






Nat. Mach. Intell. | 面向AI驱动的生物医学研究的大规模综合知识图谱
为应对生物医学研究中科学文献与数据的快速增长,知识图谱(KG)成为整合异构大数据、实现高效信息检索与自动知识发现的关键工具。然而,从非结构化文献构建KG仍具挑战,现有方法难以达到专家级准确性。本研究使用曾获2022年LitCoin自然语言处理挑战赛第一名的信息抽取流程,基于全部PubMed摘要构建了大规模KG——iKraph,其信息准确度可媲美人工注释,内容远超现有公共数据库。为提升图谱完整性,研究人员整合了40个公共数据库及高通量组学推理数据。该KG支持以往难以实现的自动知识发现评估。研究人员设计了可解释的概率推理方法,应用于2020年3月至2023年5月的新冠药物再定位,在前4个月识别约1200个候选药物,前三分之一在2个月内即被临床试验或文献支持。该成果难以通过其他方法达成。研究团队还开发了开放云平台(https://biokde.insilicom.com)供学术用户使用。

每日产生的大量自然语言科学文献,使得即便在较小的研究领域中,人工阅读全部资料也变得不切实际。同时,高通量技术的发展也带来了海量研究数据,但其中很大一部分尚未被有效利用。这一信息爆炸严重制约了研究人员基于已有数据提出创新见解的能力。自动知识发现(AKD)有望通过自动化分析、识别模式和生成新假设来缓解这一问题。
近年来,知识图谱(KG)被广泛应用于整合异构数据,成为支持AKD的重要工具。KG以实体为节点、关系为边,能结构化表达人类知识,提升信息检索效率。图算法还可基于KG推理出潜在关系,生成合理假设。
从文本构建KG主要包括两个步骤:命名实体识别(NER)和关系抽取。早期方法包括基于规则和基于机器学习的策略。随着深度学习的发展,模型能更有效地利用语义和语法信息,大幅提升抽取效果。近期,大规模语言模型(LLM)如GPT-4的兴起,进一步推动了信息抽取的精度接近甚至超越人工水平。
