









大数据平台开发规范示例
一、前要
内容包括但不限于平台对内和对外的需求、代码开发、测验和上线流程规范。
以大数据技术平台架构的视角,梳理如何与数仓、数据分析同学协作的规范示例,仅供参考。
二、环境信息
首先需要梳理出各组件的部署方式、host及版本等信息,让其他平台、数仓或数据分析同学了解平台底座的部署情况。
三、需求流程
3.1 主流程
整体需求主流程如下。
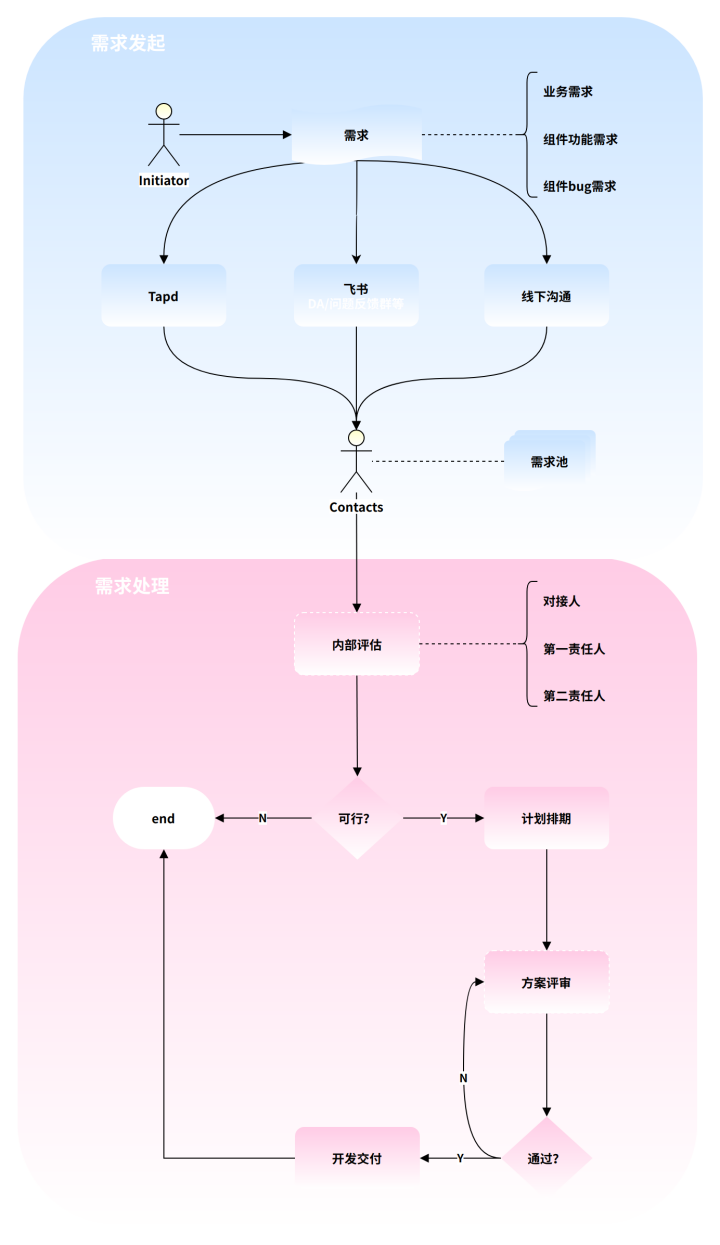
3.2 需求发起
3.2.1 需求发起人
包括但不限于如下人员。
- 数仓开发
- 数据分析
- 数据产品
- 内部人员(主动挖掘)
3.2.2 需求类型
- 业务需求:需要通过组件支撑的业务需求,例如应用脚本开发
- 组件功能需求:组件功能扩展,例如connector扩展或造轮子
- 组件bug需求:由于组件设计缺陷或版本自身缺陷导致的bug,需要结合社区和源码进行解决
3.2.3 需求渠道
- Tapd/DevOps/禅道(协作管理平台)
- 主要为组件bug需求,例如提交地址:数据平台_线上BUG汇总
- 飞书/钉钉/企业微信(企业办公平台)
- 主要为紧急且重要的问题/需求,可通过DA(数据需求入口群)、问题群或私聊反馈(允许私聊/私活,但需要内部互通,避免信息差),当前相关问题会记录于统一锚点:新集群问题记录
- 线下沟通
- 较为繁杂的需求可通过线下沟通,需要进行拆解和确认,例如:数仓需求记录
3.2.4 需求对接人
如果团队当前还处于发展中未成熟阶段,不建议采用【统一对接人】的方式,可采用【一主多从】的策略,即除团队负责人外,其他成员都可以为’需求对接人’,但无论谁是’需求对接人’,都需将需求记录于【需求池】,避免信息差。
- 团队负责人
- 组件责任人
- 每个组件的管理(技术支持/答疑)需要指定第一责任和第二责任人
- 需求池
- 对需求的记录,避免需求丢失,有助于建立清晰的需求回溯,需求池记录列表:大数据平台需求池
