






文章目录
0 简介
今天学长向大家介绍一个机器视觉的毕设项目,基于深度学习的人脸识别系统
项目运行效果:
毕业设计 opencv人脸识别系统
🧿 项目分享:见文末!
1 人脸识别 - 常用实现技术
人脸识别主要研究的是如何获得高效的特征, 并利进行人脸匹配的计算。 至今为止人脸识别的算法已经很多。
1.1 基于几何特征的人脸识别方法
该方法所考虑的特征相对朴。 所谓的几何特征是指人脸图像上各器官等的相对位置或相对距离所组成的矢量, 具体指利用人工方式标出人脸图像特征点位置, 对标定好的特征点计算相对距离; 将所得的多个距离按照预定顺序组成一个矢量, 该矢量即为几何特征。 Nicholas Roeder 和 Xiaobo Li 对几何特征的提取进行了详细研究, 由于几何特征只是粗略的描述的人脸图像, 因此效果并不如人意。
1.2 初级神经网络方法。
Intrato将无监督/监督混合神经网络应用到人脸识别问题上,该方法比传统的 BP 神经网络提取的特征更有效。 Cottrell 应用级联 BP 神经网络较好的解决了人脸遮挡和光照变化的问题。 W.Shiqian Wu 将 RBF 和 DCT 神经网络应用到人脸识别问题上。 E.Osuna 将支持向量机(SVM)应用到人脸识别问题。 Kung 和Lin 结合神经网络和统计学方法, 提出了基于概率决策的神经网络(PDBNN),此方法也获得了很好的结果, 这些方法都取得了较好的效果。 神经网络方法虽然简化了特征提取的工作, 学习到更加有效的特征, 但是神经网络往往有数目众多的神经元组成,因此训练耗时且难于收敛。
1.3 深度学习方法。
其实深度学习早在 20 世纪 90 年代就已经提出, 但是由于当时计算机技术的限制, 深度学习 并没得到很大的重视和发展。 直到 2012 年由 AlexKrizhevsky 提出的 AlexNet 卷积神经网络在 ILSVRC 图像分类竞赛中表示异常突出,从此深度学习尤其是其中的卷积神经网络得到了人们的广泛关注和深入的研究。 除了在香港中文大学的 DeepID 系列, 还有 Google 提出 FaceNet 网络 [25] , 牛津大学提出的VGG 网络等许多不同的网络, 这些网络都取得了很好的效果。深度学习具有特征自动学习, 泛化能力强和所学特征表现里强等优点, 因此深度学习在人脸识别问题上的应用极大的推动的人脸识别的发展。 但是深度学习也具有所需训练数据巨大、 训练耗时长和难于收敛等缺点。
2 人脸识别算法缺陷
(学长在这里推荐大家可以优化这些点,然后作为课题的创新点)
光照是影响人脸识别的重要原因。 现有的数字图像处理技术都是基于图像的像素值进行计算的, 因此即使是同一个人但由于光照变化引起的像素值的差异使的最终计算结果差异很大, 这极大的影响了人脸识别的性能。姿态是左右人脸识别另一个关键点。 在实际问题中人脸数据的采集往往是一种随意行为, 不能保证每次采集到是正脸。 上一节提到的各种方法往往只能适应一种姿态,对于姿态不同的图像识别问题经常是力不从心。 因此找到一种对姿态变化具有很强的鲁棒性的方法也是非常重要的。
