







一、段合并过程总论
IndexWriter中与段合并有关的成员变量有:
- HashSet<SegmentInfo> mergingSegments = new HashSet<SegmentInfo>(); //保存正在合并的段,以防止合并期间再次选中被合并。
- MergePolicy mergePolicy = new LogByteSizeMergePolicy(this);//合并策略,也即选取哪些段来进行合并。
- MergeScheduler mergeScheduler = new ConcurrentMergeScheduler();//段合并器,背后有一个线程负责合并。
- LinkedList<MergePolicy.OneMerge> pendingMerges = new LinkedList<MergePolicy.OneMerge>();//等待被合并的任务
- Set<MergePolicy.OneMerge> runningMerges = new HashSet<MergePolicy.OneMerge>();//正在被合并的任务
和段合并有关的一些参数有:
- mergeFactor:当大小几乎相当的段的数量达到此值的时候,开始合并。
- minMergeSize:所有大小小于此值的段,都被认为是大小几乎相当,一同参与合并。
- maxMergeSize:当一个段的大小大于此值的时候,就不再参与合并。
- maxMergeDocs:当一个段包含的文档数大于此值的时候,就不再参与合并。
段合并一般发生在添加完一篇文档的时候,当一篇文档添加完后,发现内存已经达到用户设定的ramBufferSize,则写入文件系统,形成一个新的段。新段的加入可能造成差不多大小的段的个数达到mergeFactor,从而开始了合并的过程。
合并过程最重要的是两部分:
- 一个是选择哪些段应该参与合并,这一步由MergePolicy来决定。
- 一个是将选择出的段合并成新段的过程,这一步由MergeScheduler来执行。段的合并也主要包括:
- 对正向信息的合并,如存储域,词向量,标准化因子等。
- 对反向信息的合并,如词典,倒排表。
在总论中,我们重点描述合并策略对段的选择以及反向信息的合并。
1.1、合并策略对段的选择
在LogMergePolicy中,选择可以合并的段的基本逻辑是这样的:
- 选择的可以合并的段都是在硬盘上的,不再存在内存中的段,也不是像早期的版本一样每添加一个Document就生成一个段,然后进行内存中的段合并,然后再合并到硬盘中。
- 由于从内存中flush到硬盘上是按照设置的内存大小来DocumentsWriter.ramBufferSize触发的,所以每个刚flush到硬盘上的段大小差不多,当然不排除中途改变内存设置,接下来的算法可以解决这个问题。
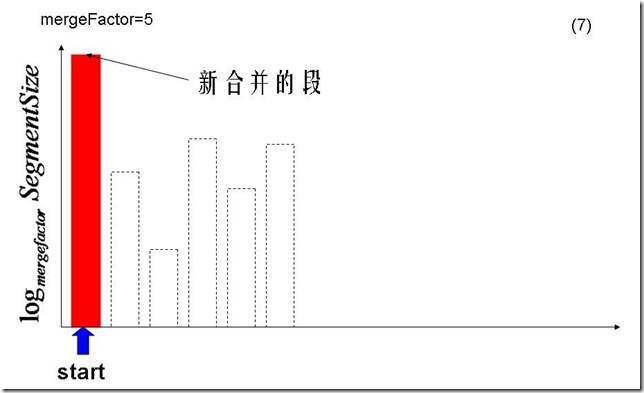
- 合并的过程是尽量按照合并几乎相同大小的段这一原则,只有大小相当的mergeFacetor个段出现的时候,才合并成一个新的段。
- 在硬盘上的段基本应该是大段在前,小段在后,因为大段总是由小段合并而成的,当小段凑够mergeFactor个的时候,就合并成一个大段,小段就被删除了,然后新来的一定是新的小段。
- 比如mergeFactor=3,开始来的段大小为10M,当凑够3个10M的时候,0.cfs, 1.cfs, 2.cfs则合并成一个新的段3.cfs,大小为30M,然后再来4.cfs, 5.cfs, 6.cfs,合并成7.cfs,大小为30M,然后再来8.cfs, 9.cfs, a.cfs合并成b.cfs, 大小为30M,这时候又凑够了3个30M的,合并成90M的c.cfs,然后又来d.cfs, e.cfs, f.cfs合并成10.cfs,大小为30M,然后11.cfs大小为10M,这时候硬盘上的段为:c.cfs(90M) 10.cfs(30M),11.cfs(10M)。
所以LogMergePolicy对合并段的选择过程如下:
- 将所有的段按照生成的顺序,将段的大小以mergeFactor为底取对数,放入数组中,作为选择的标准。

- 从头开始,选择一个值最大的段,然后将此段的值减去0.75(LEVEL_LOG_SPAN) ,之间的段被认为是大小差不多的段,属于同一阶梯,此处称为第一阶梯。
- 然后从后向前寻找第一个属于第一阶梯的段,从start到此段之间的段都被认为是属于这一阶梯的。也包括之间生成较早但大小较小的段,因为考虑到以下几点:
- 防止较早生成的段由于人工flush或者人工调整ramBufferSize,因而很小,却破坏了基本从大到小的规则。
- 如果运行较长时间后,致使段的大小参差不齐,很难合并相同大小的段。
- 也防止一个段由于较小,而不断的都有大的段生成从而始终不能参与合并。
- 第一阶梯总共4个段,小于mergeFactor因而不合并,接着start=end从而选择下一阶梯。

- 从start开始,选择一个值最大的段,然后将此段的值减去0.75(LEVEL_LOG_SPAN) ,之间的段被认为属于同一阶梯,此处称为第二阶梯。
- 然后从后向前寻找第一个属于第二阶梯的段,从start到此段之间的段都被认为是属于这一阶梯的。
- 第二阶梯总共4个段,小于mergeFactor因而不合并,接着start=end从而选择下一阶梯。

- 从start开始,选择一个值最大的段,然后将此段的值减去0.75(LEVEL_LOG_SPAN) ,之间的段被认为属于同一阶梯,此处称为第三阶梯。
- 由于最大的段减去0.75后为负的,因而从start到此段之间的段都被认为是属于这一阶梯的。
- 第三阶梯总共5个段,等于mergeFactor,因而进行合并。

- 第三阶梯的五个段合并成一个较大的段。
- 然后从头开始,依然先考察第一阶梯,仍然是4个段,不合并。
- 然后是第二阶梯,因为有了新生成的段,并且大小足够属于第二阶梯,从而第二阶梯有5个段,可以合并。

- 第二阶段的五个段合并成一个较大的段。
- 然后从头开始,考察第一阶梯,因为有了新生成的段,并且大小足够属于第一阶梯,从而第一阶梯有5个段,可以合并。

- 第一阶梯的五个段合并成一个大的段。
1.2、反向信息的合并
反向信息的合并包括两部分:
- 对字典的合并,词典中的Term是按照字典顺序排序的,需要对词典中的Term进行重新排序
- 对于相同的Term,对包含此Term的文档号列表进行合并,需要对文档号重新编号。
对词典的合并需要找出两个段中相同的词,Lucene是通过一个称为match的SegmentMergeInfo类型的数组以及称为queue的 SegmentMergeQueue实现的,SegmentMergeQueue是继承于 PriorityQueue<SegmentMergeInfo>,是一个优先级队列,是按照字典顺序排序的。 SegmentMergeInfo保存要合并的段的词典及倒排表信息,在SegmentMergeQueue中用来排序的key是它代表的段中的第一个 Term。
