
数据结构 | 算法
 关注
关注
 分享
分享
文章平均质量分 92
数据结构与算法实战分析
流烟默
这个作者很懒,什么都没留下…
展开
专栏收录文章
- 默认排序
- 最新发布
- 最早发布
- 最多阅读
- 最少阅读
-
【每日一面】关于树
【1】求二叉树的最大深度使用递归,分别求出左子树的深度、右子树的深度,两个深度的较大值+1即可。// 获取最大深度public static int getMaxDepth(TreeNode root) { if (root == null) return 0; else { int left = getMaxDepth(root.le...原创 2019-02-25 18:37:46 · 591 阅读 · 0 评论 -
认真研究ConcurrentHashMap中的元素统计策略
这里我们想研究的是jdk1.8中ConcurrentHashMap的`addCount(long x, int check)`方法。如下所示在put方法的最后会触发`addCount(long x, int check)`方法进行元素个数的统计。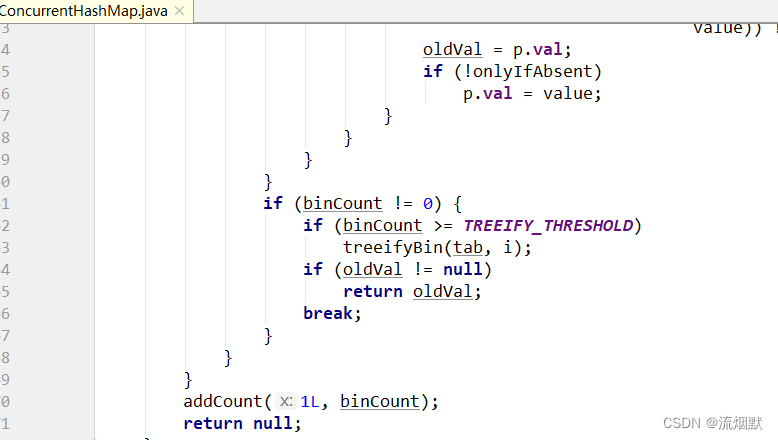我们再回顾一下另一个参数binCount :* 在操作链表的分支if (fh >= 0)中 用于统计原创 2022-08-30 15:16:12 · 1324 阅读 · 0 评论 -
认真学习jdk1.8下ConcurrentHashMap的扩容机制
jdk1.7下的rehash会对某段的某个数组进行二倍扩容,然后把链表拆分放到数组的不同位置。jdk1.8下ConcurrentHashMap的扩容就要麻烦了。首先在链表转化为树的时候,会判断tab.length原创 2017-11-28 17:28:13 · 3891 阅读 · 0 评论 -
认真学习jdk1.8下ConcurrentHashMap的实现原理
1.7 已经解决了并发问题,并且能支持 N 个 Segment 这么多次数的并发,但依然存在 HashMap 在 1.7 版本中的问题---查询、遍历链表效率太低。jdk1.8 做了一些数据结构上的调整,先来看下底层的组成结构(其实和jdk1.8下HashMap的数据结构一致,就是数组+链表+红黑树):.............................................原创 2017-10-20 16:38:06 · 8867 阅读 · 1 评论 -
认真研究HashMap中的平衡删除
**关联博文**[数据结构之Map基础入门与详解](https://janus.blog.csdn.net/article/details/53214105)[认真学习Java集合之HashMap的实现原理](https://janus.blog.csdn.net/article/details/86774652)[认真研究HashMap的读取和存放操作步骤](https://janus.blog.csdn.net/article/details/52787823)[认真研究HashMap的初始化和原创 2017-02-24 11:34:32 · 8936 阅读 · 0 评论 -
认真研究HashMap的结点移除
**关联博文**[数据结构之Map基础入门与详解](https://janus.blog.csdn.net/article/details/53214105)[认真学习Java集合之HashMap的实现原理](https://janus.blog.csdn.net/article/details/86774652)[认真研究HashMap的读取和存放操作步骤](https://janus.blog.csdn.net/article/details/52787823)[认真研究HashMap的初始化和原创 2016-09-21 15:00:13 · 6443 阅读 · 1 评论 -
认真研究HashMap中的平衡插入
本文是基于Jdk1.8,关于平衡插入这一部分涉及的内容比较多,所以从博文[认真学习Java集合之HashMap的实现原理](https://blog.csdn.net/J080624/article/details/86774652)摘取出来单独研究。下面方法参数中的root为当前root结点,x 为新插入的结点 。xpp 为xp的parent,xppl 为xpp的left,xppr 为 xpp的right ,xp是x.parent。这个过程会涉及到红黑树的左旋和右旋。```java// root为原创 2017-06-02 11:56:19 · 1740 阅读 · 0 评论 -
认真学习数据结构之B/B+/B*树
