




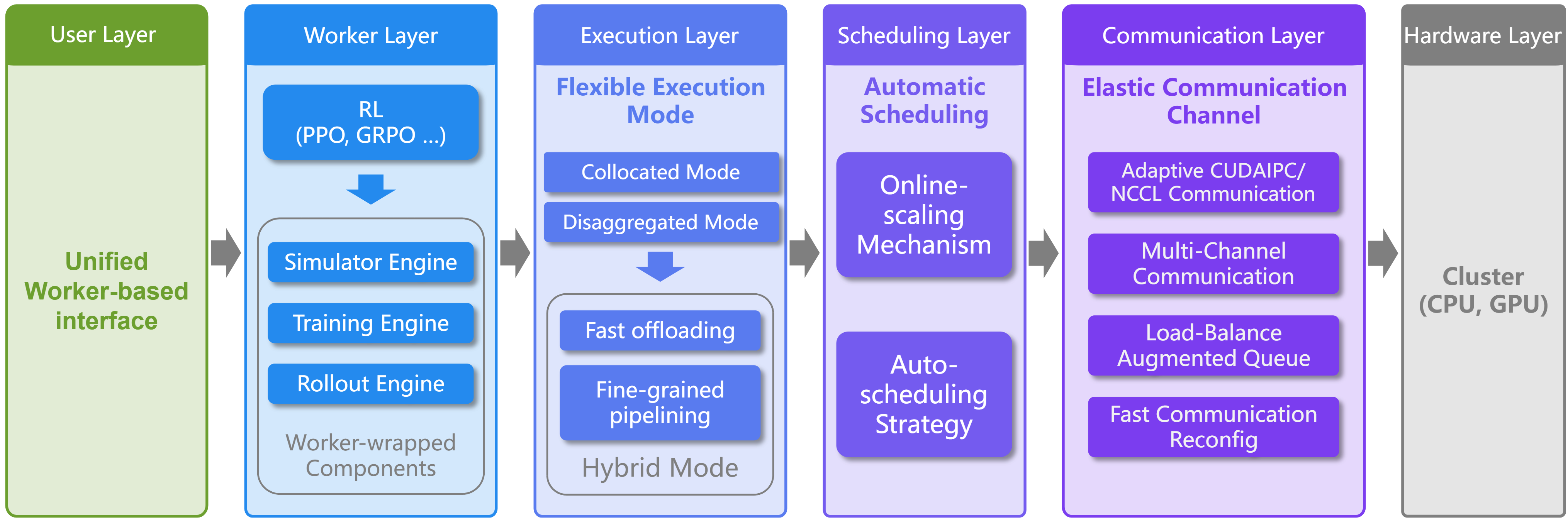
简介
RLinf 是一个灵活且可扩展的开源基础设施,专门为大模型(LLMs、VLMs、VLAs)的强化学习后训练而设计。该框架采用创新的"宏微流转换"(M2Flow)范式,为下一代智能体训练提供强大的基础设施支持。
🔗 GitHub地址:
https://github.com/RLinf/RLinf
🚀 核心价值:
强化学习 · 大模型训练 · 智能体AI · 开源基础设施 · 宏微流转换
项目背景:
-
大模型发展:大模型后训练需求增长
-
RL挑战:强化学习训练复杂性
-
基础设施缺失:专业RL基础设施缺乏
-
效率需求:训练效率优化需求
-
开源生态:开源社区贡献精神
项目特色:
-
🏗️ M2Flow架构:宏微流转换新范式
-
⚡ 高效训练:120%+吞吐量提升
-
🔧 灵活模式:多种执行模式支持
-
🤖 智能体支持:具身智能体训练
-
📊 SOTA性能:多项任务领先性能
技术突破:
-
架构创新:宏微流转换架构
-
自动调度:智能资源调度策略
-
混合模式:协同与分离混合模式
-
异步通信:自适应异步通信通道
-
多后端集成:多种训练后端支持
主要功能
1. 核心功能体系
RLinf提供了一套完整的强化学习训练解决方案,涵盖架构设计、执行模式、资源管理、算法支持、环境集成、模型训练、性能优化、监控分析、扩展集成、部署服务等多个方面。
M2Flow架构功能:
架构能力:
- 宏微转换: 宏逻辑到微执行转换
- 逻辑解耦: 逻辑工作流与物理执行解耦
- 可编程性: 灵活的工作流编程能力
- 执行效率: 高效的物理执行效率
- 资源优化: 智能资源分配优化
M2Flow特性:
- 宏级逻辑: 高级逻辑流程定义
- 微级执行: 底层执行流程优化
- 自动转换: 自动的流程转换机制
- 性能保证: 性能最优保证
- 灵活扩展: 易于功能扩展
架构优势:
- 编程友好: 开发者友好接口
- 效率优先: 执行效率优先设计
- 资源感知: 智能资源感知调度
- 弹性伸缩: 弹性资源伸缩能力
- 故障容错: 强大的容错机制执行模式功能:
模式能力:
- 协同模式: 所有GPU共享模式
- 分离模式: 细粒度流水线模式
- 混合模式: 可定制混合模式
- 自动选择: 自动模式选择策略
- 动态切换: 动态执行模式切换
模式特性:
- 协同优势: 资源充分利用优势
- 分离优势: 细粒度流水线优势
- 混合优势: 两者优势结合
- 智能调度: 智能模式调度
- 性能优化: 自动性能优化
高级功能:
- 流水线优化: 深度流水线优化
- 通信优化: 异步通信优化
- 内存优化: 智能内存管理
- 负载均衡: 自动负载均衡
- 容错处理: 执行容错处理训练优化功能:
优化能力:
- 自动缩放: 自动在线缩放策略
- 资源调度: 智能资源调度
- 性能监控: 实时性能监控
- 瓶颈分析: 训练瓶颈分析
- 优化建议: 自动优化建议
优化特性:
- 快速切换: 秒级GPU切换能力
- 效率提升: 20-40%效率提升
- 策略保持: 保持on-policy性质
- 动态调整: 动态调整资源
- 成本优化: 训练成本优化
优化策略:
- 数据并行: 高效数据并行
- 模型并行: 智能模型并行
- 流水并行: 深度流水并行
- 混合并行: 混合并行策略
- 自动调优: 自动超参数调优2. 高级功能
后端集成功能:
后端能力:
- FSDP后端: Hugging Face集成
- Megatron后端: 大规模训练优化
- SGLang集成: 推理优化支持
- 多后端支持: 多种后端选择
- 自动选择: 智能后端选择
后端特性:
- 快速原型: 快速模型原型开发
- 大规模训练: 超大规模训练支持
- 推理优化: 专用推理优化
- 灵活切换: 后端灵活切换
- 性能最优: 自动性能最优选择
集成优势:
- 易用性: 初学者友好接口
- 扩展性: 专家级扩展能力
- 兼容性: 良好框架兼容性
- 性能性: 最优性能表现