数据规模庞大也影响人脸识别性能。 在深度学习应用到人脸识别问题之前, 所提出的方法由于受到计算复杂度限制, 往往在小数据集(包含几十人或几百人)性能良好,但是在大规模数据上性能很差。 深度学习由于其具有较强的泛化能力, 因此在较大规模的数据集上表现比传统方法改善了许多。 但是深度学习的泛化能力也是相对而言较强, 其受训练集的影响很大。 目前世界上有超过 60 亿人, 而且每个地区的人面部差异较大, 在获取训练数据集时无法包含所有人, 这会对最终的泛化能力有很大影响,比如训练数据集中包括的全部是西方人(大部分是这种情况), 训练得到的网络对于东方人的泛化能力就较低, 因此即使利用深度学习也无法区分世界上所有人。
计算复杂度高对人脸识别也有影响。 计算复杂度往往随着人脸识别任务复杂度的提高和训练数据的增加而急速增加。 利用深度学习进行人脸识别, 随着神经网络规模加深, 参数量也逐渐增大, 也增加计算复杂度。 计算复杂度的增加不仅使训练时间增加, 算法难以收敛, 容易出现过拟合问题, 而且也增加了测试阶段所耗时间, 这不利用算法的实际应用。
3 人脸识别流程
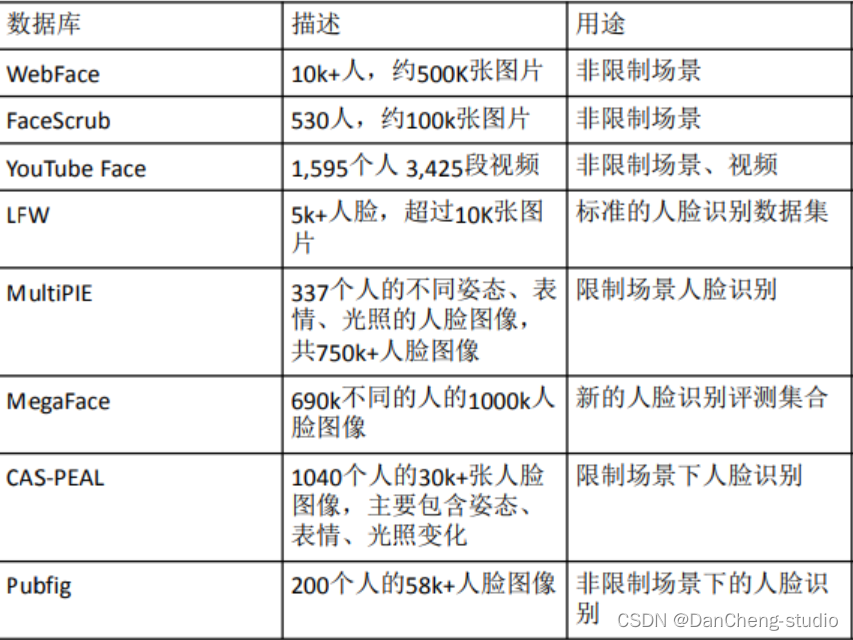
3.1 相关数据集
主要有以下几种数据集,其中仅MultiPIE需要购买,其余的申请即可。
3.2 对齐
通过确定人脸中的标定点(landmark)的位置进行人脸对齐。(找3个点即可,一般找5个点:鼻子、眼睛、嘴角两端)对齐后可以找到一个二维坐标平面,进行下一步仿射变换。

3.3 仿射变换
原理
- 二维坐标到二维坐标之间的线性变换
- 不共线的三对对应点决定了一个唯一的仿射变换

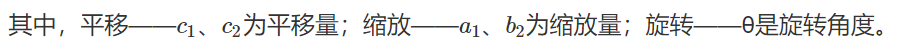
3.4 人脸目标检测
使用神经网络(比如使用的DCNN)进行回归对标定点进行检测。
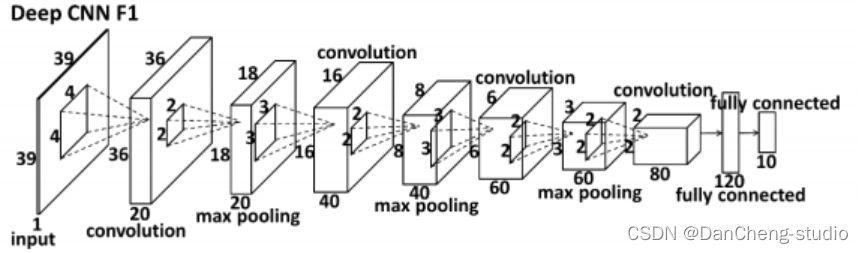
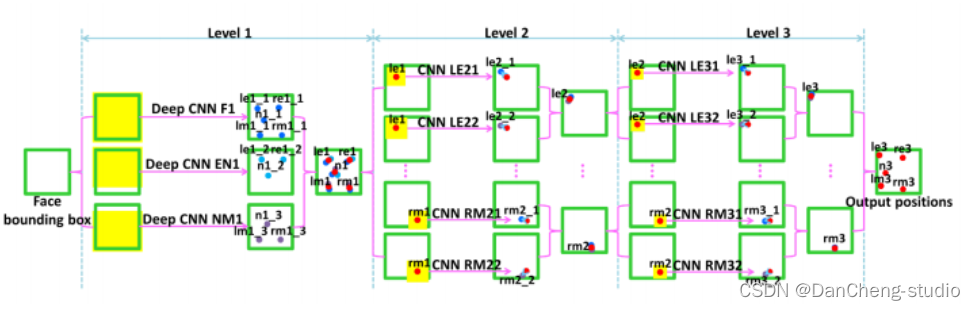
其中,输入原始画像后,进行4*4卷积后,在进行池化,卷积…最后使用两个全连接得到最终结果。这里面采用了一个级联思想实现CNN组合,级联思想实现细节如下图:
3.5 人脸特征提取
3.5.1 分类模型有哪些
- Deepface
- DeepID
- VGG
- ResNet
- FaceNet
3.5.2 度量学习模型——FaceNet为例
学长以常用的FaceNet为例,下图是FaceNet的简略示意图,例如,输入三张图片:Anchor、与Anchor不同类的Negative、与Anchor同类的Positive,通过一系列学习后实现同类相近,异类相远。
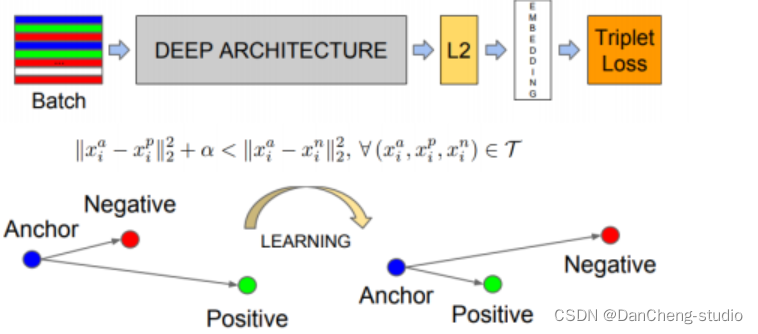 距离计算公式(前半部分为与同类positive之间的距离,后半部分计算与不同类negative的距离。)
