










背景介绍
首先介绍下推送系统的作用,如上图是一个新闻业务的推送/通知,推送主要就是在用户不打开APP的时候有一个手段触达用户,保持APP的存在感,提高APP的日活。公司目前主要用推送的业务包括
- 主播开播,公司有直播业务,主播在开直播的时候会给这个主播的所有粉丝发一个推送开播提醒
- 专辑更新,平台上有非常多的专辑,专辑下面是一系列具体的声音,比如一本儿小说是一个专辑,小说有很多章节,那么当小说更新章节的时候给所有订阅这个专辑的用户发一个更新的提醒。
- 个性化、新闻业务等。
既然想给一个用户发推送,系统要跟这个用户设备之间有一个联系的通道。自建通道需要App常驻后台,而手机厂商因为省电等原因普遍采取“激进”的后台进程管理策略,导致自建通道质量较差。目前通道一般是由“推送服务商”去维护,也就是说公司内的推送系统并不直接给用户发推送,推送流转流程如下:
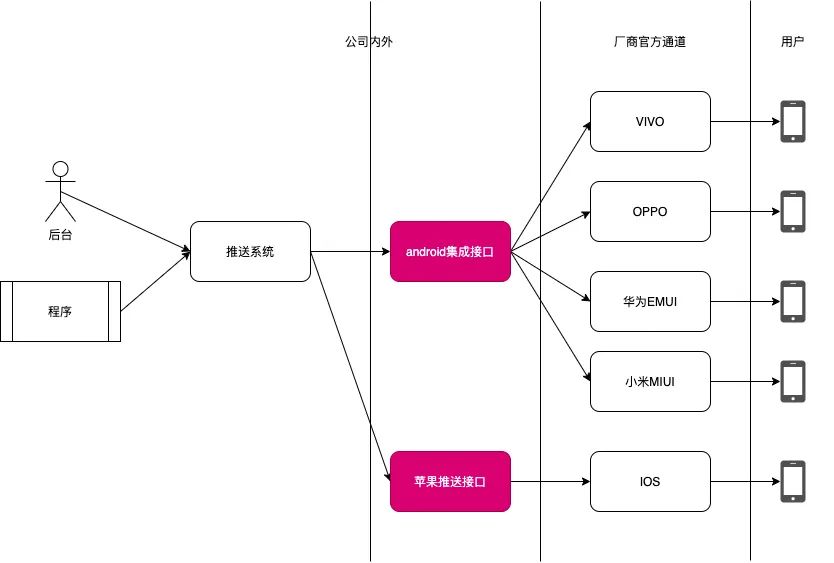
国内的几大厂商hmov有自己官方的推送通道,但是每一家接口都不一样,所以一些厂商比如小米、个推提供集成接口。发送时推送系统发给集成商,然后集成商根据具体的设备,发给hmov这些具体的厂商,最终发给用户。
给设备发推送的时候,必须说清楚你要发的是什么内容,即title、message/body,还要指定给哪个设备发推送。我们以token来标识一个设备, 在不同的场景下token的含义是不一样的,公司内部一般用uid或者deviceId标识一个设备,对于集成商、hmov也有自己对设备的唯一“编号”,所以公司内部的推送服务,要负责进行uid、deviceId到集成商token 的转换。
整体设计
技术架构设计
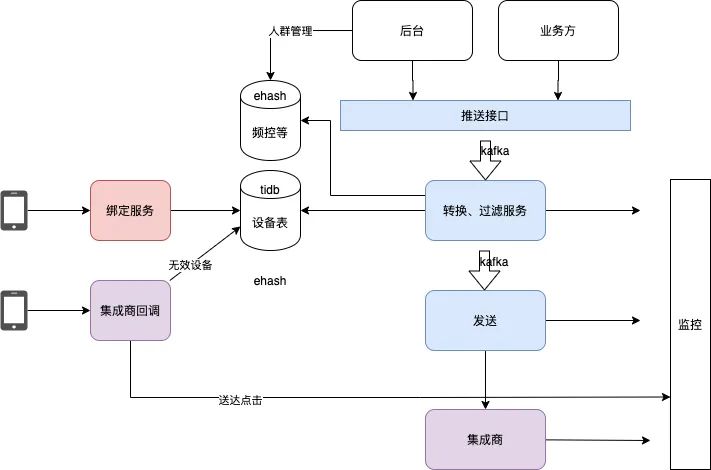
推送整体上是一个基于队列的流式处理系统,上图右侧是主链路,各个业务方通过推送接口给推送系统发推送,推送接口会把数据发到一个队列,由转换和过滤服务消费。转换就是上文说的uid/deviceId到token的转换,过滤下文专门讲,转换过滤处理后发给发送模块,最终给到集成商接口。
App 启动时会向服务端发送绑定请求,上报uid/deviceId与token的绑定关系。当卸载/重装App等导致token失效时,集成商通过http回调告知推送系统。各个组件都会通过kafka 发送流水到公司的xstream 实时流处理集群,聚合数据并落盘到mysql,最终由grafana提供各种报表展示。
业务过滤机制设计
各个业务方可以无脑给用户发推送,但推送系统要有节制,因此要对业务消息有选择的过滤,包括以下几点(按支持的先后顺序):