3.3 需求处理
3.3.1 内部评估
- 对于可快速响应和处理的小需求可跳过这步及后续的流程,例如doris因为大sql内存oom而导致读写失败的问题
- 对于无法快速响应和处理的需求,需要由对接人组织临时会议,进行内部评估,例如doris升级事项
- 内部评估需要确认事项
- 需求是否合理及是否需要进行后续处理
- 明确需求优先级
- 明确需求处理人
3.3.2 计划排期
- 由需求处理人根据需求优先级进行排期,并反馈给内外部相关人员
3.3.3 方案评审
- 由需求处理人输出方案,方案形式可采用列表、123陈述、流程图或文档形式
- 对于复杂需求/项目可先后输出概要和详细方案,例如需要自研中间件或应用系统底座等
- 由需求处理人组织,评审方式可在座位上或会议等形式进行
- 参会人员必须两人或两人以上,视需求而定是否需要拉上发起人
3.3.4 开发交付
- 根据排期时间进行开发、测试及交付,如若因其它紧急事项需优先处理,可协调顺延
- 具体流程参考如下【开发流程】
四、开发流程
包括开发、测试和上线流程。
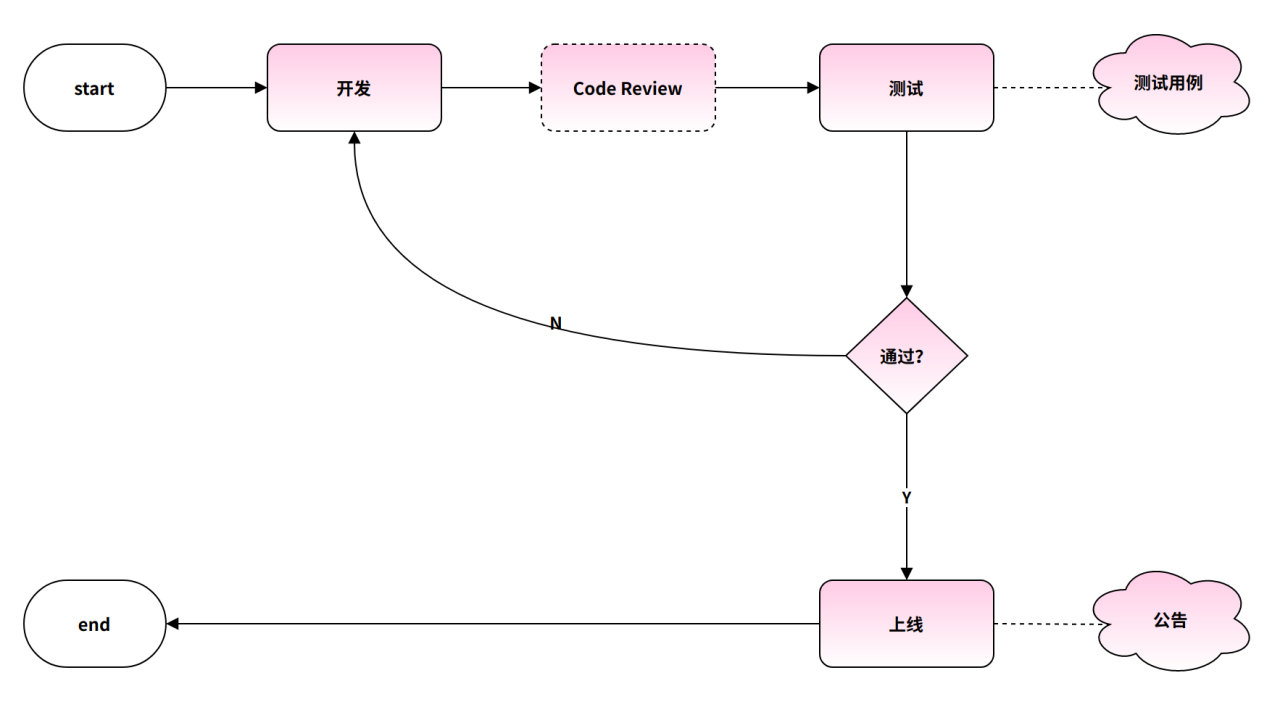
4.1 开发
- 如果有概要或详细方案设计(流程图),需严格遵循
- 按排期进行开发,每周或隔天进行进度反馈,避免信息差
- 对于公共工具类和api,可建立私有maven仓库进行统一管理
- 开发完的程序无法通过测试,则需要即刻进行返工重新发起后续流程
4.2 Code Review
- 随着时间推移,组件改造、脚本或api等开发代码量会越来越多,代码review需重视
- 促进团队技术氛围
- 提升代码质量及统一规范
- 避免’当局者迷’和’重复造轮’现象
- cr环节需要耗费一定的时间,故排期时需要包含cr的时间
4.3 测试
- 需输出相应的测试用例,包含但不限于自测、联调、场景验证和读写压测等
- 用例形式不限,可通过列表、123陈述、流程图或思维导图的形式输出
4.4 上线