我们来举一个例子来说明合并词典的过程,以便后面解析代码的时候能够很好的理解:
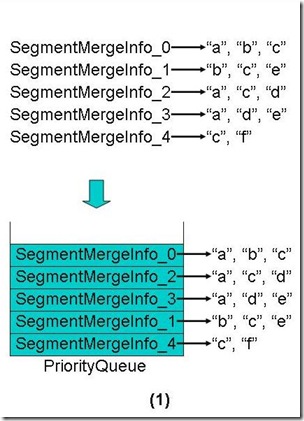
- 假设要合并五个段,每个段包含的Term也是按照字典顺序排序的,如下图所示。
- 首先把五个段全部放入优先级队列中,段在其中也是按照第一个Term的字典顺序排序的,如下图。
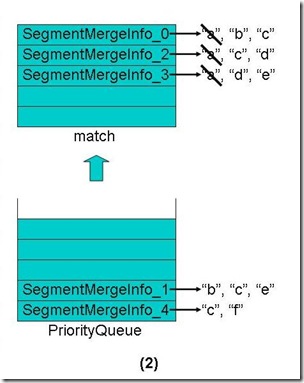
- 从优先级队列中弹出第一个Term("a")相同的段到match数组中,如下图。
- 合并这些段的第一个Term("a")的倒排表,并把此Term和它的倒排表一同加入新生成的段中。
- 对于match数组中的每个段取下一个Term
- 将match数组中还有Term的段重新放入优先级队列中,这些段也是按照第一个Term的字典顺序排序。
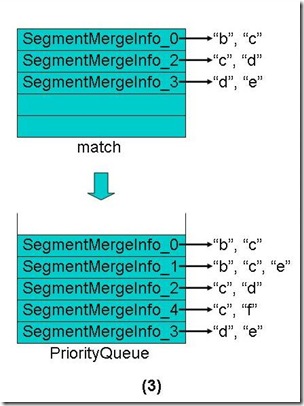
- 从优先级队列中弹出第一个Term("b")相同的段到match数组中。
- 合并这些段的第一个Term("b")的倒排表,并把此Term和它的倒排表一同加入新生成的段中。
- 对于match数组中的每个段取下一个Term
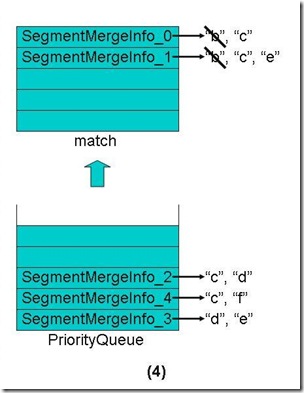
- 将match数组中还有Term的段重新放入优先级队列中,这些段也是按照第一个Term的字典顺序排序。

- 从优先级队列中弹出第一个Term("c")相同的段到match数组中。
- 合并这些段的第一个Term("c")的倒排表,并把此Term和它的倒排表一同加入新生成的段中。
- 对于match数组中的每个段取下一个Term

- 将match数组中还有Term的段重新放入优先级队列中,这些段也是按照第一个Term的字典顺序排序。

- 从优先级队列中弹出第一个Term("d")相同的段到match数组中。
- 合并这些段的第一个Term("d")的倒排表,并把此Term和它的倒排表一同加入新生成的段中。
- 对于match数组中的每个段取下一个Term

- 将match数组中还有Term的段重新放入优先级队列中,这些段也是按照第一个Term的字典顺序排序。
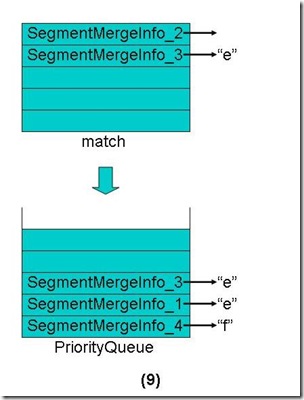
- 从优先级队列中弹出第一个Term("e")相同的段到match数组中。
- 合并这些段的第一个Term("e")的倒排表,并把此Term和它的倒排表一同加入新生成的段中。
- 对于match数组中的每个段取下一个Term

- 将match数组中还有Term的段重新放入优先级队列中,这些段也是按照第一个Term的字典顺序排序。

- 从优先级队列中弹出第一个Term("f")相同的段到match数组中。
- 合并这些段的第一个Term("f")的倒排表,并把此Term和它的倒排表一同加入新生成的段中。
- 对于match数组中的每个段取下一个Term
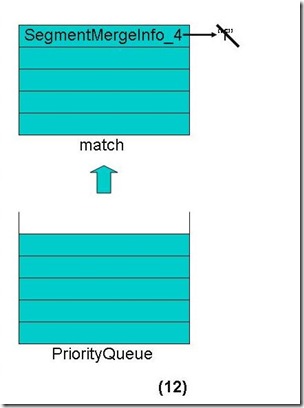
- 合并完毕。
二、段合并的详细过程
2.1、将缓存写入新的段
IndexWriter在添加文档的时候调用函数addDocument(Document doc, Analyzer analyzer),包含如下步骤:
- doFlush = docWriter.addDocument(doc, analyzer);//DocumentsWriter添加文档,最后返回是否进行向硬盘写入
- return state.doFlushAfter || timeToFlushDeletes();//这取决于timeToFlushDeletes
timeToFlushDeletes返回return (bufferIsFull || deletesFull()) && setFlushPending(),而在Lucene索引过程分析(2)的DocumentsWriter的缓存管理部分提到,当numBytesUsed+deletesRAMUsed > ramBufferSize的时候bufferIsFull设为true,也即当使用的内存大于ramBufferSize的时候,则由内存向硬盘写入。ramBufferSize可以用IndexWriter.setRAMBufferSizeMB(double mb)设定。
- if (doFlush) flush(true, false, false);//如果内存中缓存满了,则写入硬盘
- if (doFlush(flushDocStores, flushDeletes) && triggerMerge) maybeMerge();//doFlush将缓存写入硬盘,此过程在Lucene索引过程分析(4)中关闭IndexWriter一节已经描述。
当缓存写入硬盘,形成了新的段后,就有可能触发一次段合并,所以调用maybeMerge()
| IndexWriter.maybeMerge() --> maybeMerge(false); --> maybeMerge(1, optimize); --> updatePendingMerges(maxNumSegmentsOptimize, optimize); --> mergeScheduler.merge(this); |
IndexWriter.updatePendingMerges(int maxNumSegmentsOptimize, boolean optimize)主要负责找到可以合并的段,并生产段合并任务对象,并向段合并器注册这个任务。
ConcurrentMergeScheduler.merge(IndexWriter)主要负责进行段的合并。
2.2、选择合并段,生成合并任务
IndexWriter.updatePendingMerges(int maxNumSegmentsOptimize, boolean optimize)主要包括两部分:
- 选择能够合并段:MergePolicy.MergeSpecification spec = mergePolicy.findMerges(segmentInfos);
- 向段合并器注册合并任务,将任务加到pendingMerges中:
- for(int i=0;i<spec.merges.size();i++)
- registerMerge(spec.merges.get(i));
- for(int i=0;i<spec.merges.size();i++)
2.2.1、用合并策略选择合并段
默认的段合并策略是LogByteSizeMergePolicy,其选择合并段由LogMergePolicy.findMerges(SegmentInfos infos) 完成,包含以下过程:
(1) 生成levels数组,每个段一项。然后根据每个段的大小,计算每个项的值,levels[i]和段的大小的关系为Math.log(size)/Math.log(mergeFactor),代码如下:
| final int numSegments = infos.size(); float[] levels = new float[numSegments]; final float norm = (float) Math.log(mergeFactor); for(int i=0;i<numSegments;i++) { final SegmentInfo info = infos.info(i); long size = size(info); levels[i] = (float) Math.log(size)/norm; } |
(2) 由于段基本是按照由大到小排列的,而且合并段应该大小差不多的段中进行。我们把大小差不多的段称为属于同一阶梯,因而此处从第一个段开始找属于相同阶梯的段,如果属于此阶梯的段数量达到mergeFactor个,则生成合并任务,否则继续向后寻找下一阶梯。
| //计算最低阶梯值,所有小于此值的都属于最低阶梯 final float levelFloor = (float) (Math.log(minMergeSize)/norm); MergeSpecification spec = null; int start = 0; while(start < numSegments) { //找到levels数组的最大值,也即当前阶梯中的峰值 float maxLevel = levels[start]; for(int i=1+start;i<numSegments;i++) { final float level = levels[i]; if (level > maxLevel) maxLevel = level; } //计算出此阶梯的谷值,也即最大值减去0.75,之间的都属于此阶梯。如果峰值小于最低阶梯值,则所有此阶梯的段都属于最低阶梯。如果峰值大于最低阶梯值,谷值小于最低阶梯值,则设置谷值为最低阶梯值,以保证所有小于最低阶梯值的段都属于最低阶梯。 float levelBottom; if (maxLevel < levelFloor) levelBottom = -1.0F; else { levelBottom = (float) (maxLevel - LEVEL_LOG_SPAN); if (levelBottom < levelFloor && maxLevel >= levelFloor) levelBottom = levelFloor; } float levelBottom = (float) (maxLevel - LEVEL_LOG_SPAN); //从最后一个段向左找,当然段越来越大,找到第一个大于此阶梯的谷值的段,从start的段开始,一直到upto这个段,都属于此阶梯了。尽管upto 左面也有的段由于内存设置原因,虽形成较早,但是没有足够大,也作为可合并的一员考虑在内了,将被并入一个大的段,从而保证了基本上左大右小的关系。从 upto这个段向右都是比此阶梯小的多的段,应该属于下一阶梯。 int upto = numSegments-1; while(upto >= start) { if (levels[upto] >= levelBottom) { break; } upto--; } //从start段开始,数mergeFactor个段,如果不超过upto段,说明此阶梯已经足够mergeFactor个了,可以合 并了。当然如果此阶梯包含太多要合并的段,也是每mergeFactor个段进行一次合并,然后再依次数mergeFactor段进行合并,直到此阶梯的 段合并完毕。 int end = start + mergeFactor; while(end <= 1+upto) { boolean anyTooLarge = false; for(int i=start;i<end;i++) { final SegmentInfo info = infos.info(i); //如果一个段的大小超过maxMergeSize或者一个段包含的文档数量超过maxMergeDocs则不再合并。 anyTooLarge |= (size(info) >= maxMergeSize || sizeDocs(info) >= maxMergeDocs); } if (!anyTooLarge) { if (spec == null) spec = new MergeSpecification(); //如果确认要合并,则从start到end生成一个段合并任务OneMerge. spec.add(new OneMerge(infos.range(start, end), useCompoundFile)); } //刚刚合并的是从start到end共mergeFactor和段,此阶梯还有更多的段,则再依次数mergeFactor个段。 start = end; end = start + mergeFactor; } //从start到upto是此阶梯的所有的段,已经选择完毕,下面选择更小的下一个阶梯的段 start = 1+upto; } |
选择的结果保存在MergeSpecification中,结构如下:
| spec MergePolicy$MergeSpecification (id=25) |
2.2.2、注册段合并任务
注册段合并任务由IndexWriter.registerMerge(MergePolicy.OneMerge merge)完成:
(1) 如果选择出的段正在被合并,或者不存在,则退出。
| final int count = merge.segments.size(); boolean isExternal = false; for(int i=0;i<count;i++) { final SegmentInfo info = merge.segments.info(i); if (mergingSegments.contains(info)) return false; if (segmentInfos.indexOf(info) == -1) return false; if (info.dir != directory) isExternal = true; } |
(2) 将合并任务加入pendingMerges:pendingMerges.add(merge);
(3) 将要合并的段放入mergingSegments以防正在合并又被选为合并段。
| for(int i=0;i<count;i++) |
2.3、段合并器进行段合并
