






HTTP基本框架
关于 HTTP 这部分内容请移步之至☞ https://blog.csdn.net/J4Ya_/article/details/80892967
主要学习以下几个部分
-
HTTP 请求的方法
-
HTTP 报文格式(主要理解 GET 请求和 POST 请求)
-
HTTP 状态码
-
URL 格式
服务器开发流程(HttpServerStart)
启动服务器主要流程(HttpServer)
-
创建 tcp socket(socket)
-
绑定端口号(bind)
-
监听 socket 套接字
-
进入事件循环
-
获得 new socket(accept)
-
使用多个线程处理多个连接的并行操作(pthread_create),为了避免形成类似于僵尸进程,也为了不使进程因为等待阻塞,使用 pthread_detach 使线程结束后自动释放资源
-
处理请求(HandlerRequest),给出响应
-
处理请求主要流程(HandlerRequest)
-
解析
-
Http请求是行文本格式,这里按照行方式从 socket 中读取首行(ReadLine)
-
解析首行(ParseFirstLine),得到对应的方法(mathod)和url
-
解析url中的QueryString(ParseQueryString)
-
读取并解析 header 部分(Handlerheader),取出有用的字段(Content-Length)
-
-
根据请求详情决定执行动态逻辑还是静态逻辑
-
如果是 GET 请求,并且没有 query_string - 静态逻辑(HandlerstaticFile)
-
如果是 GET 请求,并且有 query_string - 动态逻辑(HandlerCGI)
-
如果是 POST 请求 - 动态页面(HandlerCGI)
-
静态页面主要流程(HandlerstaticFile)
-
根据解析出的 url_path,获取到对应的真是文件路径
-
为当前的 url_path 前拼接上自己的根目录,这里叫 static
-
当 url_path 最后一个字符是 '/' ,表示当前访问的是一个目录,那就为这个路径后拼接上默认的页面,这里叫 index.html
-
如果最后一个字符不是 '/',但是访问的还是一个目录,那就为这个路径后拼接上 '/index.html'
-
-
读取文件内容,并写入 socket
-
构造 Http 响应,四部分(首行,Header,空行,Body)
-
动态页面处理流程(HandlerCGI)
-
创建一对匿名管道,完成进程间通信
-
fork 创建子进程
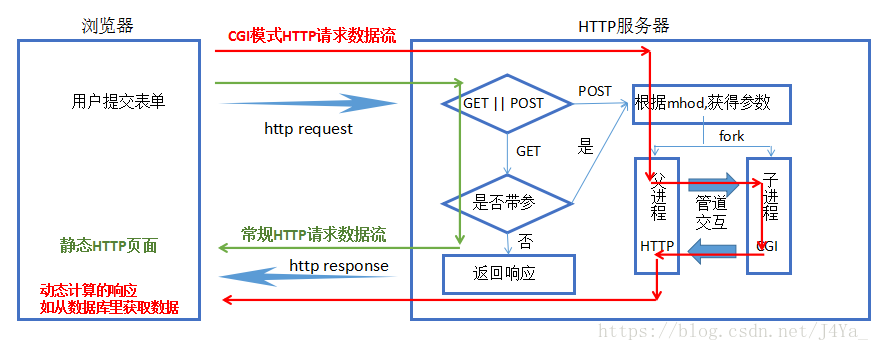
父进程逻辑(HandlerFather)
-
如果是 POST 请求,就将 body 写入管道
-
从管道读取子进程返回的 html 页面,把读取到的内容写入 socket 中(CGI 程序中构造了首行,Header,空行,body)
-
进程等待(可以使用 waitpid,这里直接忽略 SIGPIPE 信号)
子进程逻辑(HandlerChild)
-
设置环境变量,这里是简化了进程间通信
-
设置 REQUEST_METHOD
-
如果是 GET 请求,就设置 QUERY_STRING
-
如果是 POST 请求,就设置 CONTENT_LENGTH
-
-
将标准输入输出都重定向到管道中
-
dup2(child_read,0)
-
dup2(child_write,1)
-
-
进行程序替换(execl)
CGI 程序
理解 CGI
CGI(Common Gateway Interface) 是WWW技术中最重要的技术之一,有着不可替代的重要地位。CGI是外部应用程序(CGI程序)与WEB服务器之间的接口标准,是在CGI程序和Web服务器之间传递信息的过程。
这里为了练习 Python 的使用,我的 CGI 程序都是使用 Python 完成的,可能有些人会有疑惑,为什么服务器的 CGI 是用 C/C++ 写,而这里的 CGI 使用 Python写的?
注意,http提供CGI机制,和 CGI程序是两码事,所以,理论上 CGI程序你用什么编程语言写都可以,只要是可执行文件,就 OK 了
Python数据库操作
-
连接数据库
-
获取游标
-
构造查询语句
-
执行查询语句
-
关闭游标
-
关闭数据库连接
和服务器交互
上面我们说过,在子进程逻辑中,我们将子进程的输入输出都重定向到管道里,子进程进行了程序替换,那么当然,这里的 CGI 程序也就是替换以后的子进程,而 CGI程序的标准输出已被重定向至管道中,所以当我们进行 print 操作时,实质上就是向管道中写数据,再被父进程读取到 socket 中
所以我们可以通过标准输出的方式构造 HTTP响应
-
首行 - 主要构造 POST 方法
-
Header - 主要构造 Content-Type方法
-
空行
-
body - 只要构造我们需要向用户显示的 html 页面
错误处理
这个程序中有很多可能会出问题的点
- 按行读取失败
-
解析数据失败
-
静态页面处理失败
-
动态页面处理失败
这些失败了,我们都做一个简单处理,就是返回 404 响应