- 上线流程需遵循【运维规范】
- 涉及组件内容变更(bug修复、参数调整、组件升级和重启等)需提前发出公告
4.4.1 升级公告示例
[喇叭][喇叭]【Doris Be2.0升级通知】
@人员
变更时间:2023-08-08 12:12 至 2023-08-08 13:13
变更类型:BE滚动升级
变更版本:1.2.6-release升级至2.0-roc3
变更内容:仅升级BE
变更原因:
1. 引入workgroup和倒排索引等2.0新特性
2. 使用新优化器提升整体查询效率
3. ......
测验结果:升级前测试报告
回滚策略:无
预计影响范围:doris上游任务可能会存在闪断
4.4.2 调优公告示例
[喇叭][喇叭]【Dolphinscheduler调优通知】
@人员
变更时间:2023-08-08 13:13 至 2023-08-08 14:14
变更类型:调优重启
变更内容:
1. datasource调整为druid
2. 默认连接大小由50调整为100
3. 新增ldap模块,ds登录改为sso账号密码登录
预计影响范围:所有ds调度任务(重启后自动重试)
4.4.3 重启公告示例
[喇叭][喇叭]【Doris Be紧急重启通知】
@人员
变更时间:2023-08-08 00:00 至 2023-08-08 01:01
变更类型:重启
变更内容:无
变更原因:进程假死
预计影响范围:doris上游任务可能会存在闪断
4.4.4 完成公告示例
【XXX完成通知】
完成时间:2023-08-08 08:08
完成结果:升级完成/调优完成/重启完成
完成说明:顺风顺水顺财神
五、开发规范
5.1 数据库
- 拒绝select *
- 所有表都需要添加注释
- 临时库/表名必须以tmp_工号为前缀
- 根据需求取舍选择范式或反范式设计
- 库名、表名和字段名禁止使用保留字段
- 库名、表名和字段名必须使用小写字母,并采用下划线分割
5.2 JAVA
详细可参考阿里Java编码规范 。