段合并器默认为ConcurrentMergeScheduler,段的合并工作由ConcurrentMergeScheduler.merge(IndexWriter) 完成,它包含while(true)的循环,在循环中不断做以下事情:
- 得到下一个合并任务:MergePolicy.OneMerge merge = writer.getNextMerge();
- 初始化合并任务:writer.mergeInit(merge);
- 将删除文档写入硬盘:applyDeletes();
- 是否合并存储域:mergeDocStores = false。按照Lucene的索引文件格式(2)中段的元数据信息(segments_N)中提到 的,IndexWriter.flush(boolean triggerMerge, boolean flushDocStores, boolean flushDeletes)中第二个参数flushDocStores会影响到是否单独或是共享存储。其实最终影响的是 DocumentsWriter.closeDocStore()。每当flushDocStores为false时,closeDocStore不被调 用,说明下次添加到索引文件中的域和词向量信息是同此次共享一个段的。直到flushDocStores为true的时候,closeDocStore被 调用,从而下次添加到索引文件中的域和词向量信息将被保存在一个新的段中,不同此次共享一个段。如2.1节中说的那样,在addDocument中,如果 内存中缓存满了,则写入硬盘,调用的是flush(true, false, false),也即所有的存储域都存储在共享的域中(_0.fdt),因而不需要合并存储域。
- 生成新的段:merge.info = new SegmentInfo(newSegmentName(),…)
- 将新的段加入mergingSegments
- 如果已经有足够多的段合并线程,则等待while (mergeThreadCount() >= maxThreadCount) wait();
- 生成新的段合并线程:
- merger = getMergeThread(writer, merge);
- mergeThreads.add(merger);
- 启动段合并线程:merger.start();
段合并线程的类型为MergeThread,MergeThread.run()包含while(truy)循环,在循环中做以下事情:
- 合并当前的任务:doMerge(merge);
- 得到下一个段合并任务:merge = writer.getNextMerge();
ConcurrentMergeScheduler.doMerge(OneMerge) 最终调用IndexWriter.merge(OneMerge) ,主要做以下事情:
- 初始化合并任务:mergeInit(merge);
- 进行合并:mergeMiddle(merge);
- 完成合并任务:mergeFinish(merge);
- 从mergingSegments中移除被合并的段和合并新生成的段:
- for(int i=0;i<end;i++) mergingSegments.remove(sourceSegments.info(i));
- mergingSegments.remove(merge.info);
- 从runningMerges中移除此合并任务:runningMerges.remove(merge);
- 从mergingSegments中移除被合并的段和合并新生成的段:
IndexWriter.mergeMiddle(OneMerge)主要做以下几件事情:
- 生成用于合并段的对象SegmentMerger merger = new SegmentMerger(this, mergedName, merge);
- 打开Reader指向要合并的段:
| merge.readers = new SegmentReader[numSegments]; merge.readersClone = new SegmentReader[numSegments]; for (int i = 0; i < numSegments; i++) { final SegmentInfo info = sourceSegments.info(i); // Hold onto the "live" reader; we will use this to // commit merged deletes SegmentReader reader = merge.readers[i] = readerPool.get(info, merge.mergeDocStores,MERGE_READ_BUFFER_SIZE,-1); // We clone the segment readers because other // deletes may come in while we're merging so we // need readers that will not change SegmentReader clone = merge.readersClone[i] = (SegmentReader) reader.clone(true); merger.add(clone); } |
- 进行段合并:mergedDocCount = merge.info.docCount = merger.merge(merge.mergeDocStores);
- 合并生成的段生成为cfs:merger.createCompoundFile(compoundFileName);
SegmentMerger.merge(boolean) 包含以下几部分:
- 合并域:mergeFields()
- 合并词典和倒排表:mergeTerms();
- 合并标准化因子:mergeNorms();
- 合并词向量:mergeVectors();
下面依次分析者几部分。
2.3.1、合并存储域
合并存储域主要包含两部分:一部分是合并fnm信息,也即域元数据信息,一部分是合并fdt,fdx信息,也即域数据信息。
(1) 合并fnm信息
- 首先生成新的域元数据信息:fieldInfos = new FieldInfos();
- 依次用reader读取每个合并段的域元数据信息,加入上述对象
