






如果把数据中心比作一个“人”,则服务器和存储设备构成了数据中心的“器官”,而网络(交换机,路由器,防火墙)就是这个数据中心的“神经脉络”。那本节就针对数据中心的网络架构和一般设计的套路来说了。
01网络分区与等保
一般情况下,本着灵活、安全、易管理的设计原则,企业都会对数据中心网络的物理设备进行分区。通常情况下,数据中心都会采用核心—汇聚—接入三层的网络结构,核心用于所有流量的快速转发,而汇聚则是在每个网络分区上,担任网关的功能。
一般来说,数据中心的网络分区中,每一个区域会根据预期的流量和服务器的数量,分配不同的业务网段。同时,在一些等保要求较高的区域,还会设置防火墙这样的安全设备,来控制进出这个区域的流量,如下图所示:
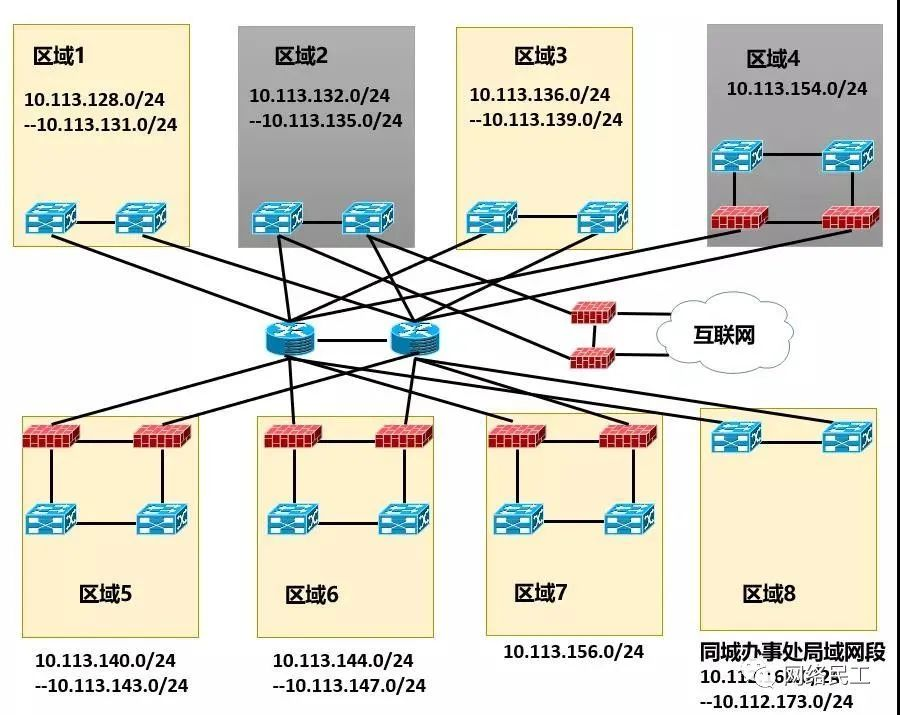
“等保”是等级保护的简写,在设置数据中心服务器区域的时候,不同业务的服务器的等级保护是不一样的。比如后台存储,带库,数据库这些服务器的等保和Web、前端、APP的等保就不一样。而在数据中心网络中,防火墙的功能,就是用来划分“等保”,同时用来控制不同等保之间的互访。
那如何更好的来理解这个“等保”的概念呢?
