







1 问题
最近遇到一个问题,评估行数和真实行数存在较大差距,导致计划不准的问题。
nestloop内表评估是根据外表的参数来的。因为外表驱动表每取一条,内表才能做查询。所以这里外表的一条数据对内表来说就是参数。内表使用参数化路径来评估行数。
本篇针对这个实例对参数化路径行数评估做一些分析。
postgres=# explain analyze select * from iii, mmm where iii.poid = mmm.poid;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=0.43..125.97 rows=17 width=27) (actual time=0.063..6.031 rows=1000 loops=1)
-> Seq Scan on mmm (cost=0.00..1.10 rows=10 width=13) (actual time=0.005..0.010 rows=10 loops=1)
-> Index Scan using idx_iii_poid on iii (cost=0.43..12.47 rows=2 width=14) (actual time=0.022..0.563 rows=100 loops=10)
Index Cond: (poid = mmm.poid)
Planning Time: 0.351 ms
Execution Time: 6.138 ms
(6 rows)
2 全文总结(便于查询)
文章结论
- get_parameterized_baserel_size计算参数化路径的选择率,本例中并没有看到任何特殊的评估方法,完全是按照poid的选择率来评估的。
clauselist_selectivity = 1.7108151058814915e-07
rel->tuples = 10000001
nrows = rel->tuples * clauselist_selectivity = 2
- pg_statistic记录的poid列唯一值个数占比
-0.58516644 - pg_class记录行数为
10000001条,所以评估poid列的唯一值个数为10000001*0.58516644=5845167(实际9901001)。这里有一半的偏差,但不是主要原因。 2行=10000001*1.71e-07,在一个均匀分布的数据集中,每一个唯一值出现的概率是1.71e-07。所以如果有1千万行数据,随便给一个poid,能选出来两行不一样的。- 如果唯一值非常少,那么选择率会变大,趋近于1,则
10000001行=10000001*1。随便给一个poid,能选出来会非常多。 - 如果唯一值非常多,那么选择率会变小,趋近于0,则
0行=10000001*0。随便给一个poid,能选出来会非常少。
- 如果唯一值非常少,那么选择率会变大,趋近于1,则
- 评估两行但实际是100行的原因是,数据不均匀但统计信息平均采样,导致pg_statistic中stadistinct不准,进一步导致选择率不准,导致计算出现偏差。
分析思路整理
- standard_join_search逐层规划连接顺序,找到参数化path节点。
1.1.1 PATH 1:用索引参数化路径,评估2行 - create_index_path在make_one_rel→set_base_rel_pathlists中一共调用6次,其中一次是参数化路径,特点是入参required_outer有值,可能拿到外表信息。
- 进一步分析create_index_path参数化成本计算,create_index_path→get_baserel_parampathinfo函数生成ParamPathInfo,ParamPathInfo中ppi_rows记录估算函数。
- 进一步分析ppi_rows的计算,在create_index_path→get_baserel_parampathinfo中处理,get_baserel_parampathinfo用行数1千万乘以选择率得到行数。
- 进一步分析选择率的计算
- clauselist_selectivity → clause_selectivity_ext → restriction_selectivity → eqsel_internal → var_eq_non_const
- 使用
stadistinct = stats->stadistinct = -0.58516644(来自pg_statistic表) - 使用
ntuples = vardata->rel->tuples = 10000001(来自relation结构,来自pg_class表) - 计算唯一行数:
clamp_row_est(-stadistinct * ntuples = 5845167.024516644) = 5845167 - 进而得到选择率selec = selec / ndistinct = 1 / 5845167 = 1.7108151058814915e-07
实例
-
计划二:优化器认为驱动表每一行,内表有2行能连接上,实际有100行能连接上。为什么差距大?
-
(cost=0.43..12.47 rows=2 width=14) (actual time=0.022..0.563 rows=100 loops=10)评估不准的原因是什么?