| for (IndexReader reader : readers) { SegmentReader segmentReader = (SegmentReader) reader; FieldInfos readerFieldInfos = segmentReader.fieldInfos(); int numReaderFieldInfos = readerFieldInfos.size(); for (int j = 0; j < numReaderFieldInfos; j++) { FieldInfo fi = readerFieldInfos.fieldInfo(j); //在通常情况下,所有的段中的文档都包含相同的域,比如添加文档的时候,每篇文档都包 含"title","description","author","time"等,不会为某一篇文档添加或减少与其他文档不同的域。但也不排除特殊情况 下有特殊的文档有特殊的域。因而此处的add是无则添加,有则更新。 fieldInfos.add(fi.name, fi.isIndexed, fi.storeTermVector, fi.storePositionWithTermVector, fi.storeOffsetWithTermVector, !reader.hasNorms(fi.name), fi.storePayloads, fi.omitTermFreqAndPositions); } } |
- 将域元数据信息fnm写入文件:fieldInfos.write(directory, segment + ".fnm");
(2) 合并段数据信息fdt, fdx
在合并段的数据信息的时候,有两种情况:
- 情况一:通常情况,要合并的段和新生成段包含的域的名称,顺序都是一样的,这样就可以把要合并的段的fdt信息直接拷贝到新生成段的最后,以提高合并效率。
- 情况二:要合并的段包含特殊的文档,其包含的域多于或者少于新生成段的域,这样就不能够直接拷贝,而是一篇文档一篇文档的添加。这样合并效率大大降低,因而不鼓励添加文档的时候,不同的文档使用不同的域。
具体过程如下:
- 首先检查要合并的各个段,其包含域的名称,顺序是否同新生成段的一致,也即是否属于第一种情况:setMatchingSegmentReaders();
| private void setMatchingSegmentReaders() { int numReaders = readers.size(); matchingSegmentReaders = new SegmentReader[numReaders]; //遍历所有的要合并的段 for (int i = 0; i < numReaders; i++) { IndexReader reader = readers.get(i); if (reader instanceof SegmentReader) { SegmentReader segmentReader = (SegmentReader) reader; boolean same = true; FieldInfos segmentFieldInfos = segmentReader.fieldInfos(); int numFieldInfos = segmentFieldInfos.size(); //依次比较要合并的段和新生成的段的段名,顺序是否一致。 for (int j = 0; same && j < numFieldInfos; j++) { same = fieldInfos.fieldName(j).equals(segmentFieldInfos.fieldName(j)); } //最后生成matchingSegmentReaders数组,如果此数组的第i项不是null,则说明第i个段同新生成的段名称,顺序完全一致,可以采取情况一得方式。如果此数组的第i项是null,则说明第i个段包含特殊的域,则采取情况二的方式。 if (same) { matchingSegmentReaders[i] = segmentReader; } } } } |
- 生成存储域的写对象:FieldsWriter fieldsWriter = new FieldsWriter(directory, segment, fieldInfos);
- 依次遍历所有的要合并的段,按照上述两种情况,使用不同策略进行合并
| int idx = 0; for (IndexReader reader : readers) { final SegmentReader matchingSegmentReader = matchingSegmentReaders[idx++]; FieldsReader matchingFieldsReader = null; //如果matchingSegmentReader!=null,表示此段属于情况一,得到matchingFieldsReader if (matchingSegmentReader != null) { final FieldsReader fieldsReader = matchingSegmentReader.getFieldsReader(); if (fieldsReader != null && fieldsReader.canReadRawDocs()) { matchingFieldsReader = fieldsReader; } } //根据此段是否包含删除的文档采取不同的策略 if (reader.hasDeletions()) { docCount += copyFieldsWithDeletions(fieldsWriter, reader, matchingFieldsReader); } else { docCount += copyFieldsNoDeletions(fieldsWriter,reader, matchingFieldsReader); } } |
- 合并包含删除文档的段
| private int copyFieldsWithDeletions(final FieldsWriter fieldsWriter, final IndexReader reader, final FieldsReader matchingFieldsReader) throws IOException, MergeAbortedException, CorruptIndexException { int docCount = 0; final int maxDoc = reader.maxDoc(); //matchingFieldsReader!=null,说明此段属于情况一, 则可以直接拷贝。 if (matchingFieldsReader != null) { for (int j = 0; j < maxDoc;) { if (reader.isDeleted(j)) { // 如果文档被删除,则跳过此文档。 ++j; continue; } int start = j, numDocs = 0; do { j++; numDocs++; if (j >= maxDoc) break; if (reader.isDeleted(j)) { j++; break; } } while(numDocs < MAX_RAW_MERGE_DOCS); //从要合并的段中从第start篇文档开始,依次读取numDocs篇文档的文档长度到rawDocLengths中。 