- 稳定性: 生产级稳定性具身智能支持:
支持能力:
- 仿真器集成: 主流仿真器支持
- 标准化接口: 统一RL接口标准
- VLA训练: 视觉语言动作模型训练
- 流程匹配: 动作专家流程匹配
- 多任务支持: 多任务训练支持
仿真器支持:
- ManiSkill3: 机器人技能仿真
- LIBERO: 开放具身基准
- 自定义仿真: 自定义仿真环境
- 多模态仿真: 多模态仿真支持
- 真实世界: 真实世界部署
训练特性:
- π模型家族: π₀和π₀.₅模型支持
- PPO算法: PPO算法支持
- GRPO算法: GRPO算法支持
- 多算法: 多种RL算法支持
- SOTA性能: 领先性能表现数学推理功能:
推理能力:
- 数学推理: 复杂数学问题求解
- 逻辑推理: 逻辑推理能力训练
- 基准测试: 多基准测试支持
- 模型优化: 推理模型优化
- 评估体系: 完整评估体系
基准支持:
- AIME 24/25: 数学竞赛基准
- GPQA: 综合知识测试
- 多尺度模型: 1.5B-7B模型支持
- 对比分析: 多模型对比分析
- 性能领先: SOTA性能表现
推理特性:
- 深度推理: 深度推理能力
- 知识整合: 多知识领域整合
- 错误分析: 推理错误分析
- 改进策略: 持续改进策略
- 可解释性: 推理过程可解释安装与配置
1. 环境准备
系统要求:
最低要求:
- 操作系统: Linux (推荐Ubuntu)
- Python版本: Python 3.8+
- 内存: 32GB RAM
- 存储: 100GB+ SSD
- GPU: NVIDIA GPU (8GB+ VRAM)
推荐要求:
- 操作系统: Ubuntu 20.04+
- Python版本: Python 3.9+
- 内存: 64GB+ RAM
- 存储: 500GB+ NVMe SSD
- GPU: 多GPU系统 (A100/H100)
生产要求:
- 计算集群: 多节点计算集群
- 高速网络: InfiniBand/RoCE
- 存储系统: 高性能并行文件系统
- 调度系统: Slurm/Kubernetes
- 监控系统: 全面监控体系
软件依赖:
- CUDA: 11.8+
- cuDNN: 8.6+
- PyTorch: 2.0+
- MPI: OpenMPI
- Docker: 容器化支持硬件要求:
GPU要求:
- 架构: Ampere+(A100/H100推荐)
- 显存: 单卡8GB+ (40GB+推荐)
- 数量: 单机多卡或多机多卡
- 互联: NVLink/NVSwitch(推荐)
CPU要求:
- 核心数: 16核心+
- 内存带宽: 高带宽架构
- PCIe: PCIe 4.0+
网络要求:
- 节点间: 高速RDMA网络
- 延迟: 低延迟要求
- 带宽: 高带宽支持
存储要求:
- 类型: 高速SSD/NVMe
- 容量: TB级存储空间
- IOPS: 高IOPS性能2. 安装步骤
基础安装:
# 1. 克隆仓库
git clone https://github.com/RLinf/RLinf.git
cd RLinf
# 2. 创建conda环境
conda create -n rlinf python=3.9
conda activate rlinf
# 3. 安装核心依赖
pip install -e .
# 4. 安装可选组件
pip install -e ".[vla]" # VLA训练支持
pip install -e ".[math]" # 数学推理支持
pip install -e ".[dev]" # 开发工具
# 5. 验证安装
python -c "import rlinf; print('RLinf installed successfully')"Docker安装:
# 1. 构建Docker镜像
docker build -t rlinf:latest .
# 2. 运行开发环境
docker run -it --gpus all --network host rlinf:latest bash