-- 计划二
drop table iii;
CREATE TABLE iii (poid INT NOT NULL, value NUMERIC, status int);
-- 可以和mmm表连上
INSERT INTO iii SELECT t%1000, t, 0 FROM generate_series(1, 100000) t order by random();
-- 干扰数据,占比高担都和mmm表连不上
INSERT INTO iii SELECT t, t, 0 FROM generate_series(100000, 10000000) t order by random();
CREATE INDEX idx_iii_poid ON iii(poid);
analyze iii;
drop table mmm;
CREATE TABLE mmm (poid INT NOT NULL, value NUMERIC, status int);
INSERT INTO mmm SELECT t, t, 0 FROM generate_series(1, 10) t order by random();
CREATE INDEX idx_mmm_poid ON mmm(poid);
analyze mmm;
set enable_hashjoin to off;
set enable_mergejoin to off;
set enable_bitmapscan to off;
explain analyze select * from iii, mmm where iii.poid = mmm.poid;
postgres=# explain analyze select * from iii, mmm where iii.poid = mmm.poid;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=0.43..125.97 rows=17 width=27) (actual time=0.063..6.031 rows=1000 loops=1)
-> Seq Scan on mmm (cost=0.00..1.10 rows=10 width=13) (actual time=0.005..0.010 rows=10 loops=1)
-> Index Scan using idx_iii_poid on iii (cost=0.43..12.47 rows=2 width=14) (actual time=0.022..0.563 rows=100 loops=10)
Index Cond: (poid = mmm.poid)
Planning Time: 0.351 ms
Execution Time: 6.138 ms
(6 rows)
要分析这个问题需要从path生成开始看:
path生成
1 standard_join_search第一层
1.1 第一层第一个RelOptInfo(iii表)
p ((RelOptInfo*)root->join_rel_level[1].elements[0].ptr_value).pathlist
1.1.1 PATH 1:用索引参数化路径,评估2行,代价total_cost = 12.466928526553348
$53 = {
path = {
type = T_IndexPath,
pathtype = T_IndexScan,
parent = 0x1e91558,
pathtarget = 0x1e697c8,
param_info = 0x1e8d340,
parallel_aware = false,
parallel_safe = true,
parallel_workers = 0,
rows = 2,
startup_cost = 0.435,
total_cost = 12.466928526553348,
pathkeys = 0x1e8cf90
},
indexinfo = 0x1e91768,
indexclauses = 0x1e8cef0,
indexorderbys = 0x0,