需要注意的点
-
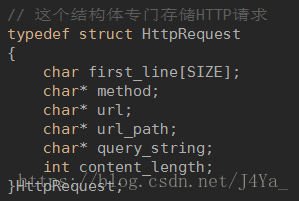
使用了一个结构体来保存 HttpRequest 信息,具体结构如下
-
按行读取的时候(ReadLind),网络中的回车换行符可能有 \n,\r, \n\r,三种情况需要全部考虑到
-
解析请求时,用到了 Split 函数,其实现就是按照特定的字符分隔字符串,但是注意,这个函数里千万不要使用 strtok 来实现分隔,因为他是线程不安全的!因为他是线程不安全的!!因为他是线程不安全的!!!我们替换成 strtok_r 就好了
-
在解析 Header 的时候,如果我们已经得到我们需要的字段,比如 Content-Length 之后,不可以跳出循环,我们必须把接受缓冲区的数据全部读完,避免粘包问题!避免粘包问题!!避免粘包问题!!!
-
当我们向一个 socket 中写数据的时候,可以使用 sendfile 函数,这个函数的优点是直接从内核中将一个文件的内容写到 socket 中,不经过内核态,大大提高效率
-
处理父进程逻辑的之前, 必须将子进程对应的管道关掉,因为读取子进程的时很有可能读失败,如果操作系统发现当前管道还有一个读端,就会阻塞,直到读端关闭,而子进程已经读取失败,即子进程异常,就无法去关闭这个文件标识符,导致一直阻塞
项目文件
http_server
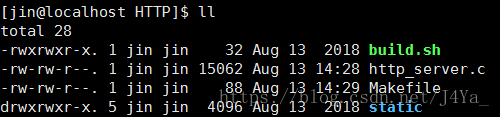
服务器根目录
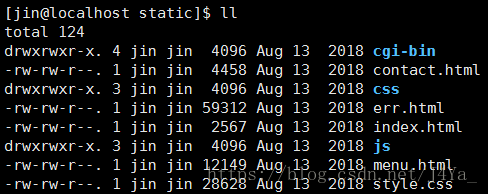
动态页面(CGI程序)
项目源码
GitHub: https://github.com/J4Yaaa/Py-plug-in














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