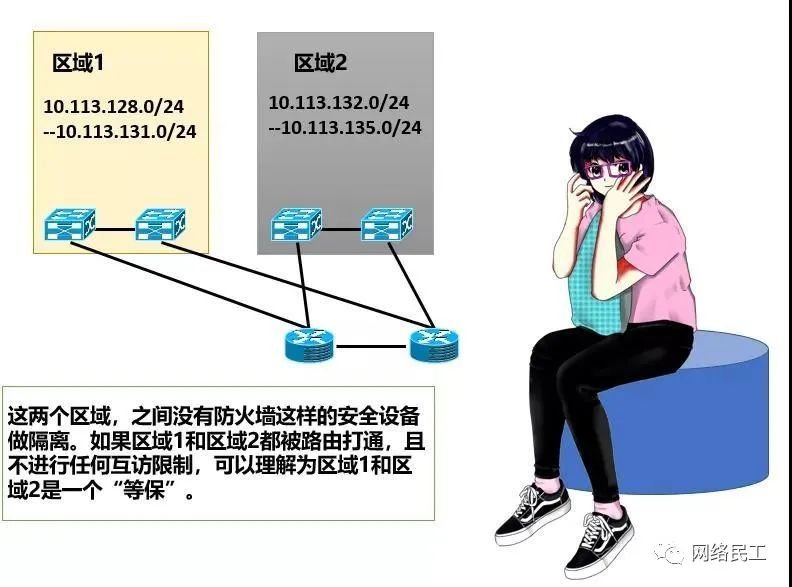
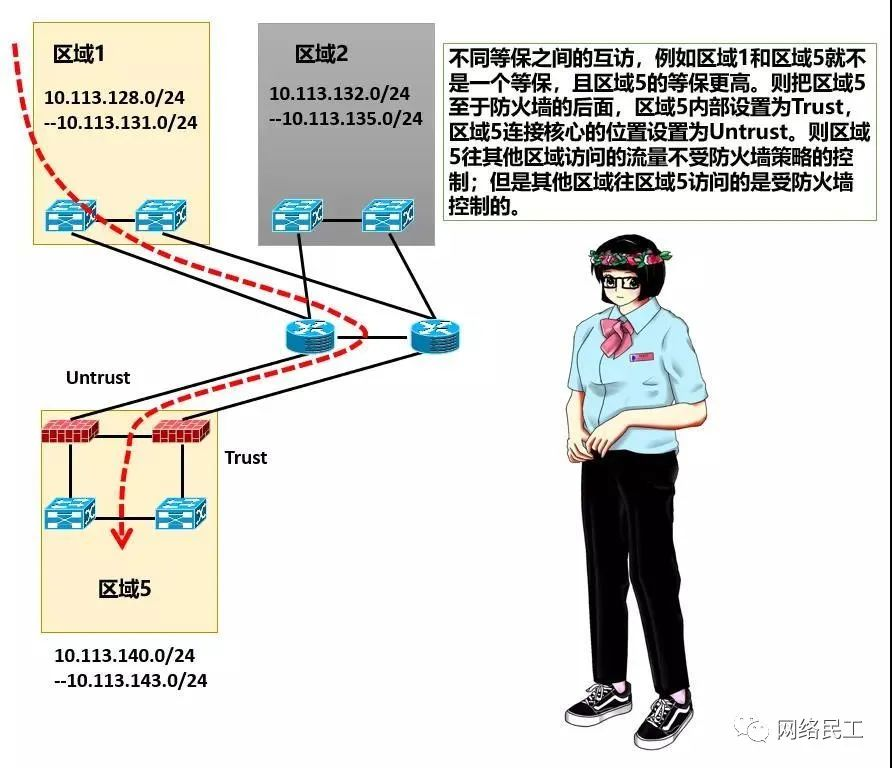
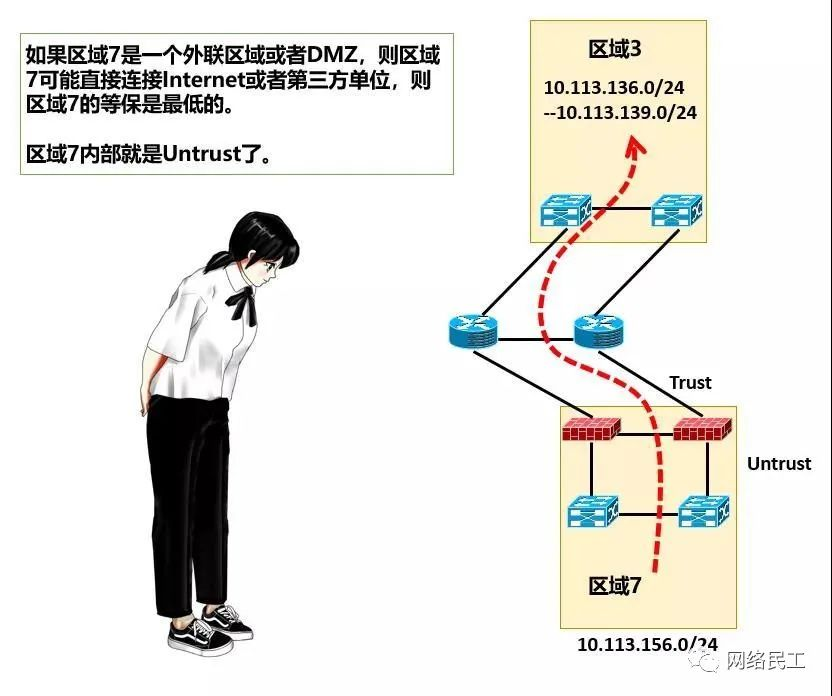
在目前的数据中心网络架构中,要考虑到不同等保之间的流量控制,又要考虑到在设计路由的时候的简便和快捷,目前数据中心的防火墙几乎都会采用旁路的方式来部署,再配合汇聚交换机上的VRF来控制流量。
02数据中心网络分区的方式
分区的划分方式有以下三种,不同分区方式各有优缺点,通常结合使用。
A.按照服务器类型分区
比如x86服务器、小型机、刀片机、大型机、虚拟机进行分类。完全按照服务器型号分类的话,在实际应用中,可能某个企业小型机被大量使用,而大型机几乎没用,就会导致小型机的网络区域流量巨大而大型机这个区域闲置了。所以,现在的数据中心,几乎看不见如此分配区域的情形了。
B.按照应用层次分区
比如Web、APP是前端服务器,而数据库、存储、NFS这些是后端服务器,所以把前端服务器放在一个区域,后端服务器放在一个区域。在有些企业的数据中心,也确实是这么分区的。比如,所有的Web服务器放在“综合业务区”,把数据库就放在“生产管理区”(你也看出来,连区域名字都起得那么“模糊” )。如此分区的好处是便于管理,因为前端服务区域和后端服务区域不在一个等保内,前端服务区域直接面对办公,后端区域则为前端区域服务,如下图所示:
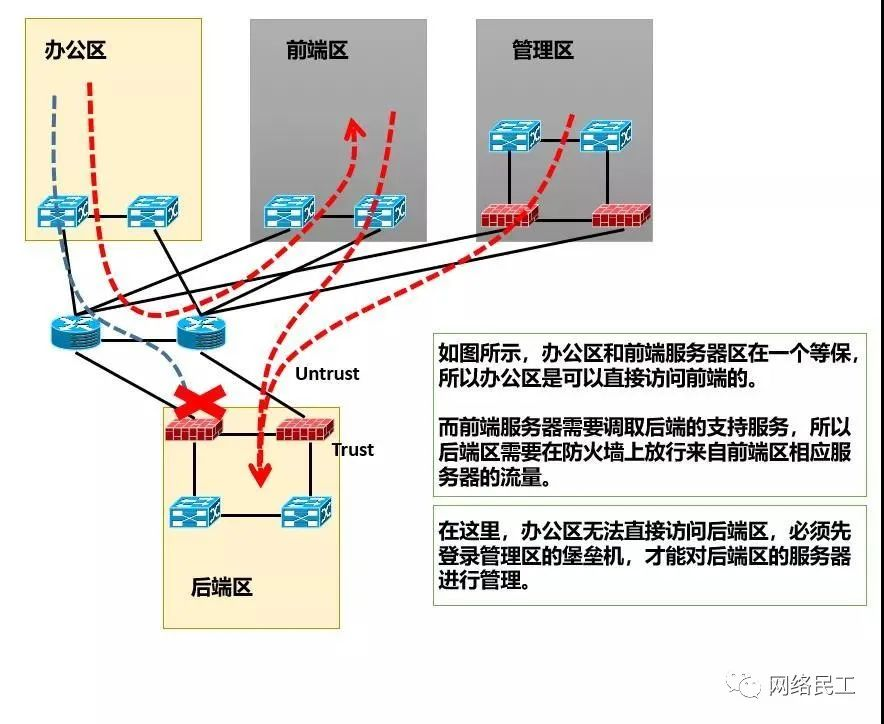
这种区域的设置方式的好处是便于分开管理,但是坏处也是运维起来屁事太多。比如,前端新上线了一个APP,后端需要相应的数据库支持,此时系统运维人员就要找网络运维人员,请他们在后端区的防火墙上开通相应的安全策略。考虑到前端和后端对接也有诸多非网络的问题,加上前端和后端之间又有防火墙的“阻碍”,所以一旦前端和后端的通信出了问题,网络运维人员就很容易“被背锅”了。
C.按照应用类型划分
例如核心服务,公共服务,办公区域,隔离区域,开发测试区域进行划分。这种分区的好处就是,一个“功能业务”的前端服务器和后端服务器都在一个等保内了,在前端和后端对接的时候,网络运维人员不至于因为防火墙策略的原因而“背锅”。但是这样划分又会显得网络规划有点“混乱”。对于一些对前期IP地址规划不太重视的管理员来说,可能会对前端服务器和后端服务器的IP地址规划带来些麻烦。比如,给核心服务器区的IP地址段是10.114.128.0/21,在这里有10.114.128.0/24---10.114.135.0/24,整整16个C段。但是对于不严谨的管理员来说,可能会让10.114.128.0/24做前端的IP地址,10.114.129.0/24做后端的IP地址,这样的话,前端和后端的IP地址段就“交叉”了。