indexorderbycols = 0x0,
indexscandir = ForwardScanDirection,
indextotalcost = 4.4499999999999993,
indexselectivity = 1.7108151058814915e-07
}
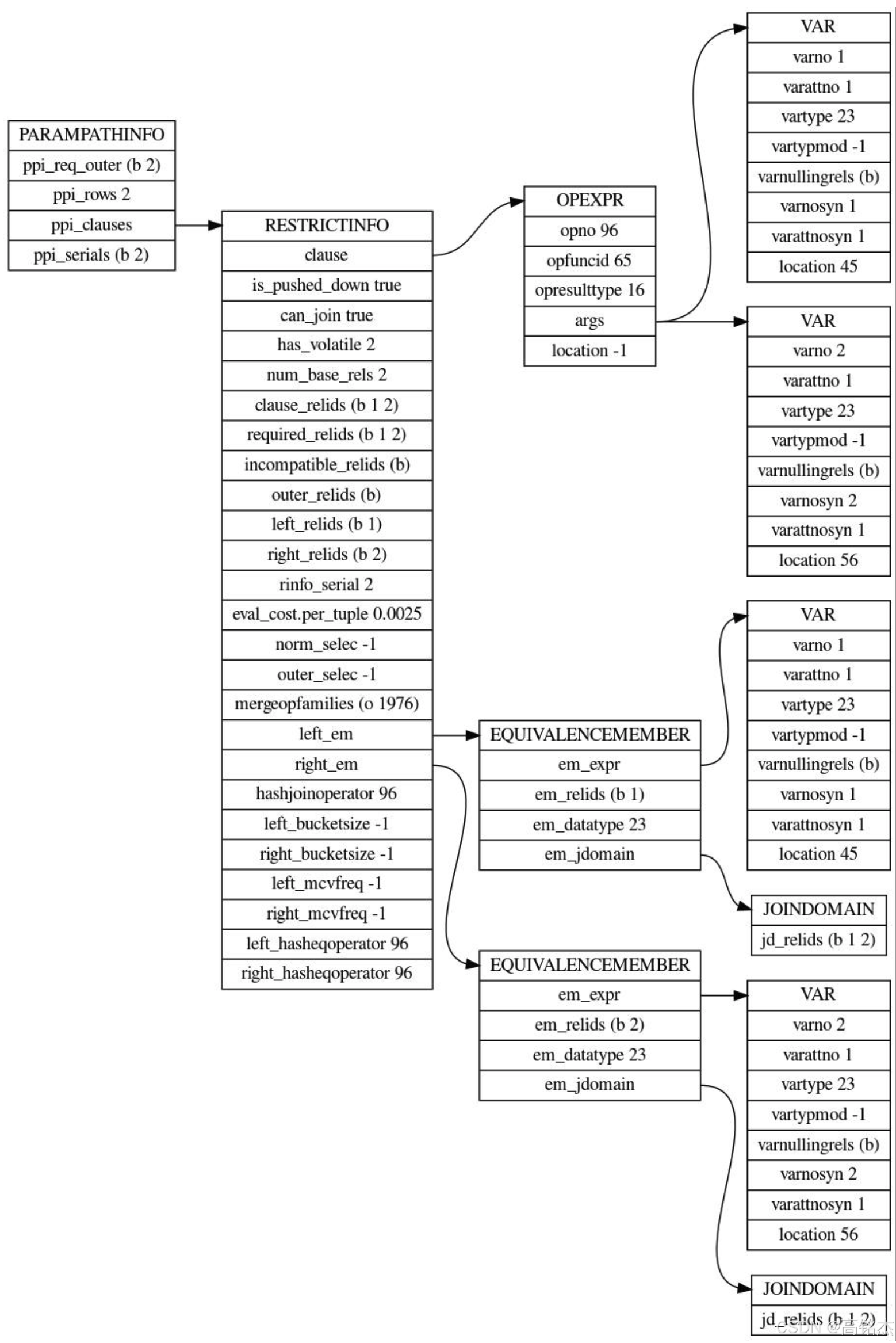
param_info = 0x1e8d340 记录了什么?
1.1.2 PATH 2:全表扫,代价total_cost = 154055.01000000001
(gdb) tr Path 0x1e8bbc0
$55 = {
type = T_Path,
pathtype = T_SeqScan,
parent = 0x1e91558,
pathtarget = 0x1e697c8,
param_info = 0x0,
parallel_aware = false,
parallel_safe = true,
parallel_workers = 0,
rows = 10000001,
startup_cost = 0,
total_cost = 154055.01000000001,
pathkeys = 0x0
}
1.1.3 PATH 3:用索引全表扫iii表,评估10000001行。代价total_cost = 475019.93093073595
$57 = {
path = {
type = T_IndexPath,
pathtype = T_IndexScan,
parent = 0x1e91558,
pathtarget = 0x1e697c8,
param_info = 0x0,
parallel_aware = false,
parallel_safe = true,
parallel_workers = 0,
rows = 10000001,
startup_cost = 0.435,
total_cost = 475019.93093073595,
pathkeys = 0x1e8c7d0
},
indexinfo = 0x1e91768,
indexclauses = 0x0,
indexorderbys = 0x0,
indexorderbycols = 0x0,
indexscandir = ForwardScanDirection,
indextotalcost = 158924.44,
indexselectivity = 1
}
1.2 第一层第二个RelOptInfo(mmm表)
p ((RelOptInfo*)root->join_rel_level[1].elements[1].ptr_value).pathlist
1.2.1 PATH 1:用索引参数化路径,评估1行,代价total_cost = 0.15250119999987999
$70 = {
path = {
type = T_IndexPath,
pathtype = T_IndexScan,
parent = 0x1e90d28,
pathtarget = 0x1e698f8,
param_info = 0x1eac2d8,
parallel_aware = false,
parallel_safe = true,
parallel_workers = 0,
rows = 1,
startup_cost = 0.13500000000000001,
total_cost = 0.15250119999987999,
pathkeys = 0x1eabfd8
},
indexinfo = 0x1e8b8c8,
indexclauses = 0x1eabf38,
indexorderbys = 0x0,
indexorderbycols = 0x0,
indexscandir = ForwardScanDirection,
indextotalcost = 0.14250079999991999,
indexselectivity = 0.10000000000000001
}
1.2.2 PATH 2:全表扫,评估10行,代价total_cost = 1.1000000000000001
$71 = {