# 3. 或使用docker-compose
docker-compose up -d
# 4. 验证环境
python -m rlinf.utils.check_install集群安装:
# 1. 配置SSH免密登录
ssh-copy-id user@manager-node
ssh-copy-id user@worker-node-1
# 2. 配置NFS共享存储
# 在所有节点挂载共享目录
# 3. 安装MPI集群支持
conda install -c conda-forge openmpi
# 4. 配置集群环境变量
export RLINF_CLUSTER_MODE=true
export RLINF_MANAGER_NODE=manager-ip
# 5. 启动集群服务
rlinf-cluster start开发环境安装:
# 1. 克隆开发分支
git clone -b dev https://github.com/RLinf/RLinf.git
cd RLinf
# 2. 安装开发依赖
pip install -e ".[dev,test]"
# 3. 安装预提交钩子
pre-commit install
# 4. 运行测试套件
pytest tests/ -v
# 5. 构建文档
cd docs && make html验证安装:
# 检查基础环境
python -c "import torch; print(f'PyTorch: {torch.__version__}')"
python -c "import torch; print(f'CUDA: {torch.cuda.is_available()}')"
# 检查RLinf核心功能
python -c "
import rlinf
print('RLinf version:', rlinf.__version__)
from rlinf.runners import create_runner
print('Basic components imported successfully')
"
# 检查GPU环境
nvidia-smi
python -c "
import torch
print(f'GPU count: {torch.cuda.device_count()}')
print(f'Current GPU: {torch.cuda.current_device()}')
"3. 配置说明
基础配置示例:
# configs/basic_config.yaml
system:
mode: "collocated" # collocated | disaggregated | hybrid
num_gpus: 4
auto_schedule: true
training:
algorithm: "PPO"
total_steps: 1000000
batch_size: 1024
learning_rate: 1e-4
model:
type: "transformer"
hidden_size: 2048
num_layers: 24
num_heads: 32
environment:
name: "ManiSkill3"
task: "PutOnPlateInScene25Mani-v3"
max_steps: 500高级训练配置:
# configs/advanced_config.yaml
execution:
mode: "hybrid"
pipeline_stages: 4
micro_batch_size: 32
gradient_accumulation: 8
resources:
gpu_memory_limit: "80%"
cpu_cores: 16
memory_limit: "32GB"
auto_scaling: true
optimization:
mixed_precision: "bf16"
gradient_clipping: 1.0