IndexInput stream = matchingFieldsReader.rawDocs(rawDocLengths, start, numDocs); //用fieldsStream.copyBytes(…)直接将fdt信息从要合并的段拷贝到新生成的段,然后将上面读出的rawDocLengths转换成为每篇文档在fdt中的偏移量,写入fdx文件。 fieldsWriter.addRawDocuments(stream, rawDocLengths, numDocs); docCount += numDocs; checkAbort.work(300 * numDocs); } } else { //matchingFieldsReader==null,说明此段属于情况二,必须每篇文档依次添加。 for (int j = 0; j < maxDoc; j++) { if (reader.isDeleted(j)) { // 如果文档被删除,则跳过此文档。 continue; } //同addDocument的过程中一样,重新将文档添加一遍。 Document doc = reader.document(j); fieldsWriter.addDocument(doc); docCount++; checkAbort.work(300); } } return docCount; } |
- 合并不包含删除文档的段:除了跳过删除的文档的部分,同上述过程一样。
- 关闭存储域的写对象:fieldsWriter.close();
2.3.2、合并标准化因子
合并标准化因子的过程比较简单,基本就是对每一个域,用指向合并段的reader读出标准化因子,然后再写入新生成的段。
| private void mergeNorms() throws IOException { byte[] normBuffer = null; IndexOutput output = null; try { int numFieldInfos = fieldInfos.size(); //对于每一个域 for (int i = 0; i < numFieldInfos; i++) { FieldInfo fi = fieldInfos.fieldInfo(i); if (fi.isIndexed && !fi.omitNorms) { if (output == null) { //指向新生成的段的nrm文件的写入流 output = directory.createOutput(segment + "." + IndexFileNames.NORMS_EXTENSION); //写nrm文件头 output.writeBytes(NORMS_HEADER,NORMS_HEADER.length); } //对于每一个合并段的reader for ( IndexReader reader : readers) { int maxDoc = reader.maxDoc(); if (normBuffer == null || normBuffer.length < maxDoc) { // the buffer is too small for the current segment normBuffer = new byte[maxDoc]; } //读出此段的nrm信息。 reader.norms(fi.name, normBuffer, 0); if (!reader.hasDeletions()) { //如果没有文档被删除则写入新生成的段。 output.writeBytes(normBuffer, maxDoc); } else { //如果有文档删除则跳过删除的文档写入新生成的段。 for (int k = 0; k < maxDoc; k++) { if (!reader.isDeleted(k)) { output.writeByte(normBuffer[k]); } } } checkAbort.work(maxDoc); } } } } finally { if (output != null) { output.close(); } } } |
2.3.3、合并词向量
合并词向量的过程同合并存储域的过程非常相似,也包括两种情况:
- 情况一:通常情况,要合并的段和新生成段包含的域的名称,顺序都是一样的,这样就可以把要合并的段的词向量信息直接拷贝到新生成段的最后,以提高合并效率。
- 情况二:要合并的段包含特殊的文档,其包含的域多于或者少于新生成段的域,这样就不能够直接拷贝,而是一篇文档一篇文档的添加。这样合并效率大大降低,因而不鼓励添加文档的时候,不同的文档使用不同的域。
具体过程如下:
- 生成词向量的写对象:TermVectorsWriter termVectorsWriter = new TermVectorsWriter(directory, segment, fieldInfos);
- 依次遍历所有的要合并的段,按照上述两种情况,使用不同策略进行合并
| int idx = 0; for (final IndexReader reader : readers) { final SegmentReader matchingSegmentReader = matchingSegmentReaders[idx++]; TermVectorsReader matchingVectorsReader = null; //如果matchingSegmentReader!=null,表示此段属于情况一,得到matchingFieldsReader if (matchingSegmentReader != null) { TermVectorsReader vectorsReader = matchingSegmentReader.getTermVectorsReaderOrig(); if (vectorsReader != null && vectorsReader.canReadRawDocs()) { matchingVectorsReader = vectorsReader; } } //根据此段是否包含删除的文档采取不同的策略 if (reader.hasDeletions()) { copyVectorsWithDeletions(termVectorsWriter, matchingVectorsReader, reader); } else { copyVectorsNoDeletions(termVectorsWriter, matchingVectorsReader, reader); } } |
- 合并包含删除文档的段
