









数据
df.to_csv('traffic1.txt', header=None, index=None)
df

数据为每小时记录一次的交通流量数据,每周有几天出现早高峰。
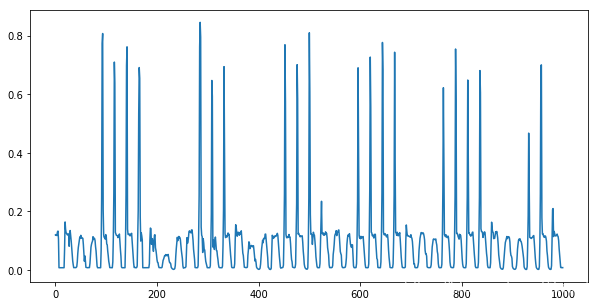
dataset
import torch
import numpy as np;
from torch.autograd import Variable
def normal_std(x):
return x.std() * np.sqrt((len(x) - 1.)/(len(x)))
class Data_utility(object):
# train and valid is the ratio of training set and validation set. test = 1 - train - valid
def __init__(self, file_name, train, valid, cuda, horizon, window, normalize = 2):
self.cuda = cuda;
self.P = window;
self.h = horizon
fin = open(file_name);
self.rawdat = np.loadtxt(fin,delimiter=',')
if(len(self.rawdat.shape)) == 1:
self.rawdat = self.rawdat.reshape(len(self.rawdat), -1)
self.dat = np.zeros(self.rawdat.shape)
self.n, self.m = self.dat.shape;
self.normalize = 2
self.scale = np.ones(self.m);
self._normalized(normalize);
self._split(int(train * self.n), int((train+valid) * self.n), self.n);
self.scale = torch.from_numpy(self.scale).float();
tmp = self.test[1] * self.scale.expand(self.test[1].size(0), self.m);
if self.cuda:
self.scale = self.scale.cuda();
self.scale = Variable(self.scale);
self.rse = normal_std(tmp);
self.rae = torch.mean(torch.abs(tmp - torch.mean(tmp)));
def _normalized(self, normalize):
#normalized by the maximum value of entire matrix.
if (normalize == 0):
self.dat = self.rawdat
if (normalize == 1):
self.dat = self.rawdat / np.max(self.rawdat);
#normlized by the maximum value of each row(sensor).
if (normalize == 2):
for i in range(self.m):
self.scale[i] = np.max(np.abs(self.rawdat[:,i]));
self.dat[:,i] = self.rawdat[:,i] / np.max(np.abs(self.rawdat[:,i]));
def _split(self, train, valid, test):
train_set = range(self.P+self.h-1, train);
valid_set = range(train, valid);
test_set = range(valid, self.n);
self.train = self._batchify(train_set, self.h);
self.valid = self._batchify(valid_set, self.h);
self.test = self._batchify(test_set, self.h);
def _batchify(self, idx_set, horizon):
n = len(idx_set);
X = torch.zeros((n,self.P,self.m));
Y = torch.zeros((n,self.m));
for i in range(n):
end = idx_set[i] - self.h + 1;
start = end - self.P;
X[i,:,:] = torch.from_numpy(self.dat[start:end, :]);
Y[i,:] = torch.from_numpy(self.dat[idx_set[i], :]);
return [X, Y];
def get_batches(self, inputs, targets, batch_size, shuffle=True):
length = len(inputs)
if shuffle:
index = torch.randperm(length)
else:
index = torch.LongTensor(range(length))
start_idx = 0
while (start_idx < length):
end_idx = min(length, start_idx + batch_size)
excerpt = index[start_idx:end_idx]
X, Y= inputs[excerpt], targets[excerpt]
if (self.cuda):
X, Y = X.cuda(), Y.cuda()
yield Variable(X), Variable(Y)
start_idx += batch_size
data = Data_utility(file_name='traffic1.txt', train=0.6, valid=0.2, cuda=False, horizon=12, window=24*7, normalize = 2)
print(data.train[0].shape, data.train[1].shape) # torch.Size([10347, 168, 1]) torch.Size([10347, 1])
window = data.train[0].shape[1]
n_val = data.train[0].shape[2]
optimizer
import math
import torch.optim as optim
class Optim(object):
def _makeOptimizer(self):
if self.method == 'sgd':
self.optimizer = optim.SGD(self.params, lr=self.lr)
elif self.method == 'adagrad':
self.optimizer = optim.Adagrad(self.params, lr=self.lr)
elif self.method == 'adadelta':
self.optimizer = optim.Adadelta(self.params, lr=self.lr)
elif self.method == 'adam':
self.optimizer = optim.Adam(self.params, lr=self.lr)
else:
raise RuntimeError("Invalid optim method: " + self.method)
def __init__(self, params, method, lr, max_grad_norm, lr_decay=1, start_decay_at=None):
self.params = list(params) # careful: params may be a generator
self.last_ppl = None
self.lr = lr
self.max_grad_norm = max_grad_norm
self.method = method
self.lr_decay = lr_decay
self.start_decay_at = start_decay_at
self.start_decay = False
self._makeOptimizer()
def step(self):
