CACHE_MODE参数决定是否用于所有的查询(如果可能),或只为带有注释的SQL查询结果缓存。
See Also:
- Oracle Database Referenceto learn more about theRESULT_CACHE_MODEinitialization parameter
- Oracle Database SQL Language Referenceto learn about theRESULT_CACHEhint
PL / SQL函数结果缓存
PL / SQL函数结果缓存存储函数的结果集。没有缓存,每秒一次的函数调用1000次将会花费 1000秒。使用高速缓存,1000次相同的输入的函数调用可能需要1秒。被频繁调用的函数在结果缓存中很好的被使用,这依赖于相对应的静态数据。
PL / SQL函数代码可以包括请求缓存其结果。这个函数调用后,系统会检查缓存中。如果缓存包含具有相同的参数值的以前的函数调用的结果,那么系统会返回缓存的结果给调用者,并且不重新执行函数体。如果缓存中不包含的结果,然后系统执行函数体,将增加缓存结果给缓存在返回控制给调用者之前。
注意事项:
你可以指定数据库对象去计算缓存结果,如果他们被更新了,缓存结果建辉失效并且必须被重新计算。
缓存可以积累许多结果-每个都被执行了的函数唯一的组合参数值结果。如果数据库需要更多的内存,然后它就会交换出更多的结果缓存。
See Also:
- Oracle Database Advanced Application Developer's Guideto learn more about the PL/SQL function result cache
- Oracle Database PL/SQL Language Referenceto learn more about the PL/SQL function result cache
保留池(Reserved Pool)
保留池是在共享内存中的一部分内存,数据库可以分配连续大块的内存。
在共享内存中分配内存是以大块形式分配的。大的数据对象(超过5KB)的大块被分配到内存中而不要求一个单独的连续区域。这种方式中,由于残片数据库减少了溢出连续内存的概率。
Java、PL/SQL、SQL游标非频繁分配超过5K大小的共享池。为了让这些分配最有效的发生,数据库隔离少量共享池为保留池。
See Also:
Oracle Database Performance Tuning Guideto learn how to configure the reserved pool
大型池(large pool)
大池是一个可选的内存区,供一次性大量的内存分配使用,例如:
- 共享服务器(shared server)及 Oracle XA 接口(当一个事务与多个数据库交互时使用的接口)使用的会话内存(session memory)
- I/O服务进程
- Oracle备份与恢复操作
如果从大型池内为共享服务器,Oracle XA,或并行查询缓冲区(parallel query buffer)分配会话内存,共享池(shared pool)就能够专注于为共享 SQL区(shared SQL area)提供内存,从而避免了共享池可用空间减小而带来的系统性能开销。
此外,Oracle备份与恢复操作,I/O服务进程,及并行执行缓存所需的存储空间通常为数百 KB。与共享池相比,大型池能够更好地满足此类大量内存分配的要求。
图14-11是一个图描绘的大池。
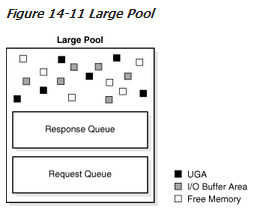
大池不同于保留空间在共享池中,保留空间使用相同的LRU链从共享池中分配内存。大池不适用LRU链表,内存块被分配并且不能在他们下次使用前被释放。一旦大块被释放了,其他的进程就能使用它。
See Also:
- "Dispatcher Request and Response Queues"to learn about allocating session memory for shared server
- Oracle Database Advanced Application Developer's Guideto learn about Oracle XA
- Oracle Database Performance Tuning Guidefor more information about the large pool
- "Parallel Execution"for information about allocating memory for parallel execution
JAVA池(Java Pool)
SGA内的 Java池(Java pool)是供各会话内运行的 Java代码及 JVM内的数据使用的。内存中包括通信借宿后被迁移到JAVA会中的JAVA对象
对于专用服务器连接,Java池包括每个Java类的共享部分,包括例如代码的载体,但不是每个Java的会话状态的方法和只读内存。对于共享服务器,池包括每个类和一些UGA被用于每个会话的一部分共享,每个UGA的增长和会话都是必须的,但总UGA的大小必须在符合的Java池空间。
Java池顾问(Java Pool Advisor)收集的统计数据能够反映库缓存(library cache)中与 Java相关的内存使用情况,并预测 Java池容量改变对解析性能的影响。当 statistics_level参数被设置为或 TYPICAL更高时,Oracle会自动地启动 Java池顾问。当 Java池顾问被关闭后,其收集的统计信息将被清除。
See Also:
- Oracle Database Java Developer's Guide
- Oracle Database Performance Tuning Guideto learn about views containing Java pool advisory statistics
数据流池(Stream Pool)
在数据库中,流池存储了消息队列缓存并且为Oracle Stream的捕获和应用队列提供内存。管理员可以在 SGA 内配置一个被称为数据流池(Streams pool)的内存池供 Oracle数据流(Stream)分配内存。管理员需要使用STREAMS_POOL_SIZE初始化参数设定数据流池的容量(单位为字节)。
除非你特殊配置它,否则数据流池初始化时0的。这个池的大小被Oracle Stream所动态的请求。
See Also:
Oracle Database 2 Day + Data Replication and Integration GuideandOracle Streams Replication Administrator's Guide
固定的SGA
固定的SGA是一个内部处理机制的区域。例如,固定的SGA包含:
1.实例和数据库的部分的一般信息,那些后台进程需要处理的信息
2.进程间需要交流的信息,例如块的信息
固定SGA的大小被数据库设定的,并不能手动设定。他的大小随着版本的发布而改变。
软件代码区概述
软件代码区是内存的一部分,代码是可主动或被动运行的。Oracle数据库的代买被存储在一个软件代码区中。这部分区域是非常独特和具有保护性的比用户程序区。
软件区通常在大小上是静态的,当软件被更新或重新安装时它被改变。这些被请求的区域大小随操作系统的而变化的。
软件代码区是只读的并且被共享或不被共享的安装。一些数据库的工具和实用程序,例如oracle窗体和SQL*Plus,可以被共享的安装,但是有些就不行。当可能的情况下,数据库代码是共享的,以至于用户可以访问它而不用在内存中有多个拷贝,结果就是减少了主要的内存和增强了整体性能。数据库多实例可以使用同一个数据库代码区,如果它们运行在同一台电脑上。
Translator:Paladin















 335
335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