如果遇到一种极端的情况,在多级数据中心使用MPLS V.PN网络对接,让前端和后端的流量“分流”时,这种前端和后端IP地址段一“交叉”,分流就会显得极其麻烦。
综上所述,每一种分区的方式,都有自己的优点和缺点,所以也要按照实际情况进行分区。
03数据中心常用网络架构
A.扁平化组网
对于功能单一,服务器数量小于300台的小型数据中心来说,通常情况下都会采用两层式的扁平化组网。也就是汇聚设备担任网关,接入设备就是一个二层设备,打通二层通道的功能。对于扁平化的组网,也分为比较传统的VRRP+MSTP,和“堆叠+链路捆绑”两种方式进行组网设计。
第一种就是VRRP+MSTP的结构,如下图所示:
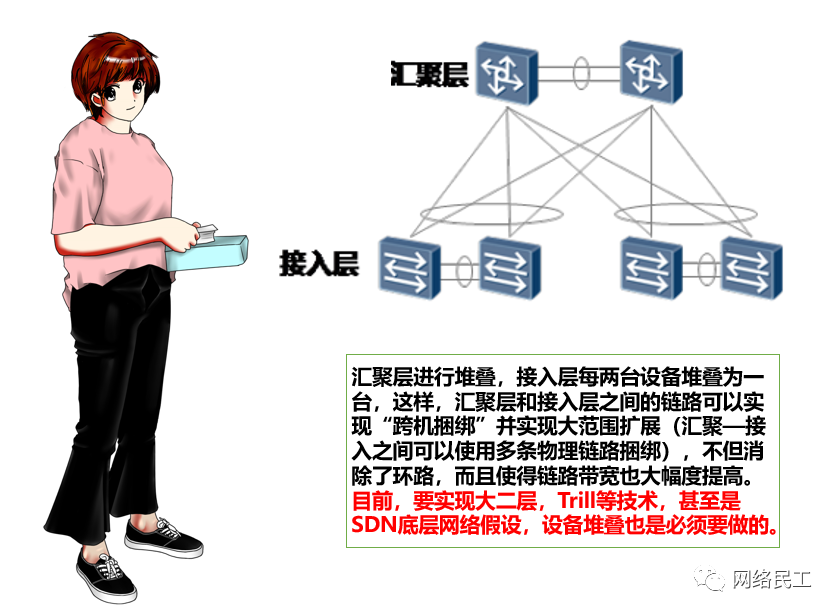
相比起第一种非常传统的MSTP+VRRP的架构,第二种“胖树”结构,则是当前数据中心扁平化组网的常用结构。它的思路是:汇聚交换机必然堆叠,接入交换机按需堆叠,所有冗余链路必须捆绑,形成一个“胖树”状结构。它的优点就是,既保证了设备的冗余性,提升带宽性能,也能从根本上防止二层环路。但是,要实现设备的堆叠,这个对硬件有要求,所以,这种“胖树”状结构的组网,成本比起第一种来说要高不少。
B.三层组网架构
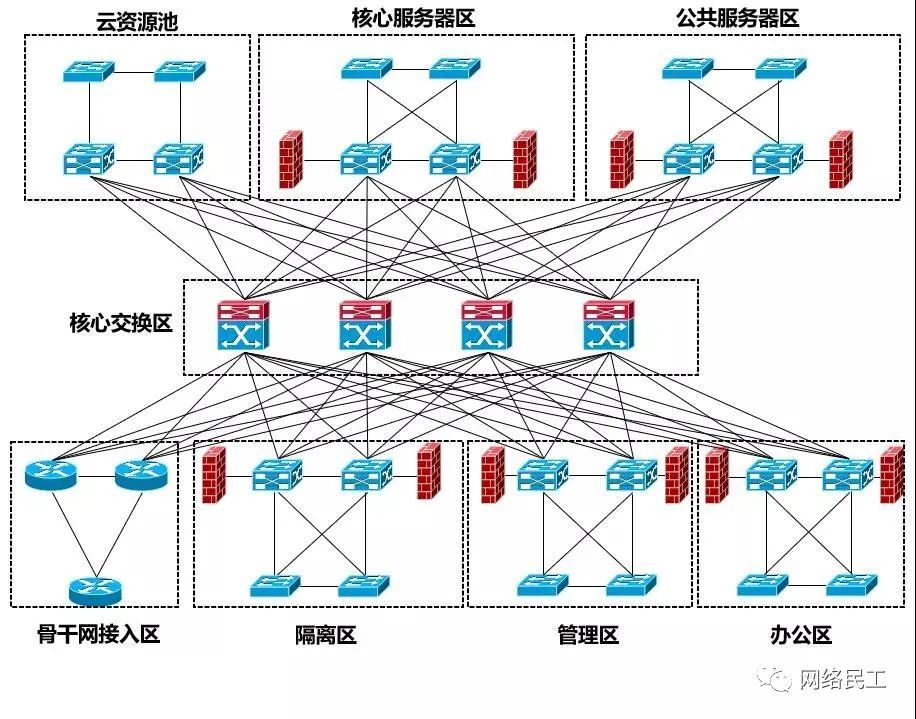
