







一、RDB持久化
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘。也是默认的持久化方式,这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。
RDB的两种方式:
1、save:
优点:节约系统资源
缺点:直接调用 rdbSave ,阻塞 Redis 主进程,直到保存完成为止。在主进程阻塞期间,服务器不能处理客户端的任何请求。
2、bgsave:Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件;fork的新进程所有数据(变量、环境变量、程序计数器等)数值都和原进程一致
优点:fork 出一个子进程,子进程负责调用 rdbSave ,并在保存完成之后向主进程发送信号,通知保存已完成。 Redis 服务器在BGSAVE 执行期间仍然可以继续处理客户端的请求
缺点:由于会fork一个进程,因此更消耗内存
stop-writes-on-bgsave-error= yes
表示reids开启Rdb的bgsave模式, redis主线程会fork一个新的后台子进程,子进程按照一定的规则将内存中的数据同步到dump rdb;
假设 :创建快照(硬盘上,产生一个新的rdb文件)需要 20s时间,redis主进程,在这20s内,会继续接受客户端命令,但是,就在这20s,内,创建快照!!!,出错了,比如磁盘满了,那么redis会认为,
当前!!!,Redis is configured to save RDB snapshots, but is currently not able to persist on disk. but is currently not able to persist on disk.
那么,redis会,拒绝 新的写入,也就是说,它认为,你当下,持久化数据出现了问题,你就不要再set啦
rdbcompression yes #指定存储至本地数据库时是否压缩数据,默认是yes,redis采用LZF压缩,如果为了节省CPU时间可以关闭该选项,但会导致数据库文件扁的巨大
rdbchecksum :默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。
dir:设置快照文件的存放路径,这个配置项一定是个目录,而不能是文件名。默认是和当前配置文件保存在同一目录
默认自动备份规则(满足这三种条件其中之一则生成rdb文件):
- save 900 1 每隔900秒有1次增删改则生成rdb文件
- save 300 10 每隔300秒有10次增删改则生成rdb文件
- save 60 10000 每隔60秒有10000次增删改则生成rdb文件
RDB自动bgsave的原理:
struct redisService{
//1、记录保存save条件的数组
struct saveparam *saveparams;
//、数器记录距离上一次成功执行 save 命令或者 bgsave 命令之后,Redis服务器进行了多少次修改(包括写入、删除、更新等操作)
long long dirty;
//3、记录上一次成功执行 save 命令或者 bgsave 命令的时间
time_t lastsave;
}
struct saveparam{
//秒数
time_t seconds;
//修改数
int changes;
};
severCron:周期性操作函数 ;默认每隔 100 毫秒就会执行一次
hz 10: 这个配置表示1s内执行10次,也就是每100ms触发一次定时任务
通过这两个属性,当服务器成功执行一次修改操作,那么dirty 计数器就会加 1,而lastsave 属性记录上一次执行save或bgsave的时间;
severCron函数会遍历并检查 saveparams 数组中的所有保存条件,只要有一个条件被满足,那么就会执行 bgsave 命令
执行完成之后,dirty 计数器更新为 0 ,lastsave 也更新为执行命令的完成时间
触发bgsave的场景:
- save m n以外
- 在主从复制场景下,如果从节点执行全量复制操作,则主节点会执行 bgsave 命令,并将rdb文件发送给从节点;
- 执行shutdown命令时,自动执行rdb持久化,
恢复操作
- 对于手动备份的场景,我们将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可
- 对于使用自动备份的,当重新启动redis服务时他会自动加载配置文件中指定的文件
RDB优点
- RDB是一个非常紧凑(compact)的文件,它保存了redis 在某个时间点上的数据集。这种文件非常适合用于进行备份和灾难恢复。
- 生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
- RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
RDB缺点
- RDB方式数据没办法做到实时持久化/秒级持久化。因为bgsave每次运行都要执行fork操作创建子进程,属于重量级操作,如果不采用压缩算法(内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑),频繁执行成本过高(影响性能)
- RDB文件使用特定二进制格式保存,Redis版本演进过程中有多个格式的RDB版本,存在老版本Redis服务无法兼容新版RDB格式的问题(版本不兼容)
- 在一定间隔时间做一次备份,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改(数据有丢失)
二、AOF持久化
RDB是一种直接保存数据的全量备份方案;AOF是一种追加操作记录(增、删、改操作指令)的备份方式;
AOF持久化原理:
1、AOF持久化需要将所有写命令记录在文件中来保存服务器状态,而文件写入操作效率比较低,如果每执行一条写命令都要写一次AOF文件无疑是低效的。为了提高效率,Redis提供了一个中间层 – AOF缓冲区,也就是说当Redis执行一条写命令后,先将该命令追加到AOF缓冲区中,在以后的某个时刻再将AOF缓冲区中的内容同步到文件中。当AOF持久化功能处于打开状态时,服务器在执行完一个写命令之后,会将执行的写命令按照协议格式追加到服务器的aof_buf缓冲区的末尾(此刻如果后台正在执行AOF文件后台重写操作,该命令还会被追加到AOF重写缓存中)
2、redis中serverCron会周期性的调用flushAppendOnlyFile函数进行文件的写入和同步,就是调用操作系统的write()方法,将aof_buf中的数据写入文件的缓冲区,是否调用fsync()函数将缓冲区真正的写入磁盘取决于redis的配置;我们可以通过配置redis.conf文件中的flush选项来指定AOF同步策略,主要有三种同步策略:
- AOF_FSYNC_NO:在该模式下,Redis服务器在每个事件循环都将AOF缓冲区server.aof_buf中的数据写入AOF文件中,但不执行同步fsync方法,由操作系统决定何时同步。该模式速度最快(无需执行同步操作)但也最不安全(如果机器崩溃将丢失上次同步后的所有数据)。
- AOF_FSYNC_ALWAYS :在该模式下,Redis服务器在每个事件循环都将AOF缓冲区server.aof_buf中的数据写入AOF文件中,且执行一次AOF文件同步操作。该模式速度最慢(每个事件循环都要执行同步操作)但也最安全(如果机器崩溃只丢失当前事件循环中处理的新数据)。
- AOF_FSYNC_EVERYSEC:在该模式下,Redis服务器在每个事件循环都将AOF缓冲区server.aof_buf中的数据写入AOF文件中,且每秒执行一次AOF文件同步操作。该模式效率和安全性(如果机器崩溃只丢失前一秒处理的新数据)比较适中,是Redis的默认同步策略。
AOF重写:
由于aof是通过不断追加写命令来记录数据库状态,所以服务器执行比较久之后,aof文件中的内容会越来越多,磁盘占有量越来越大,同时也会使通过aof文件还原数据库需要的时间也变得很久。所以就需要通过读取服务器当前的数据库状态来重写新的aof文件。新的AOF文件不会包含任何浪费空间的冗余命令,所以会比旧的AOF文件小很多。
AOF重写
1、15:30 redis 执行指令
set user:1:age 20
2、15:40 redis 执行指令
set user:1:age 21
3、15:50 redis 执行指令
set user:1:age 23
这三条指令其实操作的都是同一个数据,所以redis的AOP重写他只需要关注最后一个就好,
这样就可以排除调其他两条数据,这样文件减小2/3AOF重写是会进行大量写入操作,主进程会fork一个与自己一样的子线程,通过子线程进行重写操作;子进程重写期间,主进程可以继续处理命令,子进程带有主进程的数据副本,可以避免与主进程的冲突
AOF重写子进程如何保证与主进程执行的指令一致?
AOF重写,从创建重写子进程开始,服务器执行的所有写命令会被记录到AOF重写缓冲区里面;当子进程完成重写任务后,会向父进程发送一个信号。父进程收到信号后,将AOF重写缓冲区的类容写入到新的AOF缓冲期中,这时新AOF缓冲区中数据库的状态和服务器的当前状态一致;然后对新的AOF文件改名,直接覆盖现有的AOF文件,完成新旧AOF文件的替换,整个AOF重写期间,只有信号处理函数执行时会对服务器进程造成阻塞。
AOF文件的数据还原:数据还原就是将AOF文件中保存的命令解析并执行。因为在Redis中,命令必须由redisClient实例来执行,所以为了加载AOF文件需要创建一个伪Redis客户端,创建了伪Redis客户端后,执行数据还原的过程就是从AOF文件中读取命令并交给伪Redis客户端执行的过程