# Compute gradients norm.
grad_norm = 0
for param in self.params:
grad_norm += math.pow(param.grad.data.norm(), 2)
grad_norm = math.sqrt(grad_norm)
if grad_norm > 0:
shrinkage = self.max_grad_norm / grad_norm
else:
shrinkage = 1.
for param in self.params:
if shrinkage < 1:
param.grad.data.mul_(shrinkage)
self.optimizer.step()
return grad_norm
# decay learning rate if validation performance does not improve or we hit the start_decay_at limit
def updateLearningRate(self, ppl, epoch):
if self.start_decay_at is None or epoch <= self.start_decay_at:
return
if self.last_ppl is not None and ppl > self.last_ppl:
self.start_decay = True
if self.start_decay:
self.lr = self.lr * self.lr_decay
# print("Decaying learning rate to %g" % self.lr)
#only decay for one epoch
self.start_decay = False
self.last_ppl = ppl
self._makeOptimizer()
model
import torch
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self, n_val, window, hidRNN):
super(Model, self).__init__()
self.use_cuda = True
self.P = window # 输入窗口大小
self.m = n_val # 列数,变量数
self.hidR = hidRNN
self.GRU = nn.GRU(self.m, self.hidR)
self.linear = nn.Linear(self.hidR, self.m)
def forward(self, x):
# x: [batch, window, n_val]
# batch_size = x.shape[0]
# x_flat = x.view(batch_size, -1)
x1 = x.permute(1, 0, 2).contiguous() # x1: [window, batch, n_val]
_, h = self.GRU(x1) # r: [1, batch, hidRNN]
h = torch.squeeze(h,0) # r: [batch, hidRNN]
res = self.linear(h) # res: [batch, n_val]
return res
train
def train(data, X, Y, model, criterion, optim, batch_size):
model.train()
total_loss = 0
n_samples = 0
for X, Y in data.get_batches(X, Y, batch_size, True):
model.zero_grad();
output = model(X);
scale = data.scale.expand(output.size(0), data.m)
loss = criterion(output * scale, Y * scale);
loss.backward();
grad_norm = optim.step();
total_loss += loss.item();
n_samples += (output.size(0) * data.m);
return total_loss / n_samples
def evaluate(data, X, Y, model, evaluateL2, evaluateL1, batch_size):
model.eval()
total_loss = 0
total_loss_l1 = 0
n_samples = 0
predict = None
test = None
for X, Y in data.get_batches(X, Y, batch_size, False):
output = model(X)
if predict is None:
predict = output
test = Y
else:
predict = torch.cat((predict,output))
test = torch.cat((test, Y))
scale = data.scale.expand(output.size(0), data.m)
total_loss += evaluateL2(output * scale, Y * scale).item()
total_loss_l1 += evaluateL1(output * scale, Y * scale).item()
n_samples += (output.size(0) * data.m)
rse = math.sqrt(total_loss / n_samples)/data.rse
rae = (total_loss_l1/n_samples)/data.rae
predict = predict.data.cpu().numpy();
Ytest = test.data.cpu().numpy();
sigma_p = (predict).std(axis = 0);
sigma_g = (Ytest).std(axis = 0);
mean_p = predict.mean(axis = 0)
mean_g = Ytest.mean(axis = 0)
index = (sigma_g!=0);
correlation = ((predict - mean_p) * (Ytest - mean_g)).mean(axis = 0)/(sigma_p * sigma_g);
correlation = (correlation[index]).mean();
return rse, rae, correlation, predict
model = Model(n_val, window, 32);
nParams = sum([p.nelement() for p in model.parameters()])
print('* number of parameters: %d' % nParams)
criterion = nn.MSELoss(reduction='sum')
evaluateL2 = nn.MSELoss(reduction='sum')
evaluateL1 = nn.L1Loss(reduction='sum')
criterion = criterion.cuda()
evaluateL1 = evaluateL1.cuda()
evaluateL2 = evaluateL2.cuda()
optimizer = Optim(
model.parameters(), 'adam', lr=0.01, max_grad_norm=10, start_decay_at = 10, lr_decay = 0.9
)
batch_size=128
epochs =10
best_val = 10000000
save = 'model.pt'
print('begin training')
import time
for epoch in range(1, epochs):
epoch_start_time = time.time()
train_loss = train(data, data.train[0], data.train[1], model, criterion, optimizer, batch_size)
val_loss, val_rae, val_corr, _ = evaluate(data, data.valid[0], data.valid[1], model, evaluateL2, evaluateL1, batch_size);
print('| end of epoch {:3d} | time: {:5.2f}s | train_loss {:5.4f} | valid rse {:5.4f} | valid rae {:5.4f} | valid corr {:5.4f} | lr {:5.4f}'
.format(epoch, (time.time() - epoch_start_time), train_loss, val_loss, val_rae, val_corr, optimizer.lr))