研究人员也尝试将LLM与KG结合,用于实体识别、关系抽取和事件检测,虽然LLM在泛化和处理大规模数据方面表现出色,但在应对特定领域挑战时仍存在不足,如处理长尾实体和语义一致性问题。目前,一些微调的小模型在KG相关任务中仍优于通用LLM,但LLM在数据稀缺场景下具有重要补充价值。
为促进KG构建方法的发展,美国NIH组织了LitCoin NLP挑战赛。数据集中注释了常见的六类生物实体和八类关系,涵盖了转化研究和药物发现中的核心信息。研究人员团队JZhangLab@FSU在比赛中获得第一名。
本研究基于该团队在挑战赛中开发的信息抽取流程,构建了iKraph知识图谱,覆盖截至2023年5月的全部PubMed摘要。人工验证表明抽取结果达到专家级准确性。研究人员进一步为关系添加方向信息,训练模型预测因果方向,构建了可进行间接因果推理的图谱,并整合了40个公共数据库及高通量组学数据,极大提升了KG的覆盖度和质量。
为识别图中未直接连接实体间的因果关系,研究人员设计了基于概率的语义推理方法(PSR),通过直接关系进行可解释推理。
当前药物开发复杂且成本高昂,传统靶点多已被研究殆尽,迫切需要新策略。KG在靶点发现和药物再利用中展现出重要潜力。然而,以往相关方法难以进行系统评估。例如,药物再定位时,若无法系统查全某疾病或药物的已知关联,就难以评估方法性能。研究人员基于PubMed摘要提取了全部治疗关联,实现了准确的回顾性评估指标计算。
最后,研究人员将方法应用于多个真实案例,包括COVID-19、囊性纤维化、10种缺乏有效治疗的疾病和10种常用药物的再定位研究。系统识别了大量具有文献支持的候选药物,为后续研究提供了明确方向。
结果
构建大规模生物医学知识图谱
为推动KG构建方法的发展与评估,美国NIH于2021年11月至2022年2月组织了LitCoin自然语言处理挑战赛。研究人员团队JZhangLab@FSU在比赛中获得第一名。此外,团队还参与了2023年BioCreative VIII的BioRED赛道,在端到端KG构建任务中再次取得最高分。LitCoin数据集包含500篇PubMed摘要,标注了6类实体和8类关系。研究人员以此为基础,处理了截至2023年5月的全部PubMed摘要,构建了大规模知识图谱iKraph。