距离计算公式(前半部分为与同类positive之间的距离,后半部分计算与不同类negative的距离。)
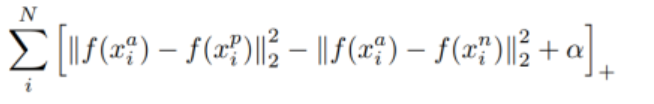
最终实现效果如下图所示,距离>1.1即可认为相互之间为不同人,即使一个人不同角度也可以被识别为同一人。

3.6 人脸识别(特征分类)
人脸识别中的人脸验证问题即是验证两张图片是否来自同一个人。主要有以下三种方法,欧氏距离和余弦距离方法是工业中常用的验证方法,Joint Bayesian方法常用在学术研究中。首先假定两张人脸图片提取的特征向量为量为 xj→ 和 xk→ 。
3.6.1 欧氏距离
距离差越大,相似度越小。
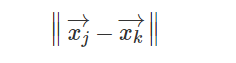
3.6.2 余弦距离
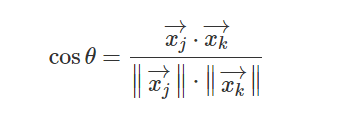
3.6.3 Joint Bayesian 方法

其中,𝑆(∆) 是差异 ∆ 的函数,𝑃(H1)为先验概率,𝑃(Δ|H1) 为似然概率,𝑃($𝐻_1|∆)是后验概率,是人脸相似性的度量。
4 实现过程
数据集来源网络搜索,我选取了几名大家认识的人物,有Biden、chenglong、mayun、Trump、yangmi、zhaoliying等。每个人物放入3-4张图片,如下图:
获得此图像数据集,我们将:
- 为数据集中的每个人脸创建 128 维嵌入
- 使用这些嵌入来识别图像和视频流中人物的面部
4.1 自己构建人脸数据集
或者你有自己的想法,构建一个自己的数据集,可以的话,记得开源给学长(手动狗头)
4.1.1 拍照程序
想要识别自己,单有别人的数据集还是不行的,还需要自己人脸的照片才行。这就需要我们收集自己的照片,然后和上面的那个数据集一起来训练模型。在拿着手机自拍的过程中我想到,问什么不写一个程序用电脑的摄像头自拍呢,随便还能研究下怎么用opencv实现拍照的功能。经过一番实验(其实还是费了好长时间),终于写了一个拍照程序。
程序的功能就是打开电脑摄像头,当P键按下(P是拍照的首字母?还是Photo的首字母?还是Picture的首字母?)的时候,保存当前帧的图像。简单到没朋友(竟然耗费了那么久!)。
while (1)
{
char key = waitKey(100);
cap >> frame;
imshow("frame", frame);
string filename = format("D:\\pic\\pic%d.jpg", i);
switch (key)
{
case'p':
i++;
imwrite(filename, frame);
imshow("photo", frame);
waitKey(500);
destroyWindow("photo");
break;
default:
break;
}
}
然后我们就可以运行程序,不停地按下p键对自己一通狂拍了。
4.2 预处理