对于大型数据中心,功能多样,且要进行功能分区的场合,就会采用标准的三层架构。
在这种组网方式中,交换核心区是整个数据中心网络的枢纽,核心设备通常部署2-4台大容量高端框式交换机,可以是独立部署,也可以通过堆叠技术后成组部署(但是考虑到核心和汇聚之间都是三层连接,且堆叠有一定裂开风险,所以一般核心都会采用独立部署的方式,即核心之间只和汇聚之间有互联,核心之间无互联)
分区内的汇聚层和接入层通过堆叠实现二层破环。
下图为大家展示了一个当前主流的数据中心三层组网架构图:
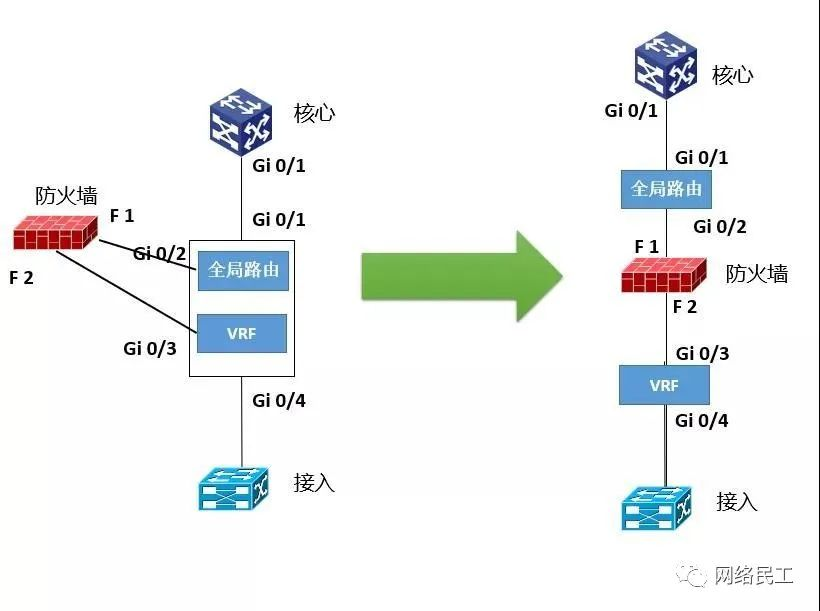
刚才的拓扑图中,各个大区域之间的防火墙采用了旁路的连接方式。防火墙采用旁路连接的目的,也是为了提升可扩展性,并且可以兼容动态路由。而这种结构,要想实现核心—汇聚—接入之间的流量进入防火墙,就需要使用VRF在汇聚交换机上隔离路由了。所以,VRF在这个地方,起到的作用是隔离路由,起到一个“化旁路为串联”的作用。
本文的难点,也正好是汇聚交换机上使用VRF时,这个业务流的逻辑图如何画出。实际上,我本人在刚接到这个项目的时候,也是花了一段时间来理解这个VRF和旁路防火墙之间的关系的。下面我可以简单为大家说一下划业务流的方法。
所谓“单一等保”,实际上就是汇聚下方的所有业务网段可以直接访问,流量无需经过防火墙控制。在这种情况下,就只需要一个VRF,把汇聚—核心和汇聚—防火墙之间的流量隔离开即可。