前面我们学习了二叉树、AVL树、23树以及红黑树等。接下来我们研究B树/B+树。# 【1】多路查找树这里我们首先引入多路查找树的概念。多路查找树(MuitlWay Search Tree)是二叉树的演进,也就是允许一个节点存储一个以上的key。比如前面我们学习的23树,其就是一个一棵多路查找树。二叉树中每个结点有一个数据项,最多有两个子节点。如果允许树的每个节点可以有两个以上的子节点,那么这个树就称为n阶的多叉树,或者称为n叉树。**那么为什么演进多路查找树呢?**有没有那么一个场景,原创 2016-09-21 09:39:15 · 1103 阅读 · 0 评论 -
认真学习数据结构之2-3树
在插入和删除结点时,要保证插入结点后不能使叶子结点之间的深度之差大于1,这样就能保证整棵树的深度最小,这就是AVL树解决BST搜索性能降低的策略。但由于每次插入或删除结点后,都可能会破坏AVL的平衡,而要动态保证AVL的平衡需要很多螺旋操作,这些操作会影响整个数据结构的性能,除非是在树的结构变化特别少的情形下,否则AVL树平衡带来的搜索性能提升有可能还不足为了平衡树所带来的性能损耗。那有没有绝对平衡的一种树呢?没有高度差也不会有平衡因子,没有平衡因子就不会调整旋转操作。2-3树正是一种绝对平衡的树,原创 2016-10-25 09:54:10 · 2272 阅读 · 0 评论 -
认真学习数据结构之AVL树
AVL树是最先发明的自平衡二叉查找树。在AVL树中任何节点的两个子树的高度最大差别为1,所以它也被称为高度平衡树。增加和删除可能需要通过一次或多次树旋转来重新平衡这个树。AVL树得名于它的发明者`G. M. Adelson-Velsky和E. M. Landis`,他们在1962年的论文`《An algorithm for the organization of information》`中发表了它。# 【1】概念介绍**二叉查找树只限制了结点值大小:*** 若它的左子树不空,则左子树上所有结点的值原创 2016-12-27 16:41:35 · 2598 阅读 · 0 评论 -
认真学习数据结构之树
树形结构是一种层级式的数据结构,由顶点(节点)和连接它们的边组成。 树类似于图,但区分树和图的重要特征是树中不存在环路。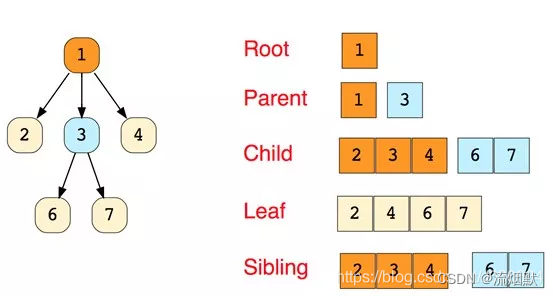常见的树的类型有:N元树、平衡树、二叉树、二叉搜索树、AVL树、红黑树、2-3树。还有一些特殊的比如完全二叉树、满二叉树。每个节点有零个或多个子节点,没有父节点的节点称为根节点,每一个非根节点有且只有一个父节点。除了根节点外原创 2017-02-24 11:47:18 · 5960 阅读 · 0 评论 -
认真学习数据结构之堆
# 【1】什么是堆?堆(heap)是计算机科学中一类特殊的数据结构的统称。堆通常是一个可以被看做一棵树的数组对象。堆总是满足下列性质:* 堆中某个结点的值总是不大于(大顶堆)或不小于其父结点的值(小顶堆);* 堆总是一棵完全二叉树。将根结点最大的堆叫做最大堆或大根堆,根结点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。堆是非线性数据结构,相当于一维数组,有两个直接后继。堆的定义如下:n个元素的序列{k1,k2,ki,…,kn}当且仅当满足下关系时,称之为堆。; public HashMap() ; public HashMap(Map原创 2017-11-03 14:39:48 · 7461 阅读 · 0 评论 -
8种常用排序算法稳定性分析
选择排序、快速排序、希尔排序、堆排序不是稳定的排序算法冒泡排序、插入排序、归并排序和基数排序都是稳定的排序算法。【1】为什么要区分排序算法的稳定性?排序算法的稳定性通俗地讲就是能保证排序前两个相等的数据其在序列中的先后位置顺序与排序后它们两个先后位置顺序相同。再简单具体一点,如果A i == A j,Ai 原来在 Aj 位置前,排序后 Ai仍然是在 Aj 位置前。下面我们分析一下稳定性的......转载 2019-02-09 18:45:08 · 16062 阅读 · 8 评论 -
【每日一面】常见的排序算法与Java实现
【1】冒泡排序import java.util.Comparator;/** * 排序器接口(策略模式: 将算法封装到具有共同接口的独立的类中使得它们可以相互替换) */public interface Sorter { /** * 排序 * @param list 待排序的数组 */ public <T extends Compar...原创 2019-01-18 19:55:34 · 613 阅读 · 1 评论 -
数据结构和算法中的时间复杂度到底是什么?