- 用户开关,App支持配置用户开关,若用户关闭了推送,则不向用户设备发推送。
- 文案排重,一个用户不能收到重复的文案,用于防止上游业务方发送逻辑出错。
- 频率控制,每一个业务对应一个msg_type,设定xx时间内最多发xx条推送。
- 静默时间,每天xx点到xx点不给用户发推送,以免打扰用户休息。
- 用户/消息分级
-
- 每一个msg/msg_type有一个level,给重要/高level业务更多发送机会。
- 当用户一天收到xx条推送时,不是重要的消息就不再发给这些用户。
一些具体的技术问题
分库分表下的多维查询问题
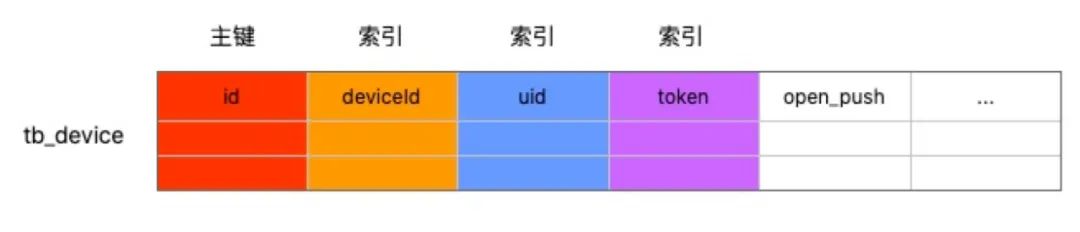
喜马拉雅现在已经有6亿+用户,对应的推送系统的设备表(记录uid/deviceId到token的映射)也有类似的量级,所以对设备表进行了分库分表,以deviceId为分表列。
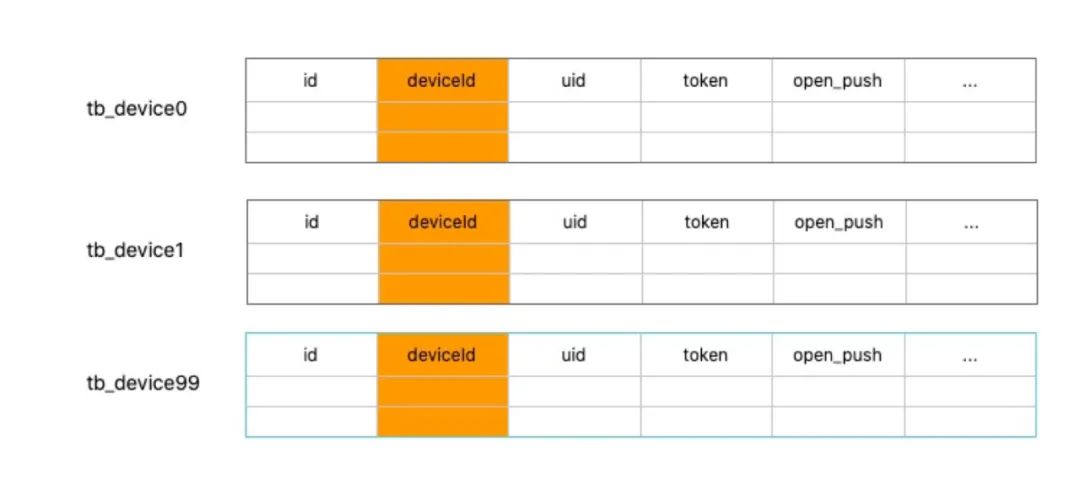
但实际上经常有根据uid/token 的查询需求,因此还需要建立以uid/token 到 deviceId的映射关系。因为uid 查询的场景也很频繁,因此uid副表也拥有和主表同样的字段。
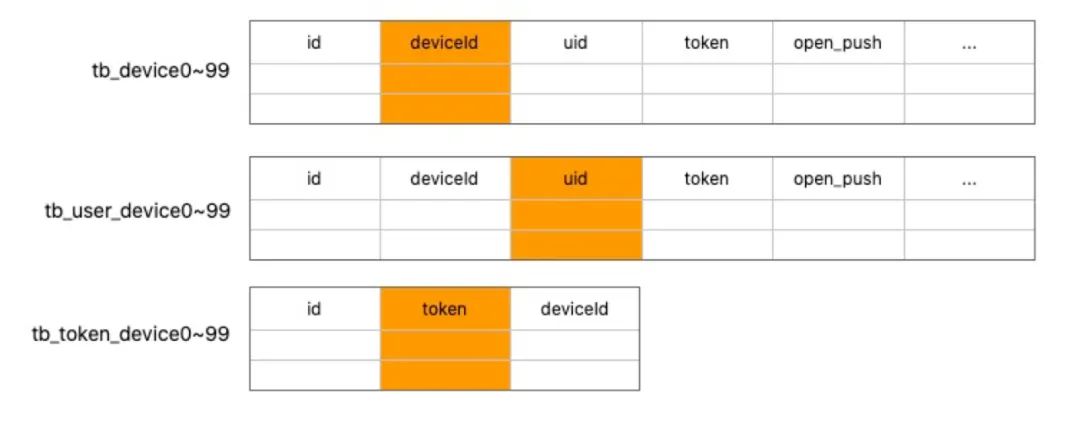
因为每天会进行一两次全局推,且针对沉默用户(不常使用app)也有专门的推送,存储方面实际上不存在“热点”,虽然使用了缓存,但作用很有限,且占用空间巨大。多分表以及缓存导致数据存在三四个副本,不同逻辑使用不同副本,经常出现不一致问题(追求一致则影响性能), 查询代码非常复杂且性能较低。最终选择了将设备数据存储在tidb上,在性能够用的前提下,大大简化了代码。
特殊业务的时效性问题
推送系统是基于队列的,“先到先推”。大部分业务不要求很高的实时性,但直播业务要求半个小时送达,新闻业务更是“欲求不满”,越快越好。若进行新闻推送时,队列中有巨量的“专辑更新”推送等待处理,则专辑更新业务会严重干扰新闻业务的送达。
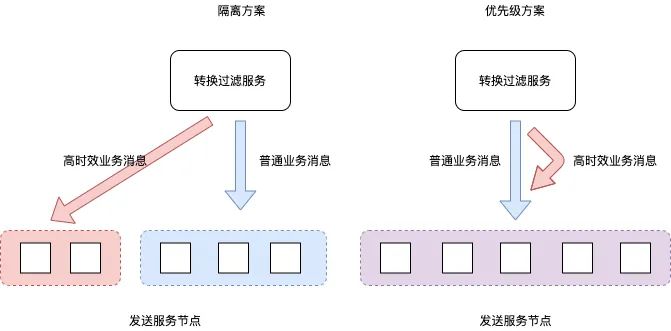
一开始我们认为这是一个隔离问题,比如10个消费节点,3个专门负责高时效性业务,7个节点负责一般业务。当时队列用的是rabbitmq,为此改造了spring-rabbit 支持根据msytype将消息路由到特定节点。该方案有以下缺点:
- 总有一些机器很忙的时候,另一些机器在“袖手旁观”。
- 新增业务时,需要额外配置msgType到消费节点的映射关系,维护成本较高。
- rabbitmq基于内存实现,推送瞬时高峰时占用内存较大,进而引发rabbitmq 不稳定。