物理连接图如下:
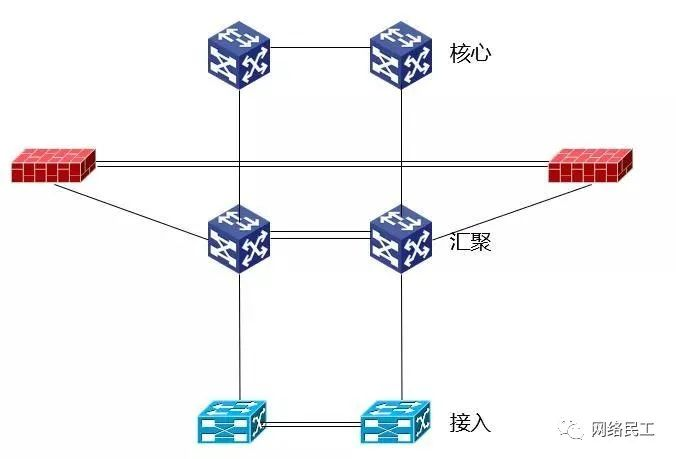
由于汇聚、接入,包括防火墙做了双机或者堆叠,所以在此时可以将汇聚、接入先暂时画成单个设备,这样物理结构就不会太复杂了。
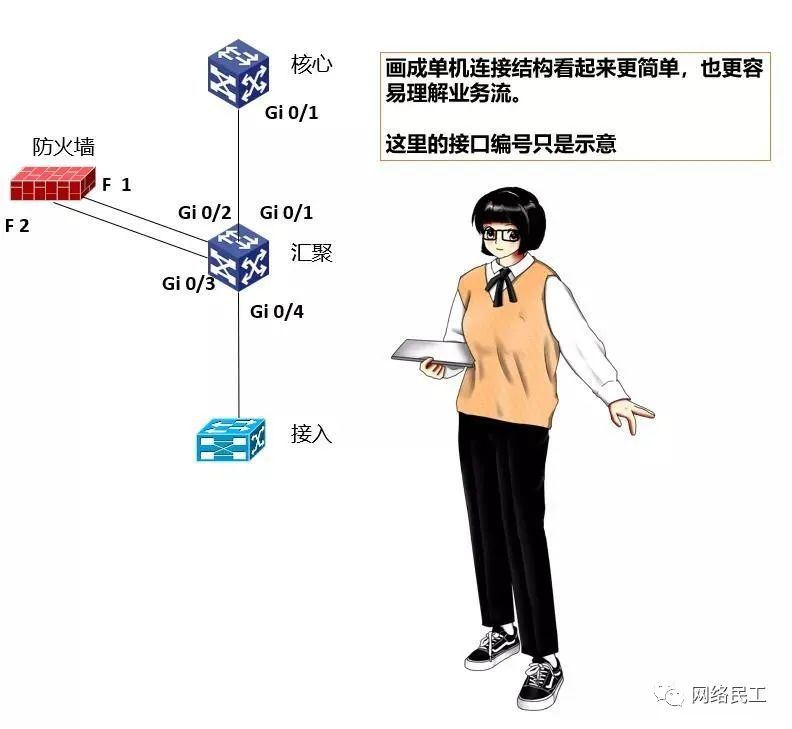
然后,去掉汇聚层设备的图标,用一个方框来代替。在方框内部添加两个小方框,代表两个拥有独立三层路由的虚拟设备,与核心连接的是全局路由,与接入连接的是VRF路由。然后,防火墙上“画出”两条线,分别与“全局路由”小框和“VRF”小框互联。防火墙与汇聚连接的两条线,可以是不同的物理接口,也可以是不同的子接口。如下图所示:
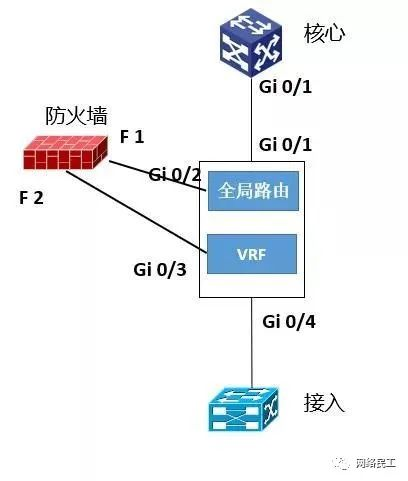
最后,去掉汇聚层设备位置的大方块,将防火墙“塞”在“全局路由”小框和“VRF”小框之间,这样,一个单一等保级别的,化旁路为串联的流量图就完成了。
两个等保级别,这就要求了两个等保级别内的业务在互访时,流量需要经过防火墙。这里你就要记住:一个等保一个VRF,不同等保级别的流量要放在不同的VRF内。
在画双等保逻辑流量的时候,采用的方式和单一等保逻辑流量的方式是一样的。第一步,仍然是把双机结构改成单机结构,所不同的是,防火墙和汇聚之间,需要画三条线。总之,汇聚下面有N个等保,汇聚和防火墙之间就画N+1条线。