在得到自己的人脸照片之后,还需要对这些照片进行一些预处理才能拿去训练模型。所谓预处理,其实就是检测并分割出人脸,并改变人脸的大小与下载的数据集中图片大小一致。
人脸检测在之前的博客中已经做了介绍,这里就不再赘述。详情参考:OpenCV人脸检测(C++/Python)。用ROI分割即可。
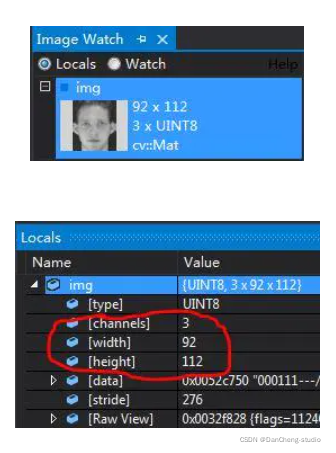
检测出人脸之后改变大小使之与ORL人脸数据库人脸大小一致。通过加断点在Locals里面或者是ImageWatch可以看到ORL人脸数据库人脸的大小是92 x 112。
这里只需要对检测后得到的ROI做一次resize即可。
这两步的代码如下:
std::vector<Rect> faces;
Mat img_gray;
cvtColor(img, img_gray, COLOR_BGR2GRAY);
equalizeHist(img_gray, img_gray);
//-- Detect faces
face_cascade.detectMultiScale(img_gray, faces, 1.1, 3, CV_HAAR_DO_ROUGH_SEARCH, Size(50, 50));
for (size_t j = 0; j < faces.size(); j++)
{
Mat faceROI = img(faces[j]);
Mat MyFace;
if (faceROI.cols > 100)
{
resize(faceROI, MyFace, Size(92, 112));
string str = format("D:\\MyFaces\\MyFcae%d.jpg", i);
imwrite(str, MyFace);
imshow("ii", MyFace);
}
waitKey(10);
}
4.3 人脸特征提取
在识别图像和视频中的人脸之前,我们首先需要量化训练集中的人脸。 请记住,我们实际上并不是在这里训练网络——网络已经被训练为在大约 300 万张图像的数据集上创建 128 维嵌入。
当然可以从头开始训练网络,甚至可以微调现有模型的权重。
但一般情况,使用预训练网络然后使用它为我们数据集中的 29张人脸中的每一张构建 128 维嵌入更容易。
然后,在分类过程中,我们可以使用一个简单的 k-NN 模型 + 投票来进行最终的人脸分类。 其他传统的机器学习模型也可以在这里使用。
新建 encode_faces.py:
# import the necessary packages
from imutils import paths
import face_recognition
import argparse
import pickle
import cv2
import os
dataset_path='dataset'
encodings_path='encodings.pickle'
detection_method='cnn'
# 获取数据集中输入图像的路径
print("[INFO] quantifying faces...")