type = T_Path,
pathtype = T_SeqScan,
parent = 0x1e90d28,
pathtarget = 0x1e698f8,
param_info = 0x0,
parallel_aware = false,
parallel_safe = true,
parallel_workers = 0,
rows = 10,
startup_cost = 0,
total_cost = 1.1000000000000001,
pathkeys = 0x0
}
1.2.3 PATH 3:索引全表扫,评估10行,代价otal_cost = 12.285
{
path = {
type = T_IndexPath,
pathtype = T_IndexScan,
parent = 0x1e90d28,
pathtarget = 0x1e698f8,
param_info = 0x0,
parallel_aware = false,
parallel_safe = true,
parallel_workers = 0,
rows = 10,
startup_cost = 0.13500000000000001,
total_cost = 12.285,
pathkeys = 0x1eab998
},
indexinfo = 0x1e8b8c8,
indexclauses = 0x0,
indexorderbys = 0x0,
indexorderbycols = 0x0,
indexscandir = ForwardScanDirection,
indextotalcost = 8.1850000000000005,
indexselectivity = 1
}
2 standard_join_search第二层,只有一个RelOptInfo
p ((RelOptInfo*)root->join_rel_level[2].elements[0].ptr_value).pathlist
只有一个PATH
$91 = {
jpath = {
path = {
type = T_NestPath,
pathtype = T_NestLoop,
parent = 0x1eacc28,
pathtarget = 0x1eace58,
param_info = 0x0,
parallel_aware = false,
parallel_safe = true,
parallel_workers = 0,
rows = 17,
startup_cost = 0.435,
total_cost = 125.96928526553347,
pathkeys = 0x0
},
jointype = JOIN_INNER,
inner_unique = false,
outerjoinpath = 0x1e8d780,
innerjoinpath = 0x1e8d020,
joinrestrictinfo = 0x0
}
}
- outerjoinpath = 0x1e8d780:选择了1.2.2 PATH 2:全表扫,评估10行,代价total_cost = 1.1000000000000001。
- innerjoinpath = 0x1e8d020:选择了1.1.1 PATH 1:用索引参数化路径,评估2行,代价total_cost = 12.466928526553348。
为什么iii表的索引参数化路径评估只有2行?
- 现阶段只有nestloop的内表需要参数化路径,因为内表评估行数时,无法确切知道能连上多少行,所以只能计算出一个行数。
- 在上文
1.1.1 PATH 1:用索引参数化路径,评估2行,代价total_cost = 12.466928526553348中,参数化node评估的行数是怎么计算出来的?
$53 = {
path = {
type = T_IndexPath,
pathtype = T_IndexScan,
parent = 0x1e91558,
pathtarget = 0x1e697c8,
param_info = 0x1e8d340,
parallel_aware = false,
parallel_safe = true,