| private void copyVectorsWithDeletions(final TermVectorsWriter termVectorsWriter, final TermVectorsReader matchingVectorsReader, final IndexReader reader) throws IOException, MergeAbortedException { final int maxDoc = reader.maxDoc(); //matchingFieldsReader!=null,说明此段属于情况一, 则可以直接拷贝。 if (matchingVectorsReader != null) { for (int docNum = 0; docNum < maxDoc;) { if (reader.isDeleted(docNum)) { // 如果文档被删除,则跳过此文档。 ++docNum; continue; } int start = docNum, numDocs = 0; do { docNum++; numDocs++; if (docNum >= maxDoc) break; if (reader.isDeleted(docNum)) { docNum++; break; } } while(numDocs < MAX_RAW_MERGE_DOCS); //从要合并的段中从第start篇文档开始,依次读取numDocs篇文档的tvd到rawDocLengths中,tvf到rawDocLengths2。 matchingVectorsReader.rawDocs(rawDocLengths, rawDocLengths2, start, numDocs); //用tvd.copyBytes(…)直接将tvd信息从要合并的段拷贝到新生成的段,然后将上面读出的rawDocLengths转 换成为每篇文档在tvd文件中的偏移量,写入tvx文件。用tvf.copyBytes(…)直接将tvf信息从要合并的段拷贝到新生成的段,然后将上面 读出的rawDocLengths2转换成为每篇文档在tvf文件中的偏移量,写入tvx文件。 termVectorsWriter.addRawDocuments(matchingVectorsReader, rawDocLengths, rawDocLengths2, numDocs); checkAbort.work(300 * numDocs); } } else { //matchingFieldsReader==null,说明此段属于情况二,必须每篇文档依次添加。 for (int docNum = 0; docNum < maxDoc; docNum++) { if (reader.isDeleted(docNum)) { // 如果文档被删除,则跳过此文档。 continue; } //同addDocument的过程中一样,重新将文档添加一遍。 TermFreqVector[] vectors = reader.getTermFreqVectors(docNum); termVectorsWriter.addAllDocVectors(vectors); checkAbort.work(300); } } } |
- 合并不包含删除文档的段:除了跳过删除的文档的部分,同上述过程一样。
- 关闭词向量的写对象:termVectorsWriter.close();
2.3.4、合并词典和倒排表
以上都是合并正向信息,相对过程比较清晰。而合并词典和倒排表就不这么简单了,因为在词典中,Lucene要求按照字典顺序排序,在倒排表中,文档号要按照从小到大顺序排序排序,在每个段中,文档号都是从零开始编号的。
所以反向信息的合并包括两部分:
- 对字典的合并,需要对词典中的Term进行重新排序
- 对于相同的Term,对包含此Term的文档号列表进行合并,需要对文档号重新编号。
后者相对简单,假设如果第一个段的编号是0~N,第二个段的编号是0~M,当两个段合并成一个段的时候,第一个段的编号依然是0~N,第二个段的编号变成N~N+M就可以了,也即增加一个偏移量(前一个段的文档个数)。
对词典的合并需要找出两个段中相同的词,Lucene是通过一个称为match的SegmentMergeInfo类型的数组以及称为queue的 SegmentMergeQueue实现的,SegmentMergeQueue是继承于 PriorityQueue<SegmentMergeInfo>,是一个优先级队列,是按照字典顺序排序的。 SegmentMergeInfo保存要合并的段的词典及倒排表信息,在SegmentMergeQueue中用来排序的key是它代表的段中的第一个 Term。
在总论部分,举了一个例子表明词典和倒排表合并的过程。
下面让我们深入代码看一看具体的实现:
(1) 生成优先级队列,并将所有的段都加入优先级队列。
| //在Lucene索引过程分析(4)中提到过,FormatPostingsFieldsConsumer 是用来写入倒排表信息的。 //FormatPostingsFieldsWriter.addField(FieldInfo field)用于添加索引域信息,其返回FormatPostingsTermsConsumer用于添加词信息。 //FormatPostingsTermsConsumer.addTerm(char[] text, int start)用于添加词信息,其返回FormatPostingsDocsConsumer用于添加freq信息 //FormatPostingsDocsConsumer.addDoc(int docID, int termDocFreq)用于添加freq信息,其返回FormatPostingsPositionsConsumer用于添加prox信息 //FormatPostingsPositionsConsumer.addPosition(int position, byte[] payload, int payloadOffset, int payloadLength)用于添加prox信息 FormatPostingsFieldsConsumer consumer = new FormatPostingsFieldsWriter(state, fieldInfos); //优先级队列 queue = new SegmentMergeQueue(readers.size()); //对于每一个段 final int readerCount = readers.size(); for (int i = 0; i < readerCount; i++) { IndexReader reader = readers.get(i); TermEnum termEnum = reader.terms(); //生成SegmentMergeInfo对象,termEnum就是此段的词典及倒排表。 SegmentMergeInfo smi = new SegmentMergeInfo(base, termEnum, reader); //base就是下一个段的文档号偏移量,等于此段的文档数目。 base += reader.numDocs(); if (smi.next()) //得到段的第一个Term queue.add(smi); //将此段放入优先级队列。 else smi.close(); } |