iKraph共处理超过3400万篇文献,最终包含10,686,927个独立实体和30,758,640条独立关系。相较于初版流程,研究人员还引入了实体标准化模块,以增强统一性。
为评估抽取质量,研究人员随机选取了50篇摘要(含1,583个实体对)进行人工比对,结果显示抽取准确率可与专家注释媲美。
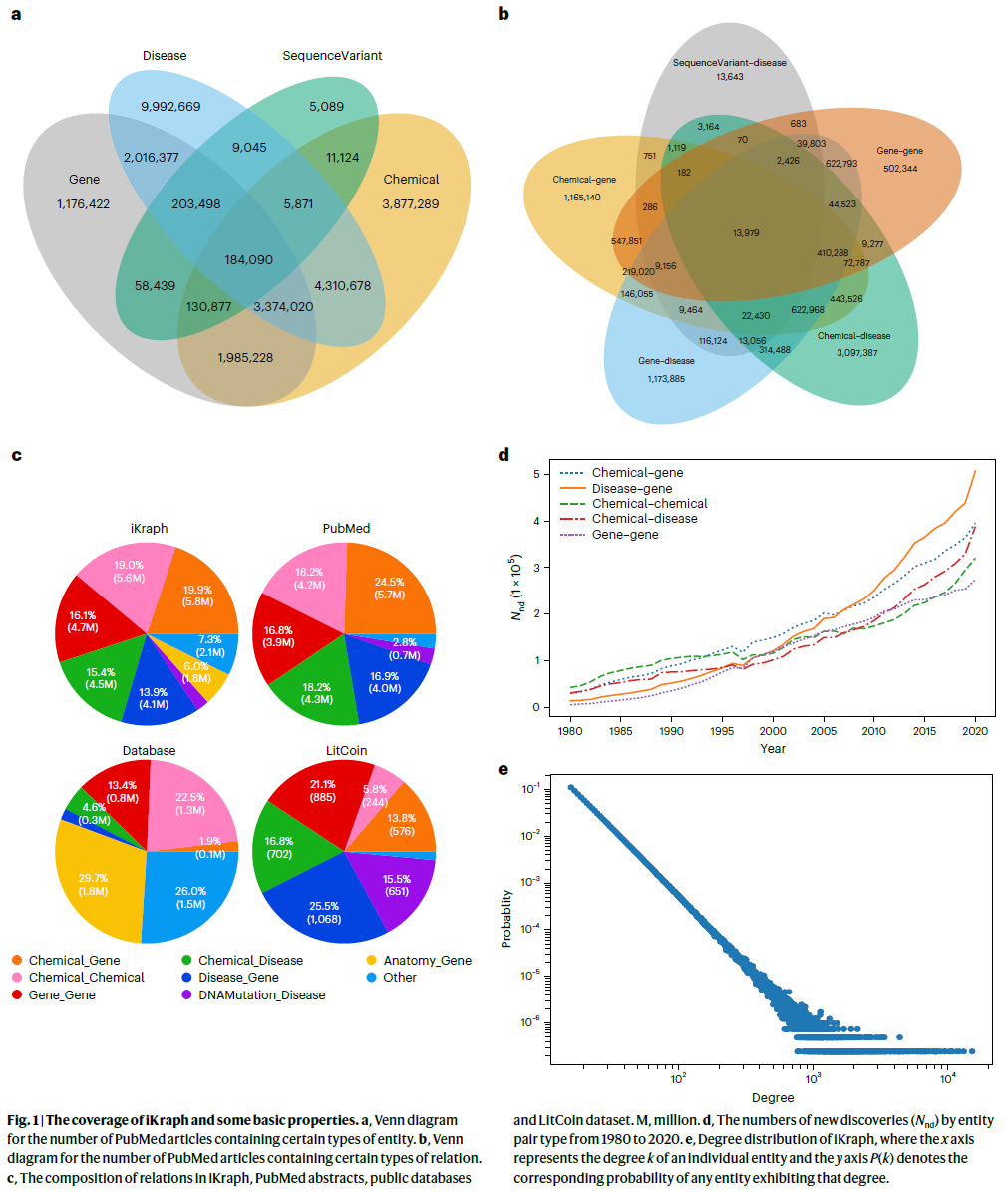
图1a展示了包含四类主要实体(疾病、基因、化学物、序列变异)的摘要数量,其中疾病实体最为常见,超过2000万篇文献涉及至少一个疾病实体,且近半仅关注疾病。图1b则呈现了包含五类主要关系的文献分布,反映生物医学研究的主题趋势。
图1c比较了从PubMed、公共数据库和LitCoin数据集中抽取的关系数量。LitCoin数据集中每篇文献的关系更多,尤其是包含变异实体的部分,解释了模型在该数据集上的高性能。PubMed与数据库中的关系信息在内容上也互为补充。
图1d呈现了不同实体对关系的年度增长趋势。自2005年以来,疾病–基因关系显著上升,反映了联邦推动的转化研究成效,也表明人类对疾病机制的分子层理解日益加深。化学–疾病关系在2020年前后快速增长,预示未来该领域仍将持续扩展。
图1e绘制了实体连接度分布P(k),发现iKraph具备无标度网络特征,幂律参数约为3.0。
补充表4对比了iKraph整合的数据库、PubMed抽取结果与简单共现法所得的五类实体对关系数。结果显示,iKraph中的关系数量远超各数据库,而共现法虽然关系数量更多,但包含大量噪声,说明精确关系抽取能显著提升知识质量。
构建因果知识图谱
研究人员在LitCoin数据集上开发了一个模型,用于预测相关关系的方向,即判断关系中实体的源与目标。这种方向性信息将原本的相关关系转化为潜在的因果关系,从而构建出可用于知识发现的有向KG。
基于PSR的间接关系推理