简单地说,时间复杂度对应代码运行时间,空间复杂度对应代码占用空间。由于运行环境和输入规模的影响,代码的绝对执行时间是无法估计的,但是我们却可以预估出代码的基本操作执行次数。【1】基本操作执行次数关于代码的基本操作执行次数,我们用四个生活中的场景,来做一下比喻:场景1:给小灰一条长10寸的面包,小灰每3天吃掉1寸,那么吃掉整个面包需要几天?答案自然是 3 X 10 = 30天。如果面包的长......转载 2019-01-22 18:38:45 · 1862 阅读 · 0 评论 -
判断2..100以内的质数--sqrt
一个判断2..100以内的质数算法引起的几点疑惑。 先看算法:明天写说明一下内层循环为什么以sqrt(i)为分界点:首先,约数是成对出现的。比如24,你找到个约数3,那么一定有个约数8,因为24/3=8。然后,这对约数必须一个在根号n之前,一个在根号n之后。因为都在根号n之前的话,乘积一定小于n(根号nX根号n=n),同样,都在根号n之后的话,乘积一定大于n。所以,如果你在根号n之前都找不到约原创 2016-10-20 22:01:55 · 1851 阅读 · 0 评论 -
常见基础实用算法详解
排序大的分类可以分为两种:内排序和外排序。在排序过程中,全部记录存放在内存,则称为内排序,如果排序过程中需要使用外存,则称为外排序。内排序有可以分为以下几类:插入排序:直接插入排序、二分法插入排序、希尔排序。选择排序:简单选择排序、堆排序。交换排序:冒泡排序、快速排序。归并排序基数排序【1】快速排序算法快速排序是由东尼·霍尔所发展的一种排序算法。在平均状况下,排序 n 个项目要...原创 2019-01-21 16:09:21 · 1694 阅读 · 0 评论 -
Comparable和Comparator两种比较器详解
【1】ComparableComparable,翻译一下为可比较的。从汉语词义来看,通常是表明对象特性,即该对象是可比较的。实现了该接口的类的实例对象就可以进行自然排序,该实例对象的集合接口源码如下:package java.lang;public interface Comparable<T> { int compareTo(T var1);}...原创 2020-05-21 09:51:27 · 2863 阅读 · 0 评论 -
深入学习Java集合之ArrayList的实现原理
ArrayList 是List 接口的可变数组的实现,底层就是一个数组, 因此按序查找快, 乱序插入、删除因为涉及到后面元素移位所以性能慢。实现了所有可选列表操作,并允许包括 null 在内的所有元素。除了实现 List 接口外,此类还提供一些方法来操作内部用来存储列表的数组的大小。每个ArrayList 实例都有一个容量,该容量是指用来存储列表元素的数组的大小。它总是至少等于列表的大小。随着向.........原创 2019-02-07 17:26:34 · 1069 阅读 · 0 评论 -
Java集合之Set概述及内外比较器详解
Set接口是Collection的子接口,set接口没有提供额外的方法Set 集合不允许包含相同的元素,如果试把两个相同的元素加入同一个 Set 集合中,则添加操作失败。Set 判断两个对象是否相同不是使用 == 运算符,而是根据 equals 方法map中的所有key,即为一个set;所有value,即为一个collection。1.Set实现类之一:HashSet2.hashCode() 方法3......原创 2016-11-18 11:00:04 · 2568 阅读 · 0 评论 -
认真研究JDK1.7下HashMap的循环链表和数据丢失问题
本篇博文以jdk1.7为例分析。前面博文[认真研究HashMap的初始化和扩容机制](https://blog.csdn.net/J080624/article/details/78435449)我们详细分析了jdk1.7和Jdk1.8下HashMap的扩容机制。其中在jdk1.7下如果并发扩容,将会存在循环链表、数据丢失问题。本文我们详细描述这个过程。**我们再回顾一下resize方法:**```javavoid resize(int newCapacity) { Entry[]转载 2019-02-25 20:13:14 · 3373 阅读 · 0 评论 -
HashMap、HashTable、LinkedHashMap和TreeMap及ConcurrentHashMap用法和区别
Java为数据结构中的映射定义了一个接口java.util.Map,其由诸多实现类,其中四个实现类分别是**HashMap、HashTable、LinkedHashMap和TreeMap**。**Map用于存储键值对,根据键得到值,因此不允许键重复,值可以重复。**# **【1】定义与特性**## **① HashMap**HashMap是一个最常用的Map,它根据键的hashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。HashMap最多只允许一条记录的键.原创 2016-10-14 14:31:17 · 1568 阅读 · 1 评论 -