#redis 默认关闭,开启需要手动把no改为yes
appendonly yes
#指定本地数据库文件名,默认值为 appendonly.aof
appendfilename "appendonly.aof"
# 指定更新日志条件(AOF持久化原理有介绍每一个的原理)
appendfsync everysec
#配置重写触发机制
auto-aof-rewrite-percentage 100
#aof文件重写最小的文件大小,即最开始aof文件必须要达到这个文件时才触发
auto-aof-rewrite-min-size 64mb
#指redis在恢复时,会忽略最后一条可能存在问题的指令。默认值yes。即在aof写入时,
#可能存在指令写错的问题(突然断电,写了一半),这种情况下,yes会log并继续,而no会直接恢复失败.
aof-load-truncatedAOF 的优缺点
- 优点:数据的完整性和一致性较高,突然断电可能会存在指令不完整的情况,但是可使用redis-check-aof工具修复
- 缺点:因为AOF记录的内容多,文件会越来越大,数据恢复也会越来越慢。由于AOF需要周期性的执行 fsync(),所以AOF 的速度可能会慢于 RDB,但是我们可以根据不同的需求设置fsync的策略
三、混合模式
RDB定时生成 RDB 快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快,但是数据的丢失量较大;AOF持久化,数据量很大时,在redis启动的时候需要花费大量的时间;所以redis4.0推出混合模式。
混合模式:混合持久化同样也是通过bgrewriteaof完成的,不同的是当开启混合持久化时,fork出的子进程先将共享的内存副本全量的以RDB方式写入aof文件,然后在将aof_rewrite_buf重写缓冲区的增量命令以AOF方式写入到文件,写入完成后通知主进程更新统计信息,并将新的含有RDB格式和AOF格式的AOF文件替换旧的的AOF文件。简单的说:新的AOF文件前半段是RDB格式的全量数据后半段是AOF格式的增量数据,如下图:
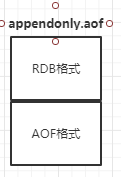
在redis重启的时候,加载 aof 文件进行恢复数据:先加载 rdb 内容再加载剩余的 aof
混合持久化配置:aof-use-rdb-preamble yes # yes:开启,no:关闭
RDB和AOF,应该用哪一个:
- 如果你的系统只是用缓存,并发量很小,你可以不持久化
- 如果你可以承受数分钟以内的数据丢失, 那么你可以只使用 RDB 持久化
- 如果你很关心你的数据,但是不介意redis的效率,可以使用AOF。
- 如果你非常关心你的数据,建议使用 redis 4.0 以后的混合持久化特性
参考博客:
https://www.cnblogs.com/harvyxu/p/7536423.html
https://www.cnblogs.com/itdragon/p/7906481.html
https://www.cnblogs.com/chichung/p/12687101.html















 493
493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