parallel_workers = 0,
rows = 2,
startup_cost = 0.435,
total_cost = 12.466928526553348,
pathkeys = 0x1e8cf90
},
indexinfo = 0x1e91768,
indexclauses = 0x1e8cef0,
indexorderbys = 0x0,
indexorderbycols = 0x0,
indexscandir = ForwardScanDirection,
indextotalcost = 4.4499999999999993,
indexselectivity = 1.7108151058814915e-07
}
create_index_path在make_one_rel→set_base_rel_pathlists中一共调用6次:
-- iii表的索引 idx_iii_poid,非参数化路径
create_index_path (root=0x1e68cb8, index=0x1e91768, indexclauses=0x0, indexorderbys=0x0, indexorderbycols=0x0, pathkeys=0x1e8c7d0, indexscandir=ForwardScanDirection, indexonly=false, required_outer=0x0, loop_count=1, partial_path=false)
-- iii表的索引 idx_iii_poid,非参数化路径
create_index_path (root=0x1e68cb8, index=0x1e91768, indexclauses=0x0, indexorderbys=0x0, indexorderbycols=0x0, pathkeys=0x1e8c7d0, indexscandir=ForwardScanDirection, indexonly=false, required_outer=0x0, loop_count=1, partial_path=true)
-- iii表的索引 idx_iii_poid,required_outer有值,计算参数化路径
create_index_path (root=0x1e68cb8, index=0x1e91768, indexclauses=0x1e8cef0, indexorderbys=0x0, indexorderbycols=0x0, pathkeys=0x1e8cf90, indexscandir=ForwardScanDirection, indexonly=false, required_outer=0x1e8cca0, loop_count=10, partial_path=false)
-- mmm表的索引 idx_mmm_poid
create_index_path (root=0x1e68cb8, index=0x1e8b8c8, indexclauses=0x0, indexorderbys=0x0, indexorderbycols=0x0, pathkeys=0x1eab998, indexscandir=ForwardScanDirection, indexonly=false, required_outer=0x0, loop_count=1, partial_path=false)
create_index_path (root=0x1e68cb8, index=0x1e8b8c8, indexclauses=0x0, indexorderbys=0x0, indexorderbycols=0x0, pathkeys=0x1eab998, indexscandir=ForwardScanDirection, indexonly=false, required_outer=0x0, loop_count=1, partial_path=true)
