







在上一篇《ES简介》已经对Elasticsearch有了一个基本的了解,接下来将深入简出的了解ES的内部构造。之前讲过elasticsearch采用gateway的概念,使得完备份更加简单,gateway是个什么东西?ElasticSearch是文档型数据库,它与传统的关系型数据库有什么区别呢?
目录
1. ES的架构
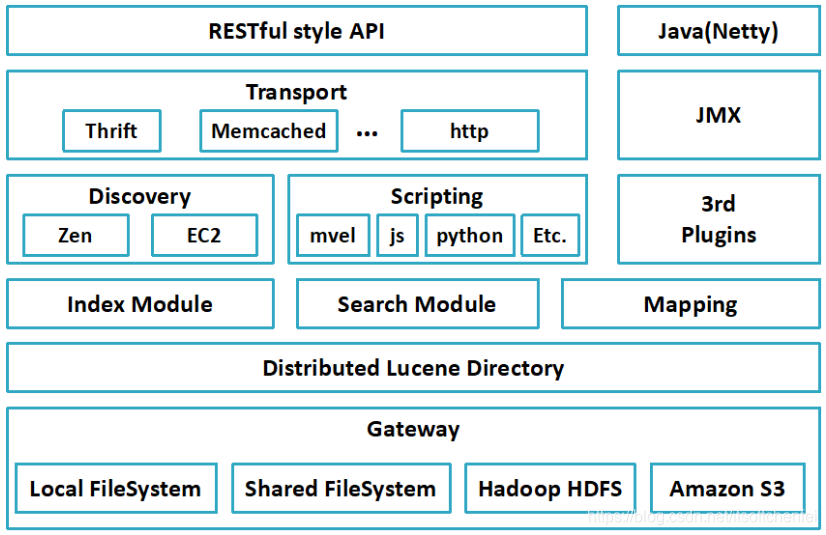
| Gateway | 它是ES用来存储索引的文件系统,支持多种类型,更多 |
| Distributed Lucene Directory | 它是一个分布式的lucene框架,位于Gateway的上层,内部包含Lucene-core |
| Index Module | 索引模块控制与所有索引全局管理的与索引相关的设置,而不是在每个索引级别上可配置,可用的设置包括: Circuit breaker 断路器对内存使用设置限制,以避免内存溢出异常 Fielddata cache 设置内存中fielddata缓存使用的堆数量的限制 Node query cache 配置用于缓存查询结果的堆数量 Indexing buffer 控制分配给索引进程的缓冲区的大小 Shard request cache 控制shard-level请求缓存的行为 Recovery 控制shard恢复过程中的资源限制 |
| Search Module | 后续专门讲 |
| Mapping | 后续专门讲 |
| Discovery | 它是ES的节点发现模块,不同机器上的ES节点要组成集群需要进行消息通信,集群内部需要选举master节点,这些工作都是由Discovery模块完成。支持多种发现机制,如 Zen 、EC2、gce、Azure |
| Scripting | Scripting用来支持在查询语句中插入javascript、python等脚本语言,scripting模块负责解析这些脚本,使用脚本语句性能稍低 |
| 3rd Plugins | ES也支持多种第三方插件 |
| Transport | 它是ES的传输模块,支持多种传输协议,如 Thrift、memecached、http,默认使用http |
| JMX | JMX是java的管理框架,用来管理ES应用。 |
| RESTful style API | 客户端可以通过RESTful接口和ES集群进行交互 |
| Java(Netty) | 略 |
基本的结构ES各个版本没有什么变化。
2. 核心概念
1. Near Realtime(NRT)
近实时。数据提交索引后,立马就可以搜索到。
2. Cluster
集群,一个集群由一个唯一的名字标识,默认为“elasticsearch”。集群名称非常重要,具有相同集群名的节点才会组成一个集群。集群名称可以在配置文件中指定。
3. Node
节点,存储集群的数据,参与集群的索引和搜索功能。像集群有名字,节点也有自己的名称,默认在启动时会以一个随机的UUID的前七个字符作为节点的名字,你可以为其指定任意的名字。通过集群名在网络中发现同伴组成集群。一个节点也可是集群。
4. Index
索引,一个索引是一个文档的集合(等同于solr中的集合)。每个索引有唯一的名字,通过这个名字来操作它。一个集群中可以有任意多个索引。
5. Type
类型,指在一个索引中,可以索引不同类型的文档,如用户数据、博客数据。从6.0.0 版本起已废弃,一个索引中只存放一个type。
6. Document
文档,被索引的一条数据,索引的基本信息单元,以JSON格式来表示。
7. Shard
分片,在创建一个索引时可以指定分成多少个分片来存储。每个分片本身也是一个功能完善且独立的“索引”,可以被放置在集群的任意节点上。分片的好处:
- 允许我们水平切分/扩展容量
- 可在多个分片上进行分布式的、并行的操作,提高系统的性能和吞吐量。
注意:分片数创建索引时指定,创建后不可改了。备份数可以随时改。
8. Replication
备份,一个分片可以有多个备份(副本)。备份的好处:
- 高可用,一个主分片挂了,副本分片就顶上去
- 扩展搜索的并发能力、吞吐量。搜索可以在所有的副本上并行运行
9. Segment
段,索引是由段(Segment)组成的,段存储在硬盘(Disk)文件中,段不是实时更新的,这意味着,段在写入磁盘后,就不再被更新。ElasticSearch引擎把被删除的文档的信息存储在一个单独的文件中,在搜索数据时,ElasticSearch引擎首先从段中查询,再从查询结果中过滤被删除的文档,这意味着,段中存储着“被删除”的文档,这使得段中含有”正常文档“的密度降低。多个段可以通过段合并(Segment Merge)操作把“已删除”的文档将从段中物理删除,把未删除的文档合并到一个新段中,新段中没有”已删除文档“,因此,段合并操作能够提高索引的查找速度,但段合并是IO密集型的操作,需要消耗大量的硬盘IO。
10. 和关系型数据库的对比
| RDBMS | ES |
| 数据库(database) | 索引(index) |
| 表(table) | 类型(type) |
| 行(row) | 文档(document) |
| 列(column) | 字段(field) |
| 表结构(schema) | 映射(mapping) |
| 词(Term) | 表示文本中的一个单词 |
| 标记(Token) | 表示在字段中出现的词,由该词的文本、偏移量(开始和结束)以及类型组成 |
| 索引 | 反向索引 |
| SQL | 查询DSL |
| SELECT * FROM ... | GET http://... |
| INSERT INTO | PUT http://... |
| UPDATE SET ... | POST http://... |
| DELETE ... | DELETE http://... |
11. 倒排索引
倒排索引原理之前在lucene系列中已经讲过,这里不再做赘述
12. 文档打分机制
在lucene系列中讲过相关性排名,es中通过_score显示得分,它主要是通过相似度算法实现
总结,数据结构后续分专题去讲,这边不做展开,下一章讲分享开发关注的ES交互客户端。















 557
557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