imagePaths = list(paths.list_images(dataset_path))
# 初始化已知编码和已知名称的列表
knownEncodings = []
knownNames = []
# 遍历图像路径
for (i, imagePath) in enumerate(imagePaths):
# 从图片路径中提取人名
print("[INFO] processing image {}/{}".format(i + 1,
len(imagePaths)))
name = imagePath.split(os.path.sep)[-2]
# 加载输入图像并从 BGR 转换(OpenCV 排序)
# 到 dlib 排序(RGB)
image = cv2.imread(imagePath)
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 检测边界框的 (x, y) 坐标
# 对应输入图像中的每个人脸
boxes = face_recognition.face_locations(rgb, model=detection_method)
# 计算人脸的嵌入
encodings = face_recognition.face_encodings(rgb, boxes)
# 遍历 encodings
for encoding in encodings:
# 将每个编码 + 名称添加到我们的已知名称集中
# 编码
knownEncodings.append(encoding)
knownNames.append(name)
代码关键点解释
- dataset_path:数据集的路径。
- encodings_path :我们的人脸编码被写入这个参数指向的文件路径。
- detection_method :在我们对图像中的人脸进行编码之前,我们首先需要检测它们。 或者两种人脸检测方法包括 hog 或 cnn 。
现在我们已经定义了我们的参数,让我们获取数据集中文件的路径(以及执行两个初始化):
输入数据集目录的路径来构建其中包含的所有图像路径的列表。
在循环之前分别初始化两个列表 knownEncodings 和 knownNames 。 这两个列表将包含数据集中每个人的面部编码和相应的姓名。 这个循环将循环 19次,对应于我们在数据集中的 19张人脸图像。
然后,将面部的边界框转换为 128 个数字的列表。这称为将面部编码为向量,而 face_recognition.face_encodings 方法会处理它。 编码和名称附加到适当的列表(knownEncodings 和 knownNames)。然后,将继续对数据集中的所有 19张图像执行此操作。
# dump the facial encodings + names to disk
print("[INFO] serializing encodings...")
data = {"encodings": knownEncodings, "names": knownNames}
f = open(args["encodings"], "wb")
f.write(pickle.dumps(data))
f.close()
构造了一个带有两个键的字典—— “encodings” 和 “names” 。 将名称和编码转储到磁盘以备将来调用。
[INFO] quantifying faces...
[INFO] processing image 1/19
[INFO] processing image 2/19
[INFO] processing image 3/19
[INFO] processing image 4/19
[INFO] processing image 5/19
[INFO] processing image 6/19
[INFO] processing image 7/19
[INFO] processing image 8/19
[INFO] processing image 9/19
[INFO] processing image 10/19
[INFO] processing image 11/19
[INFO] processing image 12/19
[INFO] processing image 13/19
[INFO] processing image 14/19
[INFO] processing image 15/19
[INFO] processing image 16/19
[INFO] processing image 17/19
[INFO] processing image 18/19
[INFO] processing image 19/19
[INFO] serializing encodings...
Process finished with exit code 0
正如输出中看到的,我们现在有一个名为 encodings.pickle 的文件——该文件包含我们数据集中每个人脸的 128 维人脸嵌入。
5 识别效果
项目运行效果:
毕业设计 opencv人脸识别系统
🧿 项目分享:见文末!

















 3736
3736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