create_index_path (root=0x1e68cb8, index=0x1e8b8c8, indexclauses=0x1eabf38, indexorderbys=0x0, indexorderbycols=0x0, pathkeys=0x1eabfd8, indexscandir=ForwardScanDirection, indexonly=false, required_outer=0x1e8d2d0, loop_count=10000001, partial_path=false)
- required_outer有值,表示参数化的indexpath:
-- iii表的索引 idx_iii_poid,required_outer有值,计算参数化路径
create_index_path (root=0x1e68cb8, index=0x1e91768, indexclauses=0x1e8cef0, indexorderbys=0x0, indexorderbycols=0x0, pathkeys=0x1e8cf90, indexscandir=ForwardScanDirection, indexonly=false, required_outer=0x1e8cca0, loop_count=10, partial_path=false)
参数化路径计算
create_index_path→get_baserel_parampathinfo函数生成ParamPathInfo
get_baserel_parampathinfo调用get_parameterized_baserel_size评估,当前节点是几行。例如评估出来2行。explain时内表看到的rows就是2行,含义是外表每一行过来,内表有两行能连上。
get_parameterized_baserel_size
double
get_parameterized_baserel_size(PlannerInfo *root, RelOptInfo *rel,
List *param_clauses)
{
List *allclauses;
double nrows;
allclauses = list_concat_copy(param_clauses, rel->baserestrictinfo);
nrows = rel->tuples *
clauselist_selectivity(root,
allclauses,
rel->relid, /* do not use 0! */
JOIN_INNER,
NULL);
nrows = clamp_row_est(nrows);
/* For safety, make sure result is not more than the base estimate */
if (nrows > rel->rows)
nrows = rel->rows;
return nrows;
}
- allclauses合并param_clauses参数化条件和rel->baserestrictinfo当前表自身的约束条件,得到综合条件列表。
- 使用 clauselist_selectivity 函数计算这些条件的综合选择率,再乘以表的基数rel->tuples,最终得到参数化路径下的预估行数。
当前的allclauses表本身没有条件,只有外表提供的参数化条件:
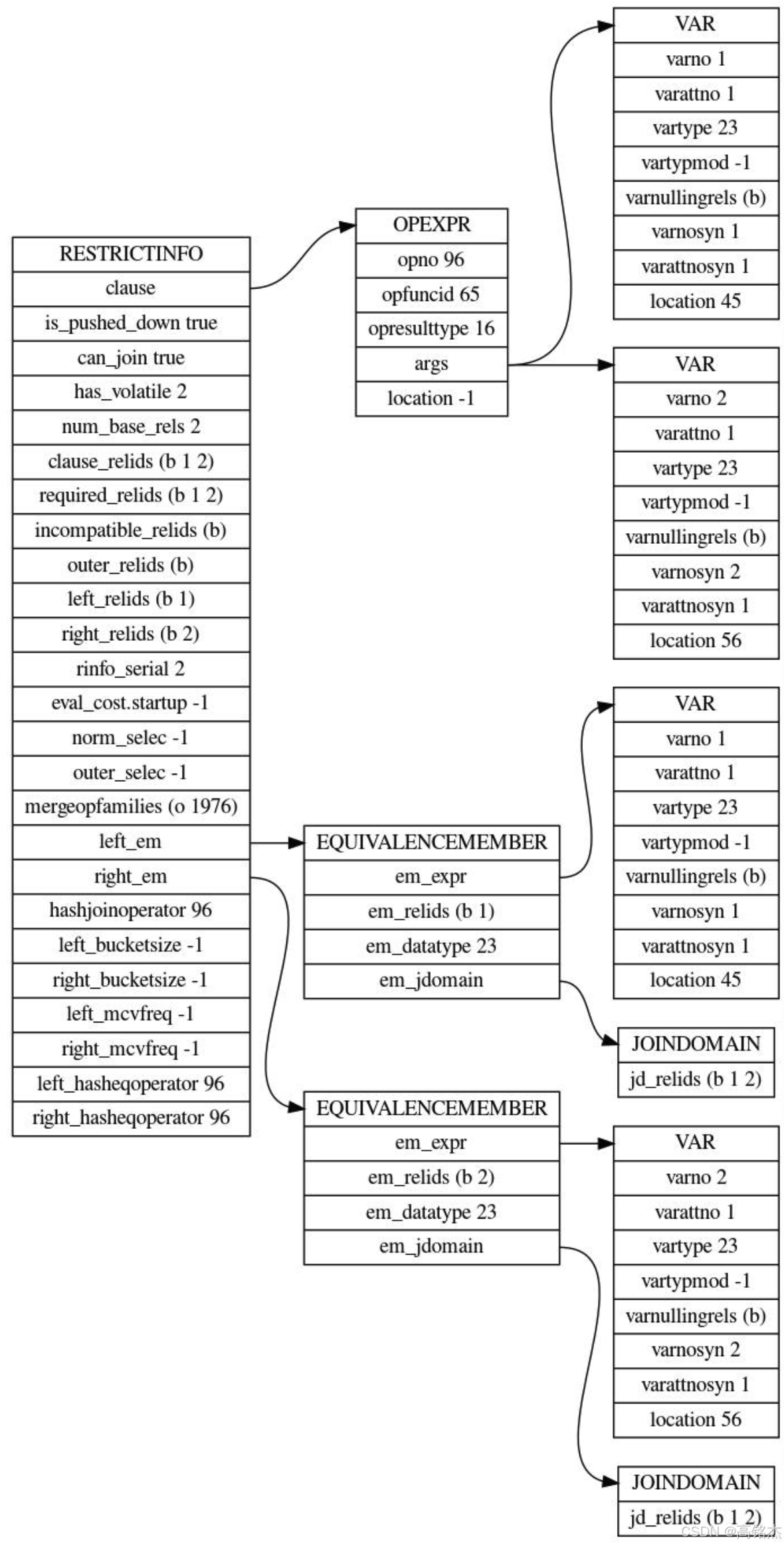
-
上图中opexpr是等号,指向varno=1、varno=2指向两个基表。
-
nrows = rel->tuples * clauselist_selectivity = 2
- clauselist_selectivity = 1.7108151058814915e-07
- rel->tuples = 10000001
clauselist_selectivity → clause_selectivity_ext的计算逻辑分支较多,这里只给出本例走到的分支:
clause_selectivity_ext
...
...
clause = (Node *) rinfo->clause;
...
...
else if (is_opclause(clause) || IsA(clause, DistinctExpr))
...
...
restriction_selectivity
...