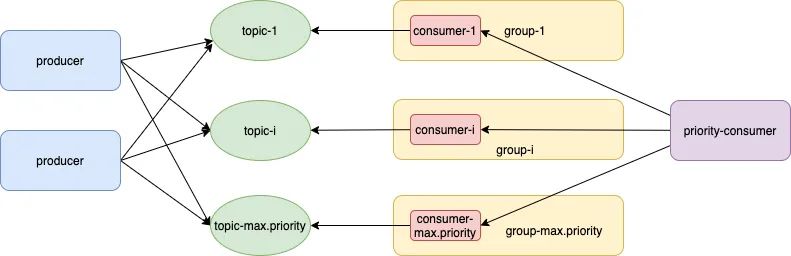
后来我们觉察到这是一个优先级问题,高优先级业务/消息可以插队,于是封装kafka支持优先级,比较好的解决了隔离性方案带来的问题。具体实现是建立多个topic,一个topic代表一个优先级,封装kafka主要是封装消费端的逻辑(即构造一个PriorityConsumer)。
备注:为描述简单,本文使用consumer.poll(num)来描述使用consumer 拉取num个消息,与真实kafka api 不一致,请知悉。
PriorityConsumer实现有三种方案
- poll到内存后重新排序。java 有现成的基于内存的优先级队列PriorityQueue 或PriorityBlockingQueue,kafka consumer 正常消费,并将poll 到的数据重新push到优先级队列。
-
- 如果使用有界队列,队列打满后,后面的消息优先级再高也put 不进去,失去“插队”效果
- 如果使用无界队列,本来应堆在kafka上的消息都会堆到内存里,OOM的风险很大。
- 先拉取高优先级topic的数据,只要有就一直消费,直到没有数据再消费低一级topic。消费低一级topic的过程中,如果发现有高一级topic消息到来,则转向消费高优先级消息。
该方案实现较为复杂,且在晚高峰等推送密集的时间段,可能会导致低优先级业务完全失去推送机会。
- 优先级从高到低,循环拉取数据,一次循环的逻辑为
consumer-1.poll(topic1-num);
cosumer-i.poll(topic-i-num);
consumer-max.priority.poll(topic-max.priority-num)如果topic1-num=topic-i-num=topic-max.priority-num,则该方案是没有优先级效果的。topic1-num 可以视为权重,我们约定topic-高-num=2 * topic-低-num,同一时刻所有topic 都会被消费,通过一次消费数量的多少来变相实现“插队效果”。具体细节上还借鉴了“滑动窗口”策略来优化某个优先级的topic 长期没有消息时总的消费性能。
从中我们可以看到,时效问题先是被理解为一个隔离问题,后被视为优先级问题,最终转化为了一个权重问题。
过滤机制的存储和性能问题
影响发送速度的主要就是tidb查询和过滤逻辑,过滤机制又分为存储和性能两个问题。
以xx业务频控限制“一个小时最多发送一条”为例,第一版实现时,redis kv 结构为 <deviceId_msgtype,已发送推送数量>,频控实现逻辑为
- 发送时,