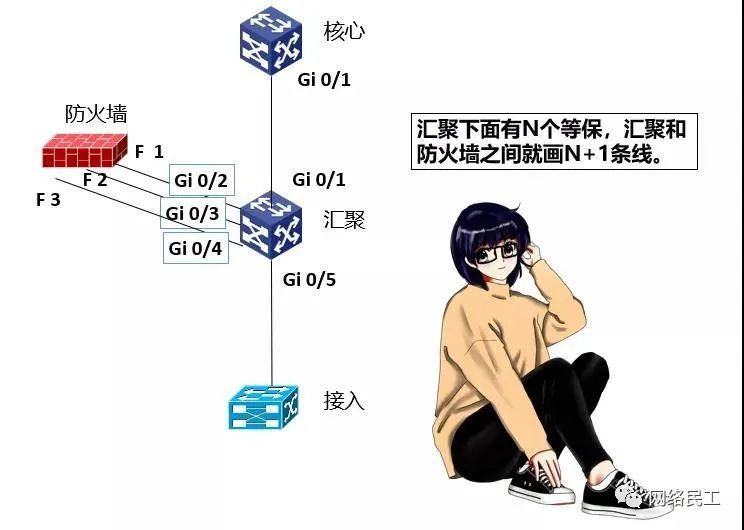
然后,去掉汇聚层设备的图标,用一个方框来代替。在方框内部添加三个小方框,代表三个拥有独立三层路由的虚拟设备,接入层交换机换成两个,分别代表等保1的接入和等保2的接入。
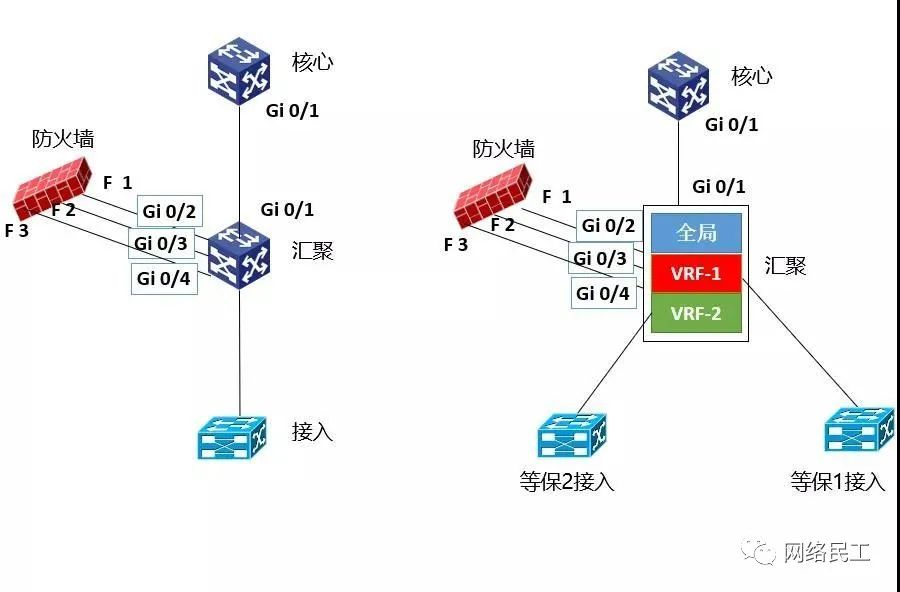
然后,去掉大方框,将防火墙“塞”在“全局路由”小方框和“VRF-1”、“VRF-2”小方块之间,先形成如下图所示的结构:
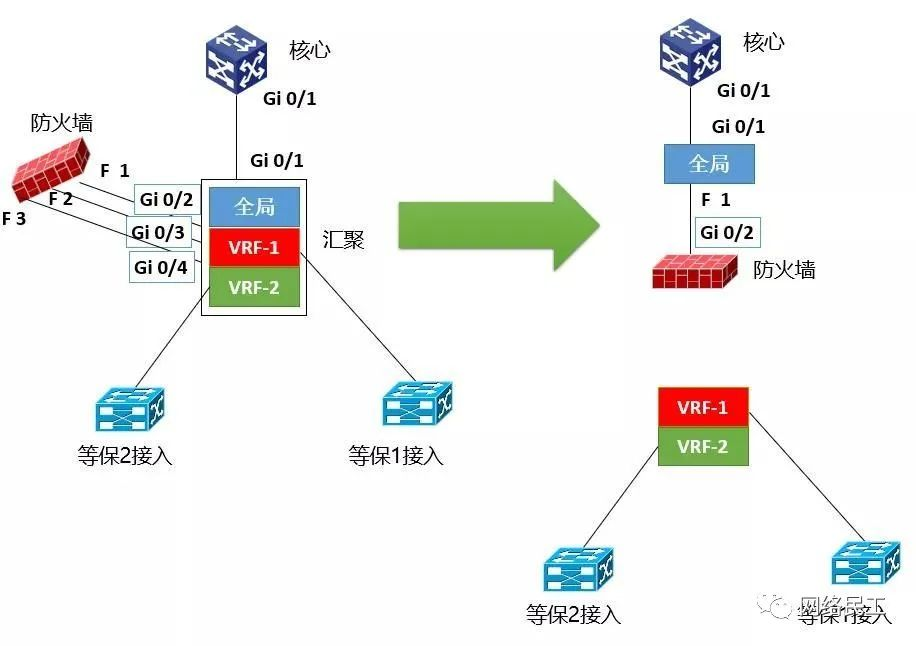
最后,将两个等保“VRF”的小方块,分别连接在防火墙的两边,这样,一个双等保的化旁路为串联的业务流逻辑图就画好了,根据标注的接口编号和规划的IP地址,就可以写配置脚本了。而且串联的逻辑图画好以后,也立刻能够知道静态路由该如何规划了。
记住一点:“全局”、“VRF-1”、“VRF-2”上标注的接口,其实全是汇聚交换机的。
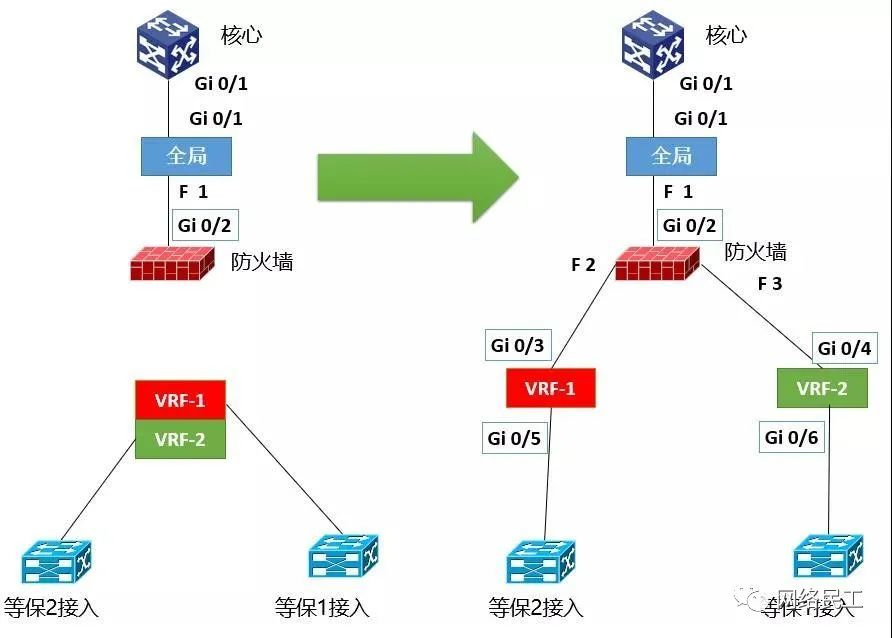
记住这个方式,以后遇到旁路防火墙,下面有N多个等保的业务流,也可以按照这个方式去照葫芦画瓢了。
04数据中心未来的发展