HashMap和Hashtable的区别
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。 Hash...原创 2016-10-13 17:59:50 · 4227 阅读 · 0 评论 -
数据结构之Map基础入门与详解
# 【1】概念介绍Map用于保存具有**映射关系**的数据,因此Map集合里保存着两组值,一组值用于保存Map里的key,另外一组值用于保存Map里的value。key和value都可以是任何引用类型的数据。`Map的Key值为set,不允许重复,即同一个Map对象的任何两个key通过equals方法比较结果总是返回false。`**关于Map,我们要从代码复用的角度去理解**java是先实现了Map,然后通过包装了一个所有value都为null的Map就实现了Set集合。Map的这些实现类原创 2016-11-18 11:08:32 · 13859 阅读 · 0 评论 -
认真研究Java集合之ArrayList的实现原理
ArrayList底层基于数组实现容量大小动态变化,允许 null 的存在。同时还实现了 RandomAccess、Cloneable、Serializable 接口,所以ArrayList 是支持快速访问、复制、序列化的。在频繁插入和删除场景中其性能不如LinkedList。# 【1】核心属性和构造## ① 核心属性```java// 默认初始化数组大小private static final int DEFAULT_CAPACITY = 10;//空的数组实例private stat原创 2016-11-18 11:13:06 · 1117 阅读 · 0 评论 -
认真研究Java集合之LinkedList的实现原理
LinkedList同时实现了List接口和Deque对口,也就是它既可以看作一个顺序容器,又可以看作一个队列(Queue),同时又可以看作一个栈(stack)。```javapublic class LinkedList extends AbstractSequentialList implements List, Deque, Cloneable, java.io.Serializable//...} ```当你需要使用栈或者队列时,可以考虑用L............原创 2017-05-15 14:32:43 · 3668 阅读 · 0 评论 -
Java集合概述和总结分析与图示
JAVA集合中主要分为两大体系:collection 、map。1.Collection接口2.Map接口继承树3.Collection接口详解主要方法:4.Map接口详解主要方法:5.使用Iterator接口遍历集合6.实现类对比分析原创 2016-11-18 10:46:08 · 1217 阅读 · 0 评论 -
数据结构之List基础入门与详解
1.List接口底层使用数组实现2.List实现类之一:ArrayList3.List实现类之二:LinkedList4.List 实现类之三:Vector5.ListIterator接口6.Iterator和ListIterator主要区别原创 2016-11-18 10:51:41 · 2208 阅读 · 0 评论 -
浅谈从fail-fast机制到CopyOnWriteArrayList使用
在ArrayList、HashMap和HashSet等集合的Javadoc中,你会看到类似如下注释:图片来源于ArrayList的javadoc 第一段翻译如下:waiting..原创 2018-09-13 18:00:17 · 1612 阅读 · 1 评论 -
认真研究Java集合之HashSet 的实现原理
HashSet 是 Set 接口的典型实现,由哈希表(实际上是一个HashMap 实例)支持,大多数时候使用 Set 集合时都使用这个实现类。HashSet 按 Hash 算法来存储集合中的元素,因此具有很好的存取和查找性能。HashSet 具有以下特点:不能保证元素的排列顺序HashSet 不是线程安全的集合元素可以是 null当向 HashSet 集合中存入一个元素时,HashS............原创 2019-01-23 19:42:52 · 2662 阅读 · 0 评论 -
数据结构基础入门
简单地说,数据结构是以某种特定的布局方式存储数据的容器。这种“布局方式”决定了数据结构对于某些操作是高效的,而对于其他操作则是低效的。首先我们需要理解各种数据结构,才能在处理实际问题时选取最合适的数据结构。首先列出一些最常见的数据结构,我们将逐一说明:数组栈队列链表树图字典树(这是一种高效的树形结构,但值得单独说明)散列表(哈希表)【1】数组数组是最简单、也是使用最广泛的...转载 2019-01-16 18:12:25 · 2212 阅读 · 0 评论 -
