










口播数字人生成教程:从生成人物到制作视频的全流程指南
一、问题引入:你还在自己出镜拍口播视频吗?
在短视频时代,口播类内容因其信息密度高、传播效率强而广受欢迎。但很多人因为镜头恐惧、时间成本高或外貌焦虑等问题,迟迟不敢尝试。
⚠️ 常见痛点:
- 拍摄准备流程繁琐
- 出镜紧张影响表达
- 后期剪辑耗时费力
有没有一种方式,可以不露脸也能做高质量口播视频?答案是:当然有!通过AI技术,你可以轻松打造一个专属的“数字人”来为你发声!
二、工具介绍:三步打造你的AI口播数字人
我们将使用以下三个平台完成整个流程:
-
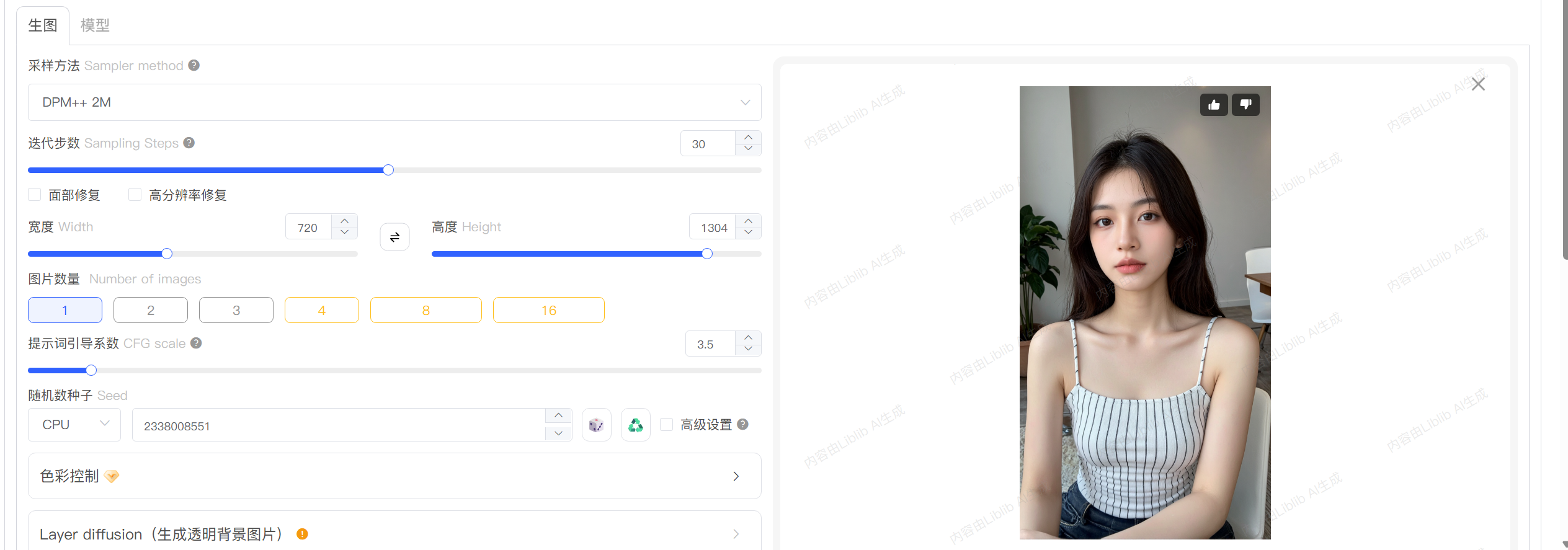
Stable Diffusion(SD):生成个性化AI人物图片 可以是你对应的职业
-
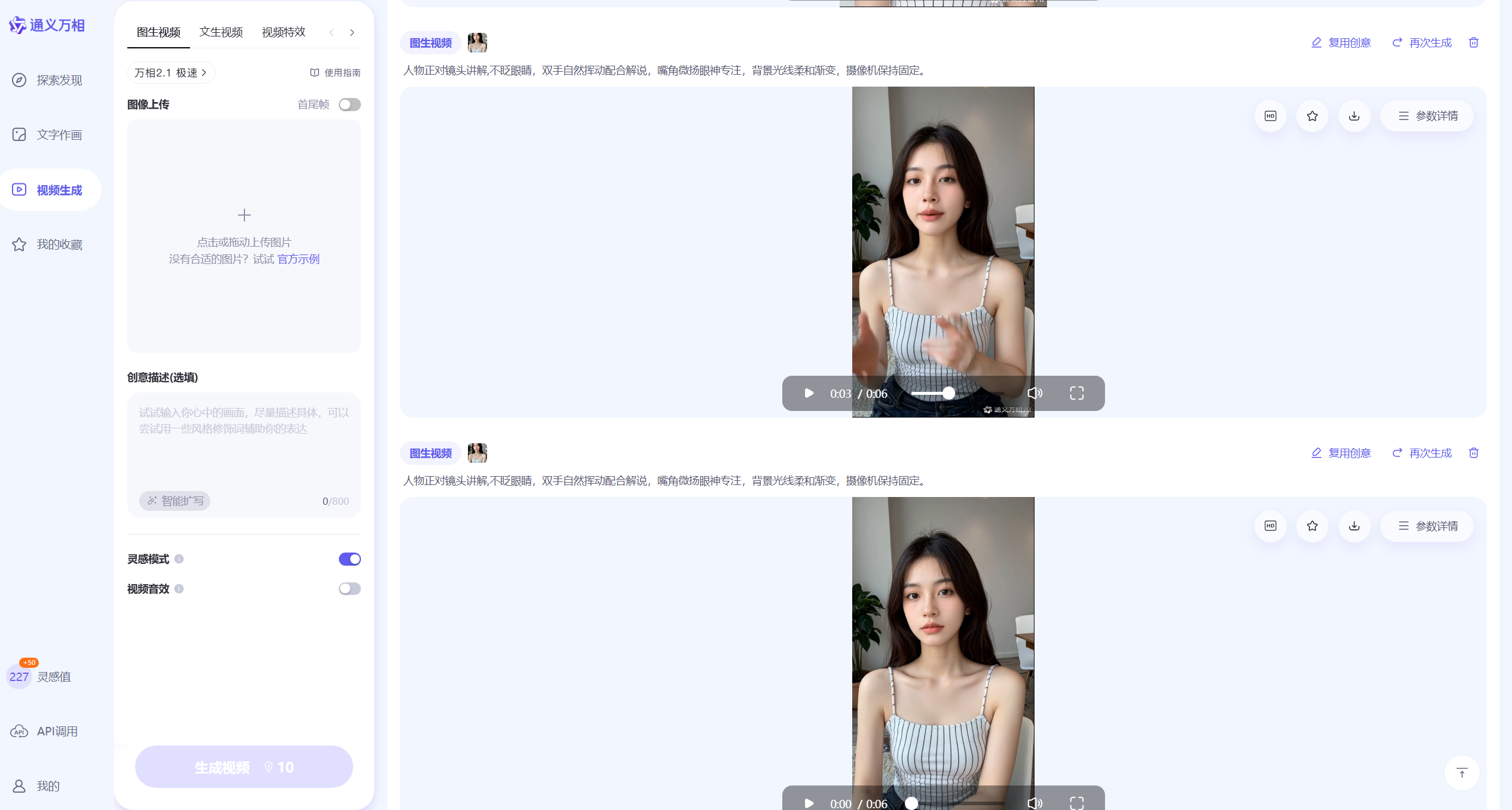
通义万相:让静态图片动起来 让图片变成讲解一样的视频
-
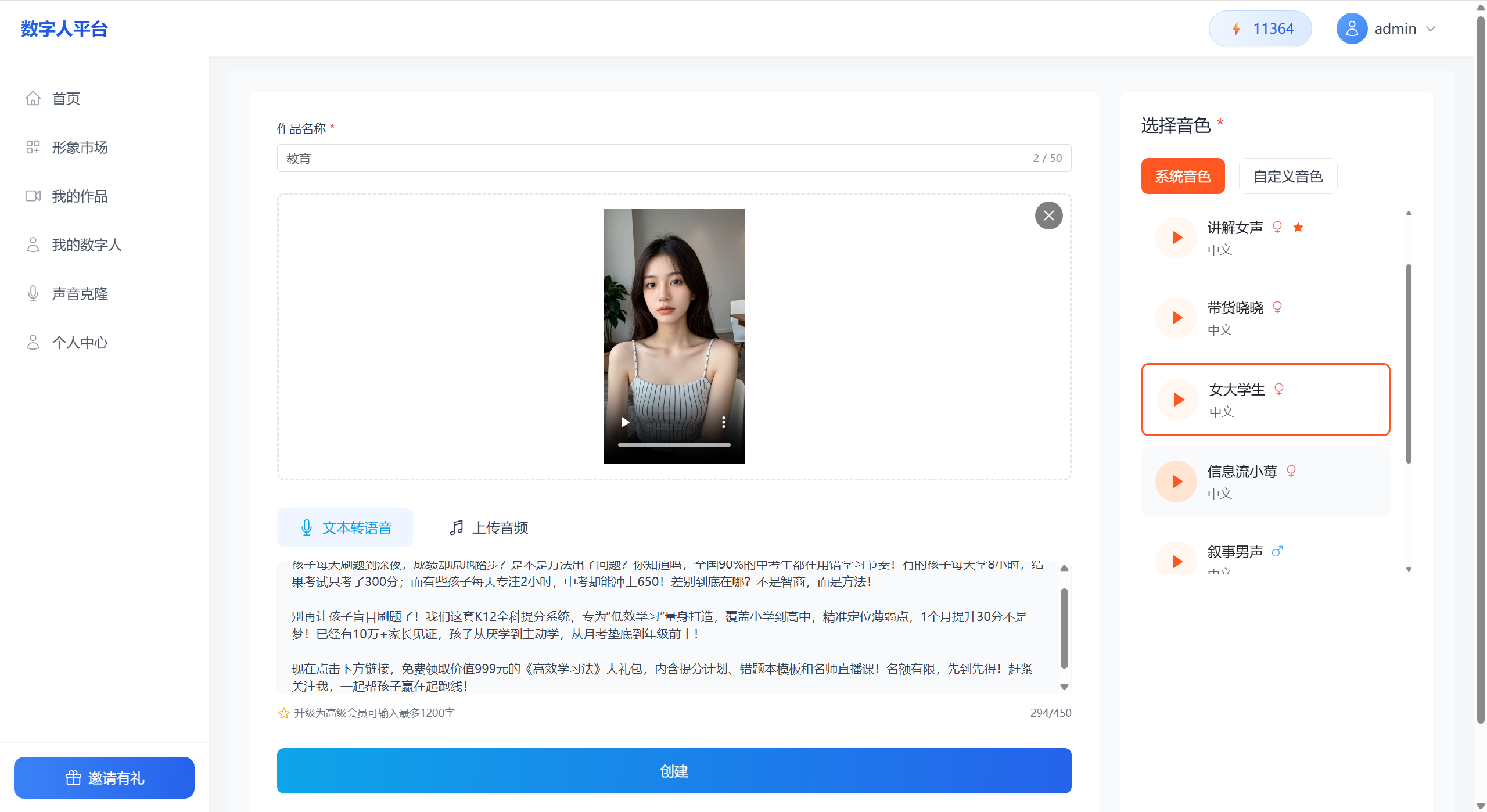
在去打开数字人制作的网站**https://ai.cutb.cn**上传通义万相生成的视频去生成口播数字人视频
一句话总结:用SD画人 → 用通义万相让人动起来 → 用cutb让TA开口说话。
2.1 Stable Diffusion:生成人物形象
什么是Stable Diffusion?
Stable Diffusion 是一个开源的图像生成模型,支持本地部署和在线使用,能根据提示词生成高质量的人物图像。