activation_checkpointing: true
tensor_parallelism: 2
monitoring:
wandb_enabled: true
metrics_frequency: 100
checkpoint_frequency: 1000
log_level: "INFO"集群配置:
# configs/cluster_config.yaml
cluster:
name: "rlinf-cluster"
manager_node: "192.168.1.100"
worker_nodes:
- "192.168.1.101"
- "192.168.1.102"
- "192.168.1.103"
network:
backend: "nccl"
interface: "eth0"
timeout: 300
storage:
type: "nfs"
mount_point: "/rlinf_data"
checkpoint_dir: "/rlinf_data/checkpoints"
scheduling:
resource_manager: "slurm"
partition: "rlinf"
time_limit: "24:00:00"使用指南
1. 基本工作流
使用RLinf的基本流程包括:环境准备 → 安装框架 → 配置训练 → 准备数据 → 启动训练 → 监控进度 → 评估结果 → 模型导出 → 部署应用 → 持续优化 → 成果分享。
2. 基本使用
命令行使用:
基本命令:
- 训练启动: rlinf train configs/basic_config.yaml
- 恢复训练: rlinf resume /path/to/checkpoint
- 评估模型: rlinf eval model_path --env task_name
- 导出模型: rlinf export model_path --format huggingface
- 集群管理: rlinf cluster [start|stop|status]
训练控制:
- 监控训练: tail -f logs/training.log
- 暂停训练: rlinf pause job_id
- 继续训练: rlinf resume job_id
- 停止训练: rlinf stop job_id
- 状态检查: rlinf status job_id
实用工具:
- 环境检查: rlinf check-env
- 基准测试: rlinf benchmark --mode throughput
- 性能分析: rlinf profile config_file
- 配置验证: rlinf validate-config config_filePython API使用:
使用步骤:
1. 导入框架: import rlinf
2. 创建运行器: runner = create_runner(config)
3. 配置训练: runner.setup_training()
4. 启动训练: runner.train()
5. 监控进度: 通过回调监控
高级用法:
- 自定义算法: 继承BaseAlgorithm
- 自定义环境: 实现Env接口
- 自定义模型: 继承BaseModel
- 自定义回调: 实现Callback接口
- 分布式训练: 使用分布式运行器
API特性:
- 类型安全: 完整类型注解
- 文档完善: 完整API文档
- 示例丰富: 丰富使用示例
- 错误处理: 完善错误处理
- 性能优化: 高性能实现配置管理使用:
配置层次:
- 系统配置: 硬件和系统配置
- 训练配置: 训练参数配置
- 模型配置: 模型架构配置
- 环境配置: 训练环境配置
- 优化配置: 优化策略配置
配置技巧:
- 模板使用: 使用配置模板
- 继承机制: 配置继承重用
- 环境变量: 环境变量覆盖
- 命令行参数: 命令行参数覆盖
- 验证检查: 配置验证检查
最佳实践:
- 版本控制: 配置版本控制
- 文档注释: 配置文档注释
- 参数搜索: 自动化参数搜索
- 配置比较: 多配置比较分析
- 生产配置: 生产环境配置3. 高级用法
自定义算法开发:
开发步骤:
1. 算法设计: 设计算法逻辑
2. 接口实现: 实现算法接口
3. 测试验证: 单元测试验证
4. 性能优化: 算法性能优化
5. 集成测试: 系统集成测试
算法接口:
- 初始化: __init__方法
- 策略计算: compute_policy方法
- 损失计算: compute_loss方法
- 更新策略: update_policy方法
- 评估方法: evaluate方法
开发工具:
- 调试支持: 完整调试支持
- 性能分析: 性能分析工具
- 测试框架: 自动化测试框架
- 代码检查: 代码质量检查
- 文档生成: 自动文档生成具身智能训练:
训练流程:
1. 环境配置: 配置仿真环境
2. 模型选择: 选择VLA模型
3. 算法配置: 配置RL算法
4. 训练启动: 启动训练过程
5. 评估调优: 评估和调优
环境集成:
- ManiSkill3: 机器人技能环境
- LIBERO: 开放基准环境
- 自定义环境: 用户自定义环境
- 多环境支持: 多环境并行训练
- 真实世界: 真实世界部署
训练策略:
- 课程学习: 渐进式难度训练
- 模仿学习: 专家示范学习
- 多任务学习: 多任务联合训练
- 元学习: 元强化学习
- 迁移学习: 跨任务迁移学习数学推理训练:
训练方法:
1. 数据准备: 准备数学推理数据
2. 模型初始化: 初始化推理模型
3. 奖励设计: 设计推理奖励函数
4. 训练优化: 优化训练过程
5. 评估分析: 全面评估分析
数据策略:
- 问题增强: 数学问题增强
- 步骤奖励: 分步骤奖励设计
- 错误分析: 错误模式分析
- 难度分级: 难度分级训练
- 多领域: 多数学领域训练
评估体系:
- 自动评估: 自动化评估流程
- 人工评估: 人工质量评估
- 错误分析: 详细错误分析
- 对比实验: 多模型对比
- 消融实验: 组件消融研究应用场景实例
案例1:机器人技能学习
场景:机器人操作技能训练
解决方案:使用RLinf训练VLA模型掌握复杂操作技能。
实施方法:
-
环境配置:配置ManiSkill3仿真环境
-
模型选择:选择OpenVLA或自定义VLA模型
-
训练策略:采用PPO算法进行策略优化
-
课程学习:从简单到复杂的课程设置
-
评估调优:在真实任务上评估调优
应用价值:
-
技能掌握:掌握复杂操作技能
-
泛化能力:强大的泛化能力
-
效率提升:训练效率大幅提升
-
成本降低:降低真实机器人训练成本
-
安全性:仿真环境确保安全
案例2:数学推理助手
场景:数学问题求解助手
解决方案:使用RLinf训练数学推理模型。
实施方法:
-
数据收集:收集AIME、GPQA等数学数据
-
奖励设计:设计步骤正确的奖励函数
-
模型训练:使用PPO优化推理策略
-
错误分析:分析推理错误模式
-
持续优化:基于反馈持续优化
教育价值:
-
解题能力:提升复杂问题求解能力
-
教学辅助:数学教学辅助工具
-
个性化:个性化学习路径
-
效率提升:学习效率提升
-
兴趣激发:激发数学学习兴趣
案例3:工业自动化智能体
场景:工业自动化流程优化
解决方案:使用RLinf训练工业自动化智能体。
实施方法:
-
环境建模:建立工业流程仿真环境
-
目标定义:定义优化目标和约束
-
策略学习:学习最优控制策略
-
安全验证:严格的安全验证流程
-
部署应用:实际工业环境部署
工业价值:
-
流程优化:工业生产流程优化
-
质量控制:产品质量控制优化
-
成本降低:运营成本降低
-
效率提升:生产效率提升
-
智能化:生产流程智能化
案例4:游戏AI智能体
场景:复杂游戏AI训练
解决方案:使用RLinf训练游戏AI智能体。
实施方法:
-
游戏环境:集成游戏仿真环境
-
多智能体:支持多智能体训练
-
分层策略:分层决策策略学习
-
课程训练:渐进式难度训练
-
