






0 项目说明
基于半监督学习和集成学习的情感分析研究
提示:适合用于课程设计或毕业设计,工作量达标,源码开放
1 数据
text/JDMilk.arff[tf-idf]
- 对于baseline 7%作为训练集 30%作为测试集
- 对于SSL alg 7%作为训练集 63%无标注数据集 30%作为测试集
切分训集和测试集 四折交叉验证
具体做法是:将数据集分成四份,轮流将其中3份作为训练数据,1份作为测试数据,进行试验,最终采用10次结果的正确率的平均值作为对算法精度的估计 显然,这种估计精度的做法具有高时间复杂度
2 测试标准
准确率(Accuracy)
3 环境配置
python2.7
scikit,numpy,scipy
docker
4 算法
4.1 监督学习(SL)的分类器选择
选择标准:能够输出后验概率的
1.支持向量机(SVC)
2.朴素贝叶斯-多项式分布假设(MultinomialNB)
4.2 半监督学习(SSL)
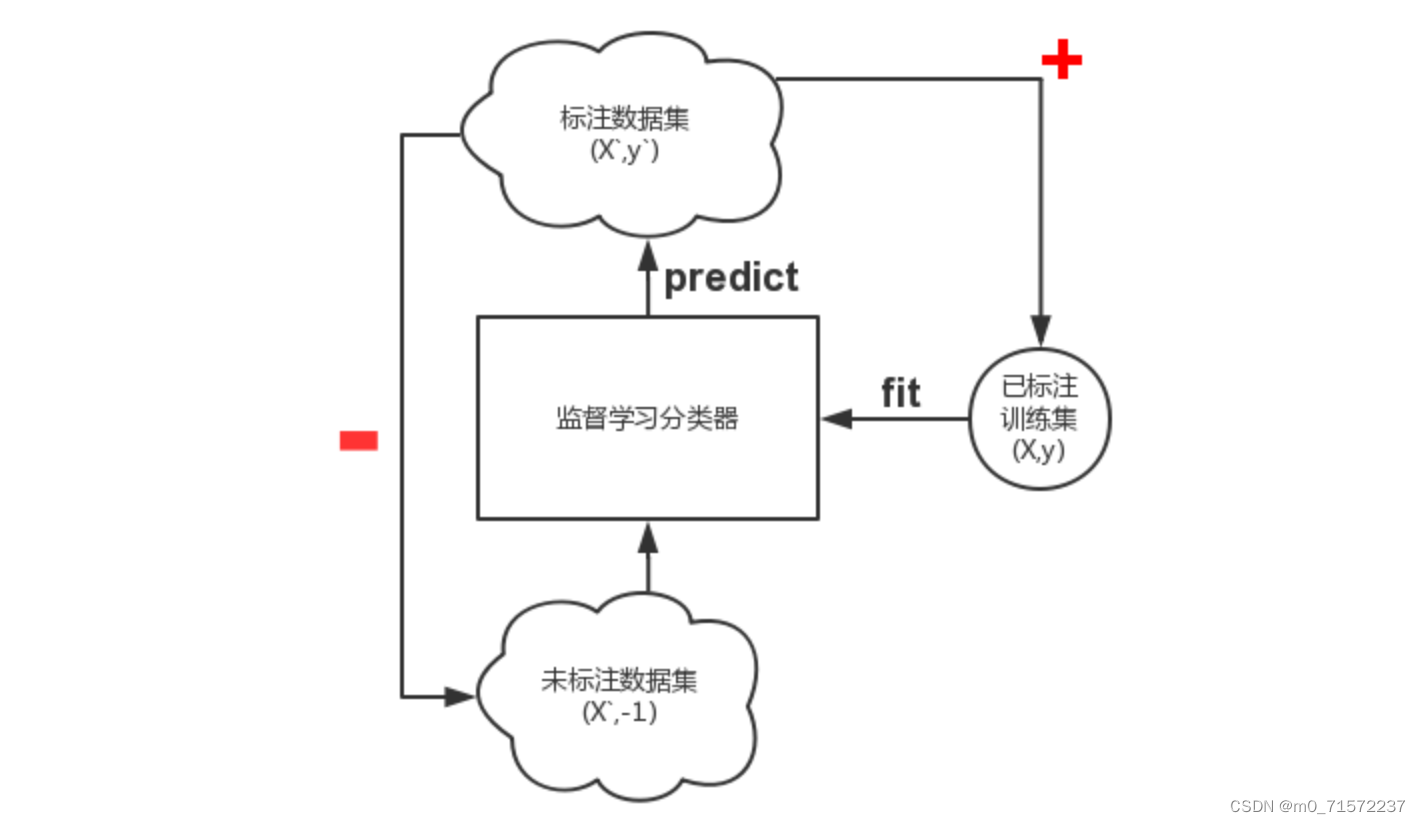
1.Self-Training
最原始的半监督学习算法,但是容易学坏,压根没有改善,甚至更差
Assumption:One’s own high confidence predictions are correct.
其主要思路是首先利用小规模的标注样本训练出一个分类器,然后对未标注样本进行分类,挑选置信度(后验概率)最高的样本进行自动标注并且更新标注集,迭代式地反复训练分类器
2.Co-Training
特点:Original(Blum & Mitshell)是针对多视图数据(网页文本和超链接),从不同视图(角度)思考问题,基于分歧
Original视图为2,分别是网站文本和超链接
p=1,n=3,k=30,u=75
Rule#1:样本可以由两个或多个冗余的条件独立视图表示
Rule#2:每个视图都能从训练样本中得到一个强分类器
视图数量4比较好,每个视图内包含的特征数量m为:总特征数量n/2[来自王娇文献]。但是,普通情感评论文本(nlp)并没有天然存在的多个视图,考虑到情感文本中特征数量非常庞大,利用随机特征子空间生成的方式
[RandomSubspaceMethod,RSM]将文本特征空间分为多个部分作为多个视图
但是视图之间至少得满足’redundant but notcompletely correlated’的条件
因为多个视图之间应该相互独立的,如果都是全相关,那么基于多视图训练出来的分类器对相同待标记示例的标记是完全一样的,这样一来Co-Training 算法就退化成了 self-training 算法
5 项目工程
**项目分享: ** https://gitee.com/asoonis/htw















 270
270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