incr key,发送次数加1 - 如果超限(incr命令返回值>发送次数上限),则不推送。
- 若未超限且返回值为1,说明在msgtype频控周期内第一次向该deviceId发消息,需
expire key设置过期时间(等于频控周期)。
上述方案有以下缺点
- 目前公司有60+推送业务, 6亿+ deviceId,一共6亿*60个key ,占用空间巨大。
- 很多时候,处理一个deviceId需要2条指令:incr+expire
为此
- 使用pika(基于磁盘的redis)替换redis,磁盘空间可以满足存储需求。
- 委托系统架构组扩充了redis协议,支持新结构ehash
ehash基于redis hash修改,是一个两级map <key,field,value>,除了key 可以设置有效期外,field也可以支持有效期,且支持有条件的设置有效期。
- 频控数据的存储结构由
<deviceId_msgtype,value>变为<deviceId,msgtype,value>,这样对于多个msgtype,deviceId只存一次,节省了占用空间。 - incr 和 expire 合并为1条指令:
incr(key,filed,expire),减少了一次网络通信。
-
- 当field未设置有效期时,则为其设置有效期
- 当field还未过期时,则忽略有效期参数
因为推送系统重度使用incr 指令,可以视为一条写指令,大部分场景还用了pipeline来实现批量写的效果,我们委托系统架构组小伙伴专门优化了pika的写入性能,支持“写模式”(优化了写场景下的相关参数),qps达到10w以上。
ehash结构在流水记录时也发挥了重要作用,比如<deviceId,msgId,100001002>,其中100001002 是我们约定的一个数据格式示例值,前中后三个部分(每个部分占3位)分别表示了某个消息(msgId)针对deviceId的发送、接收和点击详情,比如头3位“100”表示因发送时处于静默时间段所以发送失败。
小结
推送在业务设计上也做了很多工作,比如如何将送达、点击数据反馈到拦截逻辑中,因为技术问题较少,此处不再赘述。在推送系统的实践中,最深的体会就是要能够将业务需求转化为基础组件的技术需求,比如使用tidb替换mysql分库分表、kafka支持优先级、pika支持ehash结构等,推动公司优秀组件的引入和创新。同时,要对底层技术有一定的熟悉,比如因为有看过redis的源码,了解hash的大致实现,进而想到通过改造pika/redis解决业务及性能问题,否则很容易一直在业务层打转。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