对战优化:与人类玩家对战优化
游戏价值:
-
AI水平:提升游戏AI水平
-
测试验证:游戏平衡性测试
-
玩家体验:改善玩家游戏体验
-
新技术:游戏AI新技术验证
-
电竞训练:电竞选手训练对手
案例5:科学研究助手
场景:科学研究辅助工具
解决方案:使用RLinf训练科学研究助手。
实施方法:
-
科学问题:定义科学研究问题
-
假设生成:自动生成科学假设
-
实验设计:优化实验设计方案
-
数据分析:科学数据分析辅助
-
论文写作:科研论文写作辅助
科研价值:
-
创新加速:科学研究创新加速
-
假设生成:自动生成研究假设
-
实验优化:实验设计优化
-
数据分析:大数据分析能力
-
跨学科:促进跨学科研究
总结
RLinf作为一个创新的强化学习基础设施,通过其M2Flow架构、灵活的执行模式和高效的训练优化,为大模型强化学习训练提供了强大的支持。
核心优势:
-
🏗️ 架构创新:宏微流转换架构
-
⚡ 训练高效:120%+吞吐量提升
-
🔧 模式灵活:多种执行模式支持
-
🤖 智能体强:强大智能体训练能力
-
📊 性能领先:多项任务SOTA性能
适用场景:
-
机器人技能学习
-
数学推理助手
-
工业自动化智能体
-
游戏AI训练
-
科学研究助手
立即开始使用:
# 快速安装
git clone https://github.com/RLinf/RLinf.git
cd RLinf
pip install -e .
rlinf train configs/basic_config.yaml资源链接:
-
🌐 项目地址:GitHub仓库
-
📖 文档:完整技术文档
-
📄 论文:研究论文详情
-
💬 社区:技术交流社区
-
🎓 教程:使用教程指南
通过RLinf,您可以:
-
高效训练:大幅提升训练效率
-
灵活配置:灵活配置训练流程
-
先进技术:使用最先进技术
-
社区支持:活跃社区支持
-
完全开源:完全开源免费使用
特别提示:
-
💻 硬件要求:需要充足计算资源
-
📚 学习曲线:需要学习时间
-
🔧 技术基础:需要RL技术基础
-
🏗️ 架构理解:理解M2Flow架构
-
👥 社区参与:积极参与社区
通过RLinf,开启智能体AI新篇章!
未来发展:
-
🚀 更多功能:持续功能增强
-
🤖 更好支持:更好智能体支持
-
🌐 更多集成:更多框架集成
-
🔧 更易使用:更友好用户体验
-
📊 更强性能:更强性能表现
加入社区:
参与方式:
- GitHub: 提交问题和PR
- 论文引用: 引用研究论文
- 案例分享: 分享使用案例
- 问题反馈: 反馈使用问题
- 功能建议: 提出功能建议
社区价值:
- 技术交流支持
- 问题解答帮助
- 经验分享交流
- 项目发展推动
- 学术合作机会通过RLinf,共同推动强化学习发展!
许可证:开源许可证,研究友好
致谢:感谢所有贡献机构和研究人员
免责声明:注意AI伦理和安全问题
通过RLinf,负责任地进行AI研究!
成功案例:
应用成果:
- 机器人技能: 复杂操作技能掌握
- 数学推理: 多项基准SOTA性能
- 工业应用: 实际工业场景应用
- 研究成果: 顶级会议论文发表
- 技术突破: 多项技术突破
用户反馈:
- 效率提升: 训练效率大幅提升
- 易于使用: 相对易于使用
- 功能强大: 功能丰富强大
- 性能优秀: 性能表现优秀
- 社区活跃: 活跃开发社区最佳实践:
使用建议:
1. 从简单开始: 从简单配置开始
2. 理解架构: 深入理解M2Flow
3. 资源规划: 合理规划计算资源
4. 监控调优: 密切监控和调优
5. 社区学习: 向社区学习经验
避免问题:
- 资源不足: 避免资源不足
- 配置错误: 仔细检查配置
- 数据质量: 确保数据质量
- 超参数: 合理设置超参数
- 版本兼容: 注意版本兼容通过RLinf,实现高效的强化学习训练!
资源扩展:
学习资源:
- 强化学习理论基础
- 大模型技术学习
- 分布式系统知识
- 机器人学基础
- 数学推理技术通过RLinf,构建您的智能体AI未来!