5.2.1 命名
- 类名使用UpperCamelCase风格,但以下情形例外:DO / BO / DTO / VO / AO / PO等
- 常量命名全部大写,单词间用下划线隔开,力求语义表达完整清楚,不要嫌名字长
- 方法名、参数名、成员变量、局部变量都统一使用lowerCamelCase风格,必须遵从驼峰形式
5.2.2 常量
- 不允许任何魔法值 ( 即未经定义的常量 ) 直接出现在代码中
- long 或者 Long 初始赋值时,使用大写的 L ,不能是小写的 l ,小写容易跟数字 1 混淆,造成误解
5.2.3 注释
- 谨慎注释掉代码;在上方详细说明,而不是简单地注释掉;如果无用,则删除
- 类、类属性、类方法的注释必须使用 Javadoc 规范,使用/*内容/格式,不得使用 // xxx 方式
5.3 Git策略
如图所示,主要分3类分支
- prod/online:生产发布的唯一出口分支。
- test/pre:测试/预上线分支,从prod/online拉取代码。
- feature:需求或新特性开发分支,从prod/online拉取代码。
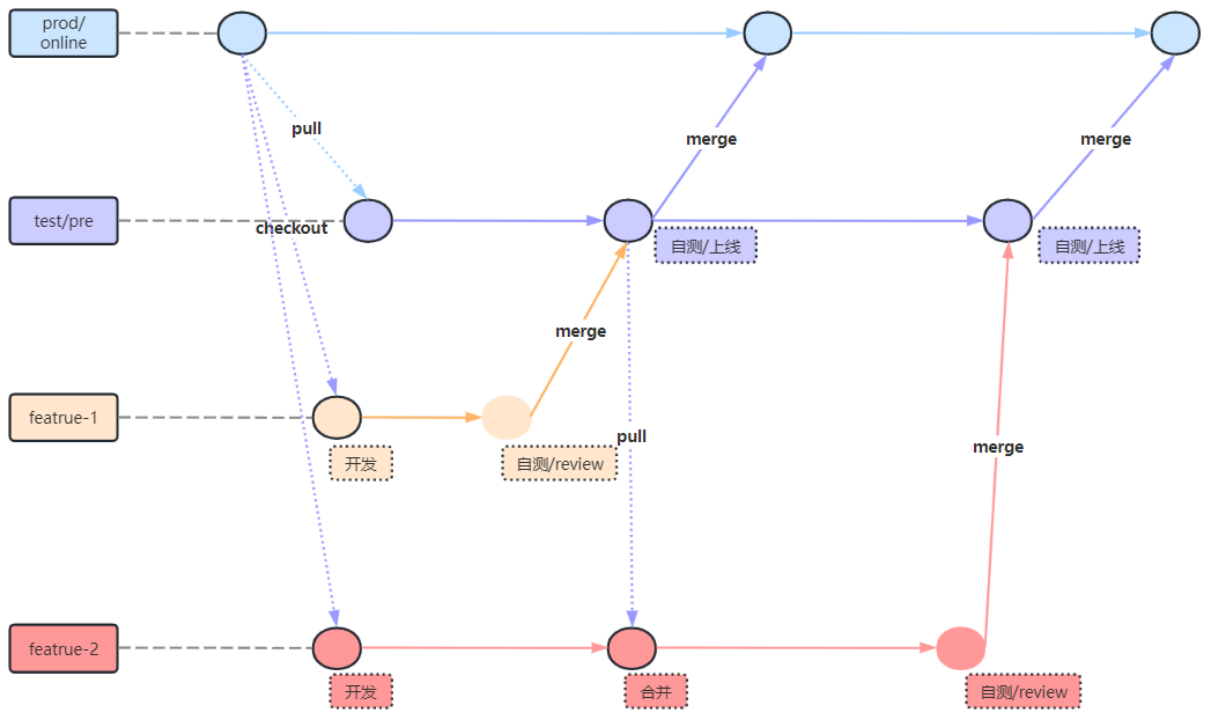
5.4 Code Review
- 测试前需进行cr,或者同步进行
- 对每次的merge request都进行cr,即mr即cr,避免mr堆积
- cr时可先输出代码的主流程图,事半功倍
- 小需求私下review
- 可2~3人到电脑旁review
- 先讲需求再review
- 核心流程会议review
- 主要review流程,让参会人员都熟悉流程
- 其次再review核心代码以及配置相关的内容
大数据平台开发规范示例分享至此结束,查阅过程中若遇到问题欢迎留言交流

















 2797
2797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