restriction_selectivity用于计算条件(where中过滤条件)的选择率:
Selectivity
restriction_selectivity(PlannerInfo *root,
Oid operatorid,
List *args,
Oid inputcollid,
int varRelid)
{
- 这里operatorid=96是等号。
- get_oprrest从系统表中拿到oprrest 字段,字段指向一个注册的选择率计算函数oid=101,eqsel函数。
RegProcedure oprrest = get_oprrest(operatorid);
float8 result;
/*
* if the oprrest procedure is missing for whatever reason, use a
* selectivity of 0.5
*/
if (!oprrest)
return (Selectivity) 0.5;
result = DatumGetFloat8(OidFunctionCall4Coll(oprrest,
inputcollid,
PointerGetDatum(root),
ObjectIdGetDatum(operatorid),
PointerGetDatum(args),
Int32GetDatum(varRelid)));
if (result < 0.0 || result > 1.0)
elog(ERROR, "invalid restriction selectivity: %f", result);
return (Selectivity) result;
}
进入eqsel函数开始计算选择率,eqsel用于计算等值和不等值操作符的选择率,是优化器代价模型的核心组成部分。
- root:优化器上下文(包含统计信息、表元数据等)
- operator:操作符的 OID(如 = 或 <>)
- args:操作符的参数列表(如 a = 5 中的列 a 和常量 5)
- varRelid:关联的关系 ID(用于确定统计信息范围)
- collation:排序规则(影响字符串比较)
/*
* Common code for eqsel() and neqsel()
*/
static double
eqsel_internal(PG_FUNCTION_ARGS, bool negate)
{
PlannerInfo *root = (PlannerInfo *) PG_GETARG_POINTER(0);
Oid operator = PG_GETARG_OID(1);
List *args = (List *) PG_GETARG_POINTER(2);
int varRelid = PG_GETARG_INT32(3);
Oid collation = PG_GET_COLLATION();
VariableStatData vardata;
Node *other;
bool varonleft;
double selec;
negate表示不等值。
if (negate)
{
operator = get_negator(operator);
if (!OidIsValid(operator))
{
/* Use default selectivity (should we raise an error instead?) */
return 1.0 - DEFAULT_EQ_SEL;
}
}
本例中的args:
- Var = {xpr = {type = T_Var}, varno = 1, varattno = 1, vartype = 23}
- Var = {xpr = {type = T_Var}, varno = 2, varattno = 1, vartype = 23}
- varRelid = 1
/*
* If expression is not variable = something or something = variable, then
* punt and return a default estimate.
*/
if (!get_restriction_variable(root, args, varRelid,
&vardata, &other, &varonleft))
return negate ? (1.0 - DEFAULT_EQ_SEL) : DEFAULT_EQ_SEL;
get_restriction_variable将条件拆分为变量和常量或其他表达式。
- vardata
- {var = 0x1e6b2c0, rel = 0x1e8b8f8, statsTuple = 0x7f4874e75e08, freefunc = 0xb73cd6 , vartype = 23, atttype = 23, atttypmod = -1, isunique = false, acl_ok = true}
- var = {xpr = {type = T_Var}, varno = 1, varattno = 1, vartype = 23}
- statsTuple = pg_stat_statistic对应的行。
- {var = 0x1e6b2c0, rel = 0x1e8b8f8, statsTuple = 0x7f4874e75e08, freefunc = 0xb73cd6 , vartype = 23, atttype = 23, atttypmod = -1, isunique = false, acl_ok = true}
- other = {{xpr = {type = T_Var}, varno = 2, varattno = 1, vartype = 2}
- varonleft = true
开始计算选择率 var_eq_non_const
/*
* We can do a lot better if the something is a constant. (Note: the
* Const might result from estimation rather than being a simple constant
* in the query.)
*/
if (IsA(other, Const))
selec = var_eq_const(&vardata, operator, collation,
((Const *) other)->constvalue,
((Const *) other)->constisnull,
varonleft, negate);
else
selec = var_eq_non_const(&vardata, operator, collation, other,
varonleft, negate);
ReleaseVariableStats(vardata);
return selec;
}
var_eq_non_const用于计算变量与非常量表达式(如其他列或子查询结果)的等值条件(= 或 <>)的选择率,例如 a = b 或 x <> y。核心逻辑是基于统计信息(如唯一性约束、NULL值比例、不同值数量等),结合启发式规则估算满足条件的行数比例
- vardata:变量统计信息(如列 a 的直方图、MCV列表等)。
- oproid:操作符OID(如 = 或 <>)。
- other:非常量表达式(如另一列 b 或表达式 b + 1)。
- negate:不等。
/*
* var_eq_non_const --- eqsel for var = something-other-than-const case
*
* This is exported so that some other estimation functions can use it.