使用建议:
- 提示词要具体:如“亚洲女性,职业装,微笑,正面照”
- 可以参考已有风格进行模仿(如主播、老师、科技博主)
「图1:Stable Diffusion WebUI界面」
⚠️ 避坑指南:
- 不要用太模糊的描述词,如“好看的人”,容易生成奇怪的结果
- 建议先下载插件(如ADetailer)自动优化人脸细节
2.2 通义万相:让图片动起来
什么是通义万相?
这是阿里推出的AI视频生成工具,支持将静态图生成带动作的视频片段,比如眨眼、张嘴、点头等。
使用方法简述:
- 打开通义万相官网
- 选择“文生视频”或“图生视频”模式
- 上传之前生成的AI人物图片
- 输入动作描述词(如“说话中”、“微笑点头”)
⚠️ 避坑指南:
- 动作描述要清晰,否则可能动作混乱
- 视频长度控制在5~10秒为宜,效果更自然
2.3 轻剪数字人:生成口播视频
什么是 轻剪数字人?
这是一个国产AI口播视频生成平台,支持上传动态头像+语音合成,自动生成口播数字人视频。
官网:https://ai.cutb.cn
操作流程:
- 注册账号并登录
- 点击“创建项目”
- 上传由通义万相生成的动态视频
- 录制或粘贴文案,选择语音风格(男声/女声、语速)
- 导出视频
⚠️ 避坑指南:
- 音色与画面风格要匹配,避免违和感
- 文案不要太长,建议控制在30秒以内
- 如果音频同步错位,可手动微调时间轴
三、功能演示:一个完整的数字人视频制作案例
我们来模拟一个场景:你要做一个关于“如何高效学习AI”的短视频口播。
步骤如下:
- Stable Diffusion:输入提示词:“自信的职业讲师,穿着西装,在讲台前站立”
- 通义万相:上传该图,输入“讲解知识点,点头示意”
- 轻剪数字人:上传生成视频,输入文案:“大家好,今天我们聊聊AI学习的三个误区……”
最终输出:一个专业讲师形象的数字人正在讲解内容,背景干净,语音自然。
四、使用技巧与实战建议
技巧1:统一风格提升专业度
- 在SD中设定统一人物形象(如性别、服装、发型)
- 在通义万相中保持一致的动作风格(如坐姿、手势)
技巧2:语音节奏控制
- 尽量使用短句,避免复杂语法
- 适当加入语气词,增强亲和力(如“你知道吗?”)
技巧3:批量制作节省时间
- 利用模板化流程快速复用角色+动作组合
- 一次生成多个视频片段,后期拼接成系列课程
五、总结建议:AI口播数字人的价值与未来趋势
随着AIGC的发展,数字人将成为内容创作的新标配。它不仅解决了出镜难题,还能实现24小时自动化内容生产。
“这不是替代人类,而是放大人类的表达能力。”
✅ 推荐使用场景:
- 教育培训类短视频
- 企业宣传/产品介绍
- 社交媒体日常更新
❌ 不推荐场景:
- 需要真实情感互动的直播
- 法律或金融领域需身份认证的内容
🧠 技术讨论题
你觉得未来几年内,数字人工具是否能完全替代真人主播?为什么?欢迎在评论区留言交流!
如果你已经准备好开始制作自己的数字人视频了,那就快去试试这三个工具吧!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