借助方向信息,研究人员可通过逻辑推理推断出图谱中间接连接实体之间的关系。为此,研究人员设计了高效且可解释的PSR算法。PSR支持所有药物与疾病之间的全对全再定位任务,且计算资源需求极低,可实现每天更新、快速生成新假设,便于跟进最新PubMed文献。相比之下,传统机器学习方法难以在效率与可解释性方面同时达标。
利用iKraph进行COVID-19药物再定位
研究人员基于PSR算法,对2020年3月至2023年5月期间的COVID-19进行回顾性、实时药物再定位研究(图2)。在此期间,基于COVID-19相关靶点持续识别候选药物。候选药物需通过一个或多个中间基因与COVID-19形成有向路径。研究人员每月评估这些候选药物是否被临床试验或PubMed文献验证,包括在ClinicalTrials.gov登记的试验或COVID-19患者疗效报道。虽然部分药物并未最终成为有效治疗手段,但它们作为科学假设具备研究价值,符合再定位的核心目标。
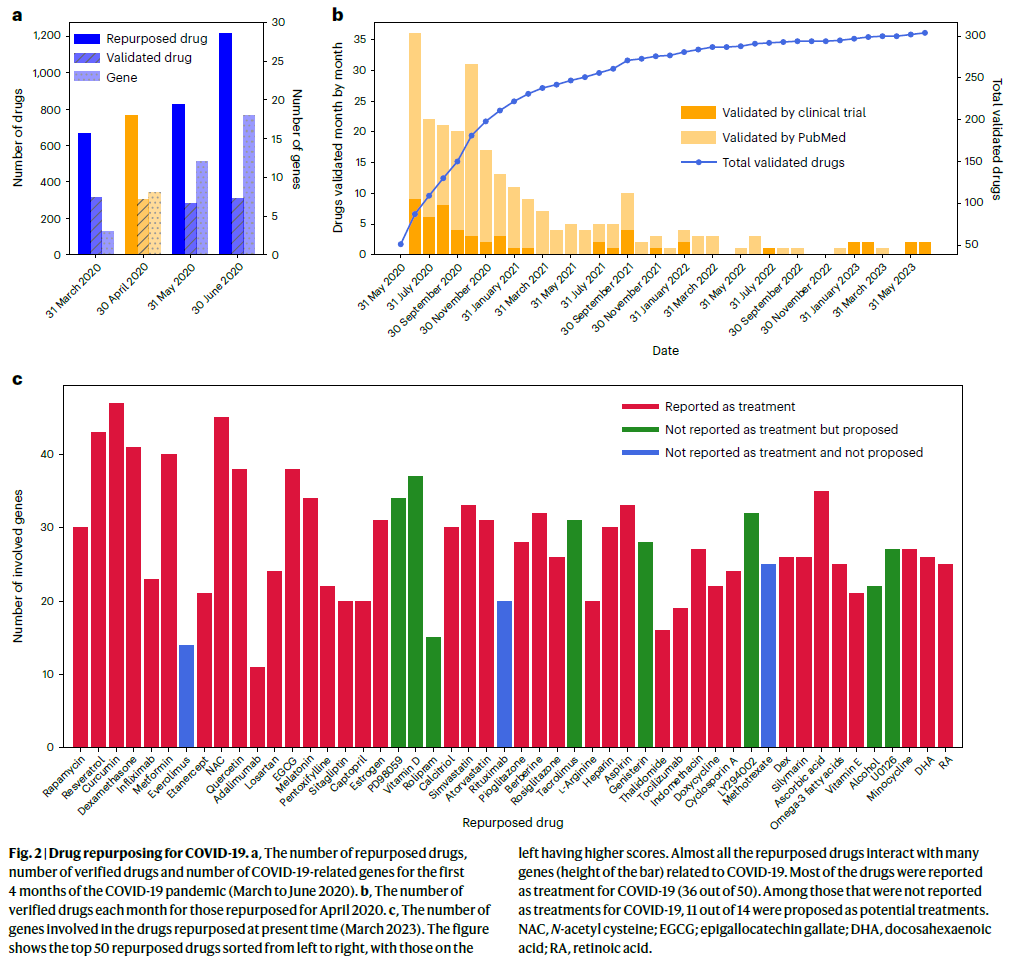
如图2a所示,PSR共识别出约600至1200个候选药物,初始两个月中识别出的药物中约三分之一随后获得临床或文献支持。即便未被验证的药物,在现有疗法效果不佳的情况下,仍值得进一步探索。
图2b展示了药物验证的时间轴。首年验证数量激增,随后逐月下降,表明许多再定位药物与临床实践的初期判断相符;部分药物在第2或第3年才获得验证,说明其价值最初不易被察觉。文献与临床试验对药物的验证数量大致相当。虽然已有许多关于COVID-19药物再定位的研究,但据研究人员所知,尚无其他研究对如此大规模的候选药物进行过系统验证,这体现了iKraph在实时识别潜在治疗药物方面的独特优势。
随后,研究人员在当前时间点进行COVID-19药物再定位分析(图2c)。本轮分析未排除已知COVID-19治疗药物,目的是检验再定位结果是否与现有治疗实践一致。图2c展示了前50个候选药物,其中36个已有文献报道其潜在或实际治疗效果,其余14个中有11个也被提出作为潜在治疗方案(补充表3中提供引文)。每种药物与COVID-19之间均通过多个中介基因建立联系,并有相应文献支持。迄今尚无其他基于文献的COVID-19再定位研究能达到如此全面的程度。