*/
double
var_eq_non_const(VariableStatData *vardata, Oid oproid, Oid collation,
Node *other,
bool varonleft, bool negate)
{
double selec;
double nullfrac = 0.0;
bool isdefault;
先拿到pg_statistic表对应的行。
if (HeapTupleIsValid(vardata->statsTuple))
{
Form_pg_statistic stats;
stats = (Form_pg_statistic) GETSTRUCT(vardata->statsTuple);
nullfrac = stats->stanullfrac;
}
...
else if (HeapTupleIsValid(vardata->statsTuple))
{
double ndistinct;
AttStatsSlot sslot;
基于统计信息估算:
- 计算非NULL值比例 1 - nullfrac。
- 通过 get_variable_numdistinct 获取变量不同值数量 ndistinct。
- 假设每个不同值均匀分布,选择率为 (1 - nullfrac) / ndistinct。
- 与MCV(最常见值)的最大频率比较,避免高估。
selec = 1.0 - nullfrac;
ndistinct = get_variable_numdistinct(vardata, &isdefault);
get_variable_numdistinct计算结果:5845167
stadistinct = stats->stadistinct = -0.58516644(来自pg_statistic表)stanullfrac = 0ntuples = vardata->rel->tuples = 10000001(来自relation结构,来自pg_class表)- 计算结果:
clamp_row_est(-stadistinct * ntuples = 5845167.024516644) = 5845167
get_variable_numdistinct计算方法总结:pg_statistic表的stadistinct中取得选择率 乘以 评估行数,等于评估出来多少个唯一值。stadistinct含义:stadistinct > 0表示该列中非空唯一值的实际数量。stadistinct < 0表示非空唯一值的数量占总行数的比例。stadistinct = 0表示无法确定该列的非空唯一值数量。
if (ndistinct > 1)
selec /= ndistinct;
...
...
return selec;
计算得到选择率
selec = selec / ndistinct = 1 / 5845167 = 1.7108151058814915e-07
回到最初的行数评估函数get_parameterized_baserel_size中:
- nrows = rel->tuples * clauselist_selectivity = 2
- clauselist_selectivity = 1.7108151058814915e-07
- rel->tuples = 10000001
总结:
- pg_statistic记录的poid列唯一值个数占比
-0.58516644 - pg_class记录行数为
10000001条,所以评估poid列的唯一值个数为10000001*0.58516644=5845167(实际9901001)。这里有一半的偏差,但不是主要原因。 2行=10000001*1.71e-07,在一个均匀分布的数据集中,每一个唯一值出现的概率是1.71e-07。所以如果有1千万行数据,随便给一个poid,能选出来两行不一样的。- 如果唯一值非常少,那么选择率会变大,趋近于1,则
10000001行=10000001*1。随便给一个poid,能选出来会非常多。 - 如果唯一值非常多,那么选择率会变小,趋近于0,则
0行=10000001*0。随便给一个poid,能选出来会非常少。
- 如果唯一值非常少,那么选择率会变大,趋近于1,则
- 评估两行但实际是100行的原因是,pg_statistic中stadistinct记录的连接条件poid列的唯一值。
create_index_path→cost_index计算参数化路径评估行数(从上一步的ParamPathInfo结果中取得)
- cost_index中如果发现参数化路径,会从ParamPathInfo中取评估行数
- 本例中path->path.param_info->ppi_rows=2。
- param_info存在表示当前索引扫描路径是参数化的,依赖外部循环(如嵌套循环连接的外层表)提供的参数值。
- 行数估算:ppi_rows 表示参数化路径的预估行数,这是优化器根据外层表(如嵌套循环中的驱动表)的约束条件和连接关系动态调整的结果,比如ppi_rows=2表示,优化器评估外表每一条,内表有两条能连得上。
void
cost_index(IndexPath *path, PlannerInfo *root, double loop_count,
bool partial_path)
...
...
if (path->path.param_info)
{
path->path.rows = path->path.param_info->ppi_rows;
/* qpquals come from the rel's restriction clauses and ppi_clauses */
qpquals = list_concat(extract_nonindex_conditions(path->indexinfo->indrestrictinfo,
path->indexclauses),
extract_nonindex_conditions(path->path.param_info->ppi_clauses,
path->indexclauses));
}
else
{
path->path.rows = baserel->rows;
/* qpquals come from just the rel's restriction clauses */
qpquals = extract_nonindex_conditions(path->indexinfo->indrestrictinfo,
path->indexclauses);
}
...



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