随着大数据时代的到来,企业数据中心承载的业务越来越多,新业务上线越来越快。为了满足业务的需要,传统数据中心网络将逐渐向具备弹性、简单和开放特征的新一代数据中心网络演进。
A.弹性
弹性是指网络能够实现灵活、平滑扩展以适应业务不断发展的需要。弹性扩展包括设备级、系统级和数据中心级的扩展。
设备级弹性扩展:网络设备需要具备持续的平滑扩容能力。例如接入交换机可以提供25GE/40GE的接入能力,核心交换机能提供百T以上的交换容量,高密度的100GE/400GE接口等。
系统级弹性扩展:数据中心网络需要支持更大规模的二层网络。例如提供X万台10GE服务器接入的能力。
数据中心级弹性扩展:数据中心互联网络要能够支持多个数据中心的资源整合,实现更大规模虚拟机跨数据中心迁移。
B.简单
简单就在于要能够让网络更好的为业务服务,能够根据业务来调度网络资源,例如要能够实现网络资源和IT资源的统一呈现与管理,能够实现从业务到逻辑网络再到物理网络的平滑转换等。
C.开放
传统网络的管理维护是封闭的,独立于计算、存储等IT资源。网络开放以后,可以打破原有的封闭环境,使网络设备可以与更多的SDN控制器、第三方管理插件、虚拟化平台等协同工作,从而打造更灵活的端到端数据中心解决方案。
来源:网络民工



















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