基于 iKraph 的囊性纤维化药物再定位
研究人员应用 PSR 算法,挖掘1985年至2022年间药物与囊性纤维化之间的间接关系(图3)。自1990年代初起,每年至少识别出50个潜在再定位药物。若某药物后来被报道对囊性纤维化具有直接治疗作用,则视为验证成功。以往受限于人工检索,相关指标难以系统评估。研究人员计算了召回率(成功再定位的已知关系占比)与观察阳性率(OPR,已再定位药物中有文献支持的比例)。与精确率不同,OPR 可纳入尚未被验证的潜在候选药物。
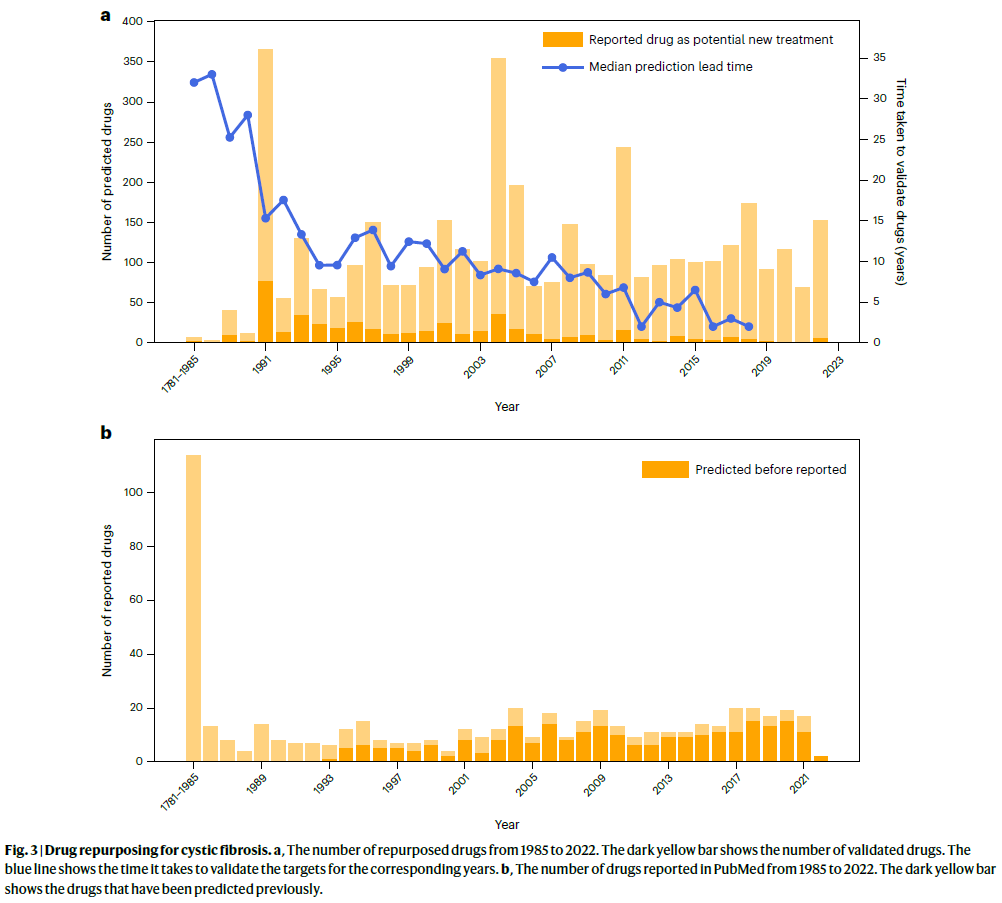
从1990至2022年,平均召回率达 0.635(图3b),而1985至2011年间的平均 OPR 为 0.159。两者使用不同时间段,是因为 OPR 依赖较早的预测结果,而新预测需时间验证。
研究人员进一步估算了药物从预测到验证的典型时间,结果显示中位验证时长为 9.4年,最长可达33年(图3a)。假设实验验证平均需2年,若预测能被即时采用,iKraph 理论上可将验证周期从9年缩短至2年。结合63%以上的召回率,这一结果表明 iKraph 有望加速囊性纤维化药物的再定位与验证过程。
面向十种疾病与十种常用药物的再定位分析
为评估方法通用性,研究人员将PSR算法应用于 10种缺乏有效治疗的疾病 以及 10种常用药物 的再定位分析(补充图3)。针对每种药物或疾病,研究人员分别计算召回率与OPR。结果显示:
- 疾病再定位的平均召回率为 0.76;
- 药物再定位的平均召回率为 0.86;
- OPR 分别为 0.197(疾病) 和 0.07147(药物)。
这些结果表明,PSR算法在保持预测数量适中的同时,仍能实现极高的有效回溯,体现出其强大再定位能力。值得注意的是,许多药物再定位出的适应症在PubMed摘要中尚无任何治疗方案记录,提示这些常用药物可能填补部分疾病的治疗空白。