未来展望:
技术路线:
- 异构GPU支持
- 异步流水线执行
- MoE专家混合
- vLLM推理后端
- 更多模型支持
应用扩展:
- 视觉语言模型训练
- 深度搜索智能体
- 多智能体训练
- 世界模型支持
- 真实世界RL通过RLinf,迎接智能体AI的未来!
结束语:
RLinf作为一个创新的强化学习基础设施,正在改变大模型强化学习训练的方式。通过其创新的架构设计和高效的训练能力,为智能体AI的发展提供了强大的基础设施支持。
记住,基础设施是扩展能力的手段,结合清晰的科研目标与合理的技术选择,共同成就智能体AI卓越。
Happy training with RLinf! 🤖🚀🧠
附录:常见问题解答
Q: RLinf适合哪些类型的用户?
A: RLinf主要适合以下用户群体:
-
研究人员:进行强化学习和大模型研究
-
工程师:开发智能体AI应用
-
学生:学习和研究强化学习技术
-
企业团队:工业应用和技术验证
-
教育机构:教学和课程开发
Q: 需要多少计算资源才能使用?
A: 资源需求根据任务规模而定:
-
小型实验:单GPU(8GB+显存),32GB内存
-
中等规模:多GPU(4-8卡),64GB+内存
-
大规模训练:多机多卡,TB级内存
-
生产部署:计算集群,高速网络
-
原型验证:可从小规模开始逐步扩展
Q: 支持哪些类型的强化学习算法?
A: 目前主要支持:
-
PPO:近端策略优化算法
-
GRPO:指导性策略优化算法
-
自定义算法:用户可扩展新算法
-
多智能体算法:多智能体场景支持
-
分层RL:分层强化学习算法
Q: 如何扩展新的环境?
A: 环境扩展方法:
-
接口实现:实现标准RL环境接口
-
配置集成:在配置文件中添加环境配置
-
测试验证:进行功能和性能测试
-
文档更新:更新相关使用文档
-
社区贡献:向社区贡献新环境
Q: 如何处理大规模数据?
A: 大规模数据处理方案:
-
分布式存储:支持分布式文件系统
-
数据并行:多节点数据并行处理
-
流式处理:支持流式数据加载
-
内存优化:智能内存管理机制
-
缓存策略:多级缓存优化策略
Q: 是否支持多模态输入?
A: 多模态支持情况:
-
视觉输入:支持图像和视频输入
-
语言输入:支持文本和语音输入
-
动作输出:支持连续和离散动作
-
传感器数据:支持各种传感器输入
-
自定义模态:可扩展新模态支持
Q: 如何保证训练稳定性?
A: 稳定性保障措施:
-
梯度裁剪:防止梯度爆炸
-
学习率调度:自适应学习率调整
-
检查点保存:定期保存训练状态
-
容错机制:自动错误恢复机制
-
监控告警:实时监控和告警系统
Q: 如何贡献代码和功能?
A: 贡献流程:
-
Fork仓库:Fork项目到个人账户
-
开发分支:创建功能开发分支
-
代码规范:遵循项目代码规范
-
测试覆盖:编写单元测试
-
文档更新:更新相关文档
-
提交PR:提交Pull Request
-
代码审查:参与代码审查
-
合并发布:通过后合并发布
Q: 商业使用有哪些限制?
A: 商业使用考虑:
-
开源协议:友好的开源许可证
-
组件许可:注意第三方组件许可
-
数据合规:确保数据使用合规
-
服务条款:遵守云服务条款
-
知识产权:注意知识产权保护
Q: 如何获取技术支持?
A: 技术支持渠道:
-
GitHub Issues:提交技术问题
-
官方文档:查阅详细文档
-
社区群组:加入技术交流群
-
示例代码:参考示例代码
-
邮件列表:订阅开发邮件
通过合理使用RLinf框架,您可以高效地进行大模型强化学习训练,享受先进基础设施带来的便利和效率。无论是学术研究还是工业应用,RLinf都能为您提供强大的技术支持。
开始您的智能体AI之旅吧! 🎯✨


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