数据结构之Queue入门与详解
Queue用于模拟"队列"这种数据结构(先进先出 FIFO)。队列的头部保存着队列中存放时间最长的元素,队列的尾部保存着队列中存放时间最短的元素。新元素插入(offer)到队列的尾部,访问元素(poll)操作会返回队列头部的元素,队列不允许随机访问队列中的元素【1】 PriorityQueuePriorityQueue并不是一个比较标准的队列实现,PriorityQueue保存队列元素的顺序并.................................原创 2019-01-28 15:45:50 · 2241 阅读 · 0 评论 -
认真学习数据结构之红黑树
【1】什么是红黑树红黑树是一种自平衡树,它也是一颗二叉树。既然能保持平衡,说明它和AVL树类似,在插入或者删除时肯定有调整的过程,只不过这个调整过程并不像AVl树那样繁琐。为何红黑树使用得比AVL树更多,就是因为红黑树它的调整过程迅速且简短。① 五个特点:节点是红色或黑色根是黑色所有叶子都是黑色(叶子是NIL节点,也就是Null节点)如果一个节点是红的,则它的两个儿子都........................................................原创 2019-02-14 20:31:32 · 1026 阅读 · 0 评论 -
认真学习阻塞队列ArrayBlockingQueue与LinkedBlockingQueue
【1】阻塞队列阻塞队列与我们平常接触的普通队列(LinkedList或ArrayList等)的最大不同点,在于阻塞添加和阻塞删除方法。阻塞添加所谓的阻塞添加是指当阻塞队列元素已满时,队列会阻塞加入元素的线程,直队列元素不满时才重新唤醒线程执行元素加入操作。阻塞删除阻塞删除是指在队列元素为空时,删除队列元素的线程将被阻塞,直到队列不为空再执行删除操作(一般都会返回被删除的元素)由........................转载 2019-02-14 21:50:56 · 1865 阅读 · 0 评论 -
认真学习Java集合之HashMap的实现原理
HashMap 是基于哈希表的Map 接口的非同步实现。此实现提供所有可选的映射操作,并允许使用null 值和null 键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(........................................................原创 2019-02-08 15:23:02 · 2647 阅读 · 0 评论 -
认真学习Java集合之LinkedHashMap的实现原理
【1】LinkedHashMap定义LinkedHashMap是HashMap的子类,其实现与HashMap 的不同之处在于,LinkedHashMap维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。注意,此实现不是同步的。如果多个线程同时访问链接的哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须保持外部同步。对于Link...............原创 2019-02-09 18:22:09 · 984 阅读 · 0 评论 -
认真学习jdk1.7下ConcurrentHashMap的实现原理
HashMap无论是 1.7 还是 1.8 其实都能看出 JDK 没有对它做任何的同步操作,所以并发会出问题,甚至出现死循环导致系统不可用。这个问题就交给ConcurrentHashMap。ConcurrentHashMap是一个 在juc包下的 map, 线程安全。 在jdk.1.8 之前采用数组+ 链表的结构 并且采用`分段锁机制` 来保证线程安全,而jdk1.8 改成了 数组+ 链表+ 红黑树,线程安全方面也改成了 `cas+ synchronized` 来保证线程安全。**Concurre原创 2019-02-09 21:08:47 · 1449 阅读 · 0 评论 -
认真学习Java集合之TreeMap的实现原理
TreeMap继承自AbstractMap 实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。此外其还实现了Cloneable, java.io.Serializable两个接口说明其是可以被克隆、序列化的。TreeMap基于红黑树(Red-Black tree)实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的Comparator 进行排序,具体取决于使用的构造方法。# 【1】核心属性和构造## ① 核心属性```java//比较器原创 2019-02-28 17:19:46 · 1230 阅读 · 0 评论