







图像标注是向图像添加标签或注释的元数据,使图像上的内容具有上下文含义。这个过程在机器学习中具有重要意义,助于在训练视觉模型过程中准确地识别图像中的元素。
视觉模型最终的用途也非常广泛,例如,帮助车辆识别道路上的不同物体或障碍物、通过对医学图像的识别帮助疾病检测和诊断。
本文主要推荐一些较好的开源免费的图像标注工具。
01 Makesense.ai
http://makesense.ai/
https://github.com/SkalskiP/make-sense

Makesense.ai是一个免费的在线跨平台工具,用于标记照片,非常适合小型计算机视觉深度学习项目。它简化了数据集的准备,标签可以以多种格式下载。该应用程序使用TypeScript编写,基于React/Redux框架开发。它集成了YOLOv、在COCO数据集上预训练的SSD和PoseNet等先进的AI模型,可以自动化图像标注。其中AI功能基于TensorFlow.js框架,因为照片不需要传输到服务器,可确保数据隐私安全。
02 Labelme
https://github.com/labelmeai/labelme
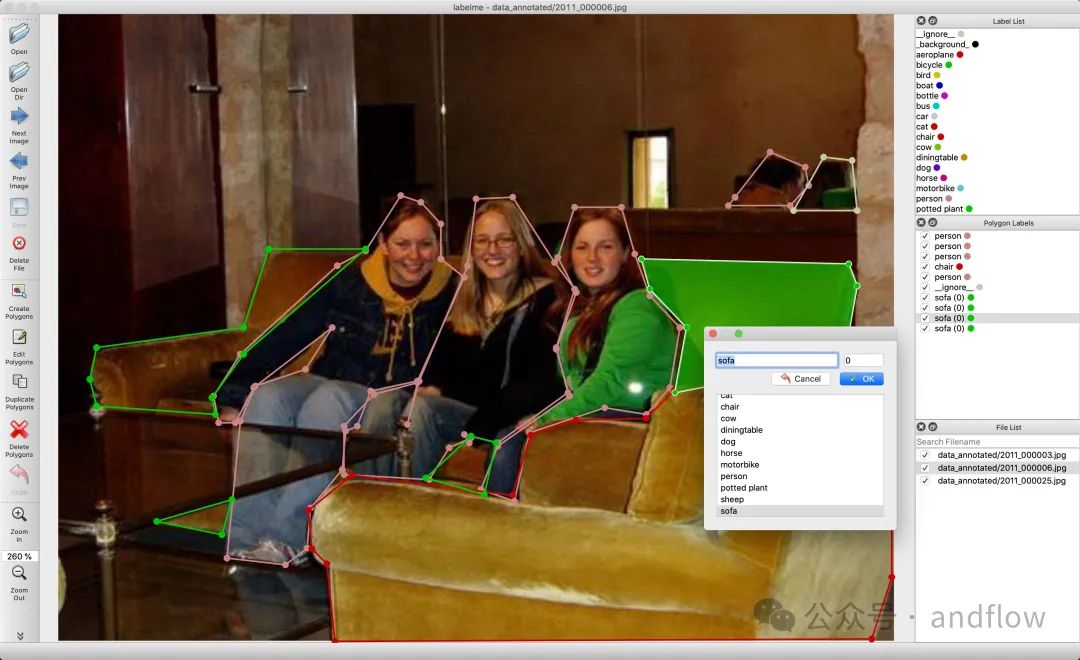
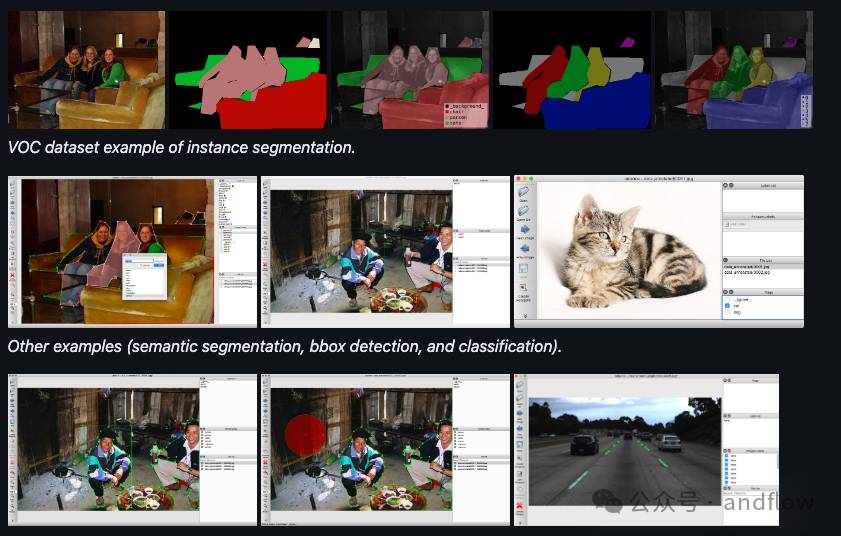
Labelme是一个基于Python的图像标注工具,支持各种标注类型,并提供自定义GUI。可以导出VOC和COCO格式的数据集,用于语义和实例分割。
功能特征
-
支持多边形、矩形、圆形、直线、点和图像级标志注释
-
适用于Ubuntu、macOS和Windows
-
标注信息保存为JSON文件
-
高级用法示例
-
将标记分配给整个图像
-
将标注指定给单个面
03 Xtreme1
https://github.com/xtreme1-io/xtreme1

Xtreme1是一个用于标注多模式训练数据的开源平台,提高了数据注释、管理和本体管理的效率。其人工智能工具旨在提高2D/3D对象检测、3D实例分割和激光雷达相机融合项目的效率。
功能特征
-
支持图像、3D LiDAR和2D/3D传感器融合数据集的数据标注
-
内置预标记和交互式模型支持2D/3D对象检测、分割和分类
-
可配置的本体中心,用于一般类(具有层次结构)和属性,用于模型训练
-
数据管理和质量监测
-
查找和修复标签错误的工具
-
模型结果可视化以协助模型评估
-
用于大型语言模型的RLHF(beta版
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