(2) 生成match数组
SegmentMergeInfo[] match = new SegmentMergeInfo[readers.size()];
(3) 合并词典
| //如果队列不为空,则合并尚未结束 while (queue.size() > 0) { int matchSize = 0; //取出优先级队列的第一个段,放到match数组中 match[matchSize++] = queue.pop(); Term term = match[0].term; SegmentMergeInfo top = queue.top(); //如果优先级队列的最顶端和已经弹出的match中的段的第一个Term相同,则全部弹出。 while (top != null && term.compareTo(top.term) == 0) { match[matchSize++] = queue.pop(); top = queue.top(); } if (currentField != term.field) { currentField = term.field; if (termsConsumer != null) termsConsumer.finish(); final FieldInfo fieldInfo = fieldInfos.fieldInfo(currentField); //FormatPostingsFieldsWriter.addField(FieldInfo field)用于添加索引域信息,其返回FormatPostingsTermsConsumer用于添加词信息。 termsConsumer = consumer.addField(fieldInfo); omitTermFreqAndPositions = fieldInfo.omitTermFreqAndPositions; } //合并match数组中的所有的段的第一个Term的倒排表信息,并写入新生成的段。 int df = appendPostings(termsConsumer, match, matchSize); checkAbort.work(df/3.0); while (matchSize > 0) { SegmentMergeInfo smi = match[—matchSize]; //如果match中的段还有下一个Term,则放回优先级队列,进行下一轮的循环。 if (smi.next()) queue.add(smi); else smi.close(); } } |
(4) 合并倒排表
| private final int appendPostings(final FormatPostingsTermsConsumer termsConsumer, SegmentMergeInfo[] smis, int n) throws CorruptIndexException, IOException { //FormatPostingsTermsConsumer.addTerm(char[] text, int start)用于添加词信息,其返回FormatPostingsDocsConsumer用于添加freq信息 //将match数组中段的第一个Term添加到新生成的段中。 final FormatPostingsDocsConsumer docConsumer = termsConsumer.addTerm(smis[0].term.text); int df = 0; for (int i = 0; i < n; i++) { SegmentMergeInfo smi = smis[i]; //得到要合并的段的位置信息(prox) TermPositions postings = smi.getPositions(); //此段的文档号偏移量 int base = smi.base; //在要合并的段中找到Term的倒排表位置。 postings.seek(smi.termEnum); //不断得到下一篇文档号 while (postings.next()) { df++; int doc = postings.doc(); //文档号都要加上偏移量 doc += base; //得到词频信息(frq) final int freq = postings.freq(); //FormatPostingsDocsConsumer.addDoc(int docID, int termDocFreq)用于添加freq信息,其返回FormatPostingsPositionsConsumer用于添加prox信息 final FormatPostingsPositionsConsumer posConsumer = docConsumer.addDoc(doc, freq); //如果位置信息需要保存 if (!omitTermFreqAndPositions) { for (int j = 0; j < freq; j++) { //得到位置信息(prox)以及payload信息 final int position = postings.nextPosition(); final int payloadLength = postings.getPayloadLength(); if (payloadLength > 0) { if (payloadBuffer == null || payloadBuffer.length < payloadLength) payloadBuffer = new byte[payloadLength]; postings.getPayload(payloadBuffer, 0); } //FormatPostingsPositionsConsumer.addPosition(int position, byte[] payload, int payloadOffset, int payloadLength)用于添加prox信息 posConsumer.addPosition(position, payloadBuffer, 0, payloadLength); } posConsumer.finish(); } } } docConsumer.finish(); return df; } |















 884
884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