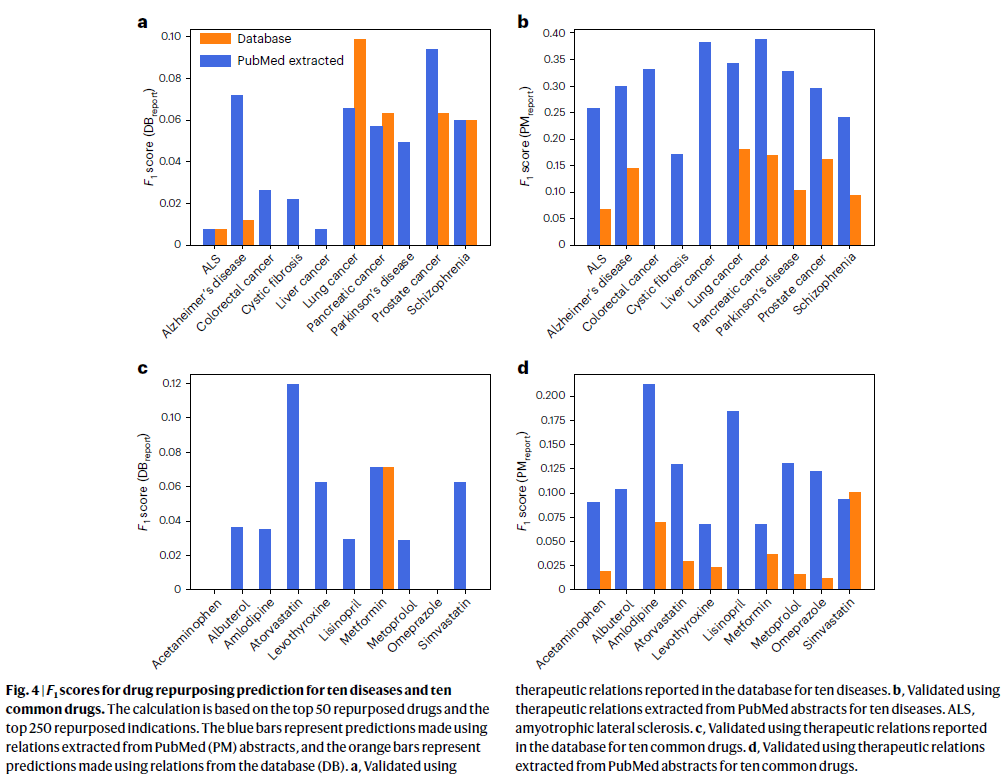
数据库 vs 文献抽取:再定位表现对比
研究人员进一步比较了基于数据库与PubMed文献抽取的再定位效果(图4)。图中蓝色柱为基于PubMed的预测结果,橙色柱为基于数据库的预测。对前50个候选药物与前250个适应症进行评估,发现大多数情况下,PubMed抽取的结果具有更高的F1分数,显示文献中的信息密度与质量远超公共数据库,为药物再定位提供更强支撑。
讨论
将非结构化科学文献转化为结构化数据,一直是自然语言处理领域的核心难题。若能成功解决这一问题,将有望极大加速科学发现的进程。尽管已有众多研究探索信息抽取方法,但在关系识别的精度上仍难以媲美人工注释,这也成为知识图谱构建的主要瓶颈。近年来,大语言模型(LLMs)的出现推动了信息抽取能力的跃升。本文中,研究人员基于一个具有人类专家水平的信息抽取流程,处理了全部PubMed摘要,构建出大规模生物医学知识图谱 iKraph。进一步整合40个公共数据库和公开组学数据后,iKraph 成为目前覆盖最全面的生物医学KG之一,其关系信息远超现有数据库。
通过构建因果型KG并设计可解释的PSR算法,研究人员能够高效开展自动知识发现(AKD)任务。iKraph 的全面性,使得以往难以实现的系统性研究变为可能。研究人员首次系统评估了AKD性能,并精确计算了召回率与观察阳性率(OPR),这在传统研究中往往因缺乏结构化全量数据而难以实现。
传统生物医学研究依赖大量人工注释进行知识整理,成本高、效率低。研究结果表明,通过少量高质量标注数据训练模型,即可在大规模文本上实现接近人工水平的信息抽取,为拓展数据库内容提供了新路径,不牺牲数据质量。
借助 iKraph 进行药物再定位等知识发现任务,研究人员识别出大量具文献支持的候选药物,显示出结构化知识在推动科学突破方面的巨大潜力。尤其在 COVID-19 的再定位研究中,iKraph 展现出快速识别应急治疗手段的能力,为未来突发公共卫生事件提供了重要技术储备。