# Save the model if the validation loss is the best we've seen so far.
if val_loss < best_val:
with open(save, 'wb') as f:
torch.save(model, f)
best_val = val_loss
if epoch % 5 == 0:
test_acc, test_rae, test_corr, _ = evaluate(data, data.test[0], data.test[1], model, evaluateL2, evaluateL1, batch_size);
print ("test rse {:5.4f} | test rae {:5.4f} | test corr {:5.4f}".format(test_acc, test_rae, test_corr))
optimizer.updateLearningRate(val_loss, epoch)
* number of parameters: 3393
begin training
| end of epoch 1 | time: 21.82s | train_loss 0.0036 | valid rse 0.6420 | valid rae 0.7820 | valid corr 0.4746 | lr 0.0100
| end of epoch 2 | time: 22.95s | train_loss 0.0024 | valid rse 0.5568 | valid rae 0.5982 | valid corr 0.5768 | lr 0.0100
| end of epoch 3 | time: 25.06s | train_loss 0.0021 | valid rse 0.5137 | valid rae 0.5141 | valid corr 0.6616 | lr 0.0100
| end of epoch 4 | time: 23.82s | train_loss 0.0020 | valid rse 0.4988 | valid rae 0.4964 | valid corr 0.7043 | lr 0.0100
| end of epoch 5 | time: 23.95s | train_loss 0.0021 | valid rse 0.5104 | valid rae 0.4532 | valid corr 0.6580 | lr 0.0100
test rse 0.7352 | test rae 0.6122 | test corr 0.6882
| end of epoch 6 | time: 23.32s | train_loss 0.0020 | valid rse 0.4880 | valid rae 0.4146 | valid corr 0.7130 | lr 0.0100
| end of epoch 7 | time: 23.69s | train_loss 0.0020 | valid rse 0.4840 | valid rae 0.4461 | valid corr 0.6972 | lr 0.0100
| end of epoch 8 | time: 24.21s | train_loss 0.0019 | valid rse 0.4765 | valid rae 0.4374 | valid corr 0.7112 | lr 0.0100
| end of epoch 9 | time: 23.89s | train_loss 0.0019 | valid rse 0.4779 | valid rae 0.4434 | valid corr 0.7292 | lr 0.0100
test_acc, test_rae, test_corr, pred = evaluate(data, data.test[0], data.test[1], model, evaluateL2, evaluateL1, batch_size);
print ("test rse {:5.4f} | test rae {:5.4f} | test corr {:5.4f}".format(test_acc, test_rae, test_corr))
test rse 0.6917 | test rae 0.5760 | test corr 0.7227
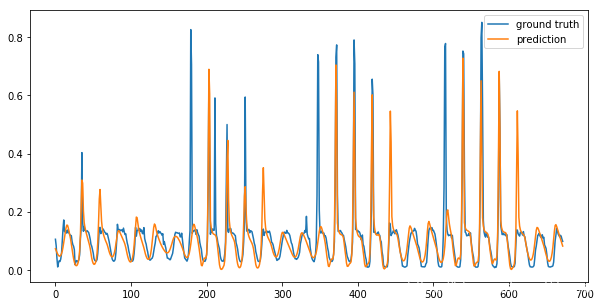
truth = data.test[1].numpy()
for i in range(truth.shape[1]):
plt.figure(figsize=(10,5))
plt.plot(truth[:24*7*4,i], label='ground truth')
plt.plot(pred[:24*7*4,i], label='prediction')
plt.legend()
plt.show()



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