针对“低质量文献是否引入噪声”的问题,研究人员提出了基于文献数量进行关系概率整合的策略(图5)。每篇文献赋予某一关系一个概率,最终通过加权聚合形成综合评分。出现频率高的关系得分更高,置信度也更强,而基于少数低质量文献的关系则因得分较低而被弱化。未来可进一步考虑引入期刊影响因子、引用量、发表时间等质量指标,赋予高质量来源更大权重。这种加权策略已被证实可有效评估科学主张的可信度,例如通过作者多样性、机构独立性、发表密度等特征提高结果可重复性。结合这些因素将有助于 iKraph 在提升预测准确性的同时,保持对错误信息的鲁棒性。
最后,研究人员将本工作置于当前NLP热门方向——大语言模型的背景下进行对比。尽管LLMs展现出强大的语言理解与生成能力,但其知识更新滞后、事实准确性不足、容易产生虚构内容等问题在生物医学领域尤其突出。因此,单独依赖LLMs难以满足高精度科学问答需求。研究人员认为,将结构化知识图谱如iKraph与LLMs结合,可有效弥补各自短板。目前,团队正基于此构建融合KG与开源LLM的智能问答系统,以实现更精准、可验证的知识获取。
更多未来研究方向与挑战详见补充材料第6节。总体而言,iKraph 为信息检索与自动知识发现提供了强有力的基础设施,有望在未来生命科学研究中发挥关键作用。
参考资料
Zhang, Y., Sui, X., Pan, F. et al. A comprehensive large-scale biomedical knowledge graph for AI-powered data-driven biomedical research. Nat Mach Intell (2025).
https://doi.org/10.1038/s42256-025-01014-w



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